sqoop配置安装以及导入
安装sqoop的前提是已经具备java和hadoop的环境
1.上传并解压


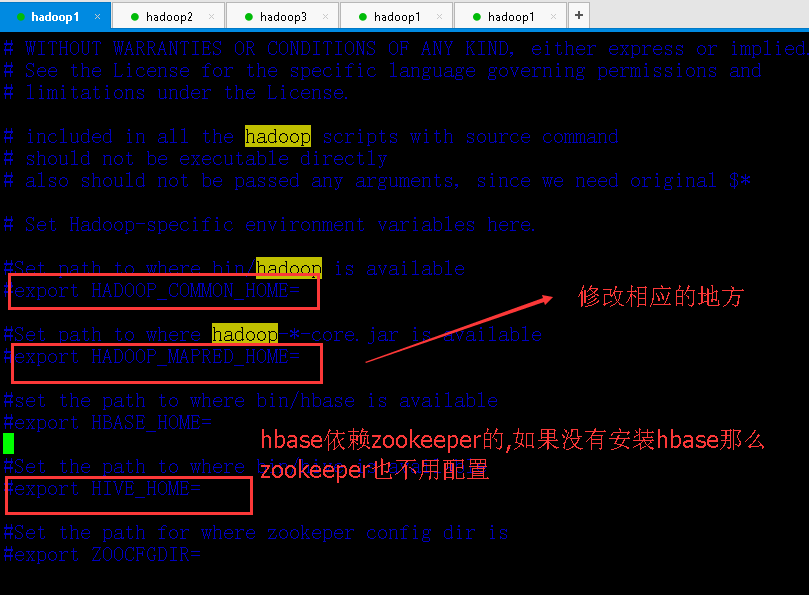

(要导mysql的数据)得加入mysql的jdbc驱动包
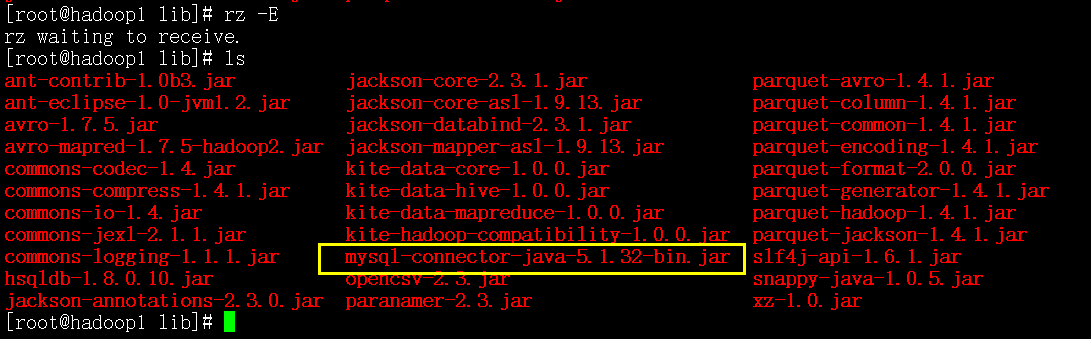
接下来验证启动

Sqoop的数据导入
“导入工具”导入单个表从RDBMS到HDFS。表中的每一行被视为HDFS的记录。所有记录都存储为文本文件的文本数据(或者Avro、sequence文件等二进制数据)
语法
下面的语法用于将数据导入HDFS。
|
$ sqoop import (generic-args) (import-args) |
示例
表数据
在mysql中有一个库userdb中三个表:emp, emp_add和emp_contact
表emp:
|
id |
name |
deg |
salary |
dept |
|
1201 |
gopal |
manager |
50,000 |
TP |
|
1202 |
manisha |
Proof reader |
50,000 |
TP |
|
1203 |
khalil |
php dev |
30,000 |
AC |
|
1204 |
prasanth |
php dev |
30,000 |
AC |
|
1205 |
kranthi |
admin |
20,000 |
TP |
表emp_add:
|
id |
hno |
street |
city |
|
1201 |
288A |
vgiri |
jublee |
|
1202 |
108I |
aoc |
sec-bad |
|
1203 |
144Z |
pgutta |
hyd |
|
1204 |
78B |
old city |
sec-bad |
|
1205 |
720X |
hitec |
sec-bad |
表emp_conn:
|
id |
phno |
|
|
1201 |
2356742 |
gopal@tp.com |
|
1202 |
1661663 |
manisha@tp.com |
|
1203 |
8887776 |
khalil@ac.com |
|
1204 |
9988774 |
prasanth@ac.com |
|
1205 |
1231231 |
kranthi@tp.com |
导入表表数据到HDFS
下面的命令用于从MySQL数据库服务器中的emp表导入HDFS。
|
$bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table emp \ --m 1 bin/sqoop import \ --connect jdbc:mysql://hadoop120:3306/hive \ --username root \ --password 111111 \ --table TBLS \ --target-dir /sqoop \ --m 1 |
如果成功执行,那么会得到下面的输出。
|
14/12/22 15:24:54 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 14/12/22 15:24:56 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/cebe706d23ebb1fd99c1f063ad51ebd7/emp.jar ----------------------------------------------------- O mapreduce.Job: map 0% reduce 0% 14/12/22 15:28:08 INFO mapreduce.Job: map 100% reduce 0% 14/12/22 15:28:16 INFO mapreduce.Job: Job job_1419242001831_0001 completed successfully ----------------------------------------------------- ----------------------------------------------------- 14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Transferred 145 bytes in 177.5849 seconds (0.8165 bytes/sec) 14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Retrieved 5 records. |
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据
|
$ $HADOOP_HOME/bin/hadoop fs -cat /user/hadoop/emp/part-m-00000 |
emp表的数据和字段之间用逗号(,)表示。
|
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP |
导入关系表到HIVE
|
bin/sqoop import --connect jdbc:mysql://hdp-node-01:3306/test --username root --password root --table emp --hive-import --m 1 bin/sqoop import --connect jdbc:mysql://hadoop102:3306/sqoop --username root --password 111111 --table sqoop_hive --hive-import --m 1 |
导入到HDFS指定目录
在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。
以下是指定目标目录选项的Sqoop导入命令的语法。
|
--target-dir <new or exist directory in HDFS> |
下面的命令是用来导入emp_add表数据到'/queryresult'目录。
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --target-dir /queryresult \ --table emp --m 1 |
下面的命令是用来验证 /queryresult 目录中 emp_add表导入的数据形式。
|
$HADOOP_HOME/bin/hadoop fs -cat /queryresult/part-m-* |
它会用逗号(,)分隔emp_add表的数据和字段。
|
1201, 288A, vgiri, jublee 1202, 108I, aoc, sec-bad 1203, 144Z, pgutta, hyd 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad |
导入表数据子集
我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
where子句的语法如下。
|
--where <condition> |
下面的命令用来导入emp_add表数据的子集。子集查询检索员工ID和地址,居住城市为:Secunderabad
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --where "city ='sec-bad'" \ --target-dir /wherequery \ --table emp_add --m 1 |
按需导入
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --target-dir /wherequery2 \ --query 'select id,name,deg from emp WHERE id>1207 and $CONDITIONS' \ --split-by id \ --fields-terminated-by '\t' \ --m 1 |
下面的命令用来验证数据从emp_add表导入/wherequery目录
|
$HADOOP_HOME/bin/hadoop fs -cat /wherequery/part-m-* |
它用逗号(,)分隔 emp_add表数据和字段。
|
1202, 108I, aoc, sec-bad 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad |
增量导入
增量导入是仅导入新添加的表中的行的技术。
它需要添加‘incremental’, ‘check-column’, 和 ‘last-value’选项来执行增量导入。
下面的语法用于Sqoop导入命令增量选项。
|
--incremental <mode> --check-column <column name> --last value <last check column value> |
假设新添加的数据转换成emp表如下:
1206, satish p, grp des, 20000, GR
下面的命令用于在EMP表执行增量导入。
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table emp --m 1 \ --incremental append \ --check-column id \ --last-value 1208 |
以下命令用于从emp表导入HDFS emp/ 目录的数据验证。
|
$ $HADOOP_HOME/bin/hadoop fs -cat /user/hadoop/emp/part-m-* 它用逗号(,)分隔 emp_add表数据和字段。 1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR |
下面的命令是从表emp 用来查看修改或新添加的行
|
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*1 这表示新添加的行用逗号(,)分隔emp表的字段。 1206, satish p, grp des, 20000, GR |
3.5 Sqoop的数据导出
将数据从HDFS导出到RDBMS数据库
导出前,目标表必须存在于目标数据库中。
u 默认操作是从将文件中的数据使用INSERT语句插入到表中
u 更新模式下,是生成UPDATE语句更新表数据
语法
以下是export命令语法。
|
$ sqoop export (generic-args) (export-args) |
示例
数据是在HDFS 中“EMP/”目录的emp_data文件中。所述emp_data如下:
|
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR |
1、首先需要手动创建mysql中的目标表
|
$ mysql mysql> USE db; mysql> CREATE TABLE employee ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT, dept VARCHAR(10)); |
2、然后执行导出命令
|
bin/sqoop export \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table employee \ --export-dir /user/hadoop/emp/ |
3、验证表mysql命令行。
|
mysql>select * from employee; 如果给定的数据存储成功,那么可以找到数据在如下的employee表。 +------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | kalil | php dev | 30000 | AC | | 1204 | prasanth | php dev | 30000 | AC | | 1205 | kranthi | admin | 20000 | TP | | 1206 | satish p | grp des | 20000 | GR | +------+--------------+-------------+-------------------+--------+ |
3.6 Sqoop作业
注:Sqoop作业——将事先定义好的数据导入导出任务按照指定流程运行
语法
以下是创建Sqoop作业的语法。
|
$ sqoop job (generic-args) (job-args) [-- [subtool-name] (subtool-args)] $ sqoop-job (generic-args) (job-args) [-- [subtool-name] (subtool-args)] |
创建作业(--create)
在这里,我们创建一个名为myjob,这可以从RDBMS表的数据导入到HDFS作业。
|
bin/sqoop job --create myimportjob -- import --connect jdbc:mysql://hdp-node-01:3306/test --username root --password root --table emp --m 1 |
该命令创建了一个从db库的employee表导入到HDFS文件的作业。
验证作业 (--list)
‘--list’ 参数是用来验证保存的作业。下面的命令用来验证保存Sqoop作业的列表。
$ sqoop job --list
它显示了保存作业列表。
Available jobs:
myimportjob
检查作业(--show)
‘--show’ 参数用于检查或验证特定的工作,及其详细信息。以下命令和样本输出用来验证一个名为myjob的作业。
$ sqoop job --show myjob
它显示了工具和它们的选择,这是使用在myjob中作业情况。
|
Job: myjob Tool: import Options: ---------------------------- direct.import = true codegen.input.delimiters.record = 0 hdfs.append.dir = false db.table = employee ... incremental.last.value = 1206 ... |
执行作业 (--exec)
‘--exec’ 选项用于执行保存的作业。下面的命令用于执行保存的作业称为myjob。
|
$ sqoop job --exec myjob 它会显示下面的输出。 10/08/19 13:08:45 INFO tool.CodeGenTool: Beginning code generation ... |
3.7 Sqoop的原理
概述
Sqoop的原理其实就是将导入导出命令转化为mapreduce程序来执行,sqoop在接收到命令后,都要生成mapreduce程序
使用sqoop的代码生成工具可以方便查看到sqoop所生成的java代码,并可在此基础之上进行深入定制开发
代码定制
以下是Sqoop代码生成命令的语法:
|
$ sqoop-codegen (generic-args) (codegen-args) $ sqoop-codegen (generic-args) (codegen-args) |
示例:以USERDB数据库中的表emp来生成Java代码为例。
下面的命令用来生成导入
|
$ sqoop-codegen \ --import --connect jdbc:mysql://localhost/userdb \ --username root \ --table emp |
如果命令成功执行,那么它就会产生如下的输出。
|
14/12/23 02:34:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 14/12/23 02:34:41 INFO tool.CodeGenTool: Beginning code generation ………………. 14/12/23 02:34:42 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop Note: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 14/12/23 02:34:47 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.jar |
验证: 查看输出目录下的文件
|
$ cd /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/ $ ls emp.class emp.jar emp.java |
如果想做深入定制导出,则可修改上述代码文件
sqoop配置安装以及导入的更多相关文章
- Sqoop安装配置及数据导入导出
前置条件 已经成功安装配置Hadoop和Mysql数据库服务器,如果将数据导入或从Hbase导出,还应该已经成功安装配置Hbase. 下载sqoop和Mysql的JDBC驱动 sqoop-1.2.0- ...
- Sqoop的安装配置及使用
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- Sqoop 组件安装与配置
下载和解压 Sqoop Sqoop相关发行版本可以通过官网 https://mirror-hk.koddos.net/apache/sqoop/ 来获取 安装 Sqoop组件需要与 Hadoop环境适 ...
- 【sqoop】安装配置测试sqoop1
3.1.1 下载sqoop1:sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 3.1.2 解压并查看目录: [hadoop@hadoop01 ~]$ tar -zxvf sq ...
- 大数据之路week07--day06 (Sqoop 的安装及配置)
Sqoop 的安装配置比较简单. 提供安装需要的安装包和连接mysql的驱动的百度云链接: 链接:https://pan.baidu.com/s/1pdFj0u2lZVFasgoSyhz-yQ 提取码 ...
- Hadoop学习笔记: sqoop配置与使用
sqoop即SQL-to-Hadoop,是一个把数据从关系型数据库导入到Hadoop系统中的工具(HDFS,HIVE和HBase),也可以将数据从Hadoop导入到关系型数据库.本文以sqoop 1. ...
- 使用sqoop将mysql数据导入到hadoop
hadoop的安装配置这里就不讲了. Sqoop的安装也很简单. 完成sqoop的安装后,可以这样测试是否可以连接到mysql(注意:mysql的jar包要放到 SQOOP_HOME/lib 下): ...
- sqoop的安装
Sqoop是一个用来完成Hadoop和关系型数据库中的数据相互转移的工具, 他可以将关系型数据库(MySql,Oracle,Postgres等)中的数据导入Hadoop的HDFS中, 也可以将HDFS ...
- sqoop工具从oracle导入数据2
sqoop工具从oracle导入数据 sqoop工具是hadoop下连接关系型数据库和Hadoop的桥梁,支持关系型数据库和hive.hdfs,hbase之间数据的相互导入,可以使用全表导入和增量导入 ...
随机推荐
- 【万里征程——Windows App开发】控件大集合2
以下再来看看一些前面还没有讲过的控件,只是控件太多以至于无法所有列出来,大家仅仅好举一反三啦. Button 前面最经常使用的控件就是Button啦,Button另一个有意思的属性呢.当把鼠标指针放在 ...
- POI 导入excel数据自己主动封装成model对象--代码分析
上完代码后,对代码进行基本的分析: 1.主要使用反射api将数数据注入javabean对象 2.代码中的日志信息级别为debug级别 3.获取ExcelImport对象后须要调用init()方法初始化 ...
- NHibernate3剖析:Query篇之NHibernate.Linq增强查询
系列引入 NHibernate3.0剖析系列分别从Configuration篇.Mapping篇.Query篇.Session策略篇.应用篇等方面全面揭示NHibernate3.0新特性和应用及其各种 ...
- Go语言Slice操作.
1.基本使用方法: a = append(a, b...) 比如:list = appened(list,[]int{1,2,3,4}...) 能够用来合并两个列表. 不用这样了 :list := m ...
- Windows下ElasticSearch及相关插件的安装
(1)在官网下载ElasticSearch压缩包.这里我下载的是elasticsearch-1.7.1(下载地址:https://download.elastic.co/elasticsearch/e ...
- Python爬糗百热门20条并邮件分发+wxPython简易GUI+py2app转成可运行文件
学了一阵子Python,拿来做个什么有意思的东西呢?爬糗百好了.爬到的内容,邮件分发出去. 然后又啃了两天的wxpython,做了个简易的邮件管理界面,能够在这里添加或者删除邮件,而且一键爬虫发送. ...
- [ZJOJ2014] 力 解题报告 (FFT)
题目链接: https://www.luogu.org/problemnew/show/P3338 题目: 给出$n$个数$q_i$,令$F_j=\sum_{i<j}\frac{q_iq_j}{ ...
- vue中router-link的click事件失效的解决办法
title: vue中router-link的click事件失效的解决办法 toc: false date: 2018-12-04 16:28:49 categories: Web tags: vue ...
- Creative Cloud 安装出错,错误代码:207
C:\Users\xxx\AppData\Local\Temp\CreativeCloud\ACC\AdobeDownload %Temp%\CreativeCloud\ACC\AdobeDownlo ...
- python 3.x 学习笔记13 (网络编程socket)
1.协议http.smtp.dns.ftp.ssh.snmp.icmp.dhcp....等具体自查 2.OSI七层应用.表示.会话.传输.网络.数据链路.物理 3.socket: 对所有上层协议的封装 ...