论文解读(gCooL)《Graph Communal Contrastive Learning》
论文信息
论文标题:Graph Communal Contrastive Learning
论文作者:Bolian Li, Baoyu Jing, Hanghang Tong
论文来源:2022, WWW
论文地址:download
论文代码:download
1 Introduction
有相同兴趣的人往往通过他们的互动而紧密联系,而有不同兴趣的人则是松散的联系。因此,同一兴趣社区的人在图形上是相似的,将它们视为负对会给节点表示引入图形错误。为了解决这一问题,我们首先提出了一种基于图结构信息学习社区划分的密集社区聚合()算法。接下来,我们引入了一种新的重加权自监督对比()训练方案,将同一社区中的节点在表示空间中拉得更近。
此外,在真实的图中,节点可以通过多个关系[22,24,44,69]进行连接,每个关系都可以被视为一个图视图(称为多重图[10])。适应于多重图的图表示学习方法的一种方法是分别学习每个图视图的表示,然后将它们与融合模型[21]相结合。然而,这种方法忽略了不同图形视图之间的图形依赖关系。例如,IMDB[62]可以被建模为一个由联合演员和联合导演关系连接的多重电影图。这两种联系并不是独立的,因为演员和导演之间的个人关系会影响他们对电影的参与。为了解决这个问题,我们应用了与单关系图情况一致的对比训练,对每对图视图应用成对对比训练,并使用后集成方式来组合下游任务中所有视图的模型输出。
2 Preliminaries
2.1 Similarity Measurement
exponent cosine similarity
$\delta_{c}\left(x_{1}, x_{2}\right)=\exp \left\{\frac{x_{1}^{T} x_{2} / \tau}{\left\|x_{1}\right\| \cdot\left\|x_{2}\right\|}\right\} \quad\quad\quad(1)$
$\delta_{e}\left(x_{1}, x_{2}\right)=\exp \left\{-\left\|x_{1}-x_{2}\right\|^{2} / \tau^{2}\right\} \quad\quad\quad(2)$
2.2 Community Detection
Formulation. For a graph $G=(V, E)$ , with its node set $V= \left\{v_{1}, v_{2}, \ldots \ldots, v_{M}\right\}$ and edge set $E=\left\{\left(v_{i_{1}}, v_{j_{1}}\right),\left(v_{i_{1}}, v_{j_{1}}\right), \ldots \ldots,\left(v_{i_{M}}, v_{j_{M}}\right)\right\}$ , we define one of its communities $C$ as a sub-graph: $C=\left(V^{C}, E^{C}\right)$ , where $V^{C} \subseteq V$ and $E^{C}=E \cap\left(V^{C} \times V^{C}\right) $.
Modularity. A widely used evaluation for community partitions is the modularity [42], defined as:
$ m=\frac{1}{2 M} \sum\limits _{i, j}\left[A[i, j]-\frac{d_{i} d_{j}}{2 M}\right] r(i, j) \quad\quad\quad(3)$
where $A$ is the adjacency matrix, $d_{i}$ is the degree of the $i -th$ node, and $r(i, j)$ is $1$ if node $i$ and $j$ are in the same community, otherwise is $0$ . The modularity measures the impact of each edge to the local edge density $\left(d_{i} d_{j} / 2 M\right)$. represents the expected local edge density), and is easily disturbed by the changing of edges.
Edge count function.We define the edge count function over the adjacency matrix:
$E(C)=\sum\limits _{i, j} \mathbb{1}\left\{A^{C}[i, j] \neq 0\right\} \quad\quad\quad(4)$
where $A^{C}$ is the adjacency matrix for community $C$ .
Edge density function.The edge density function compares the real edge count to the maximal possible number of edges in the given community $C_{k}$ :
${\large d(k)=\frac{E\left(C_{k}\right)}{\left|C_{k}\right|\left(\left|C_{k}\right|-1\right)} } \quad\quad\quad(5)$
2.3 Attributed Multiplex Graph
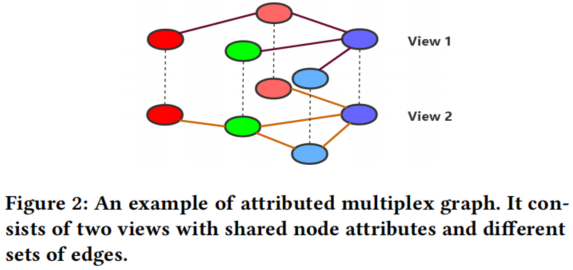
Multiplex graphs 也被称为 multi-dimensional graphs [39]或 multi-view graphs[12,23,55],它由多个单视图图组成,具有共享的节点和属性,但具有不同的图结构(通常具有不同类型的链接)[6]。
3 Method
3.1 Dense Community Aggregation
节点级GCL方法容易出现将结构相近的节点作为负样本配对的问题。本文的方法受到图中的模块化[42]的启发,它测量了社区中的 local edge density 。然而,模块化很容易受到边[36]的变化的干扰,这限制了其在检测社区时的鲁棒性(边缘在每个时代都会动态变化)。
因此,我们的目标是增强模块化的鲁棒性,并通过最大化每个社区的边缘密度来进一步扩展模块化,同时最小化不同社区之间的边缘密度。DeCA 通过端到端训练进行,如 Fig. 3 所示。
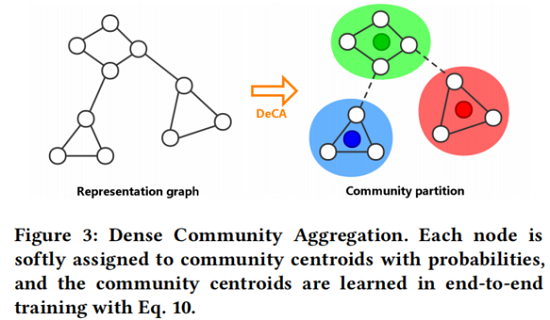
我们通过以端到端方式训练一个随机初始化的质心矩阵 $\Phi$ 来学习社区划分,其中每个 $\Phi[k,:]$ 代表第 $k$ 个社区的中心。
首先,我们将图中的每个节点以一定的概率分配给社区质心(通过相似度函数 $\text{Eq.1}$ 、$\text{Eq.2}$)。具体地说,我们定义了一个社区分配矩阵 $\boldsymbol{R}$,其中每个 $\boldsymbol{R}[i,:]$ 都是一个标准化的相似度向量,度量第 $i$ 个节点和所有社区质心之间的距离。在形式上,$\boldsymbol{R}$ 是由
$\boldsymbol{R}=\text { normalize }\left(\delta\left(f_{\theta}(\boldsymbol{X}, \boldsymbol{A}), \boldsymbol{\Phi}\right)\right) \quad\quad\quad(6)$
其中,$\delta(\cdot)$ 为 2.1 中定义的相似度函数。$f_{\theta}(\cdot)$ 是参数为 $\theta$ 的图编码器,$normalize (\cdot)$ 通过将每个社区的概率除以所有概率之和来归一化,并保持每个 $i$ 的 $\sum_{j} R[i, j]=1$。
其次,我们采用了两个目标来训练社区划分:社区内密度 (intra-community density):
$D_{\text {intra }}=\frac{1}{N} \sum\limits _{i, j} \sum\limits_{k}[A[i, j]-d(k)] R[i, k] R[j, k]\quad\quad\quad(7)$
社区间密度(inter-community density ):
$D_{\text {inter }}=\frac{1}{N(N-1)} \sum\limits_{i, j} \sum\limits_{k_{1} \neq k_{2}} A[i, j] R\left[i, k_{1}\right] R\left[j, k_{2}\right] \quad\quad\quad(8)$
这两个目标测量了每条边对 community edge density 的影响(而不是在模块化[42]中使用的局部边缘密度)。具体来说,在 $Eq. 7$ 和 $Eq. 8$ 中、$A[i, j]-d(k)$ 和 $A[i, j]-0$ 表示真实局部密度 $(A[i, j])$ 和预期密度($d(k)$,intercommunity 为 $0$)之间的差距。通过最小化联合目标,将更新质心矩阵 $\Phi$,以达到合理的社区划分:
$l_{D e C A}(R)=\lambda_{w} D_{\text {inter }}-D_{\text {intra }} \quad\quad\quad(9)$
其中 $\lambda_{w}$ 是系数。此外,为了提高计算效率,我们在实际实现中稍微修改了 $l_{D e C A}$ 的形式(如附录C所示)。最后,我们结合了两个图视图的 $l_{D e C A}$ 目标,并同时对它们进行密集的社区聚合:
$L_{D e C A}=\frac{1}{2}\left[l_{D e C A}\left(R^{1}\right)+l_{D e C A}\left(R^{2}\right)\right] \quad\quad\quad(10)$
3.2 Reweighted Self-supervised Cross-contrastive Training
在本节中,我们提出了重加权自监督交叉对比($ReSC$ )训练方案。我们首先应用图数据增强来生成两个图视图,然后同时应用节点对比和社区对比来考虑节点级和社区级的信息。我们引入 node-community 对作为额外的负样本,以解决与负样本在相同的社区中配对节点的问题。
3.2.1 Graph augmentation
属性掩藏
$\widetilde{X}=[X[1,:] \odot \boldsymbol{m} ; \boldsymbol{X}[2,:] \odot \boldsymbol{m} ; \ldots \ldots ; \boldsymbol{X}[N,:] \odot \boldsymbol{m}]^{\prime} \quad\quad\quad(11)$
其中,$m[i] \sim \text { Bernoulli }\left(1-p_{v}\right)$,$\odot $ 代表着 Hadamard product 。
边丢弃
我们通过有概率地从原始边集 $E$ 中随机删除边来生成增广边集 $\widetilde{E}$。
$P\left\{\left(v_{1}, v_{2}\right) \in \widetilde{E}\right\}=1-p_{e}, \forall\left(v_{1}, v_{2}\right) \in E \quad\quad\quad(12)$
上述两种数据增强,本文分别定义为 $t^{1}, t^{2} \sim T$。
使用上述两种数据增强生成两个视图:$\left(X^{1}, A^{1}\right)=t^{1}(X, A)$、$\left(X^{2}, A^{2}\right)=t^{2}(X, A)$。让后通过 GCN 编码器获得他们的表示:$Z^{1}=f_{\theta}\left(X^{1}, A^{1}\right) $ 和 $Z^{2}=f_{\theta}\left(X^{2}, A^{2}\right)$。
3.2.2 Node contrast
在生成两个图视图后,我们同时使用节点对比和社区对比来学习节点表示。我们引入了一个基于InfoNCE[43]的对比损失来对 比节点-节点对:
$I_{N C E}\left(Z^{1} ; Z^{2}\right)=-\log \sum\limits_{i} \frac{\delta\left(Z^{1}[i,:], Z^{2}[i,:]\right)}{\sum_{j} \delta\left(Z^{1}[i,:], Z^{2}[j,:]\right)} \quad\quad\quad(13)$
我们对这两个图的视图对称地应用节点对比度:
$L_{n o d e}=\frac{1}{2}\left[I_{N C E}\left(Z^{1} ; Z^{2}\right)+I_{N C E}\left(Z^{2} ; Z^{1}\right)\right]\quad\quad\quad(14)$
它在两个视图中区分负对,并强制最大化正对[35]之间的一致性。
3.2.3 Community contrast
Community contrast 基于 3.1 DeCA,
首先,我们用 $Eq.10$ 训练随机初始化的社区质心矩阵 $\Phi$,得到社区中心。其次,我们采用一个重新加权的交叉对比目标,将一个视图的节点表示与另一个视图的社区质心进行对比(一种交叉对比的方式)。我们受到[4]中的交叉预测方案的启发,并在InfoNCE目标[43]中引入交叉对比,以最大化两个视图之间的社区一致性,强制使一个社区中的节点表示接近另一个视图中对应社区的节点表示。在形式上,社区对比是由
${\large \begin{array}{l}l_{\text {com }}(Z, \Phi)=-\log \sum_{i} \frac{\delta\left(Z[i,:], \Phi\left[k_{i},:\right]\right)}{\delta\left(Z[i,:], \Phi\left[k_{i},:\right]\right)+\sum_{k_{i} \neq k} w(i, k) \cdot \delta(Z[i,:], \Phi[k,:])}\end{array}} \quad\quad\quad(15)$
其中,第 $i$ 个节点被分配给第 $k_{i}$ 个社区。这里的, $w(i, k)=\exp \left\{-\gamma\|Z[i,:]-\Phi[k,:]\|^{2}\right\}$ 是RBF的权值函数(与 $Eq. 2$ 中的高斯RBF相似度略有不同),这更关注更相似的社区对。在这一目标中,相同社区内的节点表示的相似性最大化,因为它们与相同的质心呈正对比,而在不同的社区中,节点表示被负对比分开。同样,我们对称地计算了生成的两个图视图的对比目标:
$L_{\text {com }}=\frac{1}{2}\left[l_{\text {com }}\left(Z^{1}, \Phi^{2}\right)+l_{\text {com }}\left(Z^{2}, \Phi^{1}\right)\right]\quad\quad\quad(16)$
其中,$Z^{1}$ 和 $\Phi^{2}$ 分别为视图1和视图2的节点表示矩阵。
3.2.4 Joint objective
我们提出用 $\alpha$-衰减系数将 $L_{n o d e}$, $L_{D e C A}$ 和 $L_{\text {com }}$ 结合成一个联合目标:
$L=L_{\text {node }}+\alpha(t) L_{D e C A}+[1-\alpha(t)] L_{\text {com }}\quad\quad\quad(17)$
其中,系数 $\alpha(t)=\exp \{-t / \eta\}$ 会随着训练的进行而顺利衰减($t$ 为epoch)。我们观察到,通过 $DeCA$ 训练,社区分区将稳定在几百个 epoch内,而 $g CooL$ 模型的训练通常需要数千个epoch。为此,我们首先将 $\alpha$-衰减主要应用于训练社区划分,并逐步将重点转移到学习节点表示上。
综上所述,$ReSC$ 的训练过程如 Algorithm 1 所示。

3.3 Adaptation to Multiplex graphs
所提出的 $gCooL$ 框架可以很自然地适应于多重图,并对训练和推理过程进行了一些修改。我们在不同的图视图之间应用对比训练,并考虑了它们之间的依赖性。
3.3.1 Training
在多重图中,我们不再需要通过图增强来生成图视图,因为多重图中的不同视图自然是多重查看的数据。我们建议在每对视图上检测社区()和学习节点表示()。改进后的训练过程如 Algorithm 2 所示。

3.3.2 Inference
4 Experiments
4.1 Experimental Setup
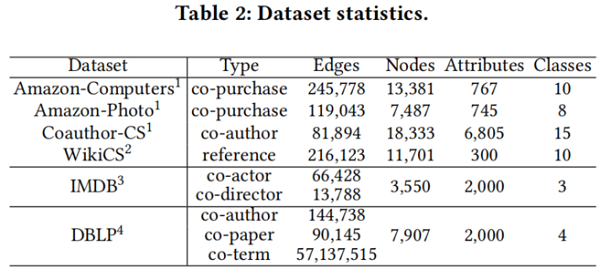
4.1.1 datasets
4.1.2 Evaluation protocol
对于节点分类任务,我们用 Micro-F1 和 Macro-F1 分数来衡量性能。
对于节点聚类任务,我们使用归一化互信息(NMI)评分来衡量性能:
$N M I=2 I(\hat{Y} ; Y) /[H(\hat{Y})+H(Y)]$
其中,$\hat{Y}$ 和 $Y$ 分别为预测的聚类索引和类标签。
Adjusted Rand Index (ARI):
$A R I=R I-\mathbb{E}[R I] /(\max \{R I\}-\mathbb{E}[R I])$
其中, $RI$ 是RandIndex[51],它测量两个集群索引和类标签之间的相似性。
4.1.3 Baselines
- 1) traditional methods including node2vec [13] and DeepWalk [48],
- 2) supervised methods including GCN [28]
- 3) unsupervised methods including MVGRL [16], DGI [59], HDI [21], graph autoencoders (GAE and VGAE) [29] and GCA [78].
- 1) methods with single-view representations including node2vec [13], DeepWalk [48], GCN [28] and DGI [59]
- 2) methods with multi-view representations including CMNA [7], MNE [70], HAN [62], DMGI [44] and HDMI [21].
此外,我们比较了不同的聚类基线,包括K-means、光谱双聚类(SBC)[30]和模块化[42],以显示我们提出的 (指数余弦相似度 $DeCA_{c}$ 和高斯RBF相似度 $D e C A_{e}$) 的有效性。
4.2 Quantitative Results
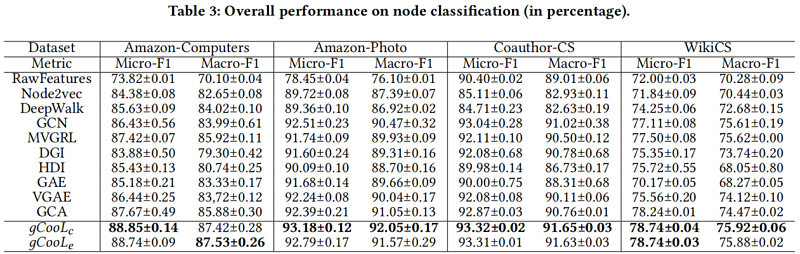
node classification on single-view graphs (Table 3)
node clustering on single-view graphs (Table 4)
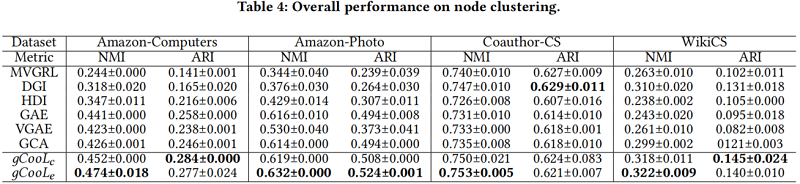
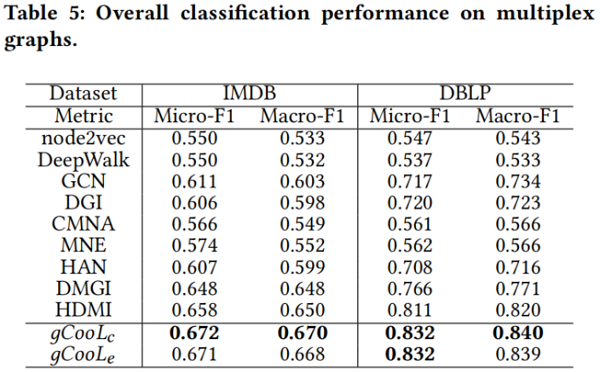
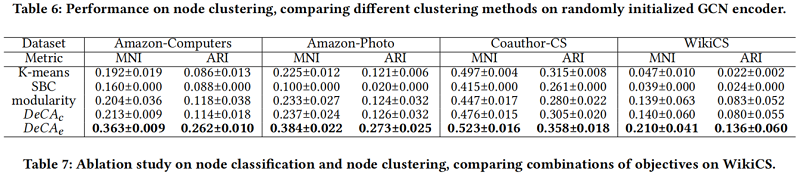
Ablation study
4.3 Visual Evaluations
我们通过可视化所分配社区的边缘密度和类熵来说明的重要性。我们评估每个检查点五次,并显示其平均值和偏差。我们将结果与传统的聚类方法(K-means和光谱双聚类[30])和前模块化[42]进行了比较。我们还可视化了消融研究的节点表示。
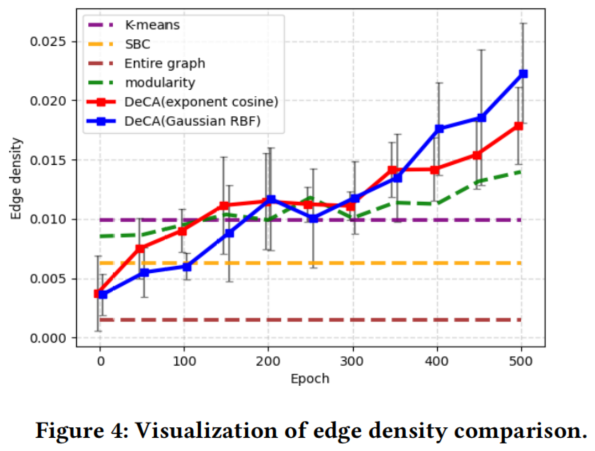
4.3.1 Edge density
边缘密度是基于 $\text{Eq.5}$、按所有社区的平均密度计算:
$E D=\frac{1}{K} \sum\limits _{k=1}^{K} d(k) \quad\quad\quad(18)$
它被用来衡量如何学习社区分区,从而使群落内密度最大化( Section 3.1)。从Fig4可以看出,经过几百个 epochs 后,的性能稳定地优于其他聚类方法。
4.3.2 Class entropy
类熵是对一个社区中类标签的同质性(一个社区包含一个主要类或具有低熵的程度)的度量。我们认为,一个好的社区分区应该区分结构上分离的节点,换句话说,就是区分不同类的节点。类熵计算为所有社区中类标签的平均熵:
$C H=-\frac{1}{K} \sum\limits _{k=1}^{K} \sum\limits_{c} P_{k}(c) \log P_{k}(c) \quad\quad\quad(19)$
其中,$P_{k}(c)$ 为第 $k$ 个社区中第 $c$ 类的出现频率。从 $Fig. 5$ 可以看出,经过几百个 epochs 后,的性能稳定地优于其他聚类方法。
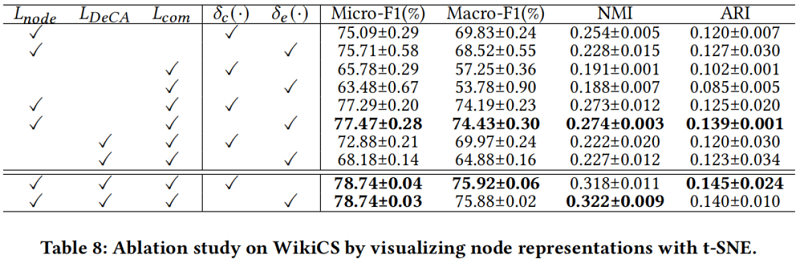
4.3.3 Visualization of node representations
为了了解节点表示是如何分布的,我们使用t-SNE[57]来减少节点表示的维数以进行可视化。当应用和时,每个类的节点表示分别分布更大,这说明了我们所提出的方法的有效性。结果如Table 8 所示。

6 Conclusion
在本文中,我们提出了一种新的图社区对比学习()框架,通过密集的社区聚合()算法来学习结构相关社区的社区划分,并通过考虑社区结构的重加权自监督交叉对比()训练方案来学习图的表示。所提出的在多个任务上始终达到了最先进的性能,并且可以自然地适应于多路图。我们表明,社区信息有利于图表示学习的整体性能。
论文解读(gCooL)《Graph Communal Contrastive Learning》的更多相关文章
- 论文解读(LG2AR)《Learning Graph Augmentations to Learn Graph Representations》
论文信息 论文标题:Learning Graph Augmentations to Learn Graph Representations论文作者:Kaveh Hassani, Amir Hosein ...
- 谣言检测(GACL)《Rumor Detection on Social Media with Graph Adversarial Contrastive Learning》
论文信息 论文标题:Rumor Detection on Social Media with Graph AdversarialContrastive Learning论文作者:Tiening Sun ...
- 论文解读(MVGRL)Contrastive Multi-View Representation Learning on Graphs
Paper Information 论文标题:Contrastive Multi-View Representation Learning on Graphs论文作者:Kaveh Hassani .A ...
- 论文解读(ARVGA)《Learning Graph Embedding with Adversarial Training Methods》
论文信息 论文标题:Learning Graph Embedding with Adversarial Training Methods论文作者:Shirui Pan, Ruiqi Hu, Sai-f ...
- 论文解读(GROC)《Towards Robust Graph Contrastive Learning》
论文信息 论文标题:Towards Robust Graph Contrastive Learning论文作者:Nikola Jovanović, Zhao Meng, Lukas Faber, Ro ...
- 论文解读(GRACE)《Deep Graph Contrastive Representation Learning》
Paper Information 论文标题:Deep Graph Contrastive Representation Learning论文作者:Yanqiao Zhu, Yichen Xu, Fe ...
- 论文解读(MLGCL)《Multi-Level Graph Contrastive Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 论文解读(GCA)《Graph Contrastive Learning with Adaptive Augmentation》
论文信息 论文标题:Graph Contrastive Learning with Adaptive Augmentation论文作者:Yanqiao Zhu.Yichen Xu3.Feng Yu4. ...
- 论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》
论文信息 论文标题:Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning ...
随机推荐
- ubantu14.04系统设置无法正常使用
方法一:执行命令: sudo apt-get install ubuntu-desktop方法二:如果系统设置打不开,请重新安装gnome-control-centersudo apt-get ins ...
- php 实验一 网页设计
实验目的: 1. 能够对整个页面进行html结构设计. 2. 掌握CSS+DIV的应用. 实验内容及要求: ***个人博客网页 参考Internet网上的博客网站,设计自己的个人网页,主要包括:图 ...
- uniapp清理缓存
<template> <view class="content"> <view>应用缓存:{{storageSize}}</view> ...
- 移动端input输入框把页面顶起, 收起键盘页面复原不了问题
我相信大家平时也会遇到这种问题, 移动端 input 或者 textarea获取光标, 整个页面被顶起来, 键盘收起, 页面不复原的问题 ====>>>> 我这边提供两种解决 ...
- Android搞定权限申请
0x00 前言 使用EasyPermissions库进行申请权限 打开App时就申请权限,如果用户拒绝权限后,会循环申请 如果永久拒绝后,会跳转到设置里继续申请 效果图: 注:不讲原理,先教你怎么实现 ...
- vue3响应式模式设计原理
vue3响应式模式设计原理 为什么要关系vue3的设计原理?了解vue3构建原理,将有助于开发者更快速上手Vue3:同时可以提高Vue调试技能,可以快速定位错误 1.vue3对比vue2 vue2的原 ...
- Centos7 搭建 Socks 服务
Centos7 搭建 Socks 服务 一丶拿到一个动态拨号的服务器还不能使用网络得先打开: pppoe-start 二丶安装命令汇总: 通过yum安装ss5 依赖包: yum install gcc ...
- 新手入门C语言第八章:C循环
一.C 循环 有的时候,我们可能需要多次执行同一块代码.一般情况下,语句是按顺序执行的:函数中的第一个语句先执行,接着是第二个语句,依此类推.编程语言提供了更为复杂执行路径的多种控制结构.循环语句允许 ...
- mmdetection 绘制PR曲线
参考:https://github.com/xuhuasheng/mmdetection_plot_pr_curve 适用于COCO数据集 import os import mmcv import n ...
- Vue_基础功能循环、计算、绑定、事件处理、组件
1 <!DOCTYPE html> 2 <html lang="en" xmlns:v-bind="http://www.w3.org/1999/xht ...