JSP中文乱码问题的由来以及解决方法
首先明确一点,在计算机中,只有二进制的数据!
一、java_web乱码问题的由来
1.字符集
1.1 ASCII字符集
在早期的计算机系统中,使用的字符非常少,这些字符包括26个英文字母、数字符号和一些常用符号(包括控制符号),对这些字符进行编码,用1个字节就足够了(1个字节可以表示28=256种字符)。然而实际上,表示这些字符,只使用了1个字节的7位,这就是ASCII编码1.ASCII
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码),是基于常用的英文字符的一套电脑编码系统。每一个ASCII码与一个8位(bit)二进制数对应。其最高位是0,相应的十进制数是0~127。例如,数字字符“0”的编码用十进制数表示就是48。另有128个扩展的ASCII码,最高位都是1,由一些图形和画线符号组成。ASCII是现今最通用的单字节编码系统。
ASCII用一个字节来表示字符,最多能够表示256种字符。随着计算机的普及,许多国家都将本地的语言符号引入到计算机中,扩展了计算机中字符的范围,于是就出现了各种不同的字符集。
1.2.ISO8859-1
因为ASCII码中缺少£、ü和许多书写其他语言所需的字符,为此,可以通过指定128以后的字符来扩展ASCII码。国际标准组织(ISO)定义了几个不同的字符集,它们是在ASCII码基础上增加了其他语言和地区需要的字符。其中最常用的是ISO8859-1,通常叫做Latin-1。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符,其中0~127的字符与ASCII码相同。ISO 8859另外定义了14个适用于不同文字的字符集(8859-2到8859-15)。这些字符集共享0~127的ASCII码,只是每个字符集都包含了128~255的其他字符。
1.3 GB2312和GBK
GB2312是中华人民共和国国家标准汉字信息交换用编码,全称《信息交换用汉字编码字符集-基本集》,标准号为GB2312-80,是一个由中华人民共和国国家标准总局发布的关于简化汉字的编码,通行于中国大陆和新加坡,简称国标码。
因为中文字符数量较多,所以采用两个字节来表示一个字符,分别称为高位和低位。为了和ASCII码有所区别,中文字符的每一个字节的最高位都用1来表示。GB2312字符集是几乎所有的中文系统和国际化的软件都支持的中文字符集,也是最基本的中文字符集。它包含了大部分常用的一、二级汉字和9区的符号,其编码范围是高位0xa1-0xfe,低位也是0xa1-0xfe,汉字从0xb0a1开始,结束于0xf 7fe。
为了对更多的字符和符号进行编码,由前电子部科技质量司和国家技术监督局标准化司于1995年12月颁布了GBK(K是“扩展”的汉语拼音第一个字母)编码规范,在新的编码系统里,除了完全兼容GB2312外,还对繁体中文、一些不常用的汉字和许多符号进行了编码。它也是现阶段Windows和其他一些中文操作系统的默认字符集,但并不是所有的国际化软件都支持该字符集。不过要注意的是GBK不是国家标准,它只是规范。GBK字符集包含了20 902个汉字,其编码范围是0x8140-0xfefe。
每个国家(或区域)都规定了计算机信息交换用的字符编码集,这就造成了交流上的困难。想像一下,你发送一封中文邮件给一位远在西班牙的朋友,当邮件通过网络发送出去的时候,你所书写的中文字符会按照本地的字符集GBK转换为二进制编码数据,然后发送出去。当你的朋友接收到邮件(二进制数据)后,查看信件时,会按照他所用系统的字符集,将二进制编码数据解码为字符,然而由于两种字符集之间编码的规则不同,导致转换出现乱码。这是因为,在不同的字符集之间,同样的数字可能对应了不同的符号,也可能在另一种字符集中,该数字没有对应符号。
为了解决上述问题,统一全世界的字符编码,由Unicode协会制定并发布了Unicode编码。
1.4 Unicode
Unicode(统一的字符编码标准集)使用0~65 535的双字节无符号数对每一个字符进行编码。它不仅包含来自英语和其他西欧国家字母表中的常见字母和符号,也包含来自古斯拉夫语、希腊语、希伯来语、阿拉伯语和梵语的字母表。另外还包含汉语和日语的象形汉字和韩国的Hangul音节表。
目前已经定义了40 000多个不同的Unicode字符,剩余25 000个空缺留给将来扩展使用。其中大约20 000个字符用于汉字,另外11 000左右的字符用于韩语音节。Unicode中0~255的字符与ISO8859-1中的一致。
Unicode编码对于英文字符采取前面加“0”字节的策略实现等长兼容。如“a”的ASCII码为0x61,Unicode码就为0x00,0x61
1.5 UTF-8
使用Unicode编码,一个英文字符要占用两个字节,在Internet上,大多数的信息都是用英文来表示的,如果都采用Unicode编码,将会使数据量增加一倍。为了减少存储和传输英文字符数据的数据量,可以使用UTF-8编码。
UTF-8全称是Eight-bit UCS Transformation Format(UCS,Universal Character Set,通用字符集,UCS是所有其他字符集标准的一个超集)。对于常用的字符,即0~127的ASCII字符,UTF-8用一个字节来表示,这意味着只包含7位ASCII字符的字符数据在ASCII和UTF-8两种编码方式下是一样的。如果字符对应的Unicode码是0x0000,或在0x0080与0x007f之间,对应的UTF-8编码是两个字节,如果字符对应的Unicode码在0x0800与0xffff之间,对应的UTF-8编码是三个字节。因为中文字符的Unicode编码在0x0800与0xffff之间,所以数据如果是中文,采用UTF-8编码数据量会增加50%。
Unicode与UTF-8转换的规则简述如下:
(1)如果Unicode编码的16位二进制数的前9位是0,则UTF-8编码用1个字节来表示,这个字节的首位是“0”,剩下的7位与原二进制数据的后7位相同。例如:
Unicode编码:/u0061 = 00000000 01100001
UTF-8编码:01100001 = 0x61
(2)如果Unicode编码的16位二进制数的头5位是0,则UTF-8编码用2个字节来表示,首字节以“110”开头,后面的5位与原二进制数据除去前5个零后的最高5位相同;第二个字节以“10”开头,后面的6位与原二进制数据中的低6位相同。例如:
Unicode编码:/u00A9 = 00000000 10101001
UTF-8编码:11000010 10101001 = 0xC2 0xA9
(3)如果不符合上述两个规则,则用三个字节表示。第一个字节以“1110”开头,后四位为原二进制数据的高四位;第二个字节以“10”开头,后六位为原二进制数据中间的六位;第三个字节以“10”开头,后六位为原二进制数据的低六位。例如:
Unicode编码:/u4E2D = 01001110 00101101
UTF-8编码:11100100 10111000 10101101 = 0xE4 0xB8 0xAD
在UTF-8编码的多字节串中,第一个字节开头“1”的数目就是整个字符串中字节的数目。
2.乱码问题分析
为了让使用Java语言编写的程序能在各种语言的平台下运行,Java在其内部使用Unicode字符集来表示字符,这样就存在Unicode字符集和本地字符集进行转换的过程。当在Java中读取字符数据的时候,需要将本地字符集编码的数据转换为Unicode编码,而在输出字符数据的时候,则需要将Unicode编码转换为本地字符集编码。
例如,在中文系统下,从控制台读取一个字符“中”,实际上读取的是“中”的GBK编码0xD6D0,在Java语言中要将GBK编码转换为Unicode编码0x4E2D,此时,在内存中,字符“中”对应的数值就是0x4E2D,当我们向控制台输出字符时,Java语言将Unicode编码再转换为GBK编码,输出到控制台,中文系统再根据GBK字符集画出相应的字符。
从上述过程来看,读取和写入的过程是可逆的,那么理应不会出现中文乱码问题。然而,实际应用的情形,比上述过程要复杂得多。在Web应用中,通常都包括了浏览器、Web服务器、Web应用程序和数据库等部分,每一部分都有可能使用不同的字符集,从而导致字符数据在各种不同的字符集之间转换时,出现乱码的问题。
在Java语言中,不同字符集编码的转换,都是通过Unicode编码作为中介来完成的。例如,GBK编码的字符“中”要转换为ISO-8859-1(同ISO8859-1)编码,其过程如下:
(1)因为在Java中的字符,都是用Unicode来表示的,所以GBK编码的字符“中”要转换为Unicode表示:0xD6D0->0x4E2D。
(2)将字符“中”的Unicode编码转换为ISO-8859-1编码,因为Unicode编码0x4E2D在ISO-8859-1中没有对应的编码,于是得到0x3f,也就是字符“?”。
下面的代码演示了这一过程:
//GBK编码的字符“中”转换为Unicode编码表示
String str="中";
//将字符“中”的Unicode编码转换为ISO-8859-1编码
byte[] b=str.getBytes("ISO-8859-1");
for(int i=0;i<b.length;i++)
{
//输出转换后的二进制代码。
System.out.print(b[i]);
}
当从Unicode编码向某个字符集转换时,如果在该字符集中没有对应的编码,则得到0x3f(即问号字符?)。这就是为什么有时候我们输入的是中文,在输出时却变成了问号。
从其他字符集向Unicode编码转换时,如果这个二进制数在该字符集中没有标识任何的字符,则得到的结果是0xfffd。例如一个GBK的编码值0x8140,从GB2312向Unicode转换,然而由于0x8140不在GB2312字符集的编码范围(0xa1a1-0xfefe),当然也就没有对应任何的字符,所以转换后会得到0xfffd。下面的代码演示了这一过程。
/构造一个二进制数据。
byte[] buf={(byte)0x81,(byte)0x40,(byte)0xb0,(byte)0xa1};
//将二进制数据按照GB2312向Unicode编码转换。
String str=new String(buf,"GB2312");
for(int i=0;i<str.length();i++)
{
//取出字符串中的每个Unicode编码的字符。
char ch=str.charAt(i);
//将该字符对应的Unicode编码以十六进制的形式输出。
System.out.print(Integer.toHexString((int)ch));
System.out.print("--");
//输出该字符。
System.out.println(ch);
}
在输出字符和字符串的时候,会从Unicode编码向中文系统默认的编码GBK转换,由于Unicode编码0xfffd在GBK字符集中没有对应的编码,于是得到0x3f,输出字符“?”。最后输出的结果如下:
fffd--?
40--@
554a--啊
从上述所知,由于存在着多种不同的字符集,在各种字符集之间进行转换,就有可能出现乱码,同样是中文字符集GB2312和GBK,由于编码范围的不同,某些字符在转换时也会出现乱码。
在一个使用了数据库的Web应用程序中,乱码可能会在多个环节产生。由于浏览器会根据本地系统默认的字符集来提交数据,而Web容器默认采用的是ISO-8859-1的编码方式解析POST数据,在浏览器提交中文数据后,Web容器会按照ISO-8859-1字符集来解码数据,在这一环节可能会导致乱码的产生。由于大多数数据库的JDBC驱动程序默认采用ISO-8859-1的编码方式在Java程序和数据库之间传递数据,我们的程序在向数据库中存储包含中文的数据时,JDBC驱动首先将程序内部的Unicode编码格式的数据转化为ISO-8859-1的格式,然后传递到数据库中,在这一环节可能会导致乱码的产生。目前流行的关系型数据库系统都支持数据库编码,也就是说在创建数据库时可以指定它自己的字符集设置,数据库的数据以指定的编码形式存储。当JDBC驱动向数据库中保存数据时,有可能还会发生字符集的转换。正是由于在Web应用程序运行过程中,输入的中文字符需要在不同的字符集之间来回转换,也就导致了中文乱码问题的频繁出现。
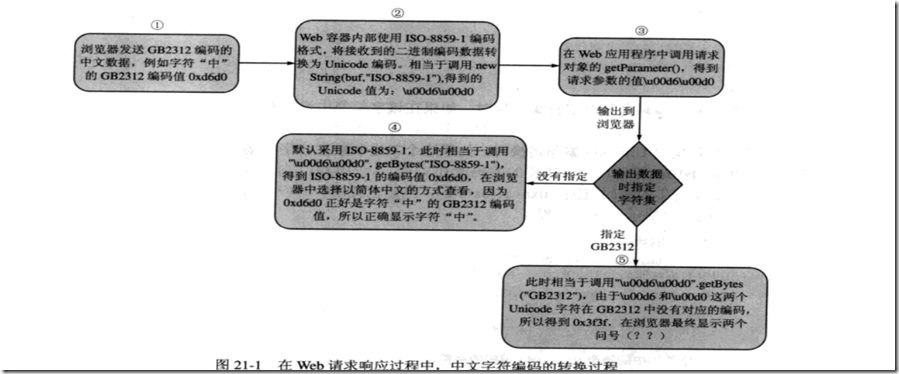
图17-1 描述了在Web应用的请求响应过程中,发生的字符编码转换过程,其中浏览器是IE 6.0,Web容器的是Tomcat 6.0.16。
从图17-1 描述的过程中可以看到,如果在Web应用程序中不指定任何的字符集,从浏览器端传来的中文字符,输出回浏览器时,可以正常显示(以简体中文的方式查看网页)。然而,事情并没有这么简单,在Servlet/JSP中,可能存在着直接写入的或从其他来源读取的中文字符,如果这些字符对应的Unicode码是从GB2312编码转换而来,那么以ISO-8859-1编码方式输出,这些字符将不能正常显示。所以对于中文的处理,应该在图17-1②和⑤的位置明确指定使用GB2312或GBK字符集。
二、中文乱码问题的解决方案
1.以POST方法提交的表单数据中有中文字符
由于Web容器默认的编码方式是ISO-8859-1,在Servlet/JSP程序中,通过请求对象的getParameter()方法得到的字符串是以ISO-8859-1转换而来,这是导致乱码产生的原因之一。为了避免容器以ISO-8859-1的编码方式返回字符串,对于以POST方法提交的表单数据,可以在获取请求参数值之前,调用request.setCharacterEncoding("GBK"),明确指定请求正文使用的字符编码方式是GBK。在向浏览器发送中文数据之前,调用response.setContentType("text/html;charset=GBK"),指定输出内容的编码方式是GBK。
对于JSP页面,在获取请求参数值之前,写上下面的代码:
<%request.setCharacterEncoding("GB2312");%>
为了指定输出内容的编码格式,设置page指令contentType属性,如下:
<%@ page contentType="text/html; charset=GBK" %>
在Web容器转换JSP页面后的Servlet类中,会自动添加下面的代码:
response.setContentType("text/html; charset=GBK");
2.以GET方法提交的表单数据中有中文字符
当提交表单采用GET方法时,提交的数据作为查询字符串被附加到URL的末端,发送到服务器,此时在服务器端调用setCharacterEncoding()方法也就没有作用了。我们需要在得到请求参数的值后,自己做正确的编码转换。
String name = request.getParameter("name");
name=new String(name.getBytes("ISO-8859-1"),"GBK");
在第一行,调用getParameter()方法得到的字符串name的Unicode值是以ISO-8859-1编码转换而来,调用name.getBytes("ISO-8859-1"),将得到原始的GBK编码值,接着,对new String()的调用将以GBK字符集重新构造字符串的Unicode编码。
为了方便从ISO-8859-1编码到GBK的转换,我们可以编写一个工具方法,如下:
public String toGBK(String str)
throws java.io.UnsupportedEncodingException
{
return new String(str.getBytes("ISO-8859-1"),"GBK");
}
3.在数据库中存储和读取中文数据
对于大多数数据库的JDBC驱动程序,在Java程序和数据库之间传递数据都是以ISO-8859-1为默认编码格式,所以,我们在程序中向数据库存储包含中文的数据时,JDBC驱动程序首先把程序内部的Unicode编码格式的数据转化为ISO-8859-1编码,然后传递到数据库中,加上数据库本身也有字符集,这就是为什么我们常常在数据库中读取中文数据时,读到的是乱码。
要解决上述问题,只需要将数据库默认的编码格式改为GBK或GB2312即可,不同的数据库还提供了另外的方式来处理字符编码转换的问题,读者在实际应用过程中,可针对具体情况再做具体处理,只要理解了编码转换的过程,就能找到问题的所在,进而解决问题。
4.Servlet/JSP在不同语言系统的平台下运行
有时候,我们在中文系统平台下开发的Web应用程序移植到英文系统平台下,在Servlet和JSP中直接书写的中文字符串在输出时,将显示为乱码。这是因为在编译Servlet类或者JSP文件时,如果没有使用-encoding参数指定Java源程序的编码格式,javac会获取本地操作系统默认采用的字符集,以该字符集将Java源程序转换为Unicode编码保存到内存中,然后将源程序编译为字节码文件(字节码文件采用的是UTF-8编码),保存到硬盘上。
在英文平台下,采用的默认编码格式是ISO-8859-1,所以在编译转换后,执行输出时,原先在源文件中书写的中文字符串就变成了乱码。
要解决这个问题,在编译Servlet类的源程序时,可以用-encoding参数指定编码为GBK或GB2312,例如:
javac –encoding GBK HelloServlet.java
对于JSP页面,只要在page指令中用contentType属性或pageEncoding属性指定编码格式为GBK或GB2312,Web容器就可以正确转换和编译JSP文件了。例如:
<%@ page contentType="text/html; charset=GBK" %>
或
<%@ page pageEncoding="GBK" %>
在实际的Web应用中,乱码问题产生的原因多种多样,然而只要我们理解了字符编码的转换过程,仔细地分析乱码产生的原因,找到问题的关键,就能对症下药,解决问题。
三、使用过滤器(filter)解决中文乱码问题
1、Filter工作原理(执行流程)
当客户端发出Web资源的请求时,Web服务器根据应用程序配置文件设置的过滤规则进行检查,若客户请求满足过滤规则,则对客户请求/响应进行拦截,对请求头和请求数据进行检查或改动,并依次通过过滤器链,最后把请求/响应交给请求的Web资源处理。请求信息在过滤器链中可以被修改,也可以根据条件让请求不发往资源处理器,并直接向客户机发回一个响应。当资源处理器完成了对资源的处理后,响应信息将逐级逆向返回。同样在这个过程中,用户可以修改响应信息,从而完成一定的任务。
过滤器实际上就是一个java类,在myeclipse中新建类,输入以下代码:
package org.sunxin.lesson.jsp.ch21; import java.io.IOException;
import javax.servlet.*; public class SetCharacterEncodingFilter implements Filter
{
protected String encoding = null;
protected FilterConfig filterConfig = null;
protected boolean ignore = true; public void init(FilterConfig filterConfig) throws ServletException
{
this.filterConfig = filterConfig;
this.encoding = filterConfig.getInitParameter("encoding");
String value = filterConfig.getInitParameter("ignore"); if (value == null)
this.ignore = true;
else if (value.equalsIgnoreCase("true"))
this.ignore = true;
else if (value.equalsIgnoreCase("yes"))
this.ignore = true;
else
this.ignore = false;
} public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws IOException, ServletException
{
if (ignore || (request.getCharacterEncoding() == null))
{
String encoding = selectEncoding(request);
if (encoding != null)
request.setCharacterEncoding(encoding);
}
response.setContentType("text/html; charset="+encoding);
chain.doFilter(request, response);
} protected String selectEncoding(ServletRequest request)
{
return (this.encoding);
} public void destroy()
{
this.encoding = null;
this.filterConfig = null;
}
}

配置工程目录下WEB-INF的web.xml文件(这一步非常关键)
<filter>
<filter-name>SetCharacterEncodingFilter</filter-name>
<filter-class>org.sunxin.lesson.jsp.ch21.SetCharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>GBK</param-value>
</init-param>
<init-param>
<param-name>ignore</param-name>
<param-value>true</param-value>
</init-param>
</filter> <filter-mapping>
<filter-name>SetCharacterEncodingFilter</filter-name>
<url-pattern>/*</url-pattern> </filter-mapping>
如果web.xml配置错误,则web应用无法启动!
四、让tomcat支持中文
在tomcat安装目录下server.xml中添加UTF-8编码方式
<Connector port="8008" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"
URIEncoding="UTF-8" />
只需添加URIEncoding="UTF-8" 即可
本文主要参考自孙鑫老师的《java web开发详解》,有兴趣的可以参考原文,其后还有关于代码国际化的讲述。
本文在整理过程中难免有纰漏,如有错误,敬请指出与改正!
JSP中文乱码问题的由来以及解决方法的更多相关文章
- Code:Blocks 中文乱码问题原因分析和解决方法
下面说说修改的地方. 1.修改源文件保存编码在:settings->Editor->gernal settings 看到右边的Encoding group Box了吗?如下图所示: Use ...
- jsp 中文乱码????解决
中文乱码是个非常蛋疼的问题,在页面表单提交的时候后台获取数据变成了????,解决方案如下: 1:确认编码都是一致的如页面和后台都设置为utf-8 2:String str = new String(r ...
- Servlet 中文乱码问题解析及详细解决方法
使用 servlet 向客户端浏览器回送中文时,经常出现中文乱码的问题,这里给大家完完全全地搞明白: 一.基本常识 中文系统默认是 GBK 编码(GBK是对GB2312的补充,包含它) 需要处理编码问 ...
- Python BeautifulSoup中文乱码问题的2种解决方法
解决方法一: 使用python的BeautifulSoup来抓取网页然后输出网页标题,但是输出的总是乱码,找了好久找到解决办法,下面分享给大家首先是代码 from bs4 import Beautif ...
- XFTP连接主机文件名显示中文乱码且不能下载的解决方法
Xftp连接主机文件名显示中文乱码且不能下载的本地解决方法 原因:Xftp编码格式问题 解决方法:把Xftp的编码格式增加UTF-8 具体步骤:打开Xftp,文件-属性,在打开的属性界面中打开&quo ...
- php -- 解决php连接sqlserver2005中文乱码问题(附详细解决方法)
@_@~~ --php5.2 --phpstudy --apache --sqlserver2005 @_@~~问题描述 问题一:php连接sqlsever2005,输入中文,然后查询sqlserve ...
- 对于使用了SSH造成的中文乱码问题,4大解决方法
修改struts2.xml struts2.xml 中添加 <constant name="struts.i18n.encoding" value="UTF-8&q ...
- Tomcat中文乱码问题的原理和解决方法
1) 更改 D:\Tomcat\conf\server.xml,指定浏览器的编码格式为“简体中文”: 方法是找到 server.xml 中的 <Connector port="8080 ...
- 如何配置Filter过滤器处理JSP中文乱码
参考Tomcat服务器目录webapps的examples示例 简单配置步骤:1.在项目web.xml文件添加过滤器标记<filter>和<filter-mapping>:2. ...
随机推荐
- Objective-C学习笔记(二十二)——初始化方法init的重写与自己定义
初学OC.对init这种方法不是非常了解.我们如今来分别对init方法进行重写以及自己定义,来加深对他的了解. 本样例也是用Person类来进行測试. (一)重写init方法. (1)在Person. ...
- ORACLE 树形查询 树查询
前台树结构依据个人的权限登录变化 全部我查询要依据 树的ID 查询以下全部的子节点 以及本节点的信息 select * from table start with id = #{id} connect ...
- android中图型的阴影效果(shadow-effect-with-custom-shapes)
思路: 在自己定义shape中添加一层或多层,并错开.就可以显示阴影效果.为添加立体感,button按下的时候,仅仅设置一层.我们能够通过top, bottom, right 和 left 四个參数来 ...
- 【cl】找不到火狐Cannot find firefox binary in PATH
org.openqa.selenium.WebDriverException: Cannot find firefox binary in PATH. Make sure firefox is ins ...
- leetCode(30):Sort Colors
Given an array with n objects colored red, white or blue, sort them so that objects of the same colo ...
- nyoj--523--亡命逃窜(BFS水题)
亡命逃窜 时间限制:1000 ms | 内存限制:65535 KB 难度:4 描述 从前有个叫hck的骑士,为了救我们美丽的公主,潜入魔王的老巢,够英雄吧.不过英雄不是这么好当的.这个可怜的娃被魔 ...
- curl ,post,get (原创)
curl get: 1)直接输出 $ch=curl_init(); curl_setopt($ch,CURLOPT_URL,"http://testopen.api.yaolan.com/a ...
- Koa 中实现 chunked 数据传输
有关于 Transfer-Encoding:chunked 类型的响应,参见之前的文章HTTP 响应的分块传输.这里看 Koa 中如何实现. Koa 中请求返回的处理 虽然官方文档有描述说明不建议直接 ...
- 小程序:前端防止用户重复提交&即时消息(IM)重复发送问题解决
背景: 最近参与开发的小程序,涉及到即时消息(IM)发送的功能: 聊天界面如下,通过键盘上的[发送]按钮,触发消息发送功能 问题发现: 功能开发完毕,进入测试流程:测试工程师反馈说: 在Android ...
- GStreamer基础教程02 - 基本概念
摘要 在 Gstreamer基础教程01 - Hello World中,我们介绍了如何快速的通过一个字符串创建一个简单的pipeline.为了能够更好的控制pipline中的element,我们需要单 ...