Elasticsearch之中文分词器插件es-ik的自定义热更新词库
不多说,直接上干货!
前提
Elasticsearch之中文分词器插件es-ik的自定义词库
先声明,热更新词库,需要用到,web项目和Tomcat。不会的,请移步
Eclipse下Maven新建项目、自动打依赖jar包(包含普通项目和Web项目)
Tomcat *的安装和运行(绿色版和安装版都适用)
Tomcat的配置文件详解
1: 部署 http 服务
在这使用 tomcat7 作为 web 容器, 先下载一个 tomcat7, 然后上传到某一台服务器上(192.168.80.10)。
再执行以下命令
tar -zxvf apache-tomcat-7.0.73.tar.gz
cd apache-tomcat-7.0.73/webapp/ROOT
vi hot.dic
测试
在这里,我是为了避免跟我的hadoop和spark集群里的端口冲突,将默认的tomcat8080端口,改为8081端口了。
在CentOS下安装tomcat并配置环境变量(改默认端口8080为8081)
如果,是3台tomcat集群的话,则对应,比如我的192.168.80.10位8081端口,192.168.80.11位8082端口,192.168.80.12位8083端口
验证一下这个文件是否可以正常访问
http://192.168.80.10:/zhoulshot.dic

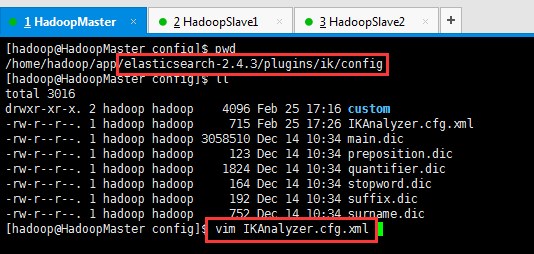
2: 修改 ik 插件的配置文件
cd elasticsearch-2.4.3/plugins/ik/config
vi IKAnalyzer.cfg.xml
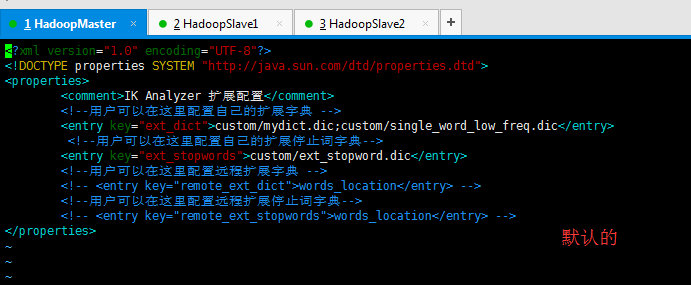
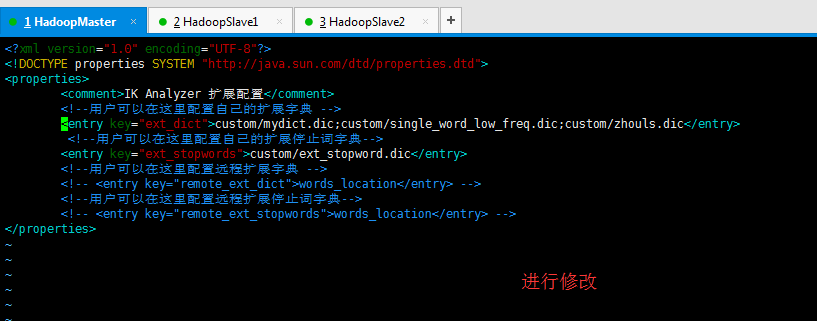
修改 key=remote_ext_dict 的 entry 中的内容
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic;custom/zhouls.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.80.10:8081/zhoulshot.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
注意:(1)默认是words_location,我这里改为我自己的了。http://192.168.80.10:8081/zhoulshot.dic (自定义词库)
(2)默认是custom/mydict.dic;custom/single_word_low_freq.dic,我这里改为我自己的了。 (自定义热更新词库) custom/mydict.dic;custom/single_word_low_freq.dic;custom/zhouls.dic
3: 验证
重启 es, 会看到如下日志信息, 说明远程的词典加载成功了。
执行下面命令查看分词效果
curl 'http://192.168.80.10:9200/zhouls/_analyze?analyzer=ik_max_word&pretty=true' -d '{"text":"桂林山水"}'
正常情况下桂林山水会分为多个词语, 但是我们希望 es 把[桂林山水]作为一个完整的词, 又不希望重启 es。
这样就需要修改前面的 zhoulshot.dic 文件, 增加一个词语[桂林山水]
vi hot.dic
桂林山水
文件保存之后, 查看 es 的日志会看到如下日志信息
再执行下面命令查看分词效果
curl 'http://192.168.80.10:9200/zhouls/_analyze?analyzer=ik_max_word&pretty=true' -d '{"text":"桂林山水"}'
到这为止, 可以实现动态添加自定义词库实现词库热更新。
==============================================================================
注意: 默认情况下, 最多一分钟之内就可以识别到新增的词语。
查看 es-ik 插件的源码可以发现
1: 部署 http 服务
第一步:下载tomcat压缩包
http://archive.apache.org/dist/tomcat/tomcat-7/v7.0.73/bin/


第二步:上传tomcat压缩包
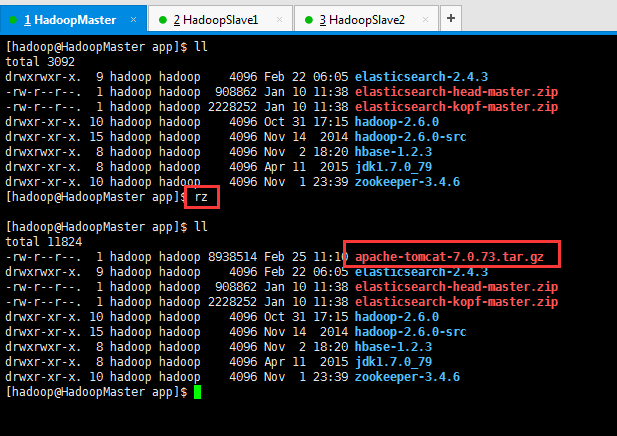
[hadoop@HadoopMaster app]$ ll
total 3092
drwxrwxr-x. 9 hadoop hadoop 4096 Feb 22 06:05 elasticsearch-2.4.3
-rw-r--r--. 1 hadoop hadoop 908862 Jan 10 11:38 elasticsearch-head-master.zip
-rw-r--r--. 1 hadoop hadoop 2228252 Jan 10 11:38 elasticsearch-kopf-master.zip
drwxr-xr-x. 10 hadoop hadoop 4096 Oct 31 17:15 hadoop-2.6.0
drwxr-xr-x. 15 hadoop hadoop 4096 Nov 14 2014 hadoop-2.6.0-src
drwxrwxr-x. 8 hadoop hadoop 4096 Nov 2 18:20 hbase-1.2.3
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
drwxr-xr-x. 10 hadoop hadoop 4096 Nov 1 23:39 zookeeper-3.4.6
[hadoop@HadoopMaster app]$ rz
[hadoop@HadoopMaster app]$ ll
total 11824
-rw-r--r--. 1 hadoop hadoop 8938514 Feb 25 11:10 apache-tomcat-7.0.73.tar.gz
drwxrwxr-x. 9 hadoop hadoop 4096 Feb 22 06:05 elasticsearch-2.4.3
-rw-r--r--. 1 hadoop hadoop 908862 Jan 10 11:38 elasticsearch-head-master.zip
-rw-r--r--. 1 hadoop hadoop 2228252 Jan 10 11:38 elasticsearch-kopf-master.zip
drwxr-xr-x. 10 hadoop hadoop 4096 Oct 31 17:15 hadoop-2.6.0
drwxr-xr-x. 15 hadoop hadoop 4096 Nov 14 2014 hadoop-2.6.0-src
drwxrwxr-x. 8 hadoop hadoop 4096 Nov 2 18:20 hbase-1.2.3
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
drwxr-xr-x. 10 hadoop hadoop 4096 Nov 1 23:39 zookeeper-3.4.6
[hadoop@HadoopMaster app]$
第三步:解压缩

[hadoop@HadoopMaster app]$ tar -zxvf apache-tomcat-7.0.73.tar.gz
第四步:删除压缩包
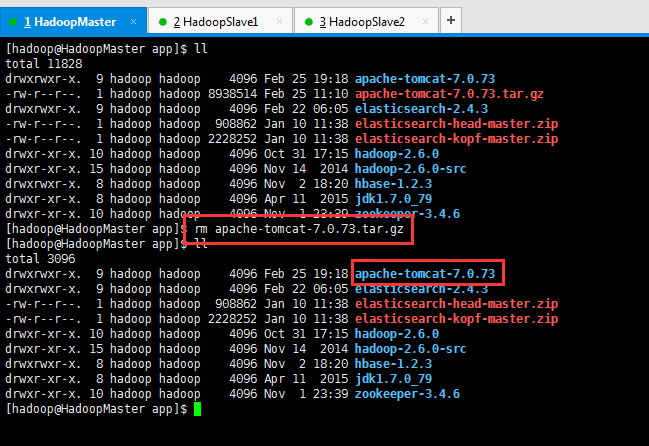
[hadoop@HadoopMaster app]$ ll
total 11828
drwxrwxr-x. 9 hadoop hadoop 4096 Feb 25 19:18 apache-tomcat-7.0.73
-rw-r--r--. 1 hadoop hadoop 8938514 Feb 25 11:10 apache-tomcat-7.0.73.tar.gz
drwxrwxr-x. 9 hadoop hadoop 4096 Feb 22 06:05 elasticsearch-2.4.3
-rw-r--r--. 1 hadoop hadoop 908862 Jan 10 11:38 elasticsearch-head-master.zip
-rw-r--r--. 1 hadoop hadoop 2228252 Jan 10 11:38 elasticsearch-kopf-master.zip
drwxr-xr-x. 10 hadoop hadoop 4096 Oct 31 17:15 hadoop-2.6.0
drwxr-xr-x. 15 hadoop hadoop 4096 Nov 14 2014 hadoop-2.6.0-src
drwxrwxr-x. 8 hadoop hadoop 4096 Nov 2 18:20 hbase-1.2.3
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
drwxr-xr-x. 10 hadoop hadoop 4096 Nov 1 23:39 zookeeper-3.4.6
[hadoop@HadoopMaster app]$ rm apache-tomcat-7.0.73.tar.gz
[hadoop@HadoopMaster app]$ ll
total 3096
drwxrwxr-x. 9 hadoop hadoop 4096 Feb 25 19:18 apache-tomcat-7.0.73
drwxrwxr-x. 9 hadoop hadoop 4096 Feb 22 06:05 elasticsearch-2.4.3
-rw-r--r--. 1 hadoop hadoop 908862 Jan 10 11:38 elasticsearch-head-master.zip
-rw-r--r--. 1 hadoop hadoop 2228252 Jan 10 11:38 elasticsearch-kopf-master.zip
drwxr-xr-x. 10 hadoop hadoop 4096 Oct 31 17:15 hadoop-2.6.0
drwxr-xr-x. 15 hadoop hadoop 4096 Nov 14 2014 hadoop-2.6.0-src
drwxrwxr-x. 8 hadoop hadoop 4096 Nov 2 18:20 hbase-1.2.3
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
drwxr-xr-x. 10 hadoop hadoop 4096 Nov 1 23:39 zookeeper-3.4.6
[hadoop@HadoopMaster app]$
第五步:重命名tomcat安装目录

[hadoop@HadoopMaster app]$ ll
total 3096
drwxrwxr-x. 9 hadoop hadoop 4096 Feb 25 19:18 apache-tomcat-7.0.73
drwxrwxr-x. 9 hadoop hadoop 4096 Feb 22 06:05 elasticsearch-2.4.3
-rw-r--r--. 1 hadoop hadoop 908862 Jan 10 11:38 elasticsearch-head-master.zip
-rw-r--r--. 1 hadoop hadoop 2228252 Jan 10 11:38 elasticsearch-kopf-master.zip
drwxr-xr-x. 10 hadoop hadoop 4096 Oct 31 17:15 hadoop-2.6.0
drwxr-xr-x. 15 hadoop hadoop 4096 Nov 14 2014 hadoop-2.6.0-src
drwxrwxr-x. 8 hadoop hadoop 4096 Nov 2 18:20 hbase-1.2.3
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
drwxr-xr-x. 10 hadoop hadoop 4096 Nov 1 23:39 zookeeper-3.4.6
[hadoop@HadoopMaster app]$ mv apache-tomcat-7.0.73 tomcat-7.0.73
[hadoop@HadoopMaster app]$ ll
total 3096
drwxrwxr-x. 9 hadoop hadoop 4096 Feb 22 06:05 elasticsearch-2.4.3
-rw-r--r--. 1 hadoop hadoop 908862 Jan 10 11:38 elasticsearch-head-master.zip
-rw-r--r--. 1 hadoop hadoop 2228252 Jan 10 11:38 elasticsearch-kopf-master.zip
drwxr-xr-x. 10 hadoop hadoop 4096 Oct 31 17:15 hadoop-2.6.0
drwxr-xr-x. 15 hadoop hadoop 4096 Nov 14 2014 hadoop-2.6.0-src
drwxrwxr-x. 8 hadoop hadoop 4096 Nov 2 18:20 hbase-1.2.3
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
drwxrwxr-x. 9 hadoop hadoop 4096 Feb 25 19:18 tomcat-7.0.73
drwxr-xr-x. 10 hadoop hadoop 4096 Nov 1 23:39 zookeeper-3.4.6
[hadoop@HadoopMaster app]$
第六步:进入tomcat安装目录,并初步认识下
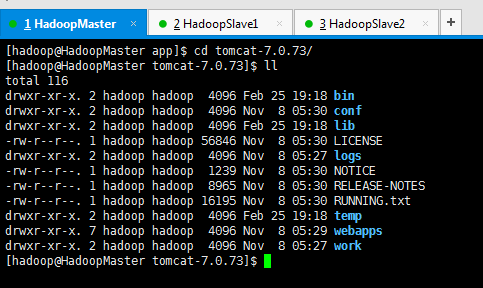
[hadoop@HadoopMaster app]$ cd tomcat-7.0.73/
[hadoop@HadoopMaster tomcat-7.0.73]$ ll
total 116
drwxr-xr-x. 2 hadoop hadoop 4096 Feb 25 19:18 bin
drwxr-xr-x. 2 hadoop hadoop 4096 Nov 8 05:30 conf
drwxr-xr-x. 2 hadoop hadoop 4096 Feb 25 19:18 lib
-rw-r--r--. 1 hadoop hadoop 56846 Nov 8 05:30 LICENSE
drwxr-xr-x. 2 hadoop hadoop 4096 Nov 8 05:27 logs
-rw-r--r--. 1 hadoop hadoop 1239 Nov 8 05:30 NOTICE
-rw-r--r--. 1 hadoop hadoop 8965 Nov 8 05:30 RELEASE-NOTES
-rw-r--r--. 1 hadoop hadoop 16195 Nov 8 05:30 RUNNING.txt
drwxr-xr-x. 2 hadoop hadoop 4096 Feb 25 19:18 temp
drwxr-xr-x. 7 hadoop hadoop 4096 Nov 8 05:29 webapps
drwxr-xr-x. 2 hadoop hadoop 4096 Nov 8 05:27 work
[hadoop@HadoopMaster tomcat-7.0.73]$
在这里,需要,先事先好,在linux下安装好tomcat。并配置好环境变量。不会的,请移步
在CentOS下安装tomcat并配置环境变量
第七步:进入webapps/ROOT目录下
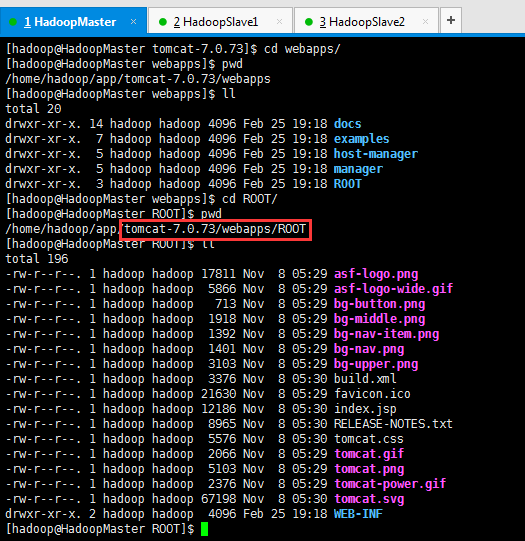
[hadoop@HadoopMaster tomcat-7.0.73]$ cd webapps/
[hadoop@HadoopMaster webapps]$ pwd
/home/hadoop/app/tomcat-7.0.73/webapps
[hadoop@HadoopMaster webapps]$ ll
total 20
drwxr-xr-x. 14 hadoop hadoop 4096 Feb 25 19:18 docs
drwxr-xr-x. 7 hadoop hadoop 4096 Feb 25 19:18 examples
drwxr-xr-x. 5 hadoop hadoop 4096 Feb 25 19:18 host-manager
drwxr-xr-x. 5 hadoop hadoop 4096 Feb 25 19:18 manager
drwxr-xr-x. 3 hadoop hadoop 4096 Feb 25 19:18 ROOT
[hadoop@HadoopMaster webapps]$ cd ROOT/
[hadoop@HadoopMaster ROOT]$ pwd
/home/hadoop/app/tomcat-7.0.73/webapps/ROOT
[hadoop@HadoopMaster ROOT]$ ll
total 196
-rw-r--r--. 1 hadoop hadoop 17811 Nov 8 05:29 asf-logo.png
-rw-r--r--. 1 hadoop hadoop 5866 Nov 8 05:29 asf-logo-wide.gif
-rw-r--r--. 1 hadoop hadoop 713 Nov 8 05:29 bg-button.png
-rw-r--r--. 1 hadoop hadoop 1918 Nov 8 05:29 bg-middle.png
-rw-r--r--. 1 hadoop hadoop 1392 Nov 8 05:29 bg-nav-item.png
-rw-r--r--. 1 hadoop hadoop 1401 Nov 8 05:29 bg-nav.png
-rw-r--r--. 1 hadoop hadoop 3103 Nov 8 05:29 bg-upper.png
-rw-r--r--. 1 hadoop hadoop 3376 Nov 8 05:30 build.xml
-rw-r--r--. 1 hadoop hadoop 21630 Nov 8 05:29 favicon.ico
-rw-r--r--. 1 hadoop hadoop 12186 Nov 8 05:30 index.jsp
-rw-r--r--. 1 hadoop hadoop 8965 Nov 8 05:30 RELEASE-NOTES.txt
-rw-r--r--. 1 hadoop hadoop 5576 Nov 8 05:30 tomcat.css
-rw-r--r--. 1 hadoop hadoop 2066 Nov 8 05:29 tomcat.gif
-rw-r--r--. 1 hadoop hadoop 5103 Nov 8 05:29 tomcat.png
-rw-r--r--. 1 hadoop hadoop 2376 Nov 8 05:29 tomcat-power.gif
-rw-r--r--. 1 hadoop hadoop 67198 Nov 8 05:30 tomcat.svg
drwxr-xr-x. 2 hadoop hadoop 4096 Feb 25 19:18 WEB-INF
[hadoop@HadoopMaster ROOT]$
第八步:新建,自定义的热更新词库。如,我这里,是,zhoulshot.dic
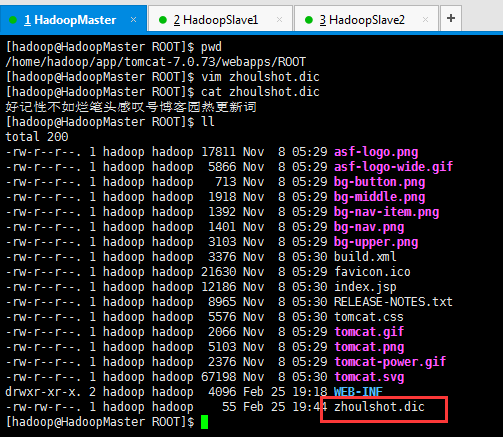
[hadoop@HadoopMaster ROOT]$ pwd
/home/hadoop/app/tomcat-7.0.73/webapps/ROOT
[hadoop@HadoopMaster ROOT]$ vim zhoulshot.dic
[hadoop@HadoopMaster ROOT]$ cat zhoulshot.dic
好记性不如烂笔头感叹号博客园热更新词
[hadoop@HadoopMaster ROOT]$ ll
total 200
-rw-r--r--. 1 hadoop hadoop 17811 Nov 8 05:29 asf-logo.png
-rw-r--r--. 1 hadoop hadoop 5866 Nov 8 05:29 asf-logo-wide.gif
-rw-r--r--. 1 hadoop hadoop 713 Nov 8 05:29 bg-button.png
-rw-r--r--. 1 hadoop hadoop 1918 Nov 8 05:29 bg-middle.png
-rw-r--r--. 1 hadoop hadoop 1392 Nov 8 05:29 bg-nav-item.png
-rw-r--r--. 1 hadoop hadoop 1401 Nov 8 05:29 bg-nav.png
-rw-r--r--. 1 hadoop hadoop 3103 Nov 8 05:29 bg-upper.png
-rw-r--r--. 1 hadoop hadoop 3376 Nov 8 05:30 build.xml
-rw-r--r--. 1 hadoop hadoop 21630 Nov 8 05:29 favicon.ico
-rw-r--r--. 1 hadoop hadoop 12186 Nov 8 05:30 index.jsp
-rw-r--r--. 1 hadoop hadoop 8965 Nov 8 05:30 RELEASE-NOTES.txt
-rw-r--r--. 1 hadoop hadoop 5576 Nov 8 05:30 tomcat.css
-rw-r--r--. 1 hadoop hadoop 2066 Nov 8 05:29 tomcat.gif
-rw-r--r--. 1 hadoop hadoop 5103 Nov 8 05:29 tomcat.png
-rw-r--r--. 1 hadoop hadoop 2376 Nov 8 05:29 tomcat-power.gif
-rw-r--r--. 1 hadoop hadoop 67198 Nov 8 05:30 tomcat.svg
drwxr-xr-x. 2 hadoop hadoop 4096 Feb 25 19:18 WEB-INF
-rw-rw-r--. 1 hadoop hadoop 55 Feb 25 19:44 zhoulshot.dic
[hadoop@HadoopMaster ROOT]$
第九步:验证一下这个zhoulshot热更新词文件是否可以正常访问

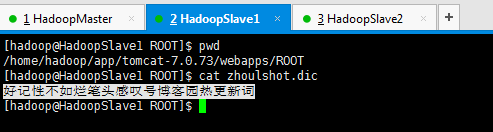
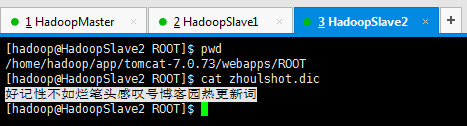
2: 修改 ik 插件的配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic;custom/zhouls.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
修改为
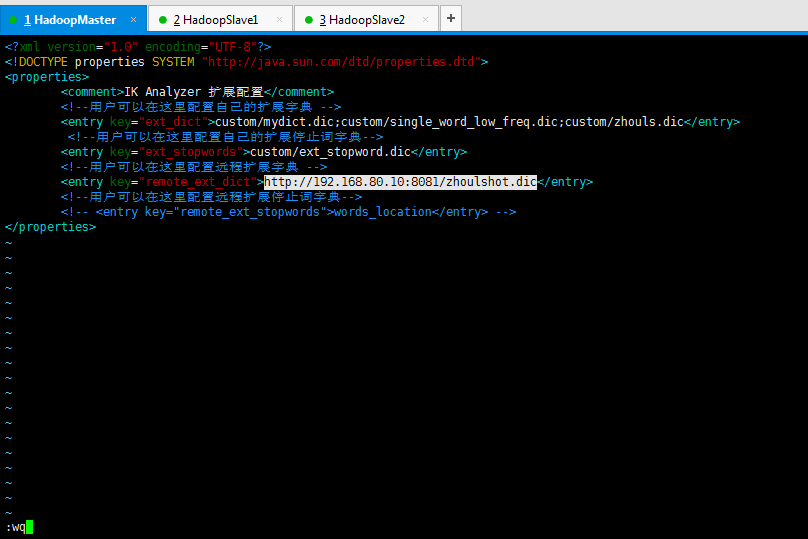
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic;custom/zhouls.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.80.10:8081/zhoulshot.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3: 验证
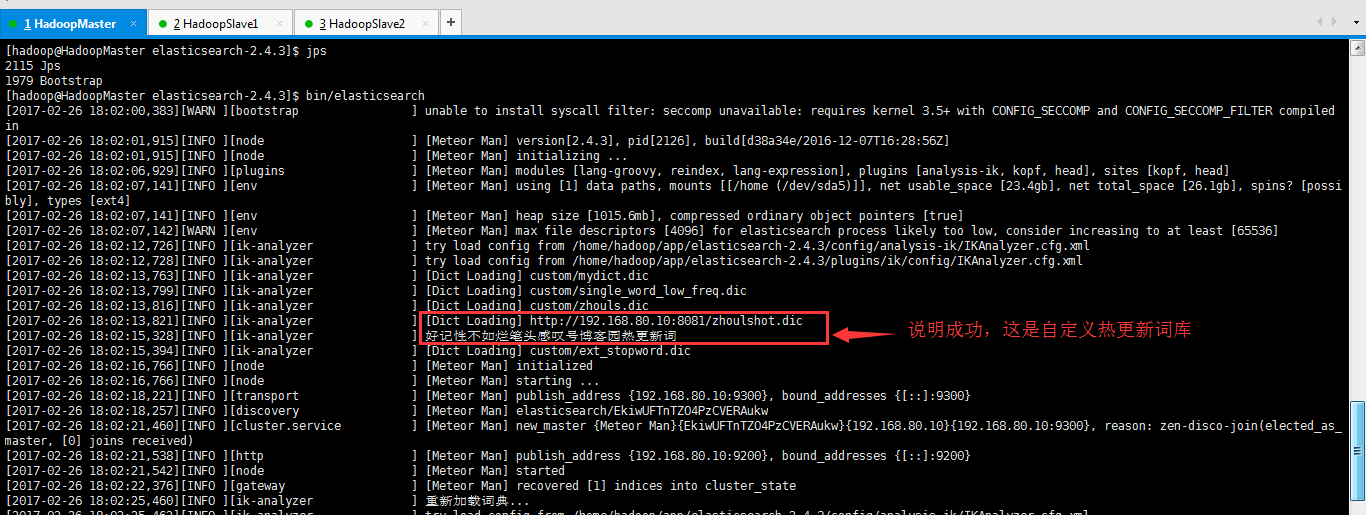
重启 es, 会看到如下日志信息, 说明远程的词典加载成功了。
我这里,为了更好地看出效果,在es的安装目录下,bin/elasticsearch这种方式来启动。
[hadoop@HadoopMaster elasticsearch-2.4.3]$ jps
2115 Jps
1979 Bootstrap
[hadoop@HadoopMaster elasticsearch-2.4.3]$ bin/elasticsearch
[2017-02-26 18:02:00,383][WARN ][bootstrap ] unable to install syscall filter: seccomp unavailable: requires kernel 3.5+ with CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER compiled in
[2017-02-26 18:02:01,915][INFO ][node ] [Meteor Man] version[2.4.3], pid[2126], build[d38a34e/2016-12-07T16:28:56Z]
[2017-02-26 18:02:01,915][INFO ][node ] [Meteor Man] initializing ...
[2017-02-26 18:02:06,929][INFO ][plugins ] [Meteor Man] modules [lang-groovy, reindex, lang-expression], plugins [analysis-ik, kopf, head], sites [kopf, head]
[2017-02-26 18:02:07,141][INFO ][env ] [Meteor Man] using [1] data paths, mounts [[/home (/dev/sda5)]], net usable_space [23.4gb], net total_space [26.1gb], spins? [possibly], types [ext4]
[2017-02-26 18:02:07,141][INFO ][env ] [Meteor Man] heap size [1015.6mb], compressed ordinary object pointers [true]
[2017-02-26 18:02:07,142][WARN ][env ] [Meteor Man] max file descriptors [4096] for elasticsearch process likely too low, consider increasing to at least [65536]
[2017-02-26 18:02:12,726][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/config/analysis-ik/IKAnalyzer.cfg.xml
[2017-02-26 18:02:12,728][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/plugins/ik/config/IKAnalyzer.cfg.xml
[2017-02-26 18:02:13,763][INFO ][ik-analyzer ] [Dict Loading] custom/mydict.dic
[2017-02-26 18:02:13,799][INFO ][ik-analyzer ] [Dict Loading] custom/single_word_low_freq.dic
[2017-02-26 18:02:13,816][INFO ][ik-analyzer ] [Dict Loading] custom/zhouls.dic
[2017-02-26 18:02:13,821][INFO ][ik-analyzer ] [Dict Loading] http://192.168.80.10:8081/zhoulshot.dic
[2017-02-26 18:02:15,328][INFO ][ik-analyzer ] 好记性不如烂笔头感叹号博客园热更新词
[2017-02-26 18:02:15,394][INFO ][ik-analyzer ] [Dict Loading] custom/ext_stopword.dic
[2017-02-26 18:02:16,766][INFO ][node ] [Meteor Man] initialized
[2017-02-26 18:02:16,766][INFO ][node ] [Meteor Man] starting ...
[2017-02-26 18:02:18,221][INFO ][transport ] [Meteor Man] publish_address {192.168.80.10:9300}, bound_addresses {[::]:9300}
[2017-02-26 18:02:18,257][INFO ][discovery ] [Meteor Man] elasticsearch/EkiwUFTnTZO4PzCVERAukw
[2017-02-26 18:02:21,460][INFO ][cluster.service ] [Meteor Man] new_master {Meteor Man}{EkiwUFTnTZO4PzCVERAukw}{192.168.80.10}{192.168.80.10:9300}, reason: zen-disco-join(elected_as_master, [0] joins received)
[2017-02-26 18:02:21,538][INFO ][http ] [Meteor Man] publish_address {192.168.80.10:9200}, bound_addresses {[::]:9200}
[2017-02-26 18:02:21,542][INFO ][node ] [Meteor Man] started
[2017-02-26 18:02:22,376][INFO ][gateway ] [Meteor Man] recovered [1] indices into cluster_state
[2017-02-26 18:02:25,460][INFO ][ik-analyzer ] 重新加载词典...
[2017-02-26 18:02:25,462][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/config/analysis-ik/IKAnalyzer.cfg.xml
[2017-02-26 18:02:25,468][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/plugins/ik/config/IKAnalyzer.cfg.xml
[2017-02-26 18:02:27,090][INFO ][ik-analyzer ] [Dict Loading] custom/mydict.dic
[2017-02-26 18:02:27,092][INFO ][ik-analyzer ] [Dict Loading] custom/single_word_low_freq.dic
[2017-02-26 18:02:27,097][INFO ][ik-analyzer ] [Dict Loading] custom/zhouls.dic
[2017-02-26 18:02:27,098][INFO ][ik-analyzer ] [Dict Loading] http://192.168.80.10:8081/zhoulshot.dic
[2017-02-26 18:02:27,134][INFO ][ik-analyzer ] 好记性不如烂笔头感叹号博客园热更新词
[2017-02-26 18:02:27,138][INFO ][ik-analyzer ] [Dict Loading] custom/ext_stopword.dic
[2017-02-26 18:02:27,140][INFO ][ik-analyzer ] 重新加载词典完毕...
执行下面命令查看分词效果
[hadoop@HadoopMaster elasticsearch-2.4.3]$ jps
2283 Jps
2195 Elasticsearch
1979 Bootstrap
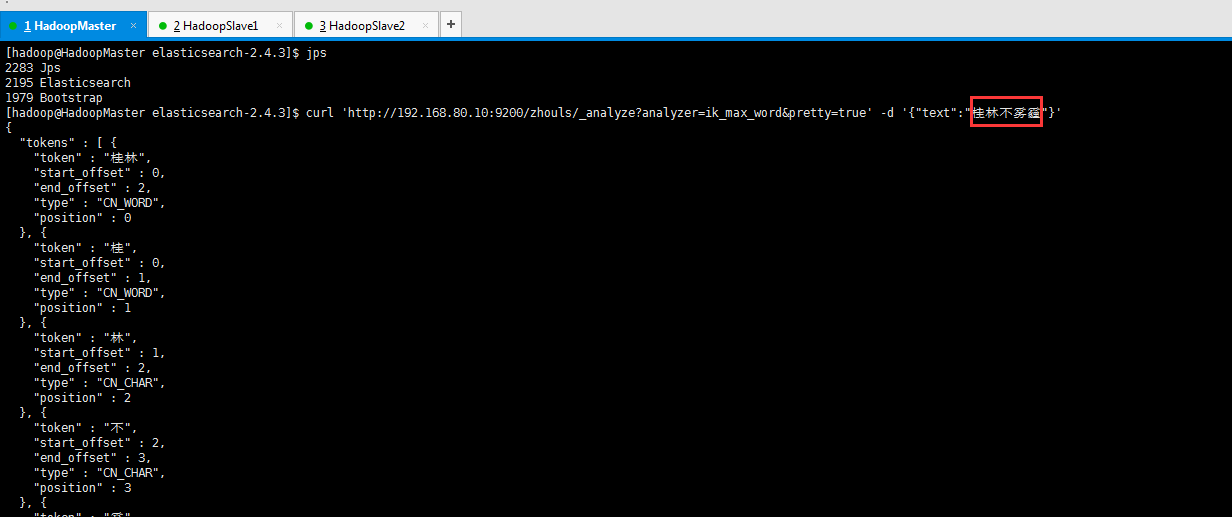
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl 'http://192.168.80.10:9200/zhouls/_analyze?analyzer=ik_max_word&pretty=true' -d '{"text":"桂林不雾霾"}'
{
"tokens" : [ {
"token" : "桂林",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
}, {
"token" : "桂",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_WORD",
"position" : 1
}, {
"token" : "林",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 2
}, {
"token" : "不",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 3
}, {
"token" : "雾",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 4
}, {
"token" : "霾",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 5
} ]
}
[hadoop@HadoopMaster elasticsearch-2.4.3]$
正常情况下桂林不雾霾会分为多个词语, 但是我们希望 es 把[桂林不雾霾]作为一个完整的词, 又不希望重启 es。
这样就需要修改前面的 zhoulshot.dic 文件, 增加一个词语[桂林不雾霾]
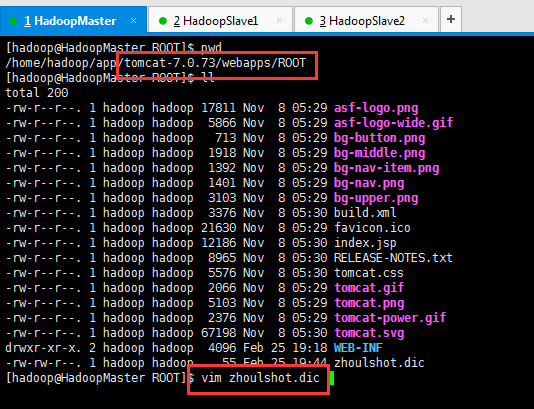
vim zhoulshot.dic
[hadoop@HadoopMaster ROOT]$ pwd
/home/hadoop/app/tomcat-7.0.73/webapps/ROOT
[hadoop@HadoopMaster ROOT]$ ll
total 200
-rw-r--r--. 1 hadoop hadoop 17811 Nov 8 05:29 asf-logo.png
-rw-r--r--. 1 hadoop hadoop 5866 Nov 8 05:29 asf-logo-wide.gif
-rw-r--r--. 1 hadoop hadoop 713 Nov 8 05:29 bg-button.png
-rw-r--r--. 1 hadoop hadoop 1918 Nov 8 05:29 bg-middle.png
-rw-r--r--. 1 hadoop hadoop 1392 Nov 8 05:29 bg-nav-item.png
-rw-r--r--. 1 hadoop hadoop 1401 Nov 8 05:29 bg-nav.png
-rw-r--r--. 1 hadoop hadoop 3103 Nov 8 05:29 bg-upper.png
-rw-r--r--. 1 hadoop hadoop 3376 Nov 8 05:30 build.xml
-rw-r--r--. 1 hadoop hadoop 21630 Nov 8 05:29 favicon.ico
-rw-r--r--. 1 hadoop hadoop 12186 Nov 8 05:30 index.jsp
-rw-r--r--. 1 hadoop hadoop 8965 Nov 8 05:30 RELEASE-NOTES.txt
-rw-r--r--. 1 hadoop hadoop 5576 Nov 8 05:30 tomcat.css
-rw-r--r--. 1 hadoop hadoop 2066 Nov 8 05:29 tomcat.gif
-rw-r--r--. 1 hadoop hadoop 5103 Nov 8 05:29 tomcat.png
-rw-r--r--. 1 hadoop hadoop 2376 Nov 8 05:29 tomcat-power.gif
-rw-r--r--. 1 hadoop hadoop 67198 Nov 8 05:30 tomcat.svg
drwxr-xr-x. 2 hadoop hadoop 4096 Feb 25 19:18 WEB-INF
-rw-rw-r--. 1 hadoop hadoop 55 Feb 25 19:44 zhoulshot.dic
[hadoop@HadoopMaster ROOT]$ vim zhoulshot.dic
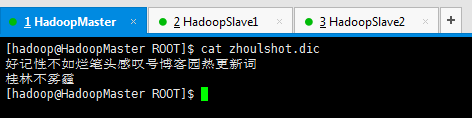
[hadoop@HadoopMaster ROOT]$ cat zhoulshot.dic
好记性不如烂笔头感叹号博客园热更新词
桂林不雾霾
[hadoop@HadoopMaster ROOT]$
文件保存之后, 重启es,查看 es 的日志会看到如下日志信息

[hadoop@HadoopMaster elasticsearch-2.4.3]$ jps
2353 Jps
1979 Bootstrap
[hadoop@HadoopMaster elasticsearch-2.4.3]$ bin/elasticsearch
[2017-02-26 18:15:11,538][WARN ][bootstrap ] unable to install syscall filter: seccomp unavailable: requires kernel 3.5+ with CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER compiled in
[2017-02-26 18:15:12,476][INFO ][node ] [Andromeda] version[2.4.3], pid[2363], build[d38a34e/2016-12-07T16:28:56Z]
[2017-02-26 18:15:12,476][INFO ][node ] [Andromeda] initializing ...
[2017-02-26 18:15:14,047][INFO ][plugins ] [Andromeda] modules [lang-groovy, reindex, lang-expression], plugins [analysis-ik, kopf, head], sites [kopf, head]
[2017-02-26 18:15:14,093][INFO ][env ] [Andromeda] using [1] data paths, mounts [[/home (/dev/sda5)]], net usable_space [23.4gb], net total_space [26.1gb], spins? [possibly], types [ext4]
[2017-02-26 18:15:14,094][INFO ][env ] [Andromeda] heap size [1015.6mb], compressed ordinary object pointers [true]
[2017-02-26 18:15:14,094][WARN ][env ] [Andromeda] max file descriptors [4096] for elasticsearch process likely too low, consider increasing to at least [65536]
[2017-02-26 18:15:17,940][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/config/analysis-ik/IKAnalyzer.cfg.xml
[2017-02-26 18:15:17,942][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/plugins/ik/config/IKAnalyzer.cfg.xml
[2017-02-26 18:15:18,804][INFO ][ik-analyzer ] [Dict Loading] custom/mydict.dic
[2017-02-26 18:15:18,805][INFO ][ik-analyzer ] [Dict Loading] custom/single_word_low_freq.dic
[2017-02-26 18:15:18,809][INFO ][ik-analyzer ] [Dict Loading] custom/zhouls.dic
[2017-02-26 18:15:18,809][INFO ][ik-analyzer ] [Dict Loading] http://192.168.80.10:8081/zhoulshot.dic
[2017-02-26 18:15:19,962][INFO ][ik-analyzer ] 好记性不如烂笔头感叹号博客园热更新词
[2017-02-26 18:15:19,964][INFO ][ik-analyzer ] 桂林不雾霾
[2017-02-26 18:15:19,979][INFO ][ik-analyzer ] [Dict Loading] custom/ext_stopword.dic
[2017-02-26 18:15:21,455][INFO ][node ] [Andromeda] initialized
[2017-02-26 18:15:21,455][INFO ][node ] [Andromeda] starting ...
[2017-02-26 18:15:21,557][INFO ][transport ] [Andromeda] publish_address {192.168.80.10:9300}, bound_addresses {[::]:9300}
[2017-02-26 18:15:21,565][INFO ][discovery ] [Andromeda] elasticsearch/U318aiv6RTi3dKHaCIRHWw
[2017-02-26 18:15:24,761][INFO ][cluster.service ] [Andromeda] new_master {Andromeda}{U318aiv6RTi3dKHaCIRHWw}{192.168.80.10}{192.168.80.10:9300}, reason: zen-disco-join(elected_as_master, [0] joins received)
[2017-02-26 18:15:24,914][INFO ][http ] [Andromeda] publish_address {192.168.80.10:9200}, bound_addresses {[::]:9200}
[2017-02-26 18:15:24,920][INFO ][node ] [Andromeda] started
[2017-02-26 18:15:25,640][INFO ][gateway ] [Andromeda] recovered [1] indices into cluster_state
[2017-02-26 18:15:30,044][INFO ][ik-analyzer ] 重新加载词典...
[2017-02-26 18:15:30,048][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/config/analysis-ik/IKAnalyzer.cfg.xml
[2017-02-26 18:15:30,051][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/plugins/ik/config/IKAnalyzer.cfg.xml
[2017-02-26 18:15:31,617][INFO ][ik-analyzer ] [Dict Loading] custom/mydict.dic
[2017-02-26 18:15:31,618][INFO ][ik-analyzer ] [Dict Loading] custom/single_word_low_freq.dic
[2017-02-26 18:15:31,625][INFO ][ik-analyzer ] [Dict Loading] custom/zhouls.dic
[2017-02-26 18:15:31,627][INFO ][ik-analyzer ] [Dict Loading] http://192.168.80.10:8081/zhoulshot.dic
[2017-02-26 18:15:31,664][INFO ][ik-analyzer ] 好记性不如烂笔头感叹号博客园热更新词
[2017-02-26 18:15:31,665][INFO ][ik-analyzer ] 桂林不雾霾
[2017-02-26 18:15:31,666][INFO ][ik-analyzer ] [Dict Loading] custom/ext_stopword.dic
[2017-02-26 18:15:31,668][INFO ][ik-analyzer ] 重新加载词典完毕...
直接,ctrl + c,终止es进程,再bin/elasticsearch -d
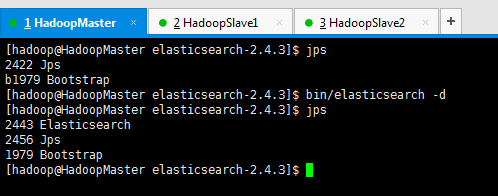
再执行下面命令查看分词效果

[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl 'http://192.168.80.10:9200/zhouls/_analyze?analyzer=ik_max_word&pretty=true' -d '{"text":"桂林不雾霾"}'
{
"tokens" : [ {
"token" : "桂林不雾霾",
"start_offset" : 0,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 0
}, {
"token" : "桂林",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
}, {
"token" : "桂",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_WORD",
"position" : 2
}, {
"token" : "林",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 3
}, {
"token" : "不",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 4
}, {
"token" : "雾",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
}, {
"token" : "霾",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 6
} ]
}
[hadoop@HadoopMaster elasticsearch-2.4.3]$
到这为止, 可以实现动态添加自定义词库实现词库热更新!
==============================================================================
注意: 默认情况下, 最多一分钟之内就可以识别到新增的词语。
完毕!
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()





打开百度App,扫码,精彩文章每天更新!欢迎关注我的百家号: 九月哥快讯
Elasticsearch之中文分词器插件es-ik的自定义热更新词库的更多相关文章
- 32.修改IK分词器源码来基于mysql热更新词库
主要知识点, 修改IK分词器源码来基于mysql热更新词库 一.IK增加新词的原因 在第32小节中学习到了直接在es的词库中增加词语,来扩充自已的词库,但是这样做有以下缺点: (1)每次添加完 ...
- 实操重写IK分词器源码,基于mysql热更新词库
实操重写IK分词器源码,基于mysql热更新词库参考网址:https://blog.csdn.net/wuzhiwei549/article/details/80451302 问题一:按照这篇文章的介 ...
- 【自定义IK词典】Elasticsearch之中文分词器插件es-ik的自定义词库
Elasticsearch之中文分词器插件es-ik 针对一些特殊的词语在分词的时候也需要能够识别 有人会问,那么,例如: 如果我想根据自己的本家姓氏来查询,如zhouls,姓氏“周”. 如 ...
- Elasticsearch之中文分词器插件es-ik(博主推荐)
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch之分词器的工作流程 Elasticsearch之停用词 Elasticsearch之中文分词器 Elasti ...
- elasticsearch安装中文分词器插件smartcn
原文:http://blog.java1234.com/blog/articles/373.html elasticsearch安装中文分词器插件smartcn elasticsearch默认分词器比 ...
- Elasticsearch之中文分词器插件es-ik的自定义词库
它在哪里呢? 非常重要! [hadoop@HadoopMaster custom]$ pwd/home/hadoop/app/elasticsearch-2.4.3/plugins/ik/config ...
- 沉淀再出发:ElasticSearch的中文分词器ik
沉淀再出发:ElasticSearch的中文分词器ik 一.前言 为什么要在elasticsearch中要使用ik这样的中文分词呢,那是因为es提供的分词是英文分词,对于中文的分词就做的非常不好了 ...
- ElasticSearch安装中文分词器IK
1.安装IK分词器,下载对应版本的插件,elasticsearch-analysis-ik中文分词器的开发者一直进行维护的,对应着elasticsearch的版本,所以选择好自己的版本即可.IKAna ...
- 如何给Elasticsearch安装中文分词器IK
安装Elasticsearch安装中文分词器IK的步骤: 1. 停止elasticsearch 2.2的服务 2. 在以下地址下载对应的elasticsearch-analysis-ik插件安装包(版 ...
随机推荐
- java.io.IOException: Cannot find any registered HttpDestinationFactory from the Bus.
转自:https://blog.csdn.net/u012849872/article/details/51037374
- Response.Redirect(),Server.Transfer(),Server.Execute()的区别与网站优化
转 http://blog.csdn.net/dannywj1371/article/details/10213631 1.Response.Redirect():Response.Redirect方 ...
- 压力测试工具 Tinyget
Tinyget 压力测试工具使用方法为:命令行切换到工具所在路径下,然后输入压力命令.如:tinyget -srv:localhost -uri:/FeaturedProdu1cts.aspx -th ...
- 【转】解析<button>和<input type="button"> 的区别
一.定义和用法 <button> 标签定义的是一个按钮. 在 button 元素内部,可以放置文本或图像.这是<button>与使用 input 元素创建的按钮的不同之处. 二 ...
- form&method【POST~GET】
<form.../>中method属性指定了该表单是以哪种方式提交请求,有两种方式:GET请求方式和POST请求方式,默认是GET请求方式.两种方式的区别:get方式的请求是在浏览器地址栏 ...
- js判断传入时间和当前时间大小
//判断时间是否过期 function judgeTime(time){ var strtime = time.replace("/-/g", "/");//时 ...
- vue 中判断向上滚动还是向下滚动
<script> export default { data(){ return{ i = 0 } }, mounted () { window.addEventListener('scr ...
- flex-2
1. 2. justify:整理版面 3. 4.归纳 justify-content:flex-start(默认).center.flex-end 下面还会提到剩下的两种项目在主轴上对齐方式: spa ...
- Java Mail解决标题乱码问题
在Java实现发送邮件功能时,直接使用 message.setSubject(subject) 的方式设置标题,在本地测试发送邮件的中文标题可以正常显示,但是将项目部署到服务器后,发送邮件的中文标题就 ...
- linux C++ 编译错误 file not found 其实是原文件后缀的问题
gcc和clang会根据源文件的后缀.c或者.cpp判断原文件类型,采取不同的编译策略,所以我使用它们编译后缀是.c的C++原文件的时候会出现找不到include的文件的错误,使用正确的后缀名即可.同 ...