30443数据查询语言DQL
5.4 SQL的数据查询功能
数据查询是数据库最常用的功能。在关系数据库中,查询操作是由SELECT语句来完成。其语法格式如下:
SELECT column_expression FROM table_name | view_name[,table_name | view_name, [,…]] [IN foreign_TABLE] [WHERE... ] [GROUP BY... ] [HAVING... ] [ORDER BY…] [With Owneraccess Option]
其中,column_expression为目标字段表达式,其语法格式为:
[ALL|DISTINCT|TOP] * | table_name.* | [table_name.]column1_name[[AS] alias_name1]
[, [table_name.] column2_name [ [AS] alias_name2] [, ...]]
SELECT语句的主要作用是,从FROM子句指定的数据表或者视图中找出满足WHERE子句设定的条件的元组,并按照SELECT子句指定的目标字段表达式重新组织这些元组,从而形成新的结果集。如果没有WHERE子句,则默认选出所有的元组。
以下主要按子句功能来介绍SELECT语句的使用方法,如果不特别说明,则均指基于表5.10所示的数据表student进行查询。

【例子】 为了能看到下文介绍的SELECT语句的执行效果,在用CREATE TABLE语句创建数据表student以后,请接着在SSMS中执行下列的INSERT语句,以在数据库中创建与表5.10所示内容完全一样的数据表:
INSERT student VALUES('20170201','刘洋','女','1997-02-03','计算机应用技术',98.5,'计算机系');
INSERT student VALUES('20170202','王晓珂','女','1997-09-20','计算机软件与理论',88.1,'计算机系');
INSERT student VALUES('20170203','王伟志','男','1996-12-12','智能科学与技术',89.8,'智能技术系');
INSERT student VALUES('20170204','岳志强','男','1998-06-01','智能科学与技术',75.8,'智能技术系');
INSERT student VALUES('20170205','贾簿','男','1994-09-03','计算机软件与理论',43.0,'计算机系');
INSERT student VALUES('20170206','李思思','女','1996-05-05','计算机应用技术',67.3,'计算机系');
INSERT student VALUES('20170207','蒙恬','男','1995-12-02','大数据技术',78.8,'大数据技术系');
INSERT student VALUES('20170208','张宇','女','1997-03-08','大数据技术',59.3,'大数据技术系');
5.4.1 基本查询
基本查询是指基于单表(一个数据表或视图)的仅仅由SELECT子句和FROM子句构成的SELECT语句。其一般格式如下:
SELECT [ALL|DISTINCT|TOP] * | table_name.* | [table_name.]column1_name[ [AS] alias_name1] [, [table_name.] column2_name [ [AS] alias_name2] [, ...]]
FROM table_name;
由于视图的查询与数据表的查询是一样的,以下仅考虑数据表的查询问题。对于视图的查询可以由此推广。
1. 选择所有字段
有时候希望查询结果包含所有的字段,这时只需将目标字段表达式设定为星号“*”即可,也可以列出所有的字段。
【例子】 下列的SELECT语句实现的就是最简单的基本查询,其结果将包含所有字段的全部数据元组:
SELECT * FROM student;
该语句等价于下列的SELECT语句:
SELECT s_no,s_name,s_sex,s_birthday,s_speciality,s_avgrade,s_dept
FROM student;
2. 选择指定的若干字段
在很多情况下,用户仅对表中的某些字段感兴趣,并且希望这些字段能够按照指定的顺序列出。
【例子】 查询全体学生的平均成绩和姓名(平均成绩在前,姓名在后)。
SELECT s_avgrade,s_name
FROM student;
执行后结果如下:
s_avgrade s_name
------------------------
98.5 刘洋
88.1 王晓珂
89.8 王伟志
75.8 岳志强
43.0 贾簿
67.3 李思思
78.8 蒙恬
59.3 张宇
每一字段都是用字段名来“标识”(字段名一般为英文),例如,第一字段标识为“s_avgrade”,第二字段标识为“s_name”。
这对中国用户来说并不方便,可以使用带关键子AS的目标字段表达式来解决,其中AS后面跟由用户指定的字段标题(关键字AS可以省略)。
【例子】 对于上述问题,可用下列的语句来完成:
SELECT s_avgrade AS 平均成绩, s_name AS 姓名 -- AS也可以省略
FROM student;
执行后结果如下:
平均 成绩姓名
------------------------
98.5 刘洋
88.1 王晓珂
89.8 王伟志
75.8 岳志强
43.0 贾簿
67.3 李思思
78.8 蒙恬
59.3 张宇
3. 构造计算字段
查询结果中的计算字段(列)是指根据数据表中的某一个或者若干个字段进行计算而得到的新字段,并把它放在查询结果集中,实际上在数据表中并不存在此字段。
【例子】 要求查询全体学生的姓名和年龄。由于数据表student中没有年龄这一字段,而仅有与之相关的出生日期(birthday)这一字段。必须经过出生日期来计算每个学生的年龄,相应的SQL语句如下:
SELECT s_name 姓名, Year(getdate())-Year(s_birthday) 年龄
FROM student;
用到两个系统函数:getdate()和Year(),它们分别用于获取datetime类型的系统时间和时间的年份。
上述语句执行的结果如下:
姓名 年龄
-----------------------
刘洋 20
王晓珂 20
王伟志 21
岳志强 19
贾簿 23
李思思 21
蒙恬 22
张宇 20
5.4.2 带DISTINCT的查询
使用SELECT查询时,SELECT后面可加上下字段关键字,以满足不同的查询要求:
ALL:ALL是默认关键字,即当不加任何关键字时,表示默认使用ALL作为关键字。它表示要返回所有满足条件的元组。前面介绍的查询正是这种查询。
TOP:有两种格式:TOP n和TOP n PERCENT。第一种格式表示返回前面n个元组,而第二种格式则表示返回前面n%个元组;如果n%不是整数,则向上取整。
DISTINCT:如果带此关键字,则在查询结果中若包含重复记录(行),则只返回这些重复元组中的一条。即关键字DISTINCT保证了查询结果集中不会包含重复元组,但与DISTINCTROW不一样的是它不会删除所有的重复元组。
【例5.6】 查询表student中涉及的不同的系别信息。
该查询要求可用下列的语句完成:
SELECT DISTINCT s_dept 所在的系
FROM student;
执行后结果如下:
所在的系
-----------------
大数据技术系
计算机系
智能技术系
如果在以上语句中不加上关键字DISTINCT,则返回下列结果:
所在的系
-----------------
计算机系
计算机系
智能技术系
智能技术系
计算机系
计算机系
大数据技术系
大数据技术系
从以上不难看出关键字DISTINCT的作用。如果DISTINCT后面跟有多个字段名,则DISTINCT必须放在第一字段名的前面(即紧跟SELECT之后),而不能放在其他字段名的前面。
【例子】 下列的语句是正确的。
SELECT DISTINCT s_dept, s_sex
FROM student;
而下面的语句则是错误的:
SELECT s_dept, DISTINCT s_sex
FROM student;
【例5.7】 查询表student中前3条记录,列出它们所有的字段信息。
该查询可用带关键字TOP来实现:
SELECT TOP 3 *
FROM student;
如果用下列语句,虽然8*38% = 3.04,但由于采取向上取整,其结果返回4条记录:
SELECT TOP 38 PERCENT *
FROM student;
5.4.3 带WHERE子句的条件查询
在实际应用中,更多时候是根据一定条件来进行查询的,即查询满足一定条件的部分记录(而不是表中的所有记录)。WHERE子句将发挥作用,其一般语法格式如下:
SELECT column_expression FROM table_name WHERE condition_expression
condition_expression是条件表达式,通常称为查询条件。查询条件就是一种逻辑表达式,只有那些使该表达式的逻辑值为真的记录才按照目标字段表达式column_expression指定的方式组成一个新记录而添加到结果集中。
查询条件是一种逻辑表达式,就可以用一些逻辑联结联结词来构建这种表达式。常用联结词包括NOT、OR、AND等,分别表示逻辑意义上的“非”、“或”和“与”。
【例5.8】 要求查询表student中平均成绩为良好(80~90,但不等于90)的学生的学号、姓名、性别和平均成绩。
对于这一查询要求,可用下列的SELECT语句:
SELECT s_no 学号,s_name 姓名,s_sex 性别, s_avgrade 平均成绩
FROM student
WHERE s_avgrade>=80 AND s_avgrade<90;
该语句执行后结果如下:
学号 姓名 性别 平均成绩
-------------------------------------------------------------
20170202 王晓珂 女 88.1
20170203 王伟志 男 89.8
WHERE子句虽然语法格式比较简单,但在查询中却是使用得最多。下面介绍的查询大多都会涉及到WHERE子句,读者应该深刻领会其使用方法。
5.4.4 带BETWEEN的范围查询
有时候需要查询哪些字段值在一定范围内的记录,这时可以使用带BETWEEN的查询语句。其语法格式为:
SELECT column_expression FROM table_name WHERE column_name [NOT] BETWEEN value1 AND value2;
value1和value2都是字段column_name的具体值,且value1≤value2。该语句的查询结果是返回所有字段column_name的值落在value1到value2(包括value1和value2)之间范围内的记录。
【例5.9】 要求查询所有出生在1996年08月01日到1997年10月01日之间(包括这两个日期)的学生,并将他们的姓名、性别、系别、平均成绩以及出生年月列出来。
对于这个查询要求,可以用下列的语句完成:
SELECT s_name 姓名, s_sex 性别, s_dept 系别, s_avgrade 平均成绩,s_birthday 出生年月 FROM student WHERE s_birthday BETWEEN '1996-08-01' AND '1997-10-01’;
执行后结果如下:
姓名 性别 系别 平均成绩 出生年月
---------------------------------------------------------------------------------------------------
刘洋 女 计算机系 98.5 1997-02-03
王晓珂 女 计算机系 88.1 1997-09-20
王伟志 男 智能技术系 89.8 1996-12-12
张宇 女 大数据技术系 59.3 1997-03-08
如果要查询字段column_name的值不落在value1到value2(包括不等于value1和value2)之间的所有记录,则只需在相应的BETWEEN前加上谓词NOT即可。
例如,上例中查询不是出生在1996年08月01日到1997年10月01日之间的学生,可用下列的语句:
SELECT s_name 姓名, s_sex 性别, s_dept 系别, s_avgrade 平均成绩,s_birthday 出生年月 FROM student WHERE s_birthday NOT BETWEEN '1996-08-01' AND '1997-10-01’;
执行结果如下:
姓名 性别 系别 平均成绩 出生年月
------------------------------------------------------------------------------------------------
岳志强 男 智能技术系 75.8 1998-06-01
贾簿 男 计算机系 43.0 1994-09-03
李思思 女 计算机系 67.3 1996-05-05
蒙恬 男 大数据技术系 78.8 1995-12-02
BETWEEN只适合于字段值为数值型的情况。
5.4.5 带IN的范围查询
IN与BETWEEN具有类似的功能,都是查询满足字段值在一定范围内的记录。但与BETWEEN不同的是,IN后面必须跟枚举的字段值表(字段值的枚举),即把所有的字段值都列出来,而不能写为“value1 AND value2”的形式。这相当于在一个集合中进行查询,适合于那些不是数值型的情况。其语法格式为:
SELECT column_expression FROM table_name WHERE column_name [NOT] IN (value1, value2, …, valuen)
【例5.10】 要求查询智能技术系和大数据技术系的学生。
对于这个查询要求,可以用下列的语句来实现:
SELECT s_no 学号, s_name 姓名, s_sex 性别, s_birthday 出生年月, s_speciality 专业,
s_avgrade 平均成绩, s_dept 系别
FROM student
WHERE s_dept IN ('智能技术系','大数据技术系')
相应的输出如下:
学号 姓名 性别 出生年月 专业 平均成绩 系别
----------------------------------------------------------------------------------------------------------------------------------------------
20170203 王伟志 男 1996-12-12 智能科学与技术 89.8 智能技术系
20170204 岳志强 男 1998-06-01 智能科学与技术 75.8 智能技术系
20170207 蒙恬 男 1995-12-02 大数据技术 78.8 大数据技术系
20170208 张宇 女 1997-03-08 大数据技术 59.3 大数据技术系
实际上,“column_name IN (value1, value2, …, valuen)” 等价“column_name=value1 OR column_name=value2 OR…OR column_name=valuen”。
上例的查询语句也等价于:
SELECT s_no 学号, s_name 姓名, s_sex 性别, s_birthday 出生年月, s_speciality 专业, s_avgrade 平均成绩, s_dept 系别 FROM student WHERE s_dept='智能技术系' OR s_dept='大数据技术系';
这种IN的语句比带OR的语句在结构上比较简洁和直观。
另外,与BETWEEN类似,对于字段值不在(value1, value2, …, valuen)中的查询,可通过在IN之前加上NOT来实现。
5.4.6 带GROUP的分组查询
带GROUP的查询就是通常所说的分组查询,它将查询结果按照某一字段或某一些字段的字段值进行分组。我们就可以对每一组进行相应的操作,而一般的查询(如上面介绍的查询)都只能针对每一条记录进行操作。
用于统计每一组的记录个数。以下是分组查询的语法格式:
SELECT column_expression[, count(*)] FROM table_name GROUP BY column_expression [HAVING condition_expression]
HAVING是可选的,它用于对形成的分组进行筛选,留下满足条件condition_expression的组。
【例5.11】 要求查询表student中各系学生的数量。
(1)对于此查询,要按系(s_dept)来实现分组,相应的语句如下:
SELECT s_dept 系别, count(*) 人数 FROM student GROUP BY s_dept;
查询结果如下:
系别 人数
--------------------------------
大数据技术系 2
计算机系 4
智能技术系 2
(2)如果要查询人数大于或等于2的系的学生数量分布情况(每个系有多少人),则可以用HAVING短语来实现。
SELECT s_dept 系别, count(*) 人数 FROM student GROUP BY s_dept HAVING count(*) >= 2;
(3)如果进一步要求在平均成绩及格(s_avgrade >= 60)的学生中完成这种分组查询,即对于平均成绩及格的学生,如果要查询他们人数大于或等于2的系的学生数量分布情况,则可以先用WHERE子句来选择及格的学生,然后用HAVING短语来实现分组查询:
SELECT s_dept 系别, count(*) 人数 FROM student WHERE s_avgrade >= 60 GROUP BY s_dept HAVING count(*) >= 2
执行结果如下:
系别 人数
-------------------------
计算机系 3
智能技术系 2
注意:WHERE子句应该在GROUP和HAVING之前出现。
注意:WHERE子句和HAVING短语的作用都一样,都是用于指定查询条件。它们是有区别的:
HAVING短语是用于对组设定条件,而不是具体的某一条记录,从而使得SELECT语句可以实现对组进行筛选;
WHERE子句是对每一条记录设定条件的,而不是一个记录组。
5.4.7 LIKE匹配IS空值查询
1. 带LIKE的匹配查询
模糊查询在大多情况下都是由谓词LIKE来实现。其一般语法格式为:
SELECT column_expression FROM table_name WHERE column_name [NOT] LIKE character_string;
column_name的类型必须是字符串类型,character_string表示字符串常数。
该语句的含义是查找字段column_name的字段值与给定字符串character_string相匹配的记录。
字符串character_string可以是一个字符串常量,也可以是包含通配符“_”和“%”的字符串。是否相匹配要根据下列原则来确定:
“_”(下划线): 它可以与任意的单字符相匹配。
“%”(百分号) :它可以与任意长度字符串(包括空值)相匹配。
除了字符“_”和“%”外,所有其它的字符都只能匹配自己。
【例5.12】 查询所有姓“王”的学生,并列出他们的学号、姓名、性别、平均成绩和系别。
SELECT s_no 学号,s_name 姓名,s_sex 性别,s_avgrade 平均成绩,s_dept 系别 FROM student WHERE s_name LIKE '王%';
该语句的查询结果如下:
学号 姓名 性别 平均成绩 系别
---------------------------------------------------------------------------------
20170202 王晓珂 女 88.1 计算机系
20170203 王伟志 男 89.8 智能技术系
这是因为字符串'王%'可以与任何第一个字为“王”的名字相互匹配。如果谓词LIKE后跟'王_',则只能找出任何王姓且姓名仅由两个字组成的学生;如果谓词LIKE后跟'%志%',则表示要找出姓名中含有“志”的学生。
注意,由于字段s_name的数据类型是固定长度的8个字符(char(8)),因此如果s_name值的实际长度不够8个字符的,则后面以空格填补。
2. 空值null的查询 IS
空值null的查询是指查找指定字段的字段值为null的记录。对于这种查询,首先想到的方法可能就是用带等号“=”的WHERE子句来实现。但这种查找方法是失败的。
例如,下列的SELECT语句将找不到任何的记录,即使存在s_avgrade的字段值为null的记录:
SELECT * FROM student WHERE s_avgrade = null -- 错误
而正确的写法应该是:
SELECT * FROM student WHERE s_avgrade IS null -- 正确
【例5.13】 查找所有字段s_avgrade的值为非空的记录。
SELECT * FROM student WHERE s_avgrade IS NOT null
5.4.8 使用ORDER排序查询结果
有时候我们希望将查询结果按照一定的顺序进行排列,以方便、快速地从结果集中获取我们需要的信息。
例如,按照学生的成绩从高到低进行排序,这样我们一眼就可以看出谁的分数最高、谁的最低。而带ORDER BY子句的SELECT语句就可以实现对查询结果进行排序。其一般语法格式如下:
SELECT column_expression FROM table_name ORDER BY column_name [ASC|DESC][,…]
column_name表示排序的依据字段,ASC表示按依据字段进行升序排列,DESC表示按依据字段进行降序排列。如果ASC和DESC都没有选择,则按依据字段进行升序排列,即ASC为默认值。
【例5.14】 对表student中的男同学按成绩进行降序排序。
SELECT * FROM student WHERE s_sex = '男' ORDER BY s_avgrade DESC
执行后结果如下:
学号 姓名 性别 出生日期 专业 平均成绩 系别
---------------------------------------------------------------------------------------------------------------------------------------
20170203 王伟志 男 1996-12-12 智能科学与技术 89.8 智能技术系
20170207 蒙恬 男 1995-12-02 大数据技术 78.8 大数据技术系
20170204 岳志强 男 1998-06-01 智能科学与技术 75.8 智能技术系
20170205 贾簿 男 1994-09-03 计算机软件与理论 43.0 计算机系
【例子】 如果希望在成绩相同的情况下,进一步按照学号进行升序排列,则可以通过在ORDER BY后面增加字段s_no的方法来实现。相应的语句如下:
SELECT * FROM student WHERE s_sex = '男' ORDER BY s_avgrade DESC, s_no ASC
在上面的语句中,排序的原理是这样的:首先按照平均成绩对记录进行降序排序(因为选择了DESC);如果查询结果包含有平均成绩相同的记录,那么这时按平均成绩就无法对这些具有相同平均成绩的记录进行排序,这时SELECT语句将自动按照下一字段——学号(s_no)对这些记录进行升序排序(升序是默认排序方式);如果s_no后面还有其他字段,那么排序原理也依次类推。
5.4.9 连接查询
同时涉及到两个或者两个以上数据表的查询称为连接查询。连接查询可以找出多个表之间蕴涵的有用信息,实际上它是关系数据库中最主要的查询。连接查询主要包括等值连接查询、自然连接查询、外连接查询以及交叉连接查询等。但交叉连接查询没有实际意义,且运用的很少,在此不作介绍。
连接查询涉及到两种表。除了表5.10所示的数据表student以外,我们还需创建另一张数据表——选课表SC。该表的结构和内容分别如表5.11和表5.12所示。
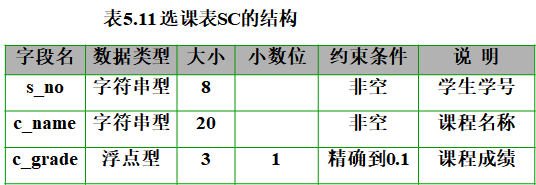

先用下列语句创建选课表SC:
CREATE TABLE SC( s_no char(8), c_name varchar(20), c_gradenumeric(3,1) CHECK(c_grade >= 0 AND c_grade <= 100), PRIMARY KEY(s_no, c_name) --将(s_no, c_name)设为主键 );
然后用下列INSERT插入如表5.12所示的数据,以便观察连接查询的效果:
INSERT SC VALUES('','英语',80.2);
INSERT SC VALUES('','数据库原理',70.0);
INSERT SC VALUES('','算法设计与分析',92.4);
INSERT SC VALUES('','英语',81.9);
INSERT SC VALUES('','算法设计与分析',85.2);
INSERT SC VALUES('','多媒体技术',68.1);
不特别说明,在本节中介绍的连接查询主要是基于表student和表SC进行的。
1. 等值连接和自然连接查询
在使用连接查询时,按照一定的条件在两个或多个表中提取数据并组成新的记录,所有这些记录的集合便构成了一个新的关系表。那么这个条件就称为连接条件,表示为join_condition。连接条件具有下列的形式:
[table1_name.]columni_name comp_oper [table2_name.]columnj_name
其中,comp_oper表示比较操作符,主要包括=、>(大于)、<(小于)、>=(大于等于)、<=(小于等于)、!=(不等)。连接条件有意义的前提是字段column1_name和column2_name是可比较的。
当连接条件的比较操作符comp_oper为等号“=”时,相应的连接就称为等值连接。对于表table1_name和表table2_name之间的等值连接,其一般格式可以表示如下:
SELECT [table1_name.]column1_name[, …], [table2_name.]column1_name[, …] FROM table1_name, table2_name WHERE [table1_name.]columni_name = [table2_name.]columnj_name
注意,对于字段名前面的表名是否需要显式标出,这取决于两个表中是否都有与此同名的字段。如果有,则必须冠以表名,否则可以不写表名。
连接条件中相互比较的两个字段必须是可比的,否则比较将无意义。但可比性并不意味着两个字段的数据类型必须一样,而只要求它们在语义上可比即可。
【例子】 对于整型的字段和浮点型的字段,虽然数据类型不同,但它们却是可比的;而将整型的字段和字符串型的字段进行比较,那是无意义的。
对于连接操作,可以这样来理解:首先取表table1_name中的第一条记录,然后从表table2_name中的第一条记录开始依次扫描所有的记录,并检查表table1_name中的第一条记录与表table2_name中的当前记录是否满足查询条件,如果满足则将这两条记录并接起来,形成结果集中的一条记录。当对表table2_name扫描完了以后,又从表table1_name中的第二条记录开始,重复上面相同的操作,直到表table1_name中所有的记录都处理完毕为止。
【例5.15】 要求查询选课学生的学号、姓名、性别、专业、系别以及所选的课程名称和成绩。
这个查询要求就涉及到两个表的查询,因为学生的基本信息包含在表student中,而选课信息则包含在表SC中。一个学生是否选课可以这样获知:如果表SC中有他的学号,则表明该学生已经选课,否则没有选课。上述查询问题就可以表述为,扫描表student和表SC中的每一条记录,如果这两个表中的当前记录在各自的字段s_no上取值相等,则将这两条记录按照指定的要求并接成一个新的记录并添加到结果集中。这种查询是以表student中的字段s_no和表SC中的字段s_no是否相等为查询条件的,所以这种查询就是等值查询。该等值查询的实现语句如下:
SELECT student.s_no 学号, s_name 姓名, s_sex 性别, s_speciality 专业, s_dept 系别,
c_name 课程名称, c_grade 课程成绩
FROM student, SC
WHERE student.s_no = SC.s_no
执行后的结果如下:
学号 姓名 性别 专业 系别 课程名称 课程成绩
---------------------------------------------------------------------------------------------------------------------------------------
20170201 刘洋 女 计算机应用技术计算机系 数据库原理 70.0
20170201 刘洋 女 计算机应用技术计算机系 算法设计与分析 92.4
20170201 刘洋 女 计算机应用技术计算机系 英语 80.2
20170202 王晓珂 女 计算机软件与理论计算机系 算法设计与分析 85.2
20170202 王晓珂 女 计算机软件与理论计算机系 英语 81.9
20170203 王伟志 男 智能科学与技术智能技术系 多媒体技术 68.1
表student和表SC中都有字段s_no,必须在其前面冠以表名,以明确s_no是属于哪一个表中的字段。如果在涉及的两个表中还有其他同名的字段,也需进行同样的处理。
如果觉得表名过长,使用起来比较麻烦,则可以利用AS来定义别名,通过使用别名来进行表的连接查询。
【例子】 上述的等值连接查询语句跟下面的查询语句是等价的:
SELECT a.s_no 学号, s_name 姓名, s_sex 性别, s_speciality 专业, s_dept 系别,
c_name 课程名称, c_grade 课程成绩
FROM student as a, SC as b
WHERE a.s_no = b.s_no
上述SELECT语句中,利用AS将表名student和SC分别定义为a和b,然后通过a和b来进行连接查询,从而简化代码。
如果在上述的等值连接查询语句中去掉WHERE子句,则得到下列的SELECT语句:
SELECT student.s_no 学号, s_name 姓名, s_sex 性别, s_speciality 专业, s_dept 系别,
c_name 课程名称, c_grade 课程成绩
FROM student, SC
该语句将形成表student和表SC的笛卡儿积。笛卡儿积是将两个表中的每一条记录分别并接而得到的结果集。笛卡儿积中记录的条数是两个表中记录条数的乘积,
自然连接实际上是一种特殊的等值连接,这种连接在等值连接的基础上增加以下两个条件而形成的:
(1)参加比较的两个字段必须是相同的,即同名同类型;
(2)结果集的字段是参加连接的两个表的字段的并集,但去掉了重复的字段。
【例5.16】 实现表student和表SC的自然连接查询。
可用下列的SELECT语句来实现:
SELECT student.s_no 学号, s_name 姓名, s_sex 性别, s_birthday 出生日期, s_speciality 专业, s_avgrade 平均成绩,s_dept 系别, c_name 课程名称, c_grade 课程成绩 FROM student, SC WHERE student.s_no = SC.s_no
上述语句执行得到的自然连接结果如表5.13所示。
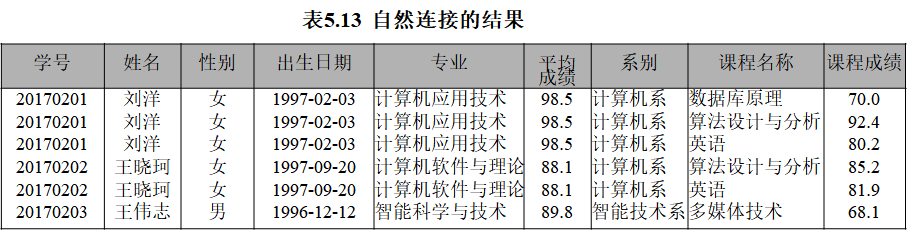
该结果集中的字段包含了表student和表SC中所有的字段,并去掉了重复字段SC.s_no而保留student.s_no(当然,也可以去掉student.s_no而保留SC.s_no),而且无其他重复字段,所以该等值查询是自然连接查询。
2. 自连接查询
以上介绍的都是基于两个不同的表进行连接查询。但有时候需要将一个表跟它自身进行连接查询,以完成相应的查询任务,这种查询就称为自连接查询。
在使用自连接查询时,虽然实际操作的是同一张表,但在逻辑上要使之分为两张表。这种逻辑上的分开可以在SQL Server中通过定义表别名的方法来实现,即为一张表定义不同的别名,这样就形成了有相同内容、但表名不同的两张表。
【例5.17】 要求查询表student中与“刘洋”在同一个专业的所有学生的学号、姓名、性别、专业和平均成绩(包括“李好”)。
这种查询的难处在于,我们不知道“刘洋”的专业是什么,如果知道了她的专业,那么该查询就很容易实现。必须从姓名为“刘洋”的学生记录中获得她的专业,然后由专业获取相关学生的信息。这种查询难以用单表查询来实现。如果使用自连接查询,那么问题就很容易得到解决。
自连接查询的方法如下:为表student创建一个别名b,这样student和b便形成逻辑上的两张表。然后通过表student和表b的连接查询实现本例的查询任务。但这种自连接查询要用到JOIN…ON…子句。查询语句如下:
SELECT b.s_no 学号, b.s_name 姓名, b.s_sex 性别,b.s_speciality 专业, b.s_avgrade 平均成绩 FROM student AS a-- 为student创建别名a JOIN student AS b -- 为student创建别名b ON (a.s_name='刘洋' AND a.s_speciality = b.s_speciality);
该语句运行结果如下:
学号 姓名 性别 专业 平均成绩
--------------------------------------------------------------------------
20170201刘洋 女 计算机应用技术 98.5
20170206李思思 女 计算机应用技术 67.3
定义student的一个别名也可以实现此功能:
SELECT b.s_no 学号, b.s_name 姓名, b.s_sex 性别,b.s_speciality 专业, b.s_avgrade 平均成绩 FROM student JOIN student AS b -- 为student创建别名b ON (student.s_name='刘洋' AND student.s_speciality = b.s_speciality);
3. 外连接查询
上述介绍的连接查询中,只有那些满足查询条件的记录才被列出来,而不满足条件的记录则“不知去向”,这在有的应用中并不合适。
例如,在对表student和表SC进行等值连接查询后,学号为“20120204”等学生由于没有选课,所以在查询结果中就没有关于这些学生的信息。但是很多时候我们希望能够将所有学生信息全部列出,对于没有选课的学生,其对应课程字段和课程成绩字段留空即可。上述连接查询方法就不适用了,需要引进另一种连接查询——外连接查询。
外连接查询的语法格式为:
SELECT [table1_name.]column1_name[, …], [table2_name.]column1_name[, …] FROM table1_name LEFT|RIGHT [OUTER] JOIN table2_name ON join_condition
如果在FROM子句中选择关键字LEFT,则该查询称为左外连接查询;如果选择关键字RIGHT,则该查询称为右外连接查询。
在左外连接查询中,对于表table1_name(左边的表)中的记录不管是否满足连接条件join_condition,它们都将将被列出;而对表table2_name(右边的表)中的记录,只有满足连接条件join_condition的部分才被列出。
在右外连接查询中,对于表table2_name中的记录不管是否满足连接条件join_condition,它们都将将被列出;而对表table1_name中的记录,只有满足连接条件join_condition的部分才被列出。
【例5.18】 查询所有学生的基本信息,如果他们选课了则同时列出相应的课程信息(含姓名、性别、专业、系别以及课程名称和课程成绩)。
这种查询的基本要求是,首先无条件地列出所有学生相关信息;其次对于已经选课的学生,则列出其相应的选课信息,而对于没有选课的学生,其相应的字段留空。即表student中的记录要无条件列出,而表SC中的记录只有满足连接条件(已选课)的部分才能列出。这需要用外连接查询来实现,其实现语句如下:
SELECT s_name 姓名, s_sex 性别, s_speciality 专业, s_dept 系别,
SC.c_name 课程名称, SC.c_grade 课程成绩
FROM student
LEFT JOIN SC ON (student.s_no = SC.s_no);
以上采用的是左外连接查询。也可以将表student和表SC的位置调换一下,改用右外连接查询,其实现语句如下:
SELECT s_name 姓名, s_sex 性别, s_speciality 专业, s_dept 系别,
SC.c_name 课程名称, SC.c_grade 课程成绩
FROM SC
RIGHT JOIN student ON (student.s_no = SC.s_no);
以上两种外连接查询语句的作用都是一样的,执行后都得到如下结果:
姓名 性别 专业 系别 课程名称 课程成绩
----------------------------------------------------------------------------------------------------------------------------
刘洋 女计算机应用技术计算机系 数据库原理70.0
刘洋 女计算机应用技术计算机系 算法设计与分析92.4
刘洋 女计算机应用技术计算机系 英语80.2
王晓珂 女计算机软件与理论计算机系 算法设计与分析85.2
王晓珂 女计算机软件与理论计算机系 英语81.9
王伟志 男智能科学与技术智能技术系 多媒体技术68.1
岳志强 男智能科学与技术智能技术系 NULLNULL
贾簿 男计算机软件与理论计算机系 NULLNULL
李思思 女计算机应用技术计算机系 NULLNULL
蒙恬 男大数据技术大数据技术系 NULLNULL
张宇 女大数据技术大数据技术系 NULLNULL
从以上结果可以看出,“岳志强”等虽然没有选课,但他们的基本信息还是被列出了,其相应显示选课信息的位置则留空(NULL)。
5.4.10 嵌套查询
一个查询A可以嵌入到另一个查询B的WHERE子句中或者HAVING短语中,由这种嵌入方法而得到的查询就称为嵌入查询。查询A称为查询B的子查询(或内层查询),查询B称为查询A的父查询(或外层查询、主查询等)。
观察下面的例子:
SELECT s_no,s_name -- FROM student ----父查询 WHERE s_no IN( -- SELECT s_no -- FROM SC ----子查询 WHERE c_name = '算法设计与分析') --
该查询就是一个嵌套查询,它找出了选“算法设计与分析”这门课的学生的学号和姓名。其中,括号内的查询为子查询,括号外的查询为父查询。子查询还可以嵌套其他的子查询,即SQL语言允许多层嵌套查询。
执行嵌套查询的过程:首先执行最内层的子查询,然后用子查询的结果构成父查询的WHERE子句,并执行该查询;父查询产生的结果又返回给其父查询的WHERE子句,其父查询又执行相同的操作,直到最外层查询执行完为止。也就是说,嵌套查询的执行过程是由里向外。
嵌套查询的优点是,每一层的查询都是一条简单的SELECT语句,其结构清晰,易于理解。但不能对子查询的结果进行排序,即子查询不能带ORDER BY子句。
以下将根据所使用谓词的不同来介绍各种嵌套查询,并且假设讨论的嵌套查询是由子查询和父查询构成。对于多层的嵌套查询,不难由此推广。
1. 使用谓词IN的嵌套查询
带IN的嵌套查询是指父查询和子查询是通过谓词IN来连接的一种嵌套查询,也是用得最多的嵌套查询之一。其特点是,子查询的返回结果被当作是一个集合,父查询则判断某一字段值是否在该集合中,以确定是否要输出该字段值对应的记录的有关信息。
【例5.19】 查询“王伟志”和“蒙恬”所在专业的所有学生信息。
这个查询的解决过程是,首先找出他们所在的专业,然后根据专业来查找学生。为此可以分为两步走。
首先确定“王伟志”和“蒙恬”所在的专业:
SELECT student.s_speciality FROM student WHERE student.s_name = '王伟志' OR student.s_name = '蒙恬‘
上述语句的返回结果是('智能科学与技术', '大数据技术')。下一步要做的就是查找所有专业为智能科学与技术或大数据技术的学生。相应的SELECT语句如下:
SELECT *
FROM student
WHERE student.s_speciality IN ('智能科学与技术', '大数据技术');
将中间结果(‘智能科学与技术’, ‘大数据技术’)去掉,代之以产生该结果的SELECT语句,于是得到了下列的嵌套查询:
SELECT * FROM student WHERE student.s_speciality IN ( SELECT student.s_speciality FROM student WHERE student.s_name = '王伟志' OR student.s_name = '蒙恬');
执行该嵌套查询后得到如下的结果,该结果与我们预想的完全一致:
s_nos_names_sexs_birthday s_speciality s_avgrade s_dept
------------------------------------------------------------------------------------------------------------------------------
20170203王伟志 男1996-12-12 智能科学与技术89.8智能技术系
20170204岳志强 男1998-06-01 智能科学与技术75.8智能技术系
20170207蒙恬 男1995-12-02 大数据技术 78.8大数据技术系
20170208张宇 女1997-03-08 大数据技术 59.3大数据技术系
对于这个例子,如果运用连接查询,会显得比较复杂。但使用带IN的嵌套查询,不管在问题的解决思路上还是在SELECT语句的构造上都显得更具条理性和直观性,而且仅涉及到一个逻辑表(不用创建别名)。
2. 使用比较运算符的嵌套查询
比较运算符是指>、<、=、>=、<=、<>等符号。这些符号可以将一个字段与一个子查询连接起来构成一个逻辑表达式。以这个逻辑表达式为查询条件的查询就构成了父查询。
一般来说,这种比较只能是基于单值进行的,所以要求子查询返回的结果必须为单字段值。
可以返回('智能科学与技术'),但返回('智能科学与技术', '大数据技术')则是不允许的。在例5.19中,如果将其嵌套查询中的谓词IN改为任意一个比较运算符,都会产生错误。原因是,该嵌套查询中的子查询返回的不是单字段值,而是两个字段值。
【例5.20】 查询所有平均成绩比“蒙恬”低的学生,并列出这些学生的学号、姓名、专业和平均成绩。
这个查询的关键是首先要找出“蒙恬”的平均成绩,然后才能据此找出其他有关学生的信息。由于“蒙恬”的平均成绩是唯一的,所以我们可以构造如下的子查询:
SELECT s_avgrade FROM student WHERE s_name = '蒙恬';
该查询返回的结果是78.8。然后由此构造父查询:
SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE s_avgrade < 78.8
把中间结果78.8去掉以后,将以上两个查询合起来,得到下列的嵌套查询:
SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE s_avgrade < ( SELECT s_avgrade FROM student WHERE s_name = '蒙恬')
上述嵌套查询后结果如下:
学号 姓名专业 平均成绩
----------------------------------------------------------------------------------------
20170204岳志强 智能科学与技术75.8
20170205贾簿 计算机软件与理论 43.0
20170206李思思 计算机应用技术67.3
20170208张宇 大数据技术 59.3
在SQL Server 2014中,子查询在比较运算符之后或者之前都无关紧要,只要查询条件返回的真值一样,则查询结果都相同。例如,下列的嵌套查询与上面的嵌套查询是等价的,查询结果都一样:
SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE ( SELECT s_avgrade FROM student WHERE s_name = '蒙恬') > s_avgrade;
3.使用谓词EXISTS的嵌套查询
在使用谓词EXISTS的嵌套查询中,只要子查询返回非空的结果,则父查询的WHERE子句将返回逻辑真,否则返回逻辑假。至于返回的结果是什么类型的数据,对这种嵌套查询是无关紧要,所以在父查询的目标字段表达式都用符号*,即使给出字段名也无实际意义。
带EXISTS的嵌套查询与前面介绍的嵌套查询的最大区别在于,它们执行的方式不一样。带EXISTS的嵌套查询是先执行外层,后执行内层,再回到外层。具体讲,对于每一条记录,父查询先从表中“抽取”出来,然后“放到”子查询中并执行一次子查询;如果该子查询返回非空值(导致WHERE子句返回逻辑真),则父查询将该记录添加到结果集中,直到所有的记录都被进行这样的处理为止。显然,父查询作用的表中有多少条记录,则子查询被执行多少次。在这种查询中,子查询依赖于父查询,所以这类查询又称为相关子查询。
前面介绍的嵌套查询中,先执行子查询,后执行父查询。子查询与父查询无关,所以这类查询称为不相关子查询。
【例5.21】 查询所有选修了《算法设计与分析》的学生学号、姓名和专业。
学生选修课程的信息放在表SC中,而学生的学号、姓名和专业信息则放在表student中,所以该查询要涉及到两个表。显然,该查询可以用很多种方法来实现,下面我们考虑运用带EXISTS的嵌套查询来完成。相应的SELECT语句如下:
SELECT s_no 学号, s_name 姓名, s_speciality 专业 FROM student WHERE EXISTS( SELECT * FROM SC WHERE student.s_no = s_no AND c_name = '算法设计与分析');
在执行该嵌套查询时,父查询先取表student中的第1条记录,记为r1;然后执行一次子查询,这时发现表SC中存在s_no字段值与r1的s_no字段值相等的记录(记为r2),而且r2在c_name字段上的取值为“算法设计与分析”,所以子查询返回记录r2(非空);由于第1条记录(r1)使得子查询返回值为非空,所以父查询的WHERE子句返回逻辑真,这样父查询便将第1条记录添加到结果集中;重复上述过程,直到表student中所有的记录都被处理完为止。
本查询也可以用带谓词IN的嵌套查询来实现,其查询实现思想也比较直观。首先用子查询返回表SC中所有选修了《算法设计与分析》的学生学号的集合,然后用父查询找出表student中学号在该集合中的学生。相应的查询语句如下:
SELECT s_no 学号, s_name 姓名, s_speciality 专业 FROM student WHERE s_no IN ( SELECT s_no FROM SC WHERE c_name = '算法设计与分析');
5.4.11 查询的集合运算
SELECT语句返回的结果是若干个记录的集合。集合有其固有的一些运算,如并、交、差等。从集合运算的角度看,可以将每一个SELECT语句当作是一个集合。于是,可以对任意两个SELECT语句进行集合运算。在SQL语言,提供了并(UNION)、交(INTERSECT)和差(EXCEPT)等几个集合运算。
两个查询的并(UNION)是指将两个查询的返回结果集合并到一起,同时去掉重复的记录。并运算的前提是,两个查询返回的结果集在结构上要一致,即结果集的字段个数要相等以及字段的类型要分别相同。
【例5.22】 查询专业为大数据技术或者平均成绩在良好以上(>=80)的学生,并列出他们的学号、姓名、专业和平均成绩。
这个查询可以看作是以下两个查询并:
-- 查询专业为大数据技术的学生
SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE s_speciality = '大数据技术';
-- 查询平均成绩在良好以上的学生
SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE s_avgrade >= 80;
以上这两个查询语句执行后所得的结果分别如下:
学号姓名 专业 平均成绩
-------------------------------------------------------------------------------
20170207 蒙恬 大数据技术 78.8
20170208 张宇 大数据技术 59.3
学号姓名专业 平均成绩
-------------------------------------------------------------------------------
20170201 刘洋 计算机应用技术 98.5
20170202 王晓珂 计算机软件与理论 88.1
20170203 王伟志 智能科学与技术 89.8
将以上两个SELECT语句用关键字UNION连起来就实现了两个查询的并:
(SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE s_speciality = '大数据技术') UNION (SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE s_avgrade >= 80);
以上语句执行后得到如下结果:
学号 姓名 专业 平均成绩
--------------------------------------------------------------------
20170201 刘洋 计算机应用技术 98.5
20170202 王晓珂 计算机软件与理论 88.1
20170203 王伟志 智能科学与技术 89.8
20170207 蒙恬 大数据技术 78.8
20170208 张宇 大数据技术 59.3
这个结果正好是上述两个查询结果集的并。
【例5.23】 查询专业为智能科学与技术而且平均成绩在良好以上(>=80)的学生,并列出他们的学号、姓名、专业和平均成绩。
该查询可以看作是专业为智能科学与技术的学生集合和平均成绩在良好以上的学生集合的交集。
基于交运算的SQL语句如下:
(SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE s_speciality = '智能科学与技术') INTERSECT (SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE s_avgrade >= 80);
此SQL语句运行结果如下:
学号 姓名 专业 平均成绩
------------------------------------------------------------------------------
20170203 王伟志 智能科学与技术 89.8
【例5.24】 查询专业为智能科学与技术而且平均成绩在良好以下(<80)的学生,并列出他们的学号、姓名、专业和平均成绩。
该查询可以看作是专业为智能科学与技术的学生集合与平均成绩在良好以上的学生集合的差集。
基于差运算的SQL语句如下:
(SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE s_speciality = '智能科学与技术') EXCEPT (SELECT s_no 学号, s_name 姓名, s_speciality 专业, s_avgrade 平均成绩 FROM student WHERE s_avgrade >= 80);
此SQL语句运行结果如下:
学号姓名 专业 平均成绩
-------------------------------------------------------------------------
20170204岳志强 智能科学与技术75.8

30443数据查询语言DQL的更多相关文章
- 数据查询语言DQL 与 内置函数(聚合函数)
数据查询语言DQL 从表中获取符合条件的数据 select select*from表的名字 查询表所有的数据.(select跟from必须一块用 成对出现的) * 表示所有字段,可以换成想要查询的 ...
- 学习资料 数据查询语言DQL
数据查询语言DQL介绍及其应用: 查询是SQL语言的核心,SQL语言只提供唯一一个用于数据库查询的语句,即SELECT语句.用于表达SQL查询的SELECT语句是功能最强也是最复杂的SQL语句,它提供 ...
- MySQL数据库笔记三:数据查询语言(DQL)与事务控制语言(TCL)
五.数据查询语言(DQL) (重中之重) 完整语法格式: select 表达式1|字段,.... [from 表名 where 条件] [group by 列名] [having 条件] [order ...
- MySQL之数据查询语言(DQL)
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块: SELECT <字段> FROM <表名> WHERE <查询条件> - ...
- mysql数据查询语言DQL
DB(database)数据库:存储数据的'仓库',保存了一系列有组织的数据 DBMS(Database Management System)数据库管理系统:用于创建或管理DB SQL(Structu ...
- SQL 复习二(数据查询语言)
1.1 数据查询语言 DQL就是数据查询语言,数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端. 语法: SELECT selection_list /*要查询的列名称*/ FR ...
- Mysql基础3-数据操作语言DML-数据查询语言DQL
主要: 数据操作语言DML 数据查询语言DQL 数据操作语言DML DML: Data Mutipulation Language 插入数据(增) 一般插入数据形式 1)形式1: insert [in ...
- MySQL — 数据查询语言
目录 1.基础查询 2.条件查询 3.分组查询 4.排序查询 5.分页查询 6.多表查询 6.1.连接查询 6.1.1.内连接 6.1.2.外连接 6.1.3.自连接 6.1.4.联合查询 6.2.子 ...
- 微软亚洲研究院开源图数据查询语言LIKQ
近日,微软亚洲研究院通过GitHub 平台开源图数据查询语言LIKQ (Language-Integrated Knowledge Query).LIKQ是基于分布式大规模图数据处理引擎Graph ...
随机推荐
- C# 反射调用私有事件
原文:C# 反射调用私有事件 在 C# 反射调用私有事件经常会不知道如何写,本文告诉大家如何调用 假设有 A 类的代码定义了一个私有的事件 class A { private event EventH ...
- springCloud你要了解的都在这(方向性)
Spring Cloud作为一套微服务治理的框架,几乎考虑到了微服务治理的方方面面,之前也写过一些关于Spring Cloud文章,主要偏重各组件的使用,本次分享主要解答这两个问题:Spring Cl ...
- jQuery插件实现的页面功能介绍引导页效果
新产品上线或是改版升级,我们会在用户第一次使用产品时建立一个使用向导,引导用户如何使用产品,如使用演示的方式逐一介绍界面上的功能模块,从而提升了用户体验和产品的亲和力. Helloweba.com之前 ...
- SIIA CODIE AWARDS 2017
Business Technology Best Advertising or Campaign Management Platform Albert, Albert Choozle, Choozle ...
- [视频]mac系统下虚拟机parallels安装ubuntu 14.04视频教程
此文是http://www.mr-wu.cn/install-ubuntu-14-04-on-parallels-for-mac/这篇博文的补充,为整个ubuntu 14.04安装过程的视频录像. m ...
- NYOJ 298 相变点(矩阵高速功率)
点的变换 时间限制:2000 ms | 内存限制:65535 KB 难度:5 描写叙述 平面上有不超过10000个点.坐标都是已知的.如今可能对全部的点做下面几种操作: 平移一定距离(M),相对X ...
- 操作系统hosts文件
为了便于北京和大连两个更好的测试系统.该公司专门申请一个域名:大连r \\ u0026 D侧只需要部署(我方系统全权负责在大连研发.所以在大连并列比较的部署方面easy--不要忘记,该项目比我们实际做 ...
- 项目管理 BUG管理 —— 禅
眼下市场管理BUG该平台是非常,例如 QC(Quality Center) 国际顶级.功能强大但收费. Bugzilla 开源免费.功能还不错.但界面丑陋,配置繁琐. EasyBUG 在线式.无需配置 ...
- socket 主机地址相关的函数
#include <arpa/inet.h> int inet_aton (const char *name, struct in_addr *addr) 将ipv4地址从数字点的形式转化 ...
- Index of /android/repository
放这里了,总是记不住... https://mirrors.zzu.edu.cn/android/repository/