从 Numpy+Pytorch 到 TensorFlow JS:总结和常用平替整理
demo展示
这是一个剪刀石头布预测模型,会根据最近20局的历史数据训练模型,神经网络输入为最近2局的历史数据。
如何拥有较为平滑的移植体验?
- 保持两种语言,和两个框架的API文档处于打开状态,并随时查阅:Python,JavaScript;Pytorch,TensorFlow JS(用浏览器 F3 搜索关键词)。
- 可选阅读,《动手学深度学习》,掌握解决常见学习问题时,Pytorch 和 TensorFlow 的实现方法。
- 精读 TensorFlow JS 的官方教程,和指南。
- 精读 TensorFlow JS 的官方文档:与 Python tf.keras 的区别。
- 深入了解 JavaScript 特色对象:生成器 Generator,Promise,async await。
- 多用谷歌。
一些碎碎念
- JavaScript 不存在像 numpy 之于 python 一样著名且好用的数据处理库,所以请放弃对 JavaScript 原生类型 Array 进行操作的尝试,转而寻找基于 TensorFlow JS API 的解决方法。
- JavaScript 作为一门前端语言,一大特色是包含了大量异步编程(即代码不是顺序执行的,浏览器自有一套标准去调整代码的执行顺序),这是为了保证前端页面不被卡死,所必备的性质。也因此,TensorFlow JS的函数中,许多输入输出传递的都不是数据,而是Promise对象。很多功能支持异步,但如果没有完全搞懂异步编程,不妨多用同步的思路:用 tf.Tensor.arraySync() 把 Tensor 的值取出,具体来说是将 Tensor 对象以同步的方式(即立即执行)拷贝生成出一个新的 array 对象。
- Promise 对象是ES6新增的对象,一般与then一起使用,但掌握 async & await 就够了,这是更简洁的写法。
- 多关注 API 文档中对象方法的返回类型,返回 Promise 对象则与异步编程相关,如果要获取Promise对象储存的值,需要在有 async function 包裹的代码中前置 await 关键字。
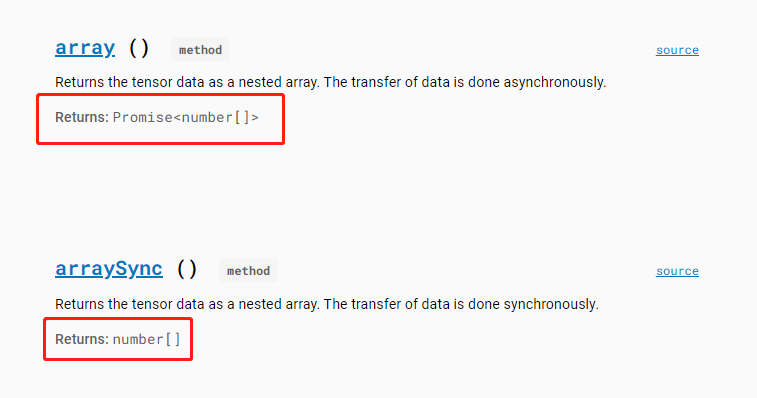
- Pytorch 中的张量可以通过索引访问其元素,而 TensorFlow JS 则不能,需要转换为 array 进行访问。
常用平替整理
将张量转换为数组
- Python, Pytorch:
tensor = torch.tensor([1,2,3])
np_array = tensor.numpy()
- JS, tfjs:
// 方式一:arraySync()
let tensor = tf.tensor1d([1,2,3]);
let array = tensor.arraySync();
console.log(array); // [1,2,3] // 方式二:在async函数体内操作
async function fun() {
let tensor = tf.tensor1d([1,2,3]);
let array = await tensor.array();
console.log(array); // [1,2,3]
}
fun(); // 注意,下面的写法是不行的,因为async函数的返回值是Promise对象
array = async function (){
return await tensor.array();
}();
console.log(array); // Promise object // 方式三:用then取出async函数返回Promise对象中的值
let a
(async function() {
let array = await tensor.array();
return array
})().then(data => {a = data;})
console.log(a); // [1,2,3]
访问张量中的元素
- Python,Pytorch:
tensor = torch.tensor([1,2,3])
print(tensor[0])
print(tensor[-1])
- JS,tfjs(不能直接通过访问tensor,需要转换成array):
const tensor = tf.tensor1d([1,2,3]);
const array = tensor.arraySync();
console.log(array[0]);
console.log(array[array.length - 1]);
获取字典/对象的关键字
- Python:
actions = {'up':[1,0,0,0], 'down':[0,1,0,0], 'left':[0,0,1,0], 'right':[0,0,0,1]}
actions_keys_list = list(actions.keys())
- JS:
const actions = {'up':[1,0,0,0], 'down':[0,1,0,0], 'left':[0,0,1,0], 'right':[0,0,0,1]};
const actionsKeysArray = Object.keys(actions);
“先进先出”栈
- Python:
memory = [1,2,3]
memory.append(4) # 入栈
memory.pop(0) # 出栈
- JS:
let memory = [1,2,3];
memory.push(4); // 入栈
memory.splice(0,1); // 出栈
“后进先出”栈
- Python:
memory = [1,2,3]
memory.append(4) # 入栈
memory.pop() # 出栈
- JS:
let memory = [1,2,3];
memory.push(4); // 入栈
memory.pop(); // 出栈
根据概率分布采样元素
- Python,Numpy:
actions = ['up','down','left','right']
prob = [0.1, 0.4, 0.4, 0.1]
sample_action = np.random.choice(actions, p=prob))
- JS,tfjs:
const actions = ['up', 'down', 'left', 'right'];
const prob = [0.1, 0.4, 0.4, 0.1];
sampleActionIndex = tf.multinomial(prob, 1, null, true).arraySync(); // tf.Tensor 不能作为索引,需要用 arraySync() 同步地传输为 array
sampleAction = actions[sampleActionIndex];
找到数组中最大值的索引(Argmax)
- Python,Numpy,Pyorch:
actions = ['up', 'down', 'left', 'right']
prob = [0.1, 0.3, 0.5, 0.1]
prob_tensor = torch.tensor(prob)
action_max_prob = actions[np.array(prob).argmax()] # np.array 可以作为索引
action_max_prob = actions[prob_tensor.argmax().numpy()] # torch.tensor 不能作为索引,需要转换为 np.array
- JS, tfjs:
const actions = ['up', 'down', 'left', 'right'];
const prob = [0.1, 0.3, 0.5, 0.1];
const probTensor = tf.tensor1d(prob);
const actionsMaxProb = actions[probTensor.argmax().arraySync()]; // tf.Tensor 不能作为索引,需要用 arraySync()同步地传输为 array
生成等差数列数组
- Python:
range_list = list(range(1,10,1))
- JS, tfjs:
const rangeArray = tf.range(1, 10, 1).arraySync();
打乱数组
- Python:
actions = ['up', 'down', 'left', 'right']
print(random.shuffle(actions))
- JS:How to randomize (shuffle) a JavaScript array? 关于原生JS解决方案的大讨论。
- tfjs:(1)用 tf.util 类操作,处理常规的需求。
const actions = ['up', 'down', 'left', 'right'];
tf.util.shuffle(actions);
console.log(actions);
(2)用 tf.data.shuffle 操作,不建议,该类及其方法一般仅与 神经网络模型更新 绑定使用。
极简逻辑回归
- Python,Numpy,Pytorch:
import numpy as np
import torch
from torch import nn
import random class Memory(object):
# 向Memory输送的数据可以是list,也可以是np.array
def __init__(self, size=100, batch_size=32):
self.memory_size = size
self.batch_size = batch_size
self.main = [] def save(self, data):
if len(self.main) == self.memory_size:
self.main.pop(0)
self.main.append(data) def sample(self):
samples = random.sample(self.main, self.batch_size)
return map(np.array, zip(*samples)) class Model(object):
# Model中所有方法的输入和返回都是np.array
def __init__(self, lr=0.01, device=None):
self.LR = lr
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 调用GPU 若无则CPU
self.network = nn.Sequential(nn.Flatten(),
nn.Linear(10, 32),
nn.ReLU(),
nn.Linear(32, 5),
nn.Softmax(dim=1)).to(self.device)
self.loss = nn.CrossEntropyLoss(reduction='mean')
self.optimizer = torch.optim.Adam(self.network.parameters(), lr=self.LR) def predict_nograd(self, _input):
with torch.no_grad():
_input = np.expand_dims(_input, axis=0)
_input = torch.from_numpy(_input).float().to(self.device)
_output = self.network(_input).cpu().numpy()
_output = np.squeeze(_output)
return _output def update(self, input_batch, target_batch):
# 设置为训练模式
self.network.train()
_input_batch = torch.from_numpy(input_batch).float().to(self.device)
_target_batch = torch.from_numpy(target_batch).float().to(self.device) self.optimizer.zero_grad()
_evaluate_batch = self.network(_input_batch)
batch_loss = self.loss(_evaluate_batch, _target_batch)
batch_loss.backward()
self.optimizer.step()
batch_loss = batch_loss.item() # 设置为预测模式
self.network.eval() if __name__ == '__main__':
memory = Memory()
model = Model() # 产生数据并输送到内存中
# 假设一个5分类问题
for i in range(memory.memory_size):
example = np.random.randint(0,2,size=10)
label = np.eye(5)[np.random.randint(0,5)]
data = [example, label]
memory.save(data) # 训练100次,每次从内存中随机抽取一个batch的数据
for i in range(100):
input_batch, target_batch = memory.sample()
model.update(input_batch, target_batch) # 预测
prediction = model.predict_nograd(np.random.randint(0,2,size=10))
print(prediction)
- JS,tfjs(网页应用一般不使用GPU):
const Memory = {
memorySize : 100,
main : [],
saveData : function (data) {
// data = [input:array, label:array]
if (this.main.length == this.memorySize) {
this.main.splice(0,1);
}
this.main.push(data);
},
getMemoryTensor: function () {
let inputArray = [],
labelArray = [];
for (let i = 0; i < this.main.length; i++) {
inputArray.push(this.main[i][0])
labelArray.push(this.main[i][1])
}
return {
inputBatch: tf.tensor2d(inputArray),
labelBatch: tf.tensor2d(labelArray)
}
}
}
const Model = {
batchSize: 32,
epoch: 200,
network: tf.sequential({
layers: [
tf.layers.dense({inputShape: [10], units: 16, activation: 'relu'}),
tf.layers.dense({units: 5, activation: 'softmax'}),
]
}),
compile: function () {
this.network.compile({
optimizer: tf.train.sgd(0.1),
shuffle: true,
loss: 'categoricalCrossentropy',
metrics: ['accuracy']
});
},
predict: function (input) {
// input = array
// Return tensor1d
return this.network.predict(tf.tensor2d([input])).squeeze();
},
update: async function (inputBatch, labelBatch) {
// inputBatch = tf.tensor2d(memorySize × 10)
// labelBatch = tf.tensor2d(memorySize × 5)
this.compile();
await this.network.fit(inputBatch, labelBatch, {
epochs: this.epoch,
batchSize: this.batchSize
}).then(info => {
console.log('Final accuracy', info.history.acc);
});
}
}
// 假设一个5分类问题
// 随机生成样例和标签,并填满内存
let example, label, rnd, data;
for (let i = 0; i < Memory.memorySize; i++) {
example = tf.multinomial(tf.tensor1d([.5, .5]), 10).arraySync();
rnd = Math.floor(Math.random()*5);
label = tf.oneHot(tf.tensor1d([rnd], 'int32'), 5).squeeze().arraySync();
data = [example, label];
Memory.saveData(data);
}
// 将内存中储存的数据导出为tensor,并训练模型
let {inputBatch, labelBatch} = Memory.getMemoryTensor();
Model.update(inputBatch, labelBatch);
从 Numpy+Pytorch 到 TensorFlow JS:总结和常用平替整理的更多相关文章
- pytorch和tensorflow的爱恨情仇之基本数据类型
自己一直以来都是使用的pytorch,最近打算好好的看下tensorflow,新开一个系列:pytorch和tensorflow的爱恨情仇(相爱相杀...) 无论学习什么框架或者是什么编程语言,最基础 ...
- pytorch和tensorflow的爱恨情仇之定义可训练的参数
pytorch和tensorflow的爱恨情仇之基本数据类型 pytorch和tensorflow的爱恨情仇之张量 pytorch版本:1.6.0 tensorflow版本:1.15.0 之前我们就已 ...
- TensorFlow.js入门(一)一维向量的学习
TensorFlow的介绍 TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理.Tensor(张量)意味着N维数组,Flow(流)意味着 ...
- 转《在浏览器中使用tensorflow.js进行人脸识别的JavaScript API》
作者 | Vincent Mühle 编译 | 姗姗 出品 | 人工智能头条(公众号ID:AI_Thinker) [导读]随着深度学习方法的应用,浏览器调用人脸识别技术已经得到了更广泛的应用与提升.在 ...
- TensorFlow.js之根据数据拟合曲线
这篇文章中,我们将使用TensorFlow.js来根据数据拟合曲线.即使用多项式产生数据然后再改变其中某些数据(点),然后我们会训练模型来找到用于产生这些数据的多项式的系数.简单的说,就是给一些在二维 ...
- TensorFlow.js之安装与核心概念
TensorFlow.js是通过WebGL加速.基于浏览器的机器学习js框架.通过tensorflow.js,我们可以在浏览器中开发机器学习.运行现有的模型或者重新训练现有的模型. 一.安装 ...
- 大前端技术系列:TWA技术+TensorFlow.js => 集成原生和AI功能的app
大前端技术系列:TWA技术+TensorFlow.js => 集成原生和AI功能的app ( 本文内容为melodyWxy原作,git地址:https://github.com/melodyWx ...
- TensorFlow.js入门:一维向量的学习
转载自:https://blog.csdn.net/weixin_34061042/article/details/89700664 一维向量及其运算 tensor 是 TensorFlow.js 的 ...
- Getting Started with TensorFlow.js
使用TensorFlow.js,您不仅可以在浏览器中运行深度学习模型进行推理,你还能够训练它们.在这个简单的样例中,将展示一个相当于“Hello World”的示例. 1.引入TensorFlow.j ...
- [ML] Tensorflow.js + Image segmentPerson
<!DOCTYPE html> <html> <head> <title>Parcel Sandbox</title> <meta c ...
随机推荐
- Mac_mysql_密码重置
1 通过Mac 的设置 stop mysql 2 跳过权限认证 // 进入数据库指令文件 cd /usr/local/mysql/bin // 跳过权限认证 sudo ./mysqld_safe -- ...
- EntityFrameworkCore 模型自动更新(下)
话题 上一篇我们讨论到获取将要执行的迁移操作,到这一步为止,针对所有数据库都通用,在此之后需要生成SQL脚本对于不同数据库将有不同差异,我们一起来瞅一瞅 SQLite脚本生成差异 在上一篇拿到的迁移操 ...
- Windows服务器TLS协议
今天在Windows Admin Center里试图安装扩展插件的时候遇到一个问题.在可用插件里没有任何显示,包括各种微软自己开发的插件. 在Feeds里删除默认的链接,重新添加的时候也会遇到报错.说 ...
- Windows打印服务器上无法删除打印机
这几天遇到了一个问题,在Windows 2008的打印服务器上的打印机无法删除.具体表现是可以在设备和打印机里删除打印机,然后刷新一下,它们又出来了.这些打印机早就不存在了,并且这些打印机的图标呈半透 ...
- K8S Pod Pending 故障原因及解决方案
文章转载自:https://mp.weixin.qq.com/s/SBpnxLfMq4Ubsvg5WH89lA
- Beats:通过Metricbeat实现外部对Elastic Stack的监控
- Java导出带格式的Excel数据到Word表格
前言 在Word中创建报告时,我们经常会遇到这样的情况:我们需要将数据从Excel中复制和粘贴到Word中,这样读者就可以直接在Word中浏览数据,而不用打开Excel文档.在本文中,您将学习如何使用 ...
- 自定义映射resultMap
resultMap处理字段和属性的映射关系 如果字段名与实体类中的属性名不一致,该如何处理映射关系? 第一种方法:为查询的字段设置别名,和属性名保持一致 下面是实体类中的属性名: private In ...
- 轻量级Web框架Flask——Web表单
安装 Flask-WTF及其依赖可使用pip安装 pip install flask_wtf 配置 要求应用配置一个密钥.密钥是一个由随机字符构成的唯一字符串,通过加密或签名以不同的方式提升应用的安全 ...
- Linux命令系列之ls——原来最简单的ls这么复杂
Linux命令系列之ls--原来最简单的ls这么复杂 ls命令应该是我们最常用的命令之一了,但是我们可能容易忽略那些看起来最简单的东西. 简介 ls命令的使用格式如下 ls [选项] [具体的文件] ...