Spark是什么
官方直达电梯
Spark一种基于内存的通用的实时大数据计算框架(作为MapReduce的另一个更优秀的可选的方案)
- 通用:Spark Core 用于离线计算,Spark SQL 用于交互式查询,Spark Streaming 用于实时流式计算,Spark Mlib 用于机器学习,Spark GraphX 用于图计算
- 实时:Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
一、Spark和Storm的区别
Storm的计算模型(实时)
- Storm是针对每条数据的流式实时计算框架,由于每条数据过来就直接处理,每条数据都会带来大量的资源消耗(传输,通信,校验等)吞吐量不高
- storm可以动态调整并行度
- Storm保证了更高的实时性,毫秒级延迟
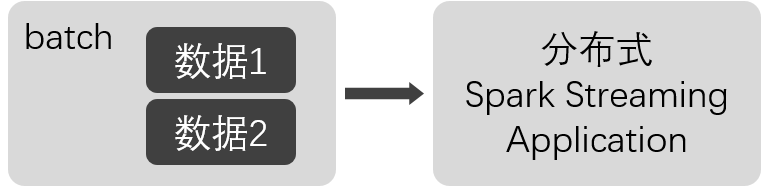
Spark Stream计算模型(准实时)
- 通过设置时间间隔 batch interval 一个时间间隔内的数据作为一个Batch收集起来给Spark Streaming Application处理(少了很多传输,校对开销),保证了高吞吐量
- 秒级延迟
- 结合Spark生态圈可以发挥很大的威力
二、Spark Streaming和MapReduce的对比
Shuffle以及MapReduce的计算模型决定了MapReduce只适合对速度要求不敏感的离线批处理任务
- Spark的多进程任务可能在同一个物理机器的内存上完成(Spark shuffle也会使用磁盘)
- MapReduce死板的模型必须基于磁盘和大量的网络传输
- MapReduce的程度编写复杂,Spark更容易上手,支持(Scale JAVA[8支持函数式编程] Python)
- Spark 在缺少调优时,会出现OOM(Out Of Memory)的问题,导致程序无法执行,而MapReduce就算是慢也能执行

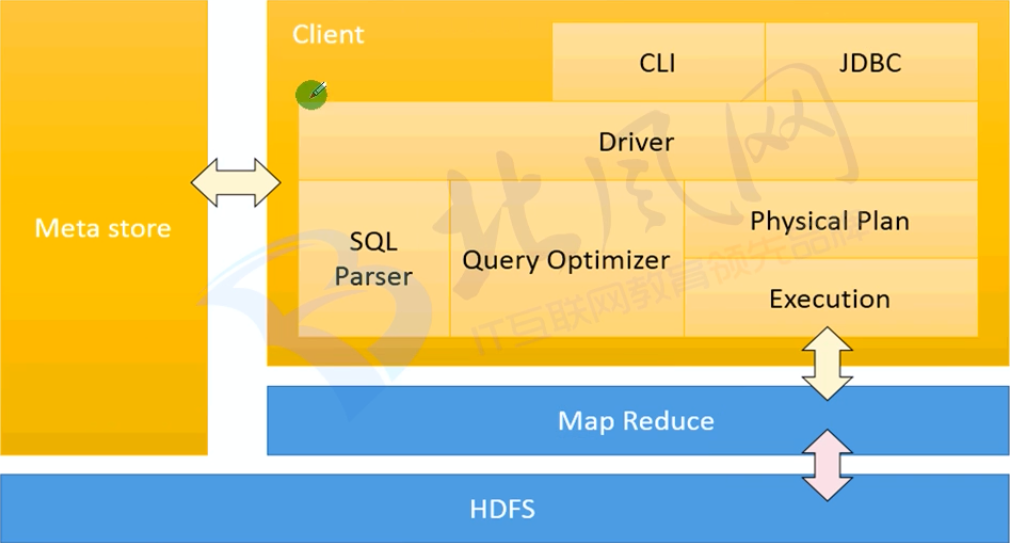
三、Spark SQL对比Hive
- Spark SQL实际上不能完全替代Hive,只是替代了Hive中的查询引擎,针对Hive数据仓库中的表进行SQL查询
- 由于Hive查询底层基于MapReduce决定了Hive的查询慢
- Hive中的一部分高级特性在Spark SQL 中未得到支持
- Spark SQL除了Hive还支持其他数据源(json parquet jdbc等),同时支持直接针对HDFS执行SQL查询
Spark是什么的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- (资源整理)带你入门Spark
一.Spark简介: 以下是百度百科对Spark的介绍: Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方 ...
- Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系.他只是一个运算框架,和storm一样只做运算,不做存储. Spark ...
- (一)Spark简介-Java&Python版Spark
Spark简介 视频教程: 1.优酷 2.YouTube 简介: Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架.Spark在2013年6月进入Apache成为孵化项目,8个月 ...
随机推荐
- Zabbix监控 windows agent安装配置
下载Windows的zabbix客户端 载地址:http://www.zabbix.com/download.php 选择windows版本的agent下载 从官方下载Zabbix Agent后,压缩 ...
- [转]Ubuntu 配置 Android 开发 环境
转自:http://blog.csdn.net/shulianghan/article/details/20855541 1. 安装 Android Studio (1) 下载Android Stud ...
- IT人们给个建议
开篇声明:我本身是中学老师,师范类大学计算机专业毕业,现在马上研究生学位就要拿上了,平时在学校搞网络维护什么的,事少,业余时间充足,也不想拘泥于做老师拿点工资,觉得白学计算机了,所以也搞些业余开发,如 ...
- Python爬虫利器之Beautiful Soup,Requests,正则的用法(转)
https://cuiqingcai.com/1319.html https://cuiqingcai.com/2556.html https://cuiqingcai.com/977.html
- Android开发学习之TabView选项卡具体解释 -- 基于Android4.4
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/he90227/article/details/24474197 直接上代码 -- 基于Android ...
- 【转】Android手机分辨率基础知识(DPI,DIP计算)
1.术语和概念 术语 说明 备注 Screen size(屏幕尺寸) 指的是手机实际的物理尺寸,比如常用的2.8英寸,3.2英寸,3.5英寸,3.7英寸 摩托罗拉milestone手机是3.7英寸 A ...
- PHP设计模式——工厂模式
<?php /** * 工厂模式 * 提供获取某个对象的新实例的一个接口,同时使调用代码避免确定实际实例化基类的步骤. * * 工厂类用于创建不同类的实例,并将其返回. */ /** * 服务端 ...
- Hashtable详细介绍(源码解析)和使用示例
第1部分 Hashtable介绍 Hashtable 简介 和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射. Hashtable 继承于Dic ...
- oracle 基础知识(四)常用函数
SQL中的单记录函数 .ASCII 返回与指定的字符对应的十进制数; SQL') zero,ascii(' ') space from dual; A A ZERO SPACE --------- - ...
- 数据库优先生成EF CRUD演示
①准备我们的数据库: Northwind ②新建 实体数据模型,由数据库优先创建 ③创建控制器,这里我们只针对了Customers这张表做演示,实际会复杂的多 注:你可以把上面两步合成一步来写,创建控 ...