pandas read_sql与read_sql_table、read_sql_query 的区别
一:创建链接数据库引擎
from sqlalchemy import create_engine
db_info = {'user':'user',
'password':'pwd',
'host':'localhost',
'database':'xx_db' # 这里我们事先指定了数据库,后续操作只需要表即可
}
engine = create_engine('mysql+pymysql://%(user)s:%(password)s@%(host)s/%(database)s?charset=utf8' % db_info,encoding='utf-8') #这里直接使用pymysql连接,echo=True,会显示在加载数据库所执行的SQL语句。
二:读取数据库数据,存储为DataFrame格式
部分来自于博客:http://blog.csdn.net/u011301133/article/details/52488690
1:读取自定义数据(通过SQL语句)
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None,chunksize=None)
例如:data = pd.read_sql_query('select * from t_line ',con = engine),会返回一个数据库t_line表的DataFrame格式。如有有时间列可以parse_dates = [time_column]用于解析时间,并把此列作为索引index_col = [time_column]
read_sql_query()中可以接受SQL语句,包括增删改查。但是DELETE语句不会返回值(但是会在数据库中执行),UPDATE,SELECT,等会返回结果.
例如:data = pd.read_sql_query('delete from test_cjk where f_intime = 1309',con = engine),这条语句会执行,删除 test_cjk表中f_intime=1309的值,但不会返回data。
其他例子:
'''插入操作''' pd.read_sql_query("insert into cjk_test h values %(data)s",params={'data':v_split[11]},con=engine)
'''更新操作''' pd.read_sql_query("update cjk_test set a='粤11111' WHERE a='粤B30738'",con =engine)
'''删除操作'''pd.read_sql_query("delete from cjk_test where c='1'",con=engine)
删除插入更新操作没有返回值,程序会抛出SourceCodeCloseError,并终止程序。如果想继续运行,可以try捕捉此异常。
2:读取整张表于DataFrame格式(通过表名)
pd.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
例如:data = pd.read_sql_table(table_name = 't_line',con = engine,parse_dates = 'time',index_col = 'time',columns = ['a','b','c'])
3:读数据库(通过SQL语句或者表名)
通过sql语句的见我另一篇文章:http://www.cnblogs.com/cymwill/articles/7576600.html
pd.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
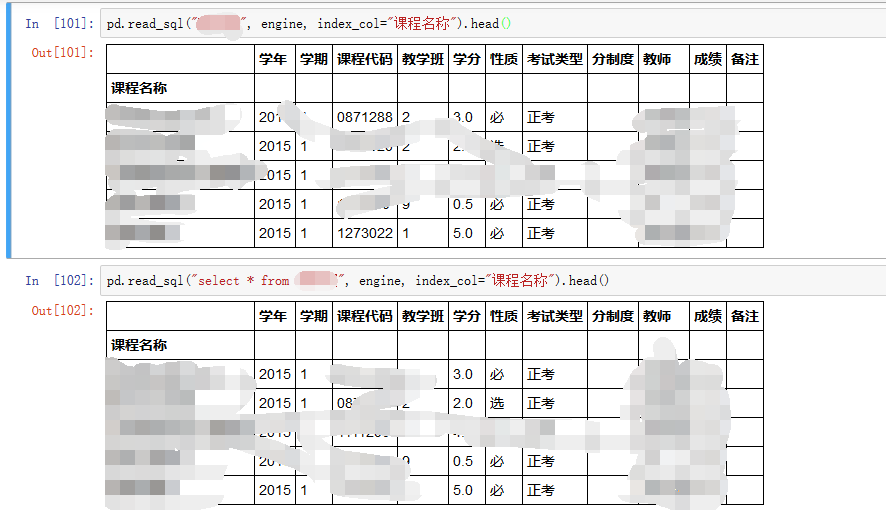
下面两个的作用又是相同的:
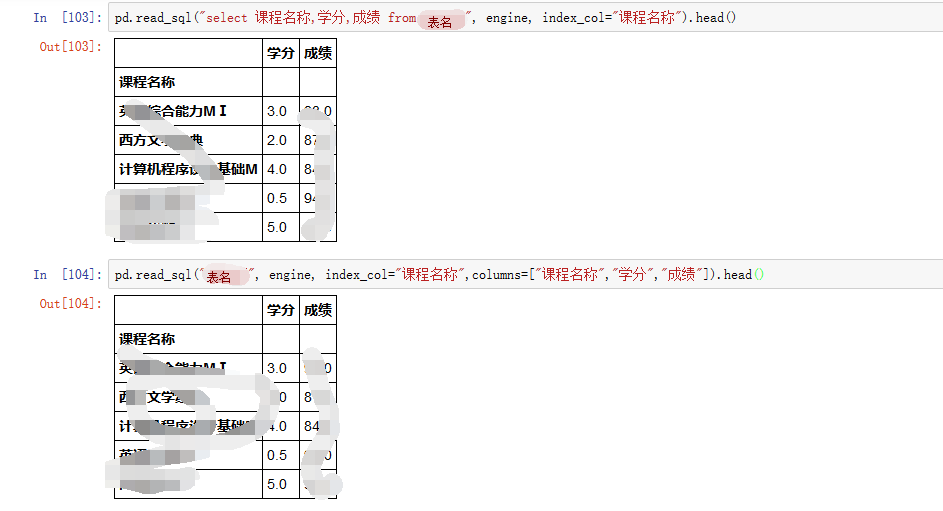
这个是官网的源代码里面的片段:
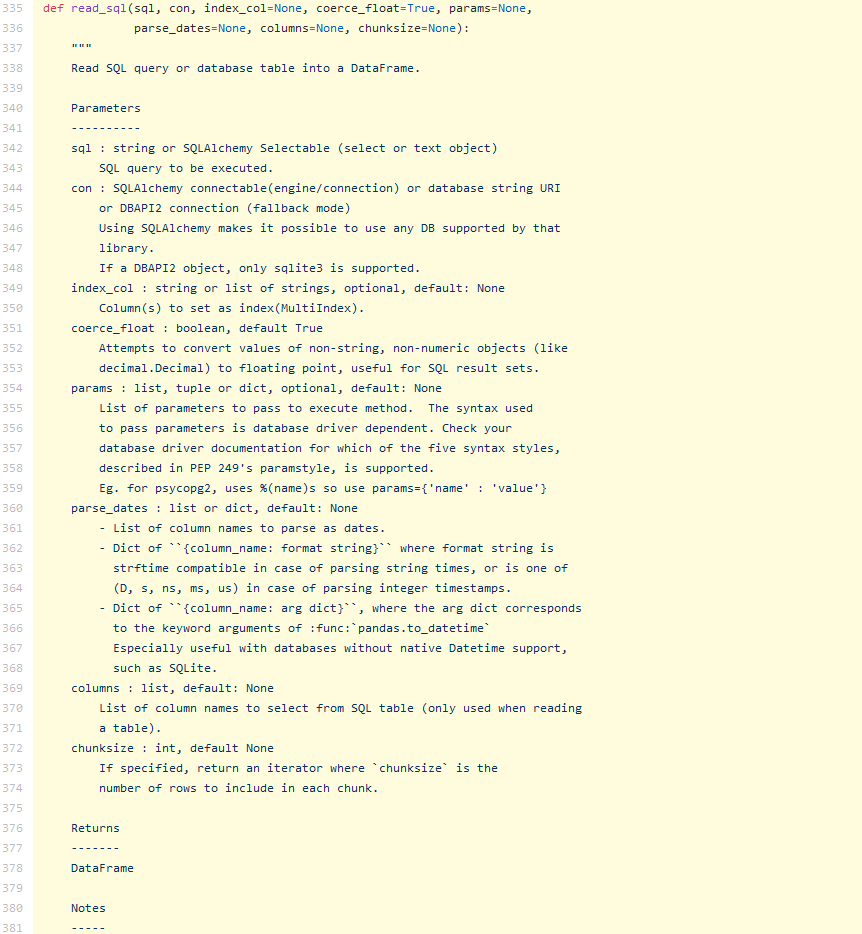
我们再将query与table相反的试一下:
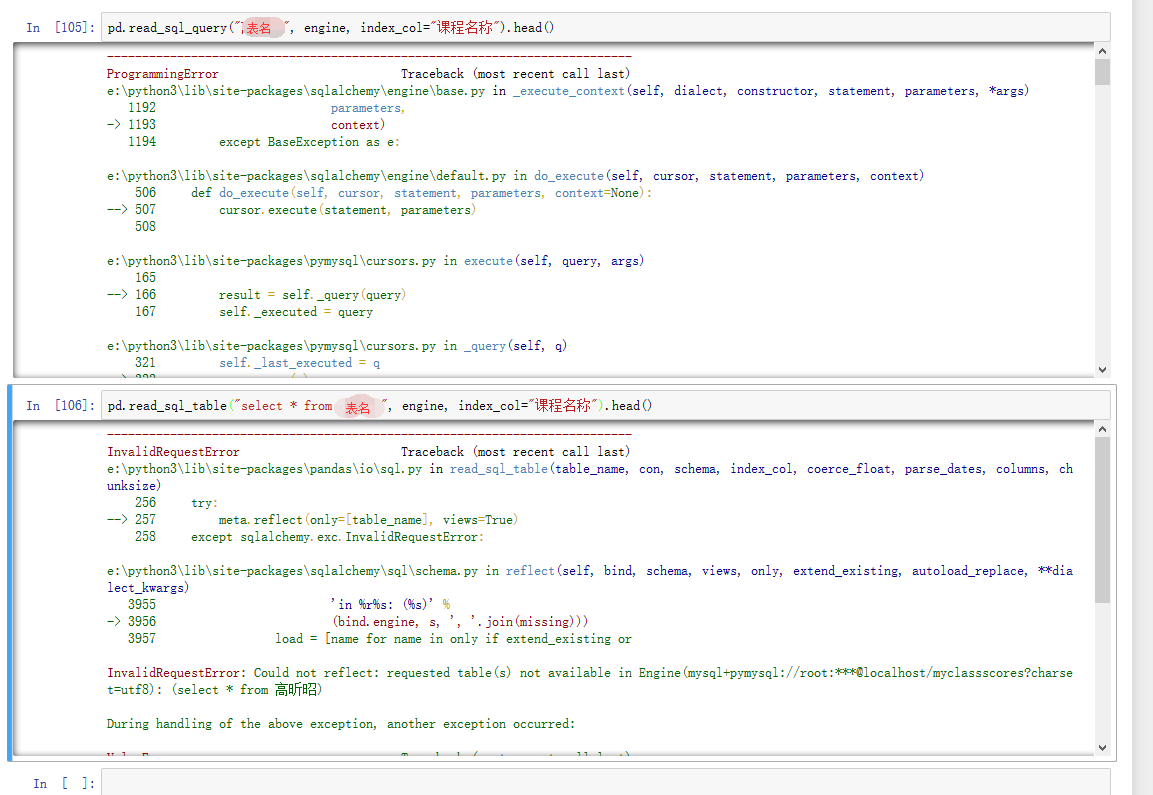
报错,故两者不能反过来。
从上面可以看到,其实read_sql是综合了read_sql_table和read_sql_query的,所以一般用read_sql就好了,省得再去区别那些东西。
三:数据写入于数据库
见我另一篇文章:http://www.cnblogs.com/cymwill/p/8288667.html
pandas read_sql与read_sql_table、read_sql_query 的区别的更多相关文章
- Pandas文件读取——Pandas.read_sql() 详解
目录 一.函数原型 二.常用参数说明 三.连接数据库方式--MySQL ①用sqlalchemy包构建数据库链接 ②用DBAPI构建数据库链接 ③将数据库敏感信息保存在文件中 一.函数原型 panda ...
- Pandas dataframe 与 Spark dataframe 的区别
区别 :http://www.voidcn.com/article/p-wsqbotem-boa.html 获取列名的列表: DataFrame.columns.values.tolist()
- [译]pandas中的iloc loc的区别?
loc 从特定的 gets rows (or columns) with particular labels from the index. iloc gets rows (or columns) a ...
- Pandas中merge和join的区别
可以说merge包含了join的操作,merge支持通过列或索引连表,而join只支持通过索引连表,只是简化了merge的索引连表的参数 示例 定义一个left的DataFrame left=pd.D ...
- Pandas中Series与Dataframe的区别
1. Series Series通俗来讲就是一维数组,索引(index)为每个元素的下标,值(value)为下标对应的值 例如: arr = ['Tom', 'Nancy', 'Jack', 'Ton ...
- read_sql_query, def read_sql_table
read_sql_query, read_sql_table def read_sql_query(sql, con, index_col=None, coerce_float=True, param ...
- Pandas:读取数据库read_sql
学习自:pandas.read_sql - pandas 1.2.4 documentation (10条消息) pd.read_sql()参数详解_pandas.read_csv()参数详解-CSD ...
- pandas DataFrame 索引(iloc 与 loc 的区别)
Pandas--ix vs loc vs iloc区别 0. DataFrame DataFrame 的构造主要依赖如下三个参数: data:表格数据: index:行索引: columns:列名: ...
- Pandas IO 操作
数据分析过程中经常需要进行读写操作,Pandas实现了很多 IO 操作的API 格式类型 数据描述 Reader Writer text CSV read_csv to_csv text JSON r ...
随机推荐
- css,查询相应标签,div等
1.类名 .类别 例子: 查询类名为“useradd” .useradd{ margin-top:50px; margin-left:200px;} 2.属性找 例子:查询类为useradd下的inp ...
- discuz X3 门户定制
为了实现门户的定制,在本机全新的安装了discuzX3,现在只想使用其门户功能(即文章CMS管理).但是论坛功能是不能关闭的可能论坛是discuz的核心功能吧. 全新安装的discuzx3,主导航上只 ...
- MySQL中lock与latch的区分
这里要区分锁中容易令人混淆的概念lock与latch.在数据库中,lock与latch都可以成为锁,但两者有截然不同的含义 latch 一般称为闩锁(轻量级的锁) 因为其要求锁定的时间非常短,若迟勋时 ...
- WebService中WSDL和WADL(转)
转自https://blog.csdn.net/liuxiao723846/article/details/51611183#commentBox 自己加了修改批注方便自己理解. 1.Java开发We ...
- ZFI_VENDOR_CREATE
创建供应商函数, 需要考虑是 G_TASK = I /U /M FUNCTION zfyj_vendor_create. *"-------------------------------- ...
- Java栈和堆的区别
一.栈空间 1.栈空间存储数据效率高 2.栈中的数据是按“先进后出”的方式管理 3.栈空间存储空间比较小,不能存放大量的数据 4.JVM将基本类型的数据存放在栈空间 帮助理解 1.“客栈” 能提供很多 ...
- C# 函数3
//获取部分 public class GF_GET { /// <summary> /// 根据坐标点获取屏幕图像 /// ...
- gearman background后台job状态获取
GearmanClient background job有一个方法叫: public array GearmanClient::jobStatus ( string $job_handle ) Get ...
- 自制Javascript浮动广告
<%@ Page Language="VB" AutoEventWireup="false" CodeFile="Default.aspx.vb ...
- css样式之补充
css常用的一些属性: 1.去掉下划线 :text-decoration:none ;2.加上下划线: text-decoration: underline; 3.调整文本和图片的位置(也就是设置元素 ...