《机器学习实战-KNN》—如何在cmd命令提示符下运行numpy和matplotlib
问题背景:好吧,文章标题是瞎取得。平常用cmd运行python代码问题不大,我在学习《机器学习实战》这本书时,发现cmd无法运行
import numpy as np以及import matplotlib*这条语句,原因是没有安装numpy和matplotlib。虽然用Anaconda的prompt以及Spyder等都可以成功运行,但如何在cmd环境下使用代码中含有numpy和matplotlib代码的文件呢?
至于如何安装,直接给答案:
用pip install numpy和pip install matplotlib命令即可,如图:

接下来的代码不是给你们看的,是给我自己看的(っ•̀ω•́)っ✎⁾⁾
现在我们试着运行代码:
这里的文件名为KNN02.py,内容来自《机器学习实战》
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 29 11:14:25 2018
@author: CHJ
"""
import numpy as np
"""
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
"""
def file2matrix(filename):
#打开文件
fr = open(filename)
#读取文件所有内容
array0Lines = fr.readlines()
#print(array0Lines)
#得到文件行数
numberOfLines = len(array0Lines)
#返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列
returnMat = np.zeros((numberOfLines,3)) #zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0
#返回的分类标签向量
classLabelVector = []
#行的索引值
index = 0
for line in array0Lines:
#s.strip(rm),当rm空时,默认删除空白符(包括'\n','\r','\t',' ')
line = line.strip()
#print(line)
#使用s.split(str ="",num = string,cout(str))将字符串根据'\t'分隔符进行切片。
listFromLine = line.split('\t') #将上一步得到的整行数据分割成一个元素列表
#print(listFromLine)
# 每列的属性数据
returnMat[index,:] = listFromLine[0:3] #将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
#print(returnMat[index,:])
#根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力
if listFromLine[-1] == 'didntLike': #索引值-1表示列表中最后一列元素
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat,classLabelVector
if __name__ == "__main__":
#打开的文件名
filename = 'datingTestSet.txt'
#打开并处理数据
datingDataMat, datingLables = file2matrix(filename)
print(datingDataMat)
print(datingLables)
#print(len(datingLabel))
看看结果:

__现在要用到matplotlib,同样也是cmd -> pip install matplotlib __
安装成功了,现在我试着在cmd环境下运行以下代码:
文件名:KNN02.py
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 29 11:14:25 2018
@author: CHJ
"""
import numpy as np
"""
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
"""
def file2matrix(filename):
#打开文件
fr = open(filename)
#读取文件所有内容
array0Lines = fr.readlines()
#print(array0Lines)
#得到文件行数
numberOfLines = len(array0Lines)
#返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列
returnMat = np.zeros((numberOfLines,3)) #zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0
#返回的分类标签向量
classLabelVector = []
#行的索引值
index = 0
for line in array0Lines:
#s.strip(rm),当rm空时,默认删除空白符(包括'\n','\r','\t',' ')
line = line.strip()
#print(line)
#使用s.split(str ="",num = string,cout(str))将字符串根据'\t'分隔符进行切片。
listFromLine = line.split('\t') #将上一步得到的整行数据分割成一个元素列表
#print(listFromLine)
# 每列的属性数据
returnMat[index,:] = listFromLine[0:3] #将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
#print(returnMat[index,:])
#根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力
if listFromLine[-1] == 'didntLike': #索引值-1表示列表中最后一列元素
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat,classLabelVector
"""编写一个可以将数据可视化的showdatas函数"""
from matplotlib.font_manager import FontProperties
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
def showdatas(datingDataMat,datingLabels):
#设置汉字格式(这里选择:华文新魏 常规)
font = FontProperties(fname = r'C:\Windows\Fonts\STXINWEI.TTF', size = 14)
#将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(13,8)
#当nrow=2, ncols = 2时,代表fig画布被分为四个区域,axs[0][0]表示第一行第一个区域
fig,axs = plt.subplots(nrows =2,ncols=2,sharex=False,sharey = False,figsize = (13,8))
#numberOfLabels = len(datingLabels)
LabelsColors = []
for i in datingLabels:
if i ==1:
LabelsColors.append('black')
if i ==2:
LabelsColors.append('blue')
if i ==3:
LabelsColors.append('red')
#画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第二列(玩游戏)数据画散点数据,散点大小为15,透明度为0.5
axs[0][0].scatter(x = datingDataMat[:,0],y = datingDataMat[:,1],color = LabelsColors,s = 15,alpha = 0.5)
#设置标题,x轴label,y轴label
axs0_title_text = axs[0][0].set_title(u'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比',FontProperties = font)
axs0_xlabel_text = axs[0][0].set_xlabel(u'每年获得的飞行常客里程数',FontProperties = font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'玩视频游戏所消耗时间占比',FontProperties = font)
plt.setp(axs0_title_text, size = 9,weight = 'bold',color = 'blue')
plt.setp(axs0_xlabel_text,size = 7,weight = 'bold',color = 'black')
plt.setp(axs0_ylabel_text,size = 7,weight = 'bold',color = 'black')
#画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[0][1].scatter(x=datingDataMat[:,0], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs1_title_text = axs[0][1].set_title(u'每年获得的飞行常客里程数与每周消费的冰激淋公升数',FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u'每年获得的飞行常客里程数',FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u'每周消费的冰激淋公升数',FontProperties=font)
plt.setp(axs1_title_text, size=9, weight='bold', color='green')
plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black')
#画出散点图,以datingDataMat矩阵的第二(玩游戏)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[1][0].scatter(x=datingDataMat[:,1], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs2_title_text = axs[1][0].set_title(u'玩视频游戏所消耗时间占比与每周消费的冰激淋公升数',FontProperties=font)
axs2_xlabel_text = axs[1][0].set_xlabel(u'玩视频游戏所消耗时间占比',FontProperties=font)
axs2_ylabel_text = axs[1][0].set_ylabel(u'每周消费的冰激淋公升数',FontProperties=font)
plt.setp(axs2_title_text, size=9, weight='bold', color='red')
plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')
#设置图例
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='blue', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
#添加图例
axs[0][0].legend(handles=[didntLike,smallDoses,largeDoses])
axs[0][1].legend(handles=[didntLike,smallDoses,largeDoses])
axs[1][0].legend(handles=[didntLike,smallDoses,largeDoses])
#显示图片
plt.show()
if __name__ == "__main__":
#打开的文件名
filename = 'datingTestSet.txt'
#打开并处理数据
datingDataMat, datingLabels = file2matrix(filename)
# =============================================================================
# print(datingDataMat)
# print(datingLables)
# #print(len(datingLabel))
# =============================================================================
showdatas(datingDataMat, datingLabels) #显示图像
在cmd下运行如图:

发现它会自动唤醒我安装的Python3.6

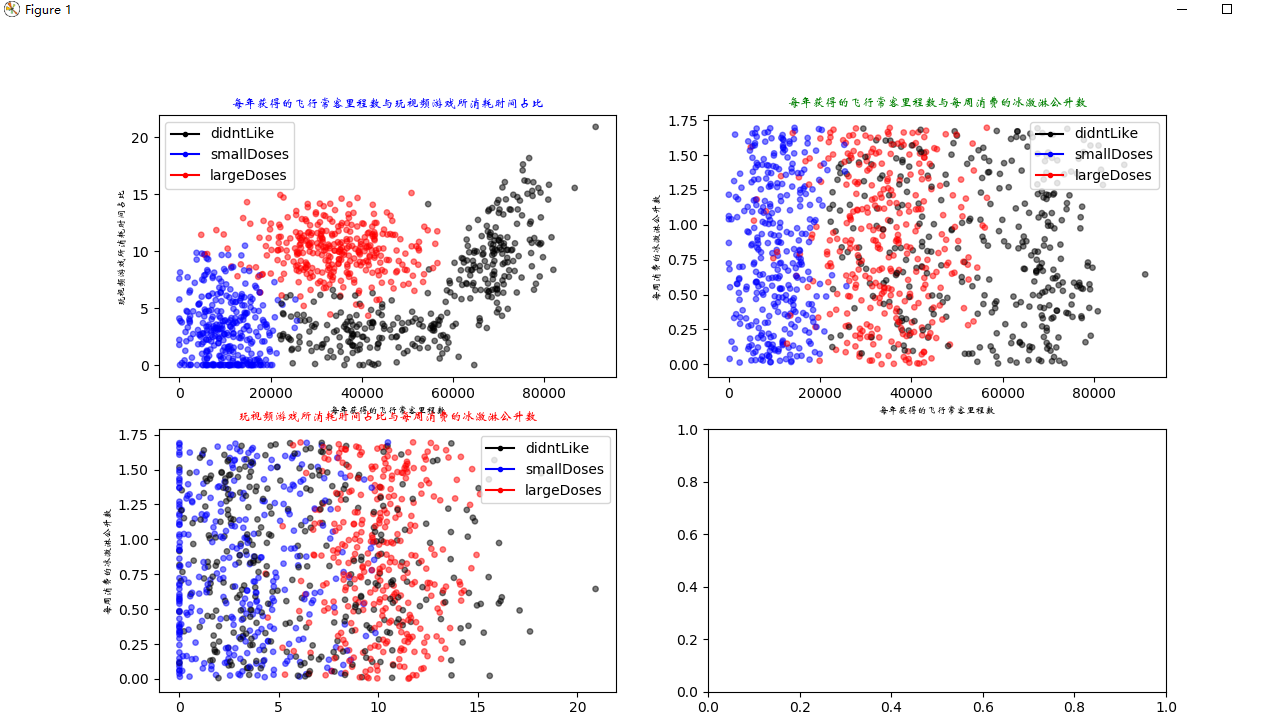
输出图像:
《机器学习实战-KNN》—如何在cmd命令提示符下运行numpy和matplotlib的更多相关文章
- 如何在cmd命令下运行python脚本
1.打开cmd窗口,输入:cd c:\\python27 (首先得确认python已加入环境变量) 2.第二条命令:python[空格]完整的python脚本路径,运行即可 3.一个案例: Micr ...
- 如何在Linuxt系统下运行maven项目
如何在Linuxt系统下运行maven项目 我们知道现在利用MAVEN来管理JAVA项目是非常常见的.比如公司一般都有一个自己的MAVEN仓库,通过MAVEN仓库来解决我们的项目依赖,更加方便的构建项 ...
- Jmeter(五十四) - 从入门到精通高级篇 - 如何在linux系统下运行jmeter脚本 - 上篇(详解教程)
1.简介 上一篇宏哥已经介绍了如何在Linux系统中安装Jmeter,想必各位小伙伴都已经在Linux服务器或者虚拟机上已经实践并且都已经成功安装好了,那么今天宏哥就来介绍一下如何在Linux系统下运 ...
- 机器学习实战knn
最近在学习这本书,按照书上的实例编写了knn.py的文件,使用canopy进行编辑,用shell交互时发现运行时报错: >>> kNN.classify0([0,0],group,l ...
- 机器学习实战-KNN
KNN算法很简单,大致的工作原理是:给定训练数据样本和标签,对于某测试的一个样本数据,选择距离其最近的k个训练样本,这k个训练样本中所属类别最多的类即为该测试样本的预测标签.简称kNN.通常k是不大于 ...
- 在cmd窗口下运行Java程序时无法找到主类的解决办法
我是Java的初学者,昨天在cmd窗口下运行一段Java程序时总是有问题,可以编译但无法执行. 也就是javac时正确,一旦java时就不对了,提示找不到或无法加载主类,经百度谷歌再加上自己的摸索终于 ...
- 机器学习实战kNN之手写识别
kNN算法算是机器学习入门级绝佳的素材.书上是这样诠释的:“存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都有标签,即我们知道样本集中每一条数据与所属分类的对应关系.输入没有标签的新数据 ...
- CMD命令提示符下选中文字即可以复制和SecureCRT一样
用过 SecureCRT 的都会觉得复制粘贴很方便.只要选中相应文字,会自动复制.然后点鼠标右键就可以粘贴,非常方便. 但是在windows系统下的CMD里面,每次都要点鼠标右键→标记,再选中相应文字 ...
- sklearn机器学习实战-KNN
KNN分类 KNN是惰性学习模型,也被称为基于实例的学习模型 简单线性回归是勤奋学习模型,训练阶段耗费计算资源,但是预测阶段代价不高 首先工作是把label的内容进行二值化(如果多分类任务,则考虑On ...
随机推荐
- js事件绑定的方法
废话不多少,直接上代码 第一种 <body> <div style="width:400px;height:400px;background:blueviolet" ...
- FFmpeg总结(六)AV系列结构体之AVPacket
AVPacket位置:libavcodec/avcodec.h下: watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvaGVqanVubGlu/font/5a6 ...
- Servlet注解
在Servle2.5能够使用注解 在web.xml的<web-app>标签下有一属性metadata-complete="true"在设置true时,Servlet中的 ...
- php中使用curl来post一段json数据
场景:在调用第三方接口时经常需要使用到curl进行数据交互,在初次使用时遇到一些小问题,记录下来随时查阅. 封装curl相关方法便于使用,方法如下: /** * @param $url * @para ...
- 合并子目录(hash)
题目2 : 合并子目录 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi的电脑的文件系统中一共有N个文件,例如: /hihocoder/offer22/soluti ...
- 《挑战程序设计竞赛》1.6 轻松热身 POJ1852
Ants Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 12782 Accepted: 5596 Description ...
- FW 配置一个私有的Docker仓库
思维 66 3月1日 发布 建分支 0 分支 收藏 0 收藏 我们在本地开发时,如果内网能部署一台Docker服务器,无疑会极大的方便镜像的分享发布,有些私有镜像就是可以直接放到内网服务器上,省去了不 ...
- Centos之常见目录作用介绍(九)
我们先切换到系统根目录 / 看看根目录下有哪些目录 [root@localhost ~]# cd / [root@localhost /]# ls bin dev home lib64 mn ...
- cxGrid时间格式与导出Excel
引用cxFormats单元: ShortDateFormat := 'dd/mm/yyyy'; DateSeparator := '/'; cxFormatController.UseDelphiDa ...
- 洛谷P5274 优化题(ccj)
洛谷P5274 优化题(ccj) 题目背景 CCJCCJ 在前往参加 Universe \ OIUniverse OI 的途中... 题目描述 有一个神犇 CCJCCJ,他在前往参加 Universe ...