环境搭建 Hadoop+Hive(orcfile格式)+Presto实现大数据存储查询一
一、前言
Hadoop简介
Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰富,包括ZooKeeper,Pig,Chukwa,Hive,Hbase,Mahout,flume等.接下来我们使用的是Hive
Hive简介
Hive 是一个基于 Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。 它把海量数据存储于 hadoop 文件系统,而不是数据库,但提供了一套类数据库的数据存储和处理机制,并采用 HQL (类 SQL )语言对这些数据进行自动化管理和处理。我们可以把 Hive 中海量结构化数据看成一个个的表,而实际上这些数据是分布式存储在 HDFS 中的。 Hive 经过对语句进行解析和转换,最终生成一系列基于 hadoop 的 map/reduce 任务,通过执行这些任务完成数据处理。
Presto简介
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。Presto支持在线数据查询,包括Hive, Cassandra, 关系数据库以及专有数据存储。 一条Presto查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
二、环境准备
Hadoop2.X
apache-hive-2.1.0
presto-server-0.156.tar.gz
Mysql5.7
三、速度测试
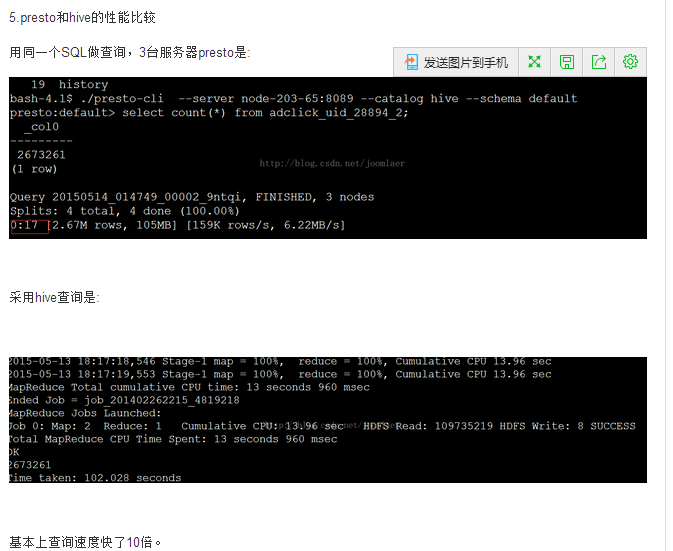
四、本机服务器准备
虚拟机使用linux的centos
Hadoop 192.168.209.142,192.168.209.140
hive 192.168.209.140
presto 192.168.209.140
mysql 10.0.0.7
五、环境搭建
1.Hadoop环境搭建<略>
2.Hive环境搭建
解压Hive文件
[root@HDP134 ~]# tar -zxvf /home/hive/apache-hive-2.1.0-bin.tar.gz
配置hive
[root@HDP134 ~]# vi /etc/profile
因为HIVE用到了Hadoop需要在最下边加上hadoop和Hive的路径
#Hadoop
export HADOOP_INSTALL=/opt/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export HADOOP_HOME=$HADOOP_INSTALL
#Hive
export HIVE_HOME=/home/hive/apache-hive-2.1.0-bin
export PATH=$PATH:$HIVE_HOME/bin
保存退出之后进入配置文件,复制并生命名hive-env.sh,hive-site.xml
[root@HDP134 ~]# cd /home/hive/apache-hive-2.1.0-bin/conf
[root@HDP134 ~]# cp hive-env.sh.template hive-env.sh
[root@HDP134 ~]# cp hive-default.xml.template hive-site.xml
配置hive-site.xml
替换hive-site.xml文件中的 ${system:java.io.tmpdir} 和 ${system:user.name}

默认情况下, Hive的元数据保存在了内嵌的 derby 数据库里, 但一般情况下生产环境使用 MySQL 来存放 Hive 元数据。
继续修改Hive-site.xml配置Mysql
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property>
保存退出
由于Hive要使用Hadoop,所以以下所有操作均是在hadoop用户下操作先为Hadoop赋值目录权限使用如下命令
chown -R hadoop:hadoop /home/hive
切换用户

在 Hive 中创建表之前需要使用以下 HDFS 命令创建 /tmp 和 /user/hive/warehouse (hive-site.xml 配置文件中属性项 hive.metastore.warehouse.dir 的默认值) 目录并给它们赋写权限。

至此基本配置已经完成,可以运行Hive了,运行Hive之前需要先开启Hadoop.

从 Hive 2.1 版本开始, 我们需要先运行 schematool 命令来执行初始化操作。

执行成功之后,可以查看自己的Mysql,我刚配置的mysql库为Hive,我们可以进行MYSQL执行show databases;查看是否已经创建hive数据库

我们可以看到已经自动生成了很多表。说明Hive已成功连接Mysql
我们来运行一下Hive,直接输入hive命令,即可(一定要是在hadoop下操作,不然会报一些无权限的一大堆错误)
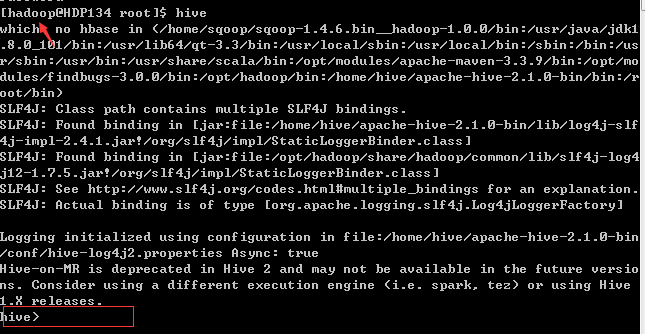
hive已启动,我们可以执行一下show tables;查看一下;
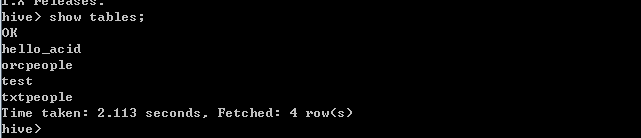
至此hive已安装完成,后边会说到如何创建一个orcfile格式的文件。
3.Presto安装
首先解压下载好的tar.gz包

配置presto
进入etc文件,我们总共需要创建并配置5个文件

除去hadoop那个文件夹,另外的5个下边一一说明
node.properties:每个节点的环境配置
jvm.config:jvm 参数
config.properties:配置 Presto Server 参数
log.properties:配置日志等级
Catalog Properties:Catalog 的配置
1>node.properties配置

节点配置node.id=1
切记:每个节点不能重复我本地把协调和生产节点部署到了一起
2>config.properties

discover.uri是服务地址,http://HDP134:8080是我192.168.209.140的映射
3>catalog hive.properties的配置

connector.name是连接器,我们就用Hive-cdh5
4>jvm.config配置
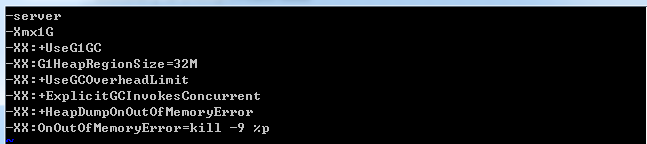
这个可以根据自己的机器配置进行相应调整
5>log.properties配置

配置完成之后,可以运行presto服务了,前提是要先为hadoop赋值目录权限,使用如下命令
chown -R hadoop:hadoop /home/presto
presto服务的启动方式有两种,第一种是strat后台运行看不到日志输出 ,run前台运行,可在前台看到打印日志,建议前期使用run进行前台运行

同样的,要使用hadoop用户启动服务
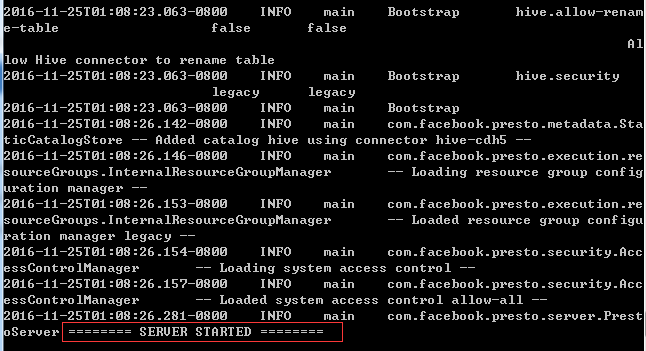
当出现这样的关键词时,恭喜搭建完成
接下来可以测试一下,我们使用一个工具presto-cli-0.90-executable.jar 下载之后,重命名为presto-cli
启动Hive服务
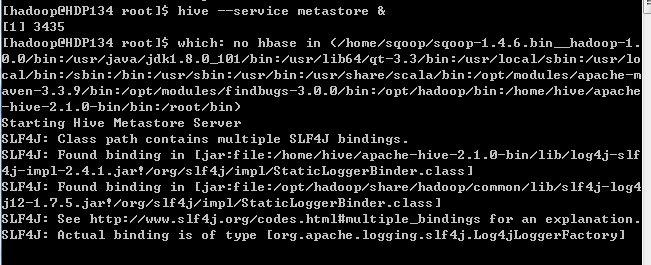
Presto客户端连接

连接Hive库,并进入如上命令行,可以执行一下show tables;进行测试
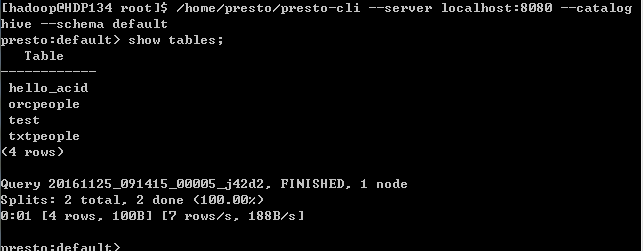
可以显示出hive的所有表,表示presto连接Hive成功
今天就先写到这里,接下来会写创建一个orcfile的几种方法,包括从txtfile转成orcfile,另一种是通过jdbc直接生成orcfile。
以上纯属自己的理解以及本地部署的过程,如果有什么地方有误敬请谅解!
环境搭建 Hadoop+Hive(orcfile格式)+Presto实现大数据存储查询一的更多相关文章
- 基于Docker搭建Hadoop+Hive
为配合生产hadoop使用,在本地搭建测试环境,使用docker环境实现(主要是省事~),拉取阿里云已有hadoop镜像基础上,安装hive组件,参考下面两个专栏文章: 克里斯:基于 Docker 构 ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- 比hive快10倍的大数据查询利器presto部署
目前最流行的大数据查询引擎非hive莫属,它是基于MR的类SQL查询工具,会把输入的查询SQL解释为MapReduce,能极大的降低使用大数据查询的门槛, 让一般的业务人员也可以直接对大数据进行查询. ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- Hadoop学习总结(1)——大数据以及Hadoop相关概念介绍
一.大数据的基本概念 1.1.什么是大数据 大数据指的就是要处理的数据是TB级别以上的数据.大数据是以TB级别起步的.在计算机当中,存放到硬盘上面的文件都会占用一定的存储空间,例如: 文件占用的存储空 ...
- 从 RAID 到 Hadoop Hdfs 『大数据存储的进化史』
我们都知道现在大数据存储用的基本都是 Hadoop Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdf ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- 手把手教你搭建hadoop+hive测试环境(新手向)
本文由 网易云发布. 作者:唐雕龙 本篇文章仅限内部分享,如需转载,请联系网易获取授权. 面向新手的hadoop+hive学习环境搭建,加对我走过的坑总结,避免大家踩坑. 对于hive相关docke ...
随机推荐
- kuangbin_SegTree I (HDU 1540)
做完D之后我信誓旦旦以为之后就只剩一个二维就能攻克线段树了 看来也跟图论一样全是模板嘛 然后我打开了I题一眼看下去似乎直接用线段树记录sum然后跟区间长度比较然后处理一下实现也不难 两个小时后:特么的 ...
- [Thinking in Java]这些必须先了解
2.基本概念和认识 2.1 Java引用 Java中一切皆是对象,一切对象实例的标识符号(对象名称)都只是对象的引用. 2.2 对象的创建 通过new关键字创建,但是要注意基础类型和String类型的 ...
- 闪回恢复区大小不够。报ORA-19809、ORA-19804
问题: 闪回恢复区大小不够,rman默认备份路径报错.RMAN> backup database;Starting backup at 01-DEC-14using target databas ...
- Android学习十一:高德地图使用
写这篇文章主要有三个目的: 1.使用高德地图api定位 2.获取天气数据 3.编程练手 文件结构 清单文件信息说明: <?xml version="1.0" encoding ...
- 用CorelDRAW等分分割图片的方法
在CorelDRAW中,想要将图片等分分割可以通过放置容器来实现,根本不需要裁剪工具和辅助线.例如两等分:首先要建立确定等分的份数,建立长方形或正方形.然后把图片放置容器,调整位置,做无缝拼接就可以了 ...
- H5页面在QQ和微信上分享,为什么不能自定义设置图片和摘要?
[记录]title标签中的页面标题为抓取标题.body内第一个img标签内的图片为自动抓取缩略图,图片宽高要大于300,如果不希望显示出来,将标签宽高皆设置为0.摘要显示为来源链接,如需自定义需要通过 ...
- javascript操控浏览器
测试环境为Chrome浏览器47.0.2526.106 m 测试窗口为F12->Console 跳转网页 // 跳转到百度 window.location.href = "https: ...
- 转载:scala中:: , +:, :+, :::, ++的区别
原文链接:https://segmentfault.com/a/1190000005083578 初学Scala的人都会被Seq的各种操作符所confuse.下面简单列举一下各个Seq操作符的区别. ...
- excel 导入数据库 / SSIS 中 excel data source --64位excel 版本不支持-- solution
当本地安装的excel(2013版) 是64-bit时:出现的以下两种错误 解决: 1. excel 导入数据库 , 如果文件是2007则会出现:“The 'Microsoft.ACE.OLEDB.1 ...
- UIWebView的使用
iOS中UIWebView的使用详解 一.初始化与三种加载方式 UIWebView继承与UIView,因此,其初始化方法和一般的view一样,通过alloc和init进行初始化,其加载数据的方式有三种 ...