索引深入浅出(5/10):非聚集索引的B树结构在堆表
在“索引深入浅出:非聚集索引的B树结构在聚集表”里,我们讨论了在聚集表上的非聚集索引,这篇文章我们讨论下在堆表上的非聚集索引。
非聚集索引可以在聚集表或堆表上创建。当我们在聚集表上创建非聚集索引时,聚集索引键担当为行指针。在堆表里,文件号,页号和槽号(file id , page number and slot number)的组合在非聚集索引里担当为行指针。
我们来看下手头的一个例子。我们创建salesorderdetail表的副本,并在上面的productid和salesorderid 列创建创建非聚集索引。
DROP TABLE SalesOrderDetailHeap SELECT * INTO dbo.SalesOrderDetailHeap FROM AdventureWorks2008r2.Sales.SalesOrderDetail
GO
CREATE UNIQUE INDEX Ix_ProductId ON SalesOrderDetailHeap(ProductId,Salesorderid)
收集非聚集索引相关信息:
TRUNCATE TABLE dbo.sp_table_pages
INSERT INTO sp_table_pages EXEC('DBCC IND(IndexDB,SalesOrderDetailHeap,2)')
GO SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC --根节点/索引页
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3720,3) DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3608,3)--叶子节点/索引页 DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3908,3)--叶子节点/索引页
SELECT * FROM dbo.sp_table_pages WHERE IndexLevel=0 --叶子节点/索引页
根据上述信息进行非聚集索引逻辑示意图的绘制:
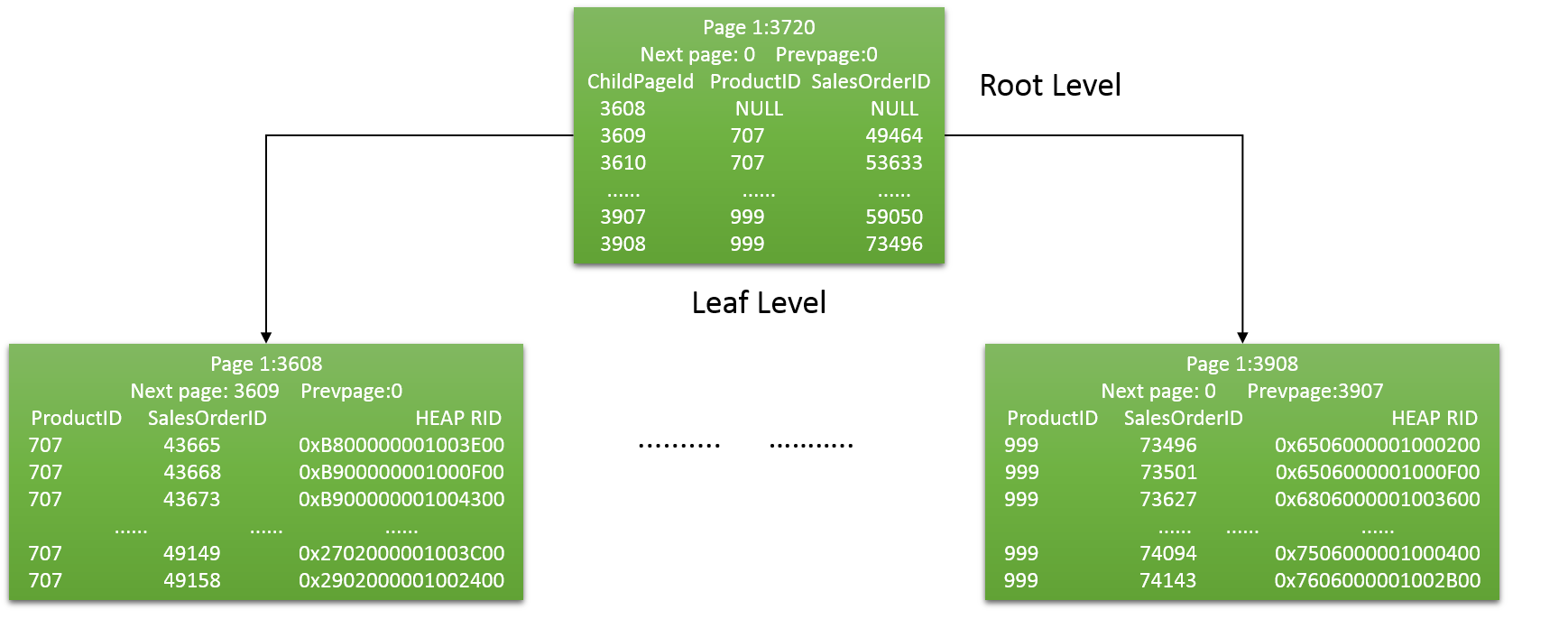
现在我们来分析下SQL Server如何存储堆表的非聚集索引,首先我们通过DBCC IND命令查看非聚集索引的页分配情况,最后一个参数,2是Ix_ProductId的索引号。
DBCC ind('IndexDB','SalesOrderDetailHeap',2)
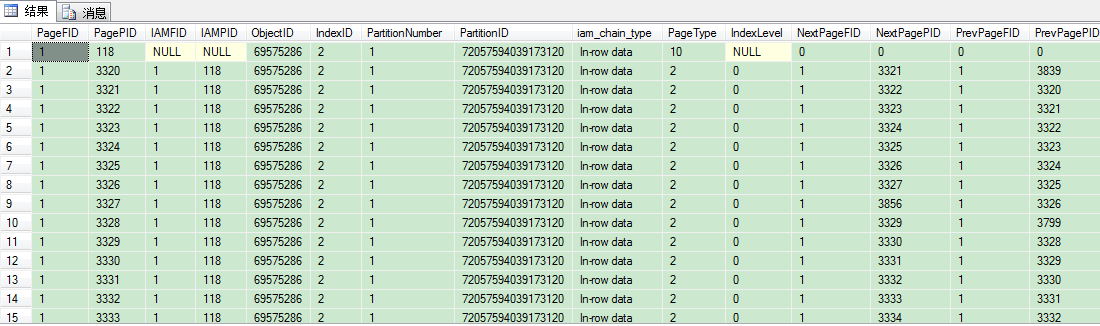

一共返回298条记录,包括1个IAM页,288个索引页,我们用下列语句找下根层的页号:
SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC

可以看到,indexlevel列最大值1的页号是3270,这个页就是根页,因为indexlevel列最大值是1,所以这个堆表的非聚集索引的B树结构只有2层,即根层和叶子层,也就是说288个索引页中,1个页是根层的根页(也是索引页),287个页是叶子层的索引页。我们来看看3270页的信息。
DBCC TRACEON(3604)
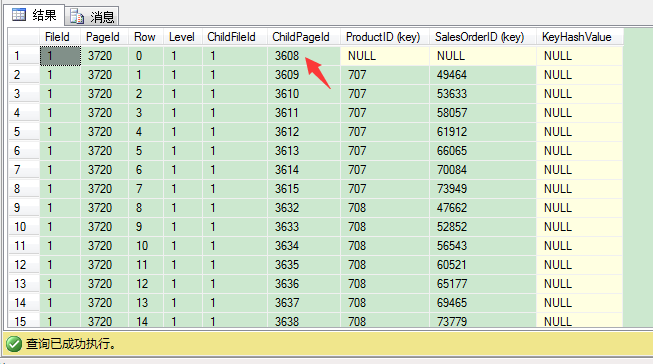
DBCC PAGE(IndexDB,1,3720,3)
输出结果,和聚集表里的非聚集索引的根页结构是一样的。
我们来看看叶子层的3608页。
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3608,3)--叶子节点/索引页
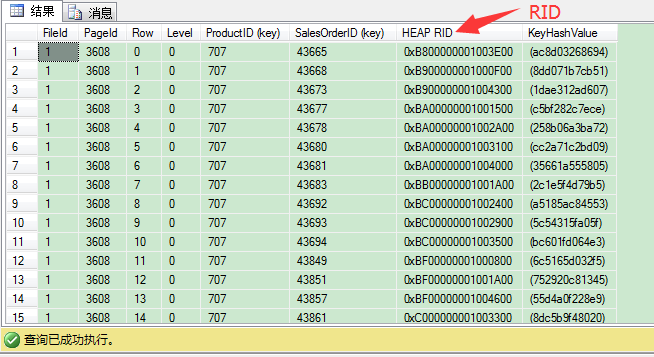
在聚集表的非聚集索引的叶子层,聚集键与非聚集键一齐加入了叶子层的页。这里我们没有聚集索引,索引SQL Server加了个行标识号(8 bytes大小),由文件号(2 bytes),页号(4 bytes)和槽号(2 bytes)组合而成。
从上图我们可以清楚看出,productid值为707,salesorderid值为43665的记录完整信息,可以在HeapRID 0xB800000001003E00位置找到。下面的查询可以帮我们把RID转为文件号:页号:槽号(FileId:PageId:SlotNo)格式。
DECLARE @HeapRid BINARY(8)
SET @HeapRid = 0xB800000001003E00
SELECT
CONVERT (VARCHAR(5),
CONVERT(INT, SUBSTRING(@HeapRid, 6, 1)
+ SUBSTRING(@HeapRid, 5, 1)))
+ ':'
+ CONVERT(VARCHAR(10),
CONVERT(INT, SUBSTRING(@HeapRid, 4, 1)
+ SUBSTRING(@HeapRid, 3, 1)
+ SUBSTRING(@HeapRid, 2, 1)
+ SUBSTRING(@HeapRid, 1, 1)))
+ ':'
+ CONVERT(VARCHAR(5),
CONVERT(INT, SUBSTRING(@HeapRid, 8, 1)
+ SUBSTRING(@HeapRid, 7, 1)))
AS 'Fileid:Pageid:Slot'

1:184:62表示文件号:1 ,页号:184 ,槽号:62。我们来看看184页。
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,184,3)
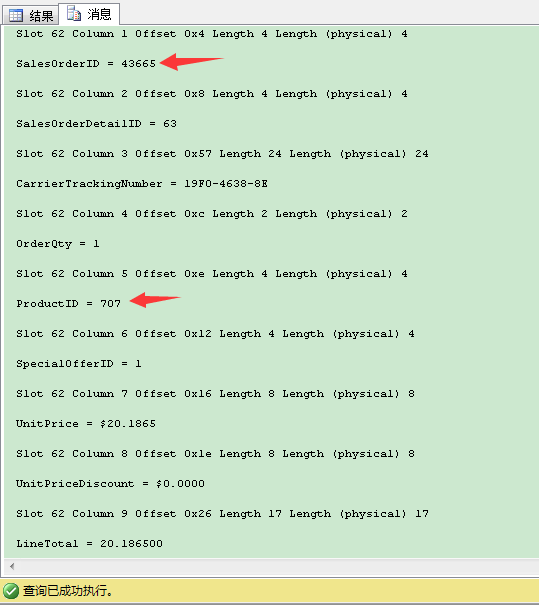
从输出我们可以看到,productid值为707,salesorderid值为43665的记录所有列可以在槽号62找到,与1:184:62表示文件号:1 ,页号:184 ,槽号:62完全一致。
我们通过下面的查询看看SQL Server如何使用非聚集索引查找堆表上的数据,点击工具栏的 显示包含实际的执行计划。
显示包含实际的执行计划。
SET STATISTICS IO ON
GO
SELECT * FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665

SQL Server需要进行2次I/O操作到达非聚集索引的叶子层,1次I/O操作通过使用RID查找(堆)拿到剩下的数据。执行计划如下所示:
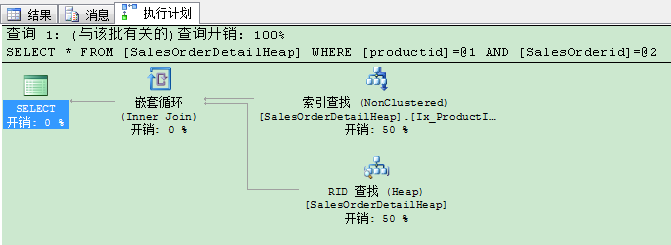
即使我们将查询语句修改为,只要 ProductId,SalesOrderid,SalesorderDetailId 这3列,SQL Server还是要进行键查找(Key lookup)操作。
SET STATISTICS IO ON
GO
SELECT * FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665 SET STATISTICS IO ON
GO
SELECT ProductId,SalesOrderid,SalesOrderDetailID FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665

这是因为,SalesorderDetailId列没有定义为聚集键,在非聚集索引的叶子层没有这列。为了避免键查找(key lookup)操作,我们需要将列限制到只有非聚集索引键(ProductKey ,salesorderid)。
SET STATISTICS IO ON
GO
SELECT ProductId,SalesOrderid FROM SalesOrderDetailHeap WHERE productid=707 AND SalesOrderid=43665

如上图所示,只有非聚集索引查找操作,没有键查找(Key lookup)操作了。
参考文章:
索引深入浅出(5/10):非聚集索引的B树结构在堆表的更多相关文章
- 索引深入浅出(3/10):聚集索引的B树结构
在SQL Server里,有2种表是以存储为基础的.有聚集索引的表叫聚集表,没有聚集索引的表叫堆表.在上一篇文章,我们讨论了堆表的特性和存储结构.在这篇文章里,我们来看下聚集表. 有聚集索引的表叫聚集 ...
- SQL Server中的聚集索引(clustered index) 和 非聚集索引 (non-clustered index)
本文转载自 http://blog.csdn.net/ak913/article/details/8026743 面试时经常问到的问题: 1. 什么是聚合索引(clustered index) / ...
- 索引深入浅出(4/10):非聚集索引的B树结构在聚集表
一个表只能有一个聚集索引,数据行以此聚集索引的顺序进行存储,一个表却能有多个非聚集索引.我们已经讨论了聚集索引的结构,这篇我们会看下非聚集索引结构. 非聚集索引的逻辑呈现 简单来说,非聚集索引是表的子 ...
- InnoDB 聚集索引和非聚集索引、覆盖索引、回表、索引下推简述
关于InnoDB 存储引擎的有聚集索引和非聚集索引,覆盖索引,回表,索引下推等概念,这些知识点比较多,也比较零碎,但是概念都是基于索引建立的,本文从索引查找数据讲述上述概念. 聚集索引和非聚集索引 在 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(下)
SQLSERVER聚集索引与非聚集索引的再次研究(下) 上篇主要说了聚集索引和简单介绍了一下非聚集索引,相信大家一定对聚集索引和非聚集索引开始有一点了解了. 这篇文章只是作为参考,里面的观点不一定正确 ...
- SQL Server临界点游戏——为什么非聚集索引被忽略!
当我们进行SQL Server问题处理的时候,有时候会发现一个很有意思的现象:SQL Server完全忽略现有定义好的非聚集索引,直接使用表扫描来获取数据.我们来看看下面的表和索引定义: CREATE ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQLServer之创建唯一非聚集索引
创建唯一非聚集索引典型实现 唯一索引可通过以下方式实现: PRIMARY KEY 或 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自 ...
- 浅谈sql server聚集索引与非聚集索引
今天同事的服务程序在执行批量插入数据操作时,会超时失败,代码debug了几遍一点问题都没有,SQL单条插入也可以正常录入数据,调试了一上午还是很迷茫,场面一度很尴尬,最后还是发现了问题的根本,原来是另 ...
随机推荐
- c语言编译器(linux平台下安装c语言环境)一
gcc : 语言的默认编译器 (ubuntu下输入gcc,可根据终端输出查看是否安装了gcc) g++ : c++的默认编译器 (ubuntu下输入g++,可根据终端输出查看是否安装了g+ ...
- Http压力测试工具HttpTest4Net
HttpTest4Net是一款基于C#实现的和HTTP压力测试工具,通过工具可以简单地对HTTP服务进行一个压力测试.虽然VS.NET也集成了压力测试项目,但由于VS自身占用的资源导致了在配置不高的P ...
- NetMq学习--发布订阅(一)
基于NeqMq 4.0.0-rc5版本发布端: using (var publisher = new PublisherSocket()) { publisher.Bind("tcp://* ...
- Linux(CentOS 6.5)下配置Mono和Jexus并且部署ASP.NET MVC5
1.开篇说明 a. 首先我在写这篇博客之前,已经在自己本地配置了mono和jexus并且成功部署了asp.net mvc项目,我也是依赖于在网上查找的各种资料来配置环境并且部署项目的,而其在网上也已有 ...
- 从一个简单例子来理解js引用类型指针的工作方式
<script> var a = {n:1}; var b = a; a.x = a = {n:2}; console.log(a.x);// --> undefined conso ...
- Win10 UWP开发中的重复性静态UI绘制小技巧 1
介绍 在Windows 10 UWP界面实现的过程中,有时会遇到一些重复性的.静态的界面设计.比如:画许多等距的线条,画一圈时钟型的刻度线,同特别的策略排布元素,等等. 读者可能觉得这些需求十分简单, ...
- 使用ACE_Get_Opt解析命令行
当我们用C++开发一些C++控制台小工具时,会需要一些用户输入的参数来决定程序如何工作和执行,而用户输入参数的方式大部分都是采用命令行参数的方式. 比如上一篇文章 玩转Windows服务系列--命令行 ...
- java提高篇(四)-----理解java的三大特性之多态
面向对象编程有三大特性:封装.继承.多态. 封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据.对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法. 继承 ...
- 像素图的实时光照 Lighting on Pixel Art
去年有这样一个工具,We got one toolkit last year. 他有什么功能呢?What is its function? 让你画出各个方向的照明图 That you can draw ...
- Windows 安装 MongoDB 服务
第一步 以管理员权限打开命令提示符 按Windows+R键(Ctrl和Alt中间的那个,有微软Logo的键),输入cmd打开命令提示符 第二步 创建数据库目录. 使用mkdir命令,创建数据库的目录和 ...