**ML : ML中的最优化方法
前言:
在机器学习方法中,若模型理解为决策模型,有些模型可以使用解析方法。不过更一般的对模型的求解使用优化的方法,更多的数据可以得到更多的精度。
AI中基于归纳的方法延伸出ML整个领域,基于数据的ML方法根据归纳准则进行拟合,基于约束函数和经验期望,并对拟合的函数形式和函数参数,进行优化。
上一篇:最优化方法之GD、SGD ;最优化之回归/拟合方法总结;
一、线性规划
线性规划、整数规划、目标规划等方法其目标函数与约束条件都是决策变量的一次函数,全部为线性规划,具有统一的数学模型及如单纯形法这样的通用解法。1947年丹齐格(G.B.Dantzig)提出了线性规划的一般方法——单纯形法。随后专业丰富了线性规划的数学模型和求解方法,并深入分析细节,如对偶理论、线性目标规划等。
摘自于小黄书,应该是自动化学院双控系的教材。
若建立的一个数学模型,(1)要求一组变量X1, X2, X3....Xn的值(2)满足特定的约束条件(Xk...Xi的之间约束关系,和Xi的定义域约束关系),(3)同时使一次目标函数 y = K1X1 + K2X2 + ... +KnXn 取得极值。即求min y( X1, X2, X3....Xn ) 。此种问题为线性规划问题。
标准形式:
min y = K1X1 + K2X2 + ... + KnXn ; ( 3 )
a11X1 + a12X2 + ... + a1nXn = b1; ( 2 )
a21X1 + a22X2 + ... + a2nXn = b2; ( 2 )
................................................... ( 2 )
am1X1 + am2X2 + ... + amnXn = bm; ( 2 )
K1<< Xi << K2 ; ( 2 )
简化形式为:

矩阵形式为:

重要的定理:
线性规划基本定理:若线性规划存在可行域,则可行域 S = { x | Ax=b,x>=0,A属于Mm*n, b 属于R^m, x 属于R^n } 为一凸集。
极点:线性规划问题的每一个基本可行解x对应可行域S的一个极点。
最优解:若线性规划具有最优解,则必可在其某个可行域的某个(或者多个)极点上达到最优解。
示例:若约束矩阵A为m*n型矩阵,且A的秩r(A)=m,则基本解的个数<= N= 组合(m,n),也是基本可行解的上限。
最基本的寻找线性规划最优解的方法为枚举法,但组合爆炸使其适用范围极窄,因此有规律寻找最优解成为必然。
单纯形法:
snip//.................................
二、非线性规划
非线性规划最简单的为一维搜索,即在一维空间寻求最优解,基本方法有黄金分割法、加步探索法、牛顿迭代法、二次优化-抛物线法。
关于一般非线性规划优化算法的求解,最优化方法一书已经介绍了很多的方法,比如有梯度下降法,坐标下降法,牛顿法和拟牛顿法,共轭梯度法。而机器学习中主要面对非线性问题,所使用的优化方法为非线性优化方法。
以下摘抄自百度百科。
1.最速下降法
梯度下降法是基于目标函数梯度的,算法的收敛速度是线性的,并且当问题是病态时或者问题规模较大时,收敛速度尤其慢(几乎不适用)。例如。SVM方法使用梯度下降法时其运行可行性受到样本数目的限制,样本数目过多会产生较大的系数矩阵,训练速度极慢。
变量轮换法(坐标下降法)虽然不用计算目标函数的梯度,但是其收敛速度依然很慢,因此它的适用范围也有局限;
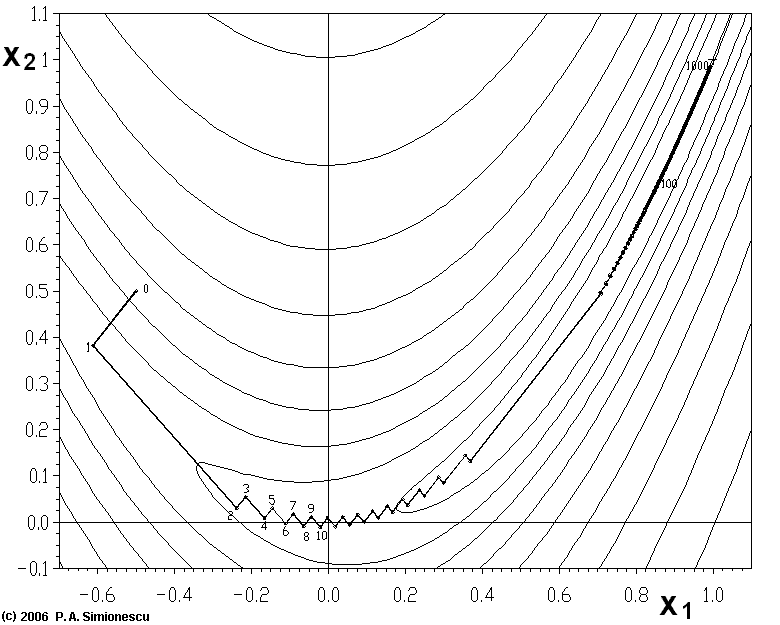
其他缺点:(1)靠近极小值时收敛速度减慢,如下图所示;(2)直线搜索时可能会产生一些问题;(3)之字形下降。
SGD和BGD
随机梯度下降每次迭代只使用一个样本,迭代一次计算量为n2,当样本个数m很大的时候,随机梯度下降迭代一次的速度要远高于批量梯度下降方法。两者的关系可以这样理解:随机梯度下降方法以损失很小的一部分精确度和增加一定数量的迭代次数为代价,换取了总体的优化效率的提升。增加的迭代次数远远小于样本的数量。
对批量梯度下降法和随机梯度下降法的总结:
批量梯度下降---最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小,但是对于大规模样本问题效率低下。
随机梯度下降---最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近,适用于大规模训练样本情况。
2.牛顿迭代法
牛顿法(修正的牛顿法)主要思想是:体现为一种函数逼近方法,在极小点附近用二阶泰勒多项近似代替目标函数f(x), 从而求出极小点的估计值。若f(x)在极小点附近有二阶连续偏导数,且在点处的黑塞矩阵正定,可进行迭代估计。又称为切线法。
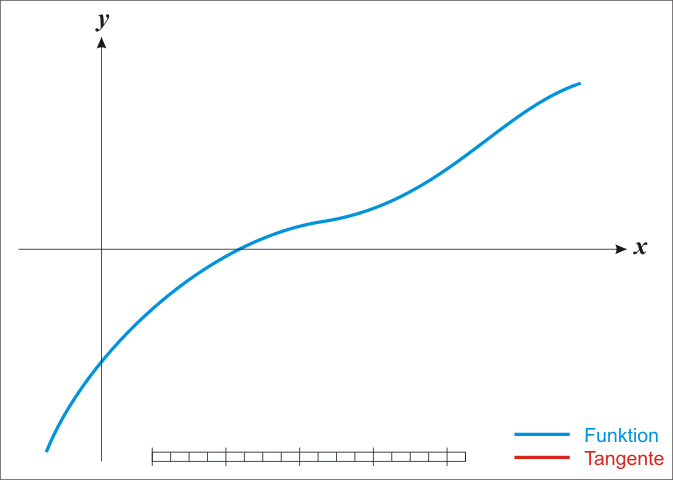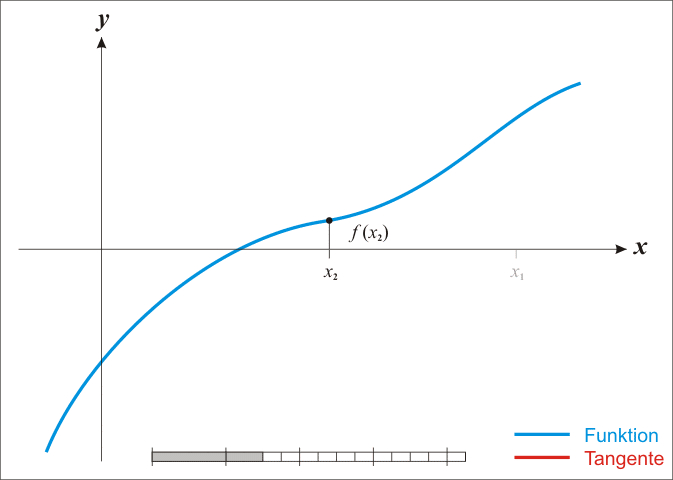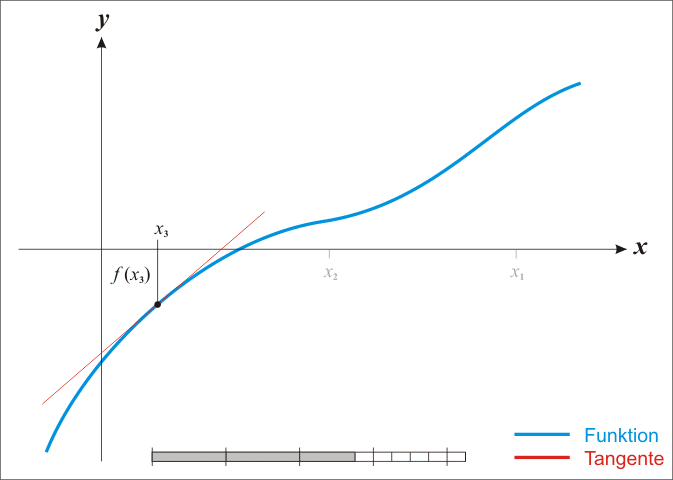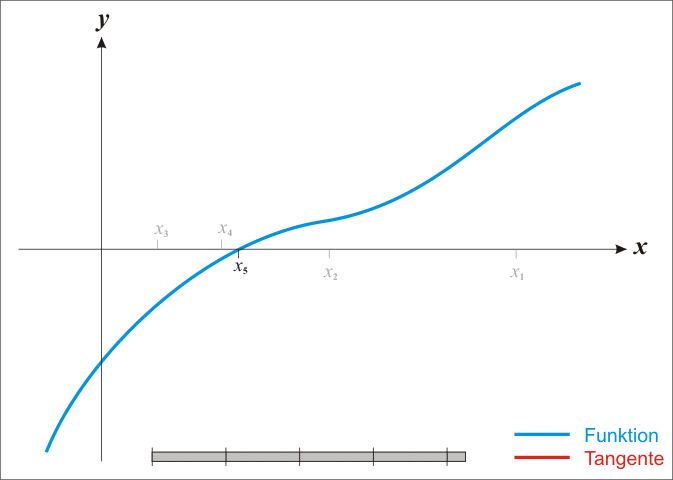
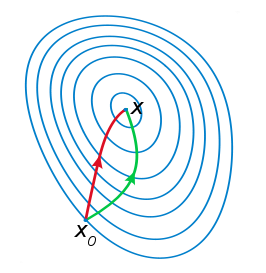
注:红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
图片来自于:ML中的常用优化方法,公式挺好
根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
牛顿法是基于目标函数的二阶导数(海森矩阵)的,其收敛速度较快,迭代次数较少,尤其是在最优值附近时,收敛速度是二次的。但牛顿法的问题在于当海森矩阵稠密时,每次迭代的计算量比较大,因为每次都会计算目标函数的海森矩阵的逆,这样一来,当问题规模较大时,不仅计算量大(有时大到不可计算),而且需要的存储空间也多,因此牛顿法在面对海量数据时由于每一步迭代的开销巨大而变得不适用;
3.拟牛顿法
牛顿法在每次迭代时不能总是保证海森矩阵是正定的,一旦海森矩阵不是正定的,优化方向就会 “ 跑偏 ”,从而使得牛顿法失效,也说明了牛顿法的鲁棒性较差。拟牛顿法用海森矩阵的逆矩阵来替代海森矩阵,虽然每次迭代不能保证是最优的优化方向,但是近似矩阵始终是正定的,因此算法总是朝着最优值的方向在搜索。
拟牛顿法(DFP和BFGS)是20世纪50年代,美国Argonne国家实验室的物理学家W. C. Davidon所提出来的。是在牛顿法的基础上引入了海森矩阵的近似矩阵,避免每次迭代都要计算海森矩阵的逆,拟牛顿法的收敛速度介于梯度下降法和牛顿法之间,是超线性的。拟牛顿法的问题也是当问题规模很大时,近似矩阵变得很稠密,在计算和存储上也有很大的开销,因此也会变得不实用。
优势:拟牛顿法和最速下降法(Steepest Descent Methods)一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法(Newton's Method)更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。

拟牛顿法主要有这几种方法:DFP方法,BFGS方法,SR1方法,Broyden族方法。
DFP方法

BFGS方法

SR1方法
Broyden族
4. L-FBGS算法
从上面的综合描述可以看出,很多优化算法在理论上有很好的结果,并且当优化问题的规模较小时,上面的任何算法都能够很好地解决问题。而在实际工程中,很多算法却失效了。比如说,在实际工程中,很多问题是病态的,这样一来,基于梯度的方法肯定会失效,即便迭代上千上万次也未必收敛到很好的结果;另外,当数据量大的时候,牛顿法和拟牛顿法需要保存矩阵的内存开销和计算矩阵的开销都很大,因此也会变得不适用。
实际工程中解决大规模优化问题时必然会用到的一种优化算法:L-BFGS算法。
L-BFGS算法就是对拟牛顿算法的一个改进。它的名字已经告诉我们它是基于拟牛顿法BFGS算法的改进。L-BFGS算法的基本思想是:算法只保存并利用最近m次迭代的曲率信息来构造海森矩阵的近似矩阵。
在介绍L-BFGS算法之前,我们先来简单回顾下BFGS算法。
以下参考:http://blog.csdn.net/henryczj/article/details/41542049?utm_source=tuicool&utm_medium=referral
在算法的每一步迭代,有如下式:

式(1)中ak是步长,Hk的更新通过如下公式:
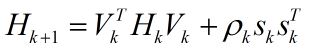
在式(2)中
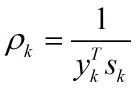
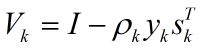
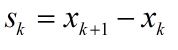
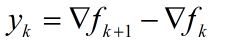
从式(2)到式(6)可以看出Hk+1是用{sk, yk}修正Hk来得到的。需要注意的是,这里Hk表示海森矩阵的逆的近似矩阵。
在BFGS算法中,由于Hk随着迭代次数的增加会越来越稠密,当优化问题的规模很大时,存储和计算矩阵Hk将变得不可行。
为了解决上述问题,我们可以不存储矩阵Hk,而是存储最近m次迭代的曲率信息,即{sk, yk}。每当完成一次迭代,最旧的曲率信息{si, yi}将被删除,而最新的曲率信息被保存下来,维持一个曲率队列。通过这种方式,算法保证了保存的曲率信息是来自于最近的m次迭代。在实际工程中,m取3到20往往能有很好的结果。除了更新矩阵Hk的策略和初始化Hk的方式不同外,L-BFGS算法和BFGS算法是一样的。
下面将会详细介绍一下矩阵Hk的更新步骤。
在第k次迭代,算法求得了xk,并且保存的曲率信息为{si, yi},其中i = k-m, …, k-1。为了得到Hk,算法首先选择一个初始的矩阵Hk0,这是不同于BFGS算法的一个地方,L-BFGS算法允许每次迭代选取一个初始的矩阵,然后用最近的m次曲率信息对该初始矩阵进行修正,从而得到Hk。
通过反复利用式(2),我们可以得到下式:
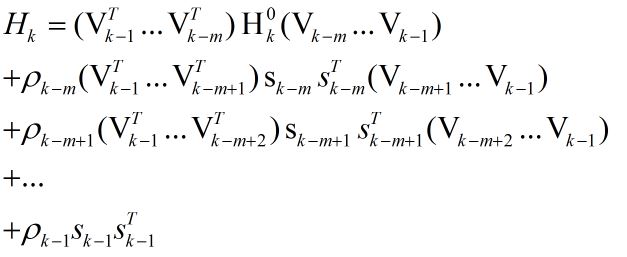
关于每次迭代时Hk0的初始值的设定,一个在实践中经常用到的有效方法为:
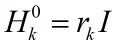
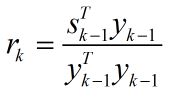
其中rk表示比例系数,它利用最近一次的曲率信息来估计真实海森矩阵的大小,这就使得当前步的搜索方向较为理想,而不至于跑得“太偏”,从而使得步长ak = 1在大多数时候都是满足的,这样就省去了步长搜索的步骤,节省了时间。
在L-BFGS算法中,通过保存最近m次的曲率信息来更新近似矩阵的这种方法在实践中是很有效的。
虽然L-BFGS算法是线性收敛,但是每次迭代的开销非常小,因此L-BFGS算法执行速度还是很快的,而且由于每一步迭代都能保证近似矩阵的正定,因此算法的鲁棒性还是很强的。
shooting算法
百度最近提出了一个shooting算法,该算法比L-BFGS快了十倍。由于L-BFGS算法的迭代方向不是最优的,所以我猜想shooting算法应该是在迭代的方向上做了优化。
............................
**ML : ML中的最优化方法的更多相关文章
- C#中的深度学习(五):在ML.NET中使用预训练模型进行硬币识别
在本系列的最后,我们将介绍另一种方法,即利用一个预先训练好的CNN来解决我们一直在研究的硬币识别问题. 在这里,我们看一下转移学习,调整预定义的CNN,并使用Model Builder训练我们的硬币识 ...
- ML:机器学习中常用的Octave语句
coursera上吴恩达的机器学习课程使用Octave/Matlab实现算法,有必要知道Octave简单的语句.最重要的:在遇到不会的语句,使用'''help '''或者'''doc '''查看官方文 ...
- .net ML机器学习中遇见错误记录
避免入坑: 1.错误提示 numClasses must be at least 2 大概是训练模型的数据分类必须是两种,如下错误: 正确数据集如下:
- #Week8 Advice for applying ML & ML System Design
一.Evaluating a Learning Algorithm 训练后测试时如果发现模型表现很差,可以有很多种方法去更改: 用更多的训练样本: 减少/增加特征数目: 尝试多项式特征: 增大/减小正 ...
- ML.NET 发布0.11版本:.NET中的机器学习,为TensorFlow和ONNX添加了新功能
微软发布了其最新版本的机器学习框架:ML.NET 0.11带来了新功能和突破性变化. 新版本的机器学习开源框架为TensorFlow和ONNX添加了新功能,但也包括一些重大变化, 这也是发布RC版本之 ...
- ML.NET Cookbook --- 1.如何从文本文件中加载数据?
使用ML.NET中的TextLoader扩展方法从文本文件中加载数据.你需要知道在文本文件中数据列在那里,它们的类型是什么,在文本文件中什么位置可以找到它们. 请注意:对于ML.NET只读取文件的某些 ...
- Spark ML源码分析之一 设计框架解读
本博客为作者原创,如需转载请注明参考 在深入理解Spark ML中的各类算法之前,先理一下整个库的设计框架,是非常有必要的,优秀的框架是对复杂问题的抽象和解剖,对这种抽象的学习本身 ...
- 机器学习 ML.NET 发布 1.0 RC
ML.NET 是面向.NET开发人员的开源和跨平台机器学习框架(Windows,Linux,macOS),通过使用ML.NET,.NET开发人员可以利用他们现有的工具和技能组,为情感分析,推荐,图像分 ...
- 关于ML.NET v1.0 RC的发布说明
ML.NET是面向.NET开发人员的开源和跨平台机器学习框架(Windows,Linux,macOS).使用ML.NET,开发人员可以利用他们现有的工具和技能组,通过为情感分析,推荐,图像分类等常见场 ...
随机推荐
- JSTL 实现 为Select赋多个值
需要注意需要在.jsp文件中引入相应的类库 <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core ...
- 对vuex的浅解
vuex是什么? 官网的解释是 Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式.它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化.Vuex 也 ...
- Expanding Rods POJ 1905 二分
Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 17050 Accepted: 4503 Description When ...
- Windows 10卸载Edge浏览器(不成功的别试了)
在命令行输入: PowerShell dir $env:LOCALAPPDATA\Packages\*edge*^|ren -newname MicrosoftEdge.old ; dir $env: ...
- JVM内存管理和垃圾回收机制介绍
http://backend.blog.163.com/blog/static/20229412620128233285220/ 内存管理和垃圾回收机制是JVM最核心的两个组成部分,对其内部实 ...
- .NET Web API - 去掉讨厌的$id并且强制返回json格式
// 只返回json字符串,屏蔽自动选择xml格式的可能性,同时去掉讨厌的$id var json = config.Formatters.JsonFormatter; json.Serializer ...
- JMS解决系统间通信问题
近期在给公司项目做二次重构,将原来庞大的系统拆分成几个小系统.系统与系统之间通过接口调用,系统间通信有非常多方式,如系统间通信接口做成请求controller,只是这样不方便也不安全,经常使用的方式是 ...
- 禁止root用户直接远程telnet/ssh登陆
AIX 封闭root,只能使用su登录root用户,禁止root用户直接远程登陆. 1. 禁止telnet登录 smit chuser ->root ->User can ...
- cocos2d-x开发的《派对小游戏》-github源代码分享
这是博主非常久曾经写的一个cocos2d-x跨平台小游戏,我称它为<派对小游戏>,如今分享给大家.希望对大家有所帮助的话. 项目源代码地址:https://github.com/xieba ...
- Android WiFi开发教程(三)——WiFi热点数据传输
在上一篇文章中介绍了WiFi的搜索和连接,如果你还没阅读过,建议先阅读上一篇Android WiFi开发教程(二)——WiFi的搜索和连接.本篇接着简单介绍手机上如何通过WiFi热点进行数据传输. 跟 ...