pandas学习笔记 - 常见的数据处理方式
1.缺失值处理 - 拉格朗日插值法
input_file数据文件内容(存在部分缺失值):
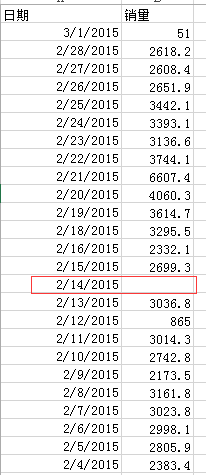
from scipy.interpolate import lagrange
import pandas as pd
import numpy as np input_file = './data/catering_sale.xls'
output_file = './data/sales.xls' data = pd.read_excel(input_file)
data['销量'][(data['销量'] < 400) | (data['销量'] > 5000)] = None # 销量小于400及大于5000的视为异常值,置为None
# 自定义列向量插值函数
# 问题:当n<k时,list(range(n-k, n))会出现负数,导致y的值出现空值,会影响最终的插值结果,这个问题还未解决。。。
def ployinterp_column(s, n, k=5):
# s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
y = s[list(range(n-k, n)) + list(range(n+1, n+k+1))]
y = y[y.notnull()] # 剔除空值
if n-k < 0: # 如果NaN值在前5位,则插值结果取k-n位
return lagrange(y.index, list(y))(k-n)
else:
return lagrange(y.index, list(y))(n) # 插值并返回插值结果 # 逐个元素判断是否需要插值
for j in range(len(data)):
if (data['销量'].isnull())[j]: # 如果元素为空,则进行插值
data['销量'][j] = ployinterp_column(data['销量'], j) data.to_excel(output_file)
output_file结果:

# np.where()
a = pd.Series([np.nan, 2.5, np.nan, 3.5, 4.5, np.nan], index=['f', 'e', 'd', 'c', 'b', 'a'])
b = pd.Series(np.arange(len(a), dtype=np.float64), index=['f', 'e', 'd', 'c', 'b', 'a']) # 如果a有缺失值,则用相应位置的b填充,否则使用a的原有元素
print(np.where(pd.isnull(a), b, a)) # result
[ 0. 2.5 2. 3.5 4.5 5. ]
# df.combine_first()
df1 = pd.DataFrame({'a': [1., np.nan, 5., np.nan],
'b': [np.nan, 2., np.nan, 6.],
'c': range(2, 18, 4)})
df2 = pd.DataFrame({'a': [5., 4., np.nan, 3., 7.],
'b': [np.nan, 3., 4., 6., 8.]}) # 将df1中的缺失值用df2中相同位置的元素填充,如果没有缺失值则保持df1的原有元素
df1.combine_first(df2) # result
a b c
0 1.0 NaN 2.0
1 4.0 2.0 6.0
2 5.0 4.0 10.0
3 3.0 6.0 14.0
4 7.0 8.0 NaN
# 异常值处理
data = pd.DataFrame(np.random.randn(1000, 4))
print(data.describe())
# result
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean -0.012809 0.007609 -0.002442 0.027889
std 1.026971 0.985884 0.999810 1.006344
min -3.174895 -2.970125 -3.011063 -3.440525
25% -0.723649 -0.657574 -0.642299 -0.647432
50% -0.019972 0.021018 -0.015020 0.012603
75% 0.707184 0.678987 0.674781 0.707672
max 3.076159 3.890196 2.869127 3.089114 col = data[3]
# 大于3的值为异常值
col[np.abs(col) > 3]
data[(np.abs(data) > 3).any(1)] # any(1)
# np.sign()函数,大于0为1,小于0为-1
data[np.abs(data) > 3] = np.sign(data) * 3
print(data.describe())
# result
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean -0.012763 0.006719 -0.002428 0.028545
std 1.026062 0.982772 0.999768 1.003687
min -3.000000 -2.970125 -3.000000 -3.000000
25% -0.723649 -0.657574 -0.642299 -0.647432
50% -0.019972 0.021018 -0.015020 0.012603
75% 0.707184 0.678987 0.674781 0.707672
max 3.000000 3.000000 2.869127 3.000000
2.数据合并:
# pd.merge()
# 使用列或者索引,以类似数据库连接的方式合并多个DataFrame对象
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'], 'data1': range(7)})
df2 = pd.DataFrame({'key': ['a', 'b', 'd'], 'data2': range(3)}) print(pd.merge(df1, df2)) # 自动匹配合并列, 默认内连接
print(pd.merge(df1, df2, on='key')) # 显式指定
# result
data1 key data2
0 0 b 1
1 1 b 1
2 6 b 1
3 2 a 0
4 4 a 0
5 5 a 0
df3 = pd.DataFrame({'lkey': ['b', 'b', 'a', 'c', 'a', 'a', 'b'], 'data1': range(7)})
df4 = pd.DataFrame({'rkey': ['a', 'b', 'd'], 'data2': range(3)})
print(pd.merge(df3, df4, left_on='lkey', right_on='rkey')) # 当不存在相同column时,需要分别指定连接列名
# result
data1 lkey data2 rkey
0 0 b 1 b
1 1 b 1 b
2 6 b 1 b
3 2 a 0 a
4 4 a 0 a
5 5 a 0 a
## 指定连接方式
# 外连接
print(pd.merge(df1, df2, how='outer')) # result data1 key data2
0 0.0 b 1.0
1 1.0 b 1.0
2 6.0 b 1.0
3 2.0 a 0.0
4 4.0 a 0.0
5 5.0 a 0.0
6 3.0 c NaN
7 NaN d 2.0
# 左连接
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'], 'data1': range(6)})
df2 = pd.DataFrame({'key': ['a', 'b', 'a', 'b', 'd'] ,'data2': range(5)}) print(pd.merge(df1, df2, how='left')) # result data1 key data2
0 0 b 1.0
1 0 b 3.0
2 1 b 1.0
3 1 b 3.0
4 2 a 0.0
5 2 a 2.0
6 3 c NaN
7 4 a 0.0
8 4 a 2.0
9 5 b 1.0
10 5 b 3.0
# 多列连接
left = pd.DataFrame({'key1': ['foo', 'foo', 'bar'],
'key2': ['one', 'two', 'one'],
'lval': [1, 2, 3]})
right = pd.DataFrame({'key1': ['foo', 'foo', 'bar', 'bar'],
'key2': ['one', 'one', 'one', 'two'],
'rval': [4, 5, 6, 7]}) print(pd.merge(left, right, on=['key1', 'key2'])) # 默认内连接 # result
key1 key2 lval rval
0 foo one 1 4
1 foo one 1 5
2 bar one 3 6 print(pd.merge(left, right, on=['key1', 'key2'], how='outer')) # 外连接 # result
key1 key2 lval rval
0 foo one 1.0 4.0
1 foo one 1.0 5.0
2 foo two 2.0 NaN
3 bar one 3.0 6.0
4 bar two NaN 7.0
# 只以其中一个列连接,会出现冗余列
pd.merge(left, right, on='key1') # result
key1 key2_x lval key2_y rval
0 foo one 1 one 4
1 foo one 1 one 5
2 foo two 2 one 4
3 foo two 2 one 5
4 bar one 3 one 6
5 bar one 3 two 7 print(pd.merge(left, right, on='key1', suffixes=('_left', '_right'))) # 给冗余列增加后缀 # result
key1 key2_left lval key2_right rval
0 foo one 1 one 4
1 foo one 1 one 5
2 foo two 2 one 4
3 foo two 2 one 5
4 bar one 3 one 6
5 bar one 3 two 7
# 使用索引与列进行合并
left1 = pd.DataFrame({'key': ['a', 'b', 'a', 'a', 'b', 'c'],'value': range(6)})
right1 = pd.DataFrame({'group_val': [3.5, 7]}, index=['a', 'b']) print(pd.merge(left1, right1, left_on='key', right_index=True)) # left1使用key列连接,right1使用index列连接 # result
key value group_val
0 a 0 3.5
2 a 2 3.5
3 a 3 3.5
1 b 1 7.0
4 b 4 7.0
# 多列索引连接
lefth = pd.DataFrame({'key1': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'key2': [2000, 2001, 2002, 2001, 2002],
'data': np.arange(5.)})
righth = pd.DataFrame(np.arange(12).reshape((6, 2)),
index=[['Nevada', 'Nevada', 'Ohio', 'Ohio', 'Ohio', 'Ohio'],
[2001, 2000, 2000, 2000, 2001, 2002]],
columns=['event1', 'event2']) print(pd.merge(lefth, righth, left_on=['key1', 'key2'], right_index=True)) # result
data key1 key2 event1 event2
0 0.0 Ohio 2000 4 5
0 0.0 Ohio 2000 6 7
1 1.0 Ohio 2001 8 9
2 2.0 Ohio 2002 10 11
3 3.0 Nevada 2001 0 1
# pd.join()
# pd.join()可以使用index或key合并两个及以上的DataFrame(列方向上的合并)
left2 = pd.DataFrame([[1., 2.], [3., 4.], [5., 6.]], index=['a', 'c', 'e'],
columns=['Ohio', 'Nevada'])
right2 = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [13, 14]],
index=['b', 'c', 'd', 'e'], columns=['Missouri', 'Alabama']) print(left2.join(right2, how='outer')) # result Ohio Nevada Missouri Alabama
a 1.0 2.0 NaN NaN
b NaN NaN 7.0 8.0
c 3.0 4.0 9.0 10.0
d NaN NaN 11.0 12.0
e 5.0 6.0 13.0 14.0
# 合并多个DataFrame
another = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [16., 17.]],
index=['a', 'c', 'e', 'f'], columns=['New York', 'Oregon']) left2.join([right2, another], how='outer') # result
Ohio Nevada Missouri Alabama New York Oregon
a 1.0 2.0 NaN NaN 7.0 8.0
b NaN NaN 7.0 8.0 NaN NaN
c 3.0 4.0 9.0 10.0 9.0 10.0
d NaN NaN 11.0 12.0 NaN NaN
e 5.0 6.0 13.0 14.0 11.0 12.0
f NaN NaN NaN NaN 16.0 17.0
# 轴向连接# np.concatenate()
arr = np.arange(12).reshape((3,4))
print(np.concatenate([arr, arr], axis=1)) # 在column方向上连接 # result array([[ 0, 1, 2, ..., 1, 2, 3],
[ 4, 5, 6, ..., 5, 6, 7],
[ 8, 9, 10, ..., 9, 10, 11]])
# pd.concat()
s1 = pd.Series([0,1], index=['a', 'b'])
s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])
s3 = pd.Series([5, 6], index=['f', 'g']) print(pd.concat([s1, s2, s3])) # axis参数默认为0,row方向的
# result
a 0
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64 print(pd.concat([s1, s2, s3], axis=1)) # column方向合并,值如果不存在则记为NaN
# result
0 1 2
a 0.0 NaN NaN
b 1.0 NaN NaN
c NaN 2.0 NaN
d NaN 3.0 NaN
e NaN 4.0 NaN
f NaN NaN 5.0
g NaN NaN 6.0 s4 = pd.concat([s1 * 5, s3])
s5 = pd.concat([s1, s4], axis=1)
s5.columns = ['s1', 's4']
print(s5) # result
s1 s4
a 0.0 0
b 1.0 5
f NaN 5
g NaN 6 print(pd.concat([s1, s4], axis=1, join='inner')) # join参数指定连接方式
# result
0 1
a 0 0
b 1 5 print(pd.concat([s1, s4], axis=1, join_axes=[['a', 'c', 'b', 'e']])) # 手动指定要连接的index
# result
0 1
a 0.0 0.0
c NaN NaN
b 1.0 5.0
e NaN NaN
# 使用keys参数对索引进行分级
result = pd.concat([s1, s2, s3], keys=['one', 'two', 'three']) # 在row方向合并时,keys对应每个Series的一级index,每个Series原有的index则作为二级index print(result) # result
one a 0
b 1
two c 2
d 3
e 4
three f 5
g 6
dtype: int64
# Series.unstack() 将Seris格式转换为DataFrame格式
print(result.unstack()) # 一级索引将作为index,二级索引作为columns # result
a b c d e f g
one 0.0 1.0 NaN NaN NaN NaN NaN
two NaN NaN 2.0 3.0 4.0 NaN NaN
three NaN NaN NaN NaN NaN 5.0 6.0
# 在列合并时使用keys参数指定column名称
print(pd.concat([s1, s2, s3], axis=1, keys=['one', 'two', 'three'])) # 在column方向合并时,keys对应每个合并的Series的column # result
one two three
a 0.0 NaN NaN
b 1.0 NaN NaN
c NaN 2.0 NaN
d NaN 3.0 NaN
e NaN 4.0 NaN
f NaN NaN 5.0
g NaN NaN 6.0
# 指定分级column
df1 = pd.DataFrame(np.arange(6).reshape(3, 2), index=['a', 'b', 'c'], columns=['one', 'two'])
df2 = pd.DataFrame(5 + np.arange(4).reshape(2, 2), index=['a', 'c'], columns=['three', 'four'])
# 因为DataFrame对象已经有了column,所以keys参数会设置新的一级column, df原有的column则作为二级column
df3 = pd.concat([df1, df2], axis=1, keys=['level1', 'level2'])
print(df3)
print(df3.columns)
# result
level1 level2
one two three four
a 0 1 5.0 6.0
b 2 3 NaN NaN
c 4 5 7.0 8.0 MultiIndex(levels=[['level1', 'level2'], ['four', 'one', 'three', 'two']],
labels=[[0, 0, 1, 1], [1, 3, 2, 0]]) # 使用字典实现相同的功能
print(pd.concat({'level1': df1, 'level2': df2}, axis=1))
#result
level1 level2
one two three four
a 0 1 5.0 6.0
b 2 3 NaN NaN
c 4 5 7.0 8.0 # 指定分级column名称
df = pd.concat([df1, df2], axis=1, keys=['level1', 'level2'], names=['levels', 'number'])
print(df)
print(df.columns) # result
levels level1 level2
number one two three four
a 0 1 5.0 6.0
b 2 3 NaN NaN
c 4 5 7.0 8.0 MultiIndex(levels=[['level1', 'level2'], ['four', 'one', 'three', 'two']],
labels=[[0, 0, 1, 1], [1, 3, 2, 0]],
names=['levels', 'number'])
# ignore_index
df1 = pd.DataFrame(np.random.randn(3, 4), columns=['a', 'b', 'c', 'd'])
df2 = pd.DataFrame(np.random.randn(2, 3), columns=['b', 'd', 'a']) # row方向忽略索引
print(pd.concat([df1, df2], ignore_index=True))
# result
a b c d
0 1.261208 0.022188 -2.489475 -1.098245
1 0.618618 -1.179827 1.475738 0.334444
2 -0.319088 -0.153492 0.029245 0.336055
3 -0.999023 -0.502154 NaN 0.722256
4 1.428007 -0.726810 NaN 0.432440 # column方向忽略列名
print(pd.concat([df1, df2], axis=1, ignore_index=True))
# result
0 1 2 3 4 5 6
0 1.261208 0.022188 -2.489475 -1.098245 -0.502154 0.722256 -0.999023
1 0.618618 -1.179827 1.475738 0.334444 -0.726810 0.432440 1.428007
2 -0.319088 -0.153492 0.029245 0.336055 NaN NaN NaN
3.重塑层次化索引
data = pd.DataFrame(np.arange(6).reshape((2, 3)),
index=pd.Index(['Ohio', 'Colorado'], name='state'),
columns=pd.Index(['one', 'two', 'three'], name='number')) # 轴向旋转
result = data.stack()
print(result)
# result
state number
Ohio one 0
two 1
three 2
Colorado one 3
two 4
three 5 # 还原操作
print(result.unstack())
# result
number one two three
state
Ohio 0 1 2
Colorado 3 4 5 # 行列转置
print(result.unstack(0))
# result
state Ohio Colorado
number
one 0 3
two 1 4
three 2 5 # 指定要转置的索引名
print(result.unstack('number'))
# result
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
# 例1:
s1 = pd.Series([0, 1, 2, 3], index=['a', 'b', 'c', 'd'])
s2 = pd.Series([4, 5, 6], index=['c', 'd', 'e'])
data2 = pd.concat([s1, s2], keys=['one', 'two']) print(data2.unstack())
# result
a b c d e
one 0.0 1.0 2.0 3.0 NaN
two NaN NaN 4.0 5.0 6.0 print(data2.unstack().stack())
# result
one a 0.0
b 1.0
c 2.0
d 3.0
two c 4.0
d 5.0
e 6.0
dtype: float64 # 不dropnan值
print(data2.unstack().stack(dropna=False))
# result
one a 0.0
b 1.0
c 2.0
d 3.0
e NaN
two a NaN
b NaN
c 4.0
d 5.0
e 6.0
dtype: float64
# 例2:
df = pd.DataFrame({'left': result, 'right': result + 5},
columns=pd.Index(['left', 'right'], name='side'))
print(df.unstack('state'))
# result
side left right
state Ohio Colorado Ohio Colorado
number
one 0 3 5 8
two 1 4 6 9
three 2 5 7 10
print(df.unstack('state').stack('side'))
# result
state Colorado Ohio
number side
one left 3 0
right 8 5
two left 4 1
right 9 6
three left 5 2
right 10 7
4.长宽格式的转换:
所谓长格式,即相关属性都集中在同一个列中,另有一个VALUE列对应相应的属性值;
而宽格式, 就是各个属性自成一列,不需要单独的VALUE列。
# 导入宽格式数据
data = pd.read_csv('./data/macrodata.csv')
# pd.PeriodIndex 用来存放表示周期性日期的数组,数组元素是不可更改的。例如:年、季度、月、天等。
periods = pd.PeriodIndex(year=data.year, quarter=data.quarter, name='date')
data = pd.DataFrame(data.to_records(), # to_records() 将DF转换成numpy record数组
columns=pd.Index(['realgdp', 'infl', 'unemp'], name='item'),
index=periods.to_timestamp('D', 'end')) print(data.head())
# result
item realgdp infl unemp
date
1959-03-31 2710.349 0.00 5.8
1959-06-30 2778.801 2.34 5.1
1959-09-30 2775.488 2.74 5.3
1959-12-31 2785.204 0.27 5.6
1960-03-31 2847.699 2.31 5.2
# 将宽格式转换为长格式
# 轴向旋转 -> 重置索引 -> rename列名
long_data = data.stack().reset_index().rename(columns={0: 'value'}) print(long_data.head())
# result
date item value
0 1959-03-31 realgdp 2710.349
1 1959-03-31 infl 0.000
2 1959-03-31 unemp 5.800
3 1959-06-30 realgdp 2778.801
4 1959-06-30 infl 2.340
# 将长格式转换为宽格式
""" pd.pivot()
基于index/column的值重新调整DataFrame的坐标轴。不支持数据聚合,重复值会导致重复记录
语法格式: df.pivot(index(optional), columns, values) """ wide_data = long_data.pivot('date', 'item', 'value') print(wide_data.head())
# result
item infl realgdp unemp
date
1959-03-31 0.00 2710.349 5.8
1959-06-30 2.34 2778.801 5.1
1959-09-30 2.74 2775.488 5.3
1959-12-31 0.27 2785.204 5.6
1960-03-31 2.31 2847.699 5.2
# 增加一列value2
long_data['value2'] = np.random.rand(len(long_data)) print(long_data.head())
# result
date item value value2
0 1959-03-31 realgdp 2710.349 0.155924
1 1959-03-31 infl 0.000 0.340776
2 1959-03-31 unemp 5.800 0.615475
3 1959-06-30 realgdp 2778.801 0.417256
4 1959-06-30 infl 2.340 0.845293 # 转换时如果不指定values,会将剩余的列都作为values列
pivoted = long_data.pivot('date', 'item') # data为index,item为columns print(pivoted.head())
# result
value value2
item infl realgdp unemp infl realgdp unemp
date
1959-03-31 0.00 2710.349 5.8 0.340776 0.155924 0.615475
1959-06-30 2.34 2778.801 5.1 0.845293 0.417256 0.825615
1959-09-30 2.74 2775.488 5.3 0.413700 0.512401 0.874806
1959-12-31 0.27 2785.204 5.6 0.081047 0.358632 0.790962
1960-03-31 2.31 2847.699 5.2 0.833500 0.395999 0.329820
5. 删除重复数据:
data = pd.DataFrame({'k1': ['one'] * 3 + ['two'] * 4,
'k2': [1, 1, 2, 3, 3, 4, 4]})
print(data)
# result
k1 k2
0 one 1
1 one 1
2 one 2
3 two 3
4 two 3
5 two 4
6 two 4
# 判断当前行与前一行是否相同
print(data.duplicated())
# result
0 False
1 True
2 False
3 False
4 True
5 False
6 True
dtype: bool
# drop重复行
print(data.drop_duplicates())
# result
k1 k2
0 one 1
2 one 2
3 two 3
5 two 4
# 新增v1列
data['v1'] = range(7) # 只以k1列为标准删除重复行
print(data.drop_duplicates(['k1']))
# result
k1 k2 v1
0 one 1 0
3 two 3 3 # 以k1,k2为准,并且取最后一行的值
print(data.drop_duplicates(['k1', 'k2'], keep='last'))
# result
k1 k2 v1
1 one 1 1
2 one 2 2
4 two 3 4
6 two 4 6
6.利用函数及映射进行转换
# 使用字典映射进行转换
data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon', 'Pastrami',
'corned beef', 'Bacon', 'pastrami', 'honey ham',
'nova lox'],
'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
print(data)
# result
food ounces
0 bacon 4.0
1 pulled pork 3.0
2 bacon 12.0
3 Pastrami 6.0
4 corned beef 7.5
5 Bacon 8.0
6 pastrami 3.0
7 honey ham 5.0
8 nova lox 6.0 meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
} data['animal'] = data['food'].map(str.lower).map(meat_to_animal)
print(data)
# result
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastrami 3.0 cow
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
# 使用lambda匿名函数进行转换 data['animal2'] = data.food.map(lambda x:meat_to_animal[x.lower()]) print(data)
# result
food ounces animal animal2
0 bacon 4.0 pig pig
1 pulled pork 3.0 pig pig
2 bacon 12.0 pig pig
3 Pastrami 6.0 cow cow
4 corned beef 7.5 cow cow
5 Bacon 8.0 pig pig
6 pastrami 3.0 cow cow
7 honey ham 5.0 pig pig
8 nova lox 6.0 salmon salmon
7.数据标准化
有时候由于量纲(数据单位)不一致,导致数据的差异很大,无法进行比较,需要进行数据标准化,将数据进行一定范围的压缩,以便进行数据比对等后续操作。
datafile = './data/normalization_data.xls'
data = pd.read_excel(datafile, header=None)
print(data)
# result
0 1 2 3
0 78 521 602 2863
1 144 -600 -521 2245
2 95 -457 468 -1283
3 69 596 695 1054
4 190 527 691 2051
5 101 403 470 2487
6 146 413 435 2571 # 最小-最大规范化
data1 = (data - data.min()) / (data.max() - data.min())
print(data1)
# result
0 1 2 3
0 0.074380 0.937291 0.923520 1.000000
1 0.619835 0.000000 0.000000 0.850941
2 0.214876 0.119565 0.813322 0.000000
3 0.000000 1.000000 1.000000 0.563676
4 1.000000 0.942308 0.996711 0.804149
5 0.264463 0.838629 0.814967 0.909310
6 0.636364 0.846990 0.786184 0.929571 # 零-均值规范化
data2 = (data - data.mean()) / data.std()
print(data2)
# result
0 1 2 3
0 -0.905383 0.635863 0.464531 0.798149
1 0.604678 -1.587675 -2.193167 0.369390
2 -0.516428 -1.304030 0.147406 -2.078279
3 -1.111301 0.784628 0.684625 -0.456906
4 1.657146 0.647765 0.675159 0.234796
5 -0.379150 0.401807 0.152139 0.537286
6 0.650438 0.421642 0.069308 0.595564 # np.ceil() 正向取整
data3 = data/10**np.ceil(np.log10(data.abs().max()))
print(data3)
# result
0 1 2 3
0 0.078 0.521 0.602 0.2863
1 0.144 -0.600 -0.521 0.2245
2 0.095 -0.457 0.468 -0.1283
3 0.069 0.596 0.695 0.1054
4 0.190 0.527 0.691 0.2051
5 0.101 0.403 0.470 0.2487
6 0.146 0.413 0.435 0.2571
8.replace替换
data = pd.Series([1., -999., 2., -999., -1000., 3.])
print(data)
# result
0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
dtype: float64 # 基本替换方式
print(data.replace(-999, np.nan))
# result
0 1.0
1 NaN
2 2.0
3 NaN
4 -1000.0
5 3.0
dtype: float64 # 使用列表分别替换对应位置的元素
print(data.replace([-999, -1000], [np.nan, 0]))
# result
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
# 使用字典进行更明确的替换
print(data.replace({-999: np.nan, -1000: 0}))
# result
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
9.重命名轴索引:
data = pd.DataFrame(np.arange(12).reshape((3, 4)),
index=['Ohio', 'Colorado', 'New York'],
columns=['one', 'two', 'three', 'four'])
data.index = data.index.map(str.upper) print(data)
# result
one two three four
OHIO 0 1 2 3
COLORADO 4 5 6 7
NEW YORK 8 9 10 11 # 重命名索引及列名
print(data.rename(index=str.title, columns=str.upper))
# result
ONE TWO THREE FOUR
Ohio 0 1 2 3
Colorado 4 5 6 7
New York 8 9 10 11 # 使用字典映射新索引及新列名
print(data.rename(index={'OHIO': 'INDIANA'}, columns={'three': 'peekaboo'}))
# result
one two peekaboo four
INDIANA 0 1 2 3
COLORADO 4 5 6 7
NEW YORK 8 9 10 11
10.数据离散化与面元划分
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
bins = [18, 25, 35, 60, 100] # 按照bins中的区间划分ages中的元素
cats = pd.cut(ages, bins)
print(cats)
# result
[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (25, 35], (60, 100], (35, 60], (35, 60], (25, 35]]
Length: 12
Categories (4, interval[int64]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]] # 查看元素属于哪个区间
print(cats.labels) # python2用法
print(cats.codes) # python3用法
# result
[0 0 0 ..., 2 2 1] # 统计元素分布情况
print(pd.value_counts(cats))
# result
(18, 25] 5
(35, 60] 3
(25, 35] 3
(60, 100] 1
dtype: int64
# 默认的区间访问为左开右闭,指定right=False后,变成左闭右开
print(pd.cut(ages, [18, 26, 36, 61, 100], right=False))
# result
[[18, 26), [18, 26), [18, 26), [26, 36), [18, 26), ..., [26, 36), [61, 100), [36, 61), [36, 61), [26, 36)]
Length: 12
Categories (4, interval[int64]): [[18, 26) < [26, 36) < [36, 61) < [61, 100)] # 手动设置标签,用来替换默认的区间
group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
cat2 = pd.cut(ages, bins, labels=group_names)
print(cat2.value_counts())
# result
MiddleAged 3
Senior 1
YoungAdult 3
Youth 5
dtype: int64
# 指定区间的划分精度
data = np.random.rand(20)
print(pd.cut(data, 4, precision=2))
# result
[(0.054, 0.27], (0.71, 0.93], (0.27, 0.49], (0.27, 0.49], (0.054, 0.27], ..., (0.71, 0.93], (0.71, 0.93], (0.71, 0.93], (0.054, 0.27], (0.71, 0.93]]
Length: 20
Categories (4, interval[float64]): [(0.054, 0.27] < (0.27, 0.49] < (0.49, 0.71] < (0.71, 0.93]]
# 自定义分位点
print(pd.qcut(data, [0, 0.1, 0.5, 0.9, 1]))
# result
[(0.0953, 0.431], (0.893, 0.929], (0.431, 0.893], (0.0953, 0.431], (0.0953, 0.431], ..., (0.431, 0.893], (0.431, 0.893], (0.431, 0.893], (0.0536, 0.0953], (0.431, 0.893]]
Length: 20
Categories (4, interval[float64]): [(0.0536, 0.0953] < (0.0953, 0.431] < (0.431, 0.893] < (0.893, 0.929]]
11.排列与随机采样
# np.random.permutation()
df = pd.DataFrame(np.arange(5 * 4).reshape((5, 4)))
print(df)
# result
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19 # 随机取5个数组成一个排列
sampler = np.random.permutation(5)
print(sampler)
# result
[0 1 2 4 3] # 按照排列获取df中的数据
print(df.take(sampler))
# result
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
4 16 17 18 19
3 12 13 14 15 # 只取排列中的后三行数据
print(df.take(np.random.permutation(len(df))[:3]))
# result
0 1 2 3
1 4 5 6 7
4 16 17 18 19
0 0 1 2 3
# np.random.randint()
bag = np.array([5, 7, -1, 6, 4]) # 从0到5中随机取10个数
sampler = np.random.randint(0, len(bag), size=10)
print(sampler)
# result
[4 0 0 3 3 4 3 0 1 1] # 将sampler作为索引值,获取bag的对应元素
draws = bag.take(sampler)
print(draws)
print(bag[sampler]) # 简化写法,可得同样结果
# result
[4 5 5 6 6 4 6 5 7 7]
12.哑向量的使用
哑向量通常用来表示一组彼此间相互独立的属性,也成为因子。将他们的关系用只有0和1的向量表示,就叫做哑向量。
# 对某列取哑向量
df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'], 'data1': range(6), 'data2': [1, 3, 5, 7, 9, 11]})
print(pd.get_dummies(df['key']))
# result
a b c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 0 print(pd.get_dummies(df['data2']))
# result
1 3 5 7 9 11
0 1 0 0 0 0 0
1 0 1 0 0 0 0
2 0 0 1 0 0 0
3 0 0 0 1 0 0
4 0 0 0 0 1 0
5 0 0 0 0 0 1
# 对列名加前缀
dummies = pd.get_dummies(df['key'], prefix='key')
# 将哑向量与df[data1]连接在一起
df_with_dummy = df[['data1']].join(dummies)
print(df_with_dummy)
# result
data1 key_a key_b key_c
0 0 0 1 0
1 1 0 1 0
2 2 1 0 0
3 3 0 0 1
4 4 1 0 0
5 5 0 1 0
# 哑向量例子
# 读入影评数据
movies = pd.read_table('./data/movies.dat', sep='::', header=None, names=mnames) 数据文件内容:

# 设置列名
mnames = ['movie_id', 'title', 'genres'] # 提取genres列中的数据,将分离的元素组成集合
genre_iter = (set(x.split('|')) for x in movies.genres)
# 对genre_iter中的set集合解压后去重,再排序
genres = sorted(set.union(*genre_iter)) # 生成DataFrame哑向量
dummies = pd.DataFrame(np.zeros((len(movies), len(genres))), columns=genres) # 先根据数据文件生成一个元素均为0的DF
for i, gen in enumerate(movies.genres): # 对genres进行循环
dummies.loc[i, gen.split('|')] = 1 # 将genres中的项按照行号设置为1,使其成为哑向量 # 将哑向量df与原df合并到一起
movies_windic = movies.join(dummies.add_prefix('Genre_'))
# 查看第一行数据(Series格式)
print(movies_windic.iloc[0])
# result
movie_id 1
title Toy Story (1995)
genres Animation|Children's|Comedy
Genre_Action 0
Genre_Adventure 0
Genre_Animation 1
Genre_Children's 1
Genre_Comedy 1
Genre_Crime 0
Genre_Documentary 0
Genre_Drama 0
Genre_Fantasy 0
Genre_Film-Noir 0
Genre_Horror 0
Genre_Musical 0
Genre_Mystery 0
Genre_Romance 0
Genre_Sci-Fi 0
Genre_Thriller 0
Genre_War 0
Genre_Western 0
Name: 0, dtype: object
# 使用pd.cut()进行分类,然后转换成哑向量
values = np.random.rand(10)
bins = [0, 0.2, 0.4, 0.6, 0.8, 1]
pd.get_dummies(pd.cut(values, bins))
# result
(0.0, 0.2] (0.2, 0.4] (0.4, 0.6] (0.6, 0.8] (0.8, 1.0]
0 1 0 0 0 0
1 0 0 0 1 0
2 0 0 0 0 1
3 0 0 1 0 0
4 1 0 0 0 0
5 0 0 0 1 0
6 0 0 1 0 0
7 0 0 0 0 1
8 0 1 0 0 0
9 0 1 0 0 0
pandas学习笔记 - 常见的数据处理方式的更多相关文章
- 【转】Pandas学习笔记(五)合并 concat
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(二)选择数据
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- Pandas 学习笔记
Pandas 学习笔记 pandas 由两部份组成,分别是 Series 和 DataFrame. Series 可以理解为"一维数组.列表.字典" DataFrame 可以理解为 ...
- mybatis学习笔记--常见的错误
原文来自:<mybatis学习笔记--常见的错误> 昨天刚学了下mybatis,用的是3.2.2的版本,在使用过程中遇到了些小问题,现总结如下,会不断更新. 1.没有在configurat ...
- 【转】Pandas学习笔记(七)plot画图
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(六)合并 merge
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(四)处理丢失值
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(三)修改&添加值
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(一)基本介绍
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
随机推荐
- luogu p1004
P1004 题意 类似一个比较小的方格(N<=9),有的点是0,有的点有数, A->B的路径经过的点加上该点代表的数,求两次A->B的最大解(最优解) 一个令人恼的问题是两条路径如果 ...
- 加减法计算器-java
由于经常进行较大数据的加减法计算,好多计算器都是转换成科学技术法的,所以自己用java写了一个 功能如下: 1,可以输入多个带千位分隔符的数字,进行加减法计算 2,结果展示带千位分隔符 3,结果展示不 ...
- centos7最小化安装Oracle11gR2
1.准备CentOS 7 系统环境 我以 CentOS-7-x86_64-DVD-1511.iso 为例,简述Oracle 11g的安装过程. 由于是使用静默模式(silent)安装的,无需使用图形化 ...
- python_字符串常用操作
name = "monicao"name.capitalize() #首字母大写print(name.capitalize()) print(name.count("o& ...
- 新手学python-Day4-作业
购物车程序 要求: 1.启动程序后,让用户输入工资,然后打印商品列表 2.允许用户根据商品编号购买商品 3.用户选择商品后,检查余额是否足够,够了就扣款,不够就提醒 4.可随时退出,退出时,打印已购买 ...
- 前端通过canvas实现图片压缩
在一次的项目中,需要用户上传图片,目前市场随便一个手机拍出来的照片都是好几兆,直接上传特别占用带宽,影响用户体验,所以要求对用户上传图片进行压缩后再上传:那么前端怎么实现这个功能呢? 亲测可将4M图片 ...
- java的继承中构造方法
构造方法在创建对象的时候是被自动调用的,然后在继承中,是先调用父类的构造方法,然后在调用子类的构造方法, 当构造方法重写之后,在super中添加对应你想要调用构造方法的参数 例:父类 package ...
- angular-HTTP
AngularJS $http 是一个用于读取web服务器上数据的服务. $http.get(url) 是用于读取服务器数据的函数. <div ng-app="myApp" ...
- leetcode笔记:Find Median from Data Stream
一. 题目描写叙述 Median is the middle value in an ordered integer list. If the size of the list is even, th ...
- web服务启动spring自己主动运行ApplicationListener的使用方法
我们知道.一般来说一个项目启动时须要载入或者运行一些特殊的任务来初始化系统.通常的做法就是用servlet去初始化.可是servlet在使用spring bean时不能直接注入,还须要在web.xml ...