采用Kettle分页处理大数据量抽取任务
作者:Grey
原文地址: http://greyzeng.com/2016/10/31/big-data-etl/
需求:
将Oracle数据库中某张表历史数据导入MySQL的一张表里面。
源表(Oracle):table1
目标表(MySQL):table2
数据量:20,000,000
思路:
由于服务器内存资源有限,所以,无法使用Kettle一次性从源表导入目标表千万级别的数据,考虑采用分页导入的方式来进行数据传输,即:
根据实际情况设置一个每次处理的数据量,比如:5,000条,然后根据总的数据条数和每次处理的数据量计算出一共分几页,
假设总数据量有:20,000,000,所以页数为:20,000,000/5,000=4,000页
注: 若存在小数,小数部分算一页,比如:20.3算21页
步骤:
根据需求的条件,首先对数据进行分页:
数据量:20,000,000
每页数据量:5,000
页数:4,000
源表(Oracle):table1
目标表(MySQL):table2
主流程:transfer_table1_to_table2.kjb

流程说明:
transfer_table1_to_table2.kjb: 主流程
build_query_page.ktr: 构造页数游标
loop_execute.kjb: 根据页数来执行数据导入操作
我们分别来看各个部分的构成:
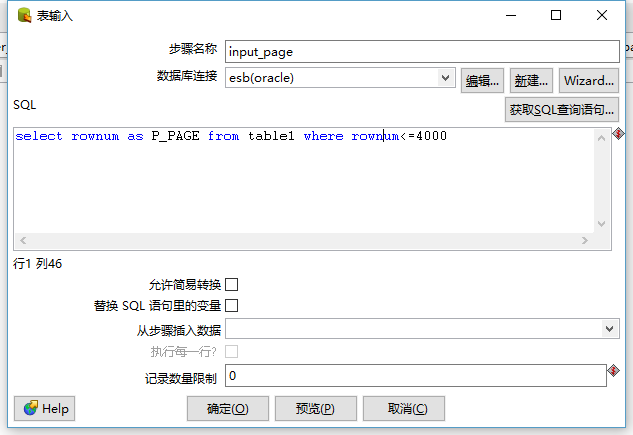
build_query_page.ktr: 构造页数游标
这一步中,我们需要构造一个类似这样的数据结构:

其中P_PAGE是表头,其余为页码数,
注: 在这里取页码数我通过这个表的rownum来构造
SQL:
select
rownum
as P_PAGE from mds.mds_balances_hist where
rownum<=4000
具体实现如下图:



loop_execute.kjb: 根据页数来执行数据导入操作
在上一步中,我们构造了页数,在这步中,我们遍历上一步中的页码数,通过页码数找出相应的数据集进行操作,
其中包括set_values.ktr和execute_by_page.ktr两个转换
loop_execute.kjb具体实现如下:

set_values.ktr:表示获取从上一步中获得的页数

execute_by_page.ktr:表示根据页数进行数据导入操作
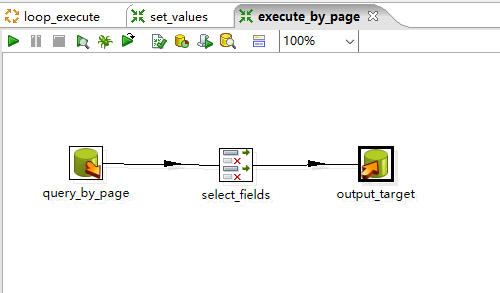
其中query_by_page采用Oracle经典三层嵌套分页算法:
SELECT b.rn,b.* FROM
(
SELECT A.*, ROWNUM RN
FROM (SELECT * FROM table1) A
WHERE
ROWNUM <= (${VAR_P_PAGE}*5000)
) b
WHERE RN >= ((${VAR_P_PAGE}-1)*5000+1)

注: ${VAR_P_PAGE}为每次获取的页码数。
select_field为设置需要导入的列名:


output_target目的是输出到目标表table2:

因为要遍历上一次执行的结果,那么需要在transfer_table1_to_table2.kjb的loop_execute.kjb中做如下设置:

最后,执行transfer_table1_to_table2.kjb即可。
总结:
通过上述方法,我们可以很好的解决内存不足的情况下,大数据量在不同的数据库之间的导入工作。
FAQ:
- 在Kettle导入大量数据的过程中,可能会出现连接断开的现象:
http://forums.pentaho.com/showthread.php?74102-MySQL-connection-settings-at-java-level
(Idle connection timeout if we keep kettle idle for 8hours).
解决办法:

采用Kettle分页处理大数据量抽取任务的更多相关文章
- MySQL分页查询大数据量优化方法
方法1: 直接使用数据库提供的SQL语句 语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N适应场景: 适用于数据量较少的情况(元组百/千级)原因/缺点: ...
- 参考 ZTree 加载大数据量。加载慢问题解析
参考 ZTree 加载大数据量. 1.一次性加载大数据量加载说明 1).zTree v3.x 针对大数据量一次性加载进行了更深入的优化,实现了延迟加载功能,即不展开的节点不创建子节点的 DOM. 2) ...
- 大数据量报表APPLET打印分页传输方案
1 . 问题概述 当报表运算完成时,客户端经常需要调用润乾自带的runqianReport4Applet.jar来完成打印操作, 然而数据量比较大的时候,会导致无法加载完成,直至applet内存 ...
- 大数据量下,分页的解决办法,bubuko.com分享,快乐人生
大数据量,比如10万以上的数据,数据库在5G以上,单表5G以上等.大数据分页时需要考虑的问题更多. 比如信息表,单表数据100W以上. 分页如果在1秒以上,在页面上的体验将是很糟糕的. 优化思路: 1 ...
- MySQL大数据量快速分页实现(转载)
在mysql中如果是小数据量分页我们直接使用limit x,y即可,但是如果千万数据使用这样你无法正常使用分页功能了,那么大数据量要如何构造sql查询分页呢? 般刚开始学SQL语句的时候,会这 ...
- MySQL大数据量分页查询
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- mysql大数据量下的分页
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
随机推荐
- log4net入门
简介 几乎所有的大型应用都会有自己的用于跟踪调试的API.因为一旦程序被部署以后,就不太可能再利用专门的调试工具了.然而一个管理员可能需要有一套强大的日志系统来诊断和修复配置上的问题. 经验表明,日志 ...
- 使用XtraReport的CalculatedFiled(计算字段)实现RDLC报表中表达式
DevExpress报表确实强大,花样繁多,眼花缭乱. 这次使用XtraReport开发报表,很多问题在官方的文档中并没有详细的说明,特此记录. 1.XtraReport中FormattingRule ...
- [.net 面向对象编程基础] (23) 结束语
[.net 面向对象编程基础] (23) 结束语 这个系列的文章终于写完了,用了半个多月的时间,没有令我的粉丝们失望.我的感觉就是一个字累,两个字好累,三个字非常累.小伙伴们看我每篇博客的时间就知道 ...
- 在.net中使用aquiles访问Cassandra(三)
之前我们实现了如何修改数据,还需要相应的删除动作.删除方式会有几种情况,以下分别一一介绍. 1.批量删除,适应于多行多列的情况. public void Remove(string columnF ...
- Android自定义View的构造函数
自定义View是Android中一个常见的需求,每个自定义的View都需要实现三个基本的构造函数,而这三个构造函数又有两种常见的写法. 第一种 每个构造函数分别调用基类的构造函数,再调用一个公共的初始 ...
- [我给Unity官方视频教程做中文字幕]beginner Graphics – Lessons系列之灯光介绍Lights
[我给Unity官方视频教程做中文字幕]beginner Graphics – Lessons系列之灯光介绍Lights 既上一篇分享了中文字幕的摄像机介绍Cameras后,本篇分享一下第2个已完工的 ...
- Senparc.Weixin.MP SDK 微信公众平台开发教程(八):通用接口说明
一.基础说明 这里说的“通用接口(CommonAPIs)”是使用微信公众账号一系列高级功能的必备验证功能(应用于开发模式). 我们通过微信后台唯一的凭证,向通用接口发出请求,得到访问令牌(Access ...
- fir.im Weekly - 从零开始,搭建理想的直播平台
2016年苹果发布会如期而至,新一代的 iPhone 7, Apple Watch 同时亮相,可惜大家期待的 MacBookPro.AR.VR产品并未出现.不论大家对新产品是"买买买&quo ...
- 快速入门系列--JMeter压测工具
今天的年会已过,仍然是空手而归,不过俺坚信能让生活稳定永远都是努力.由于隔壁组负责年会的抢红包项目,因而趁此机会把通过工具模拟高并发的知识补了补,通过和身边大师的交流,总算是对压力测试有了个简要的了解 ...
- C# List.ForEach 方法
C#中List.ForEach 方法是对 List 的每个元素执行指定操作. 示例: using System; using System.Collections.Generic; using Sys ...