HDFS 伪分布式环境搭建
HDFS 伪分布式环境搭建
作者:Grey
原文地址:
相关软件版本
Hadoop 2.6.5
CentOS 7
Oracle JDK 1.8
安装步骤
在CentOS 下安装 Oracle JDK 1.8
将下载好的 JDK 的安装包 jdk-8u202-linux-x64.tar.gz 上传到应用服务器的/tmp目录下
执行以下命令
cd /usr/local && mkdir jdk && tar -zxvf /tmp/jdk-8u202-linux-x64.tar.gz -C ./jdk --strip-components 1
执行下面两个命令配置环境变量
echo "export JAVA_HOME=/usr/local/jdk" >> /etc/profile
echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile
然后执行
source /etc/profile
验证 JDK 是否安装好,输入
java -version
显示如下内容
'java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
JDK 安装成功。
创建如下目录:
mkdir /opt/bigdata
将 Hadoop 安装包下载至/opt/bigdata目录下
下载方式一
执行:yum install -y wget
然后执行如下命令:cd /opt/bigdata/ && wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
下载方式二
如果报错或者网络不顺畅,可以直接把下载好的安装包上传到/opt/bigdata/目录下
配置静态ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
内容参考如下内容修改
修改BOOTPROTO="static"
新增:
IPADDR="192.168.150.137"
NETMASK="255.255.255.0"
GATEWAY="192.168.150.2"
DNS1="223.5.5.5"
DNS2="114.114.114.114"
然后执行service network restart
设置主机名vi /etc/sysconfig/network
设置为
NETWORKING=yes
HOSTNAME=node01
注:HOSTNAME 自己定义即可,主要要和后面的 hosts 配置中的一样。
设置本机的ip到主机名的映射关系:vi /etc/hosts
192.168.150.137 node01
注:IP 根据你的实际情况来定
重启网络service network restart
执行如个命令,关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
firewall-cmd --reload
service iptables stop
chkconfig iptables off
关闭 selinux:执行vi /etc/selinux/config
设置
SELINUX=disabled
做时间同步yum install ntp -y
修改配置文件vi /etc/ntp.conf
加入如下配置:
server ntp1.aliyun.com
启动时间同步服务
service ntpd start
加入开机启动
chkconfig ntpd on
SSH 免密配置,在需要远程到这个服务器的客户端中
执行ssh localhost
依次输入:yes
然后输入:本机的密码
生成本机的密钥和公钥:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
在服务器上配置免密:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
在客户端再次执行ssh localhost
发现可以免密登录,不需要输入密码了
接下来安装 hadoop 安装包,执行
cd /opt/bigdata && tar xf hadoop-2.6.5.tar.gz
然后执行:
mv hadoop-2.6.5 hadoop
添加环境变量vi /etc/profile
加入如下内容:
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/opt/bigdata/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后执行source /etc/profile
Hadoop 配置
执行vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
配置 JAVA_HOME
export JAVA_HOME=/usr/local/jdk
执行vi $HADOOP_HOME/etc/hadoop/core-site.xml
在<configuration></configuration>节点内配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
执行vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
在<configuration></configuration>节点内配置
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/local/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/local/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name> <value>/var/bigdata/hadoop/local/dfs/secondary</value>
</property>
执行vi $HADOOP_HOME/etc/hadoop/slaves
配置为node01
初始化和启动 HDFS,执行
hdfs namenode -format
创建目录,并初始化一个空的fsimage
如果你使用windows作为客户端,那么需要配置 hosts 条目
进入C:\Windows\System32\drivers\etc
在 host 文件中增加如下条目:
192.168.241.137 node01
注:ip 地址要和你的服务器地址一样
启动 hdfs
执行start-dfs.sh
输入: yes
第一次启动,datanode 和 secondary 角色会初始化创建自己的数据目录
并在命令行执行:
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root
通过 hdfs 上传文件:
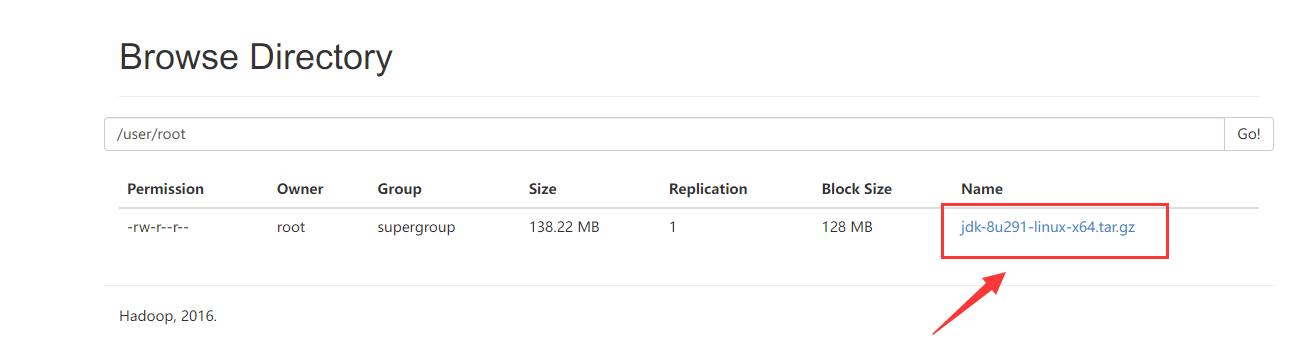
hdfs dfs -put jdk-8u291-linux-x64.tar.gz /user/root
通过:http://node01:50070/explorer.html#/user/root
可以看到上传的文件
参考资料
Hadoop MapReduce Next Generation - Setting up a Single Node Cluster.
HDFS 伪分布式环境搭建的更多相关文章
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- HDFS伪分布式环境搭建
(一).HDFS shell操作 以上已经介绍了如何搭建伪分布式的Hadoop,既然环境已经搭建起来了,那要怎么去操作呢?这就是本节将要介绍的内容: HDFS自带有一些shell命令,通过这些命令我们 ...
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- 【Hadoop】伪分布式环境搭建、验证
Hadoop伪分布式环境搭建: 自动部署脚本: #!/bin/bash set -eux export APP_PATH=/opt/applications export APP_NAME=Ares ...
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- Hadoop 2.7 伪分布式环境搭建
1.安装环境 ①.一台Linux CentOS6.7 系统 hostname ipaddress subnet mask ...
- hive-2.2.0 伪分布式环境搭建
一,实验环境: 1, ubuntu server 16.04 2, jdk,1.8 3, hadoop 2.7.4 伪分布式环境或者集群模式 4, apache-hive-2.2.0-bin.tar. ...
随机推荐
- 数字图像处理-基于matlab-直方图均匀化,傅立叶变换,图像平滑,图像锐化
直方图均匀化 任务:用MATLAB或VC或Delphi等实现图像直方图均匀化的算法. clc;clear;close all; % 清除工作台 % path(path,'..\pics'); % 设置 ...
- 自己封装的tools.js文件
/* * 生成指定范围的随机整数 * @param lower 下限 * @param upper 上限 * @return 返回指定范围的随机整数,上/下限值均可取 */ function rand ...
- 「快速学习系列」我熬夜整理了Vue3.x响应性API
前言 Vue3.x正式版发布已经快半年了,相信大家也多多少少也用Vue3.x开发过项目.那么,我们今天就整理下Vue3.x中的响应性API.响应性APIreactive 作用: 创建一个响应式数据. ...
- C# · 委托语句简化演变
1.委托基础语句形式 namespace QLVision { delegate void dHelp();//定义委托 static class Program { /// <summary& ...
- 【python基础】第04回 变量常量
本章内容概要 1. python 语法注释 2. python 语法之变量常量 3. python 基本数据类型(整型(int),浮点型(float),字符串(str)) 本章内容详解 1. pyth ...
- rhel挂载本地光盘为yum源
挂载光盘 mount /dev/sr0 /mnt/cdrom mkdir /mnt/cdrom 临时挂载 mount /dev/sr0 /mnt/cdrom 永久挂载光盘 mount -a 执行挂载 ...
- MySQL case when then 用法
下面演示一下MYSQL中的CASE WHEN THEN的用法. 一. SELECT MENU_NAME, YXBZ, case YXBZ when 'Y' then '开放' when 'N' the ...
- C# Winform程序界面优化实例
进入移动互联网时代以来,Windows桌面开发已经很久不碰了.之前就是从做Windows开发入行的. 当年,还是C++ VC6, MFC的时代.那时候开发要查的是MSDN :-).内存要自己管理, 排 ...
- Codeforces Round #789 (Div. 2)
题集链接 A. Tokitsukaze and All Zero Sequence 题意 Tokitsukaze 有一个长度为 n 的序列 a. 对于每个操作,她选择两个数字 ai 和 aj (i≠j ...
- 意想不到的Python ttkbootstrap 制作账户注册信息界面
嗨害大家好,我是小熊猫 今天给大家来整一个旧活~ 前言 ttkbootstrap 是一个基于 tkinter 的界面美化库,使用这个工具可以开发出类似前端 bootstrap 风格的tkinter 桌 ...