(数据科学学习手札21)sklearn.datasets常用功能详解
作为Python中经典的机器学习模块,sklearn围绕着机器学习提供了很多可直接调用的机器学习算法以及很多经典的数据集,本文就对sklearn中专门用来得到已有或自定义数据集的datasets模块进行详细介绍;
datasets中的数据集分为很多种,本文介绍几类常用的数据集生成方法,本文总结的所有内容你都可以在sklearn的官网:
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
中找到对应的更加详细的英文版解释;
1 自带的经典小数据集
1.1 波士顿房价数据(适用于回归任务)
这个数据集包含了506处波士顿不同地理位置的房产的房价数据(因变量),和与之对应的包含房屋以及房屋周围的详细信息(自变量),其中包含城镇犯罪率、一氧化氮浓度、住宅平均房间数、到中心区域的加权距离以及自住房平均房价等13个维度的数据,因此,波士顿房价数据集能够应用到回归问题上,这里使用load_boston(return_X_y=False)方法来导出数据,其中参数return_X_y控制输出数据的结构,若选为True,则将因变量和自变量独立导出;
from sklearn import datasets '''清空sklearn环境下所有数据'''
datasets.clear_data_home() '''载入波士顿房价数据''' X,y = datasets.load_boston(return_X_y=True) '''获取自变量数据的形状''' print(X.shape) '''获取因变量数据的形状''' print(y.shape)

自变量X:

因变量y:
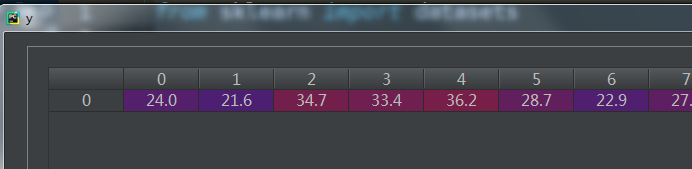
1.2 威斯康辛州乳腺癌数据(适用于分类问题)
这个数据集包含了威斯康辛州记录的569个病人的乳腺癌恶性/良性(1/0)类别型数据(训练目标),以及与之对应的30个维度的生理指标数据;因此这是个非常标准的二类判别数据集,在这里使用load_breast_cancer(return_X_y)来导出数据:
from sklearn import datasets '''载入威斯康辛州乳腺癌数据''' X,y = datasets.load_breast_cancer(return_X_y=True) '''获取自变量数据的形状''' print(X.shape) '''获取因变量数据的形状''' print(y.shape)

自变量X:

因变量y:
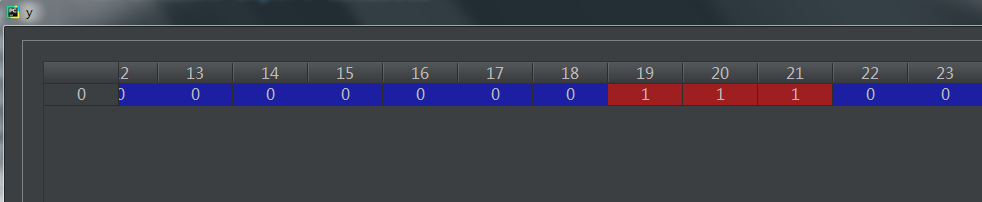
1.3 糖尿病数据(适用于回归任务)
这是一个糖尿病的数据集,主要包括442行数据,10个属性值,分别是:Age(年龄)、性别(Sex)、Body mass index(体质指数)、Average Blood Pressure(平均血压)、S1~S6一年后疾病级数指标。Target为一年后患疾病的定量指标,因此适合与回归任务;这里使用load_diabetes(return_X_y)来导出数据:
from sklearn import datasets '''载入糖尿病数据''' X,y = datasets.load_diabetes(return_X_y=True) '''获取自变量数据的形状''' print(X.shape) '''获取因变量数据的形状''' print(y.shape)
自变量X:
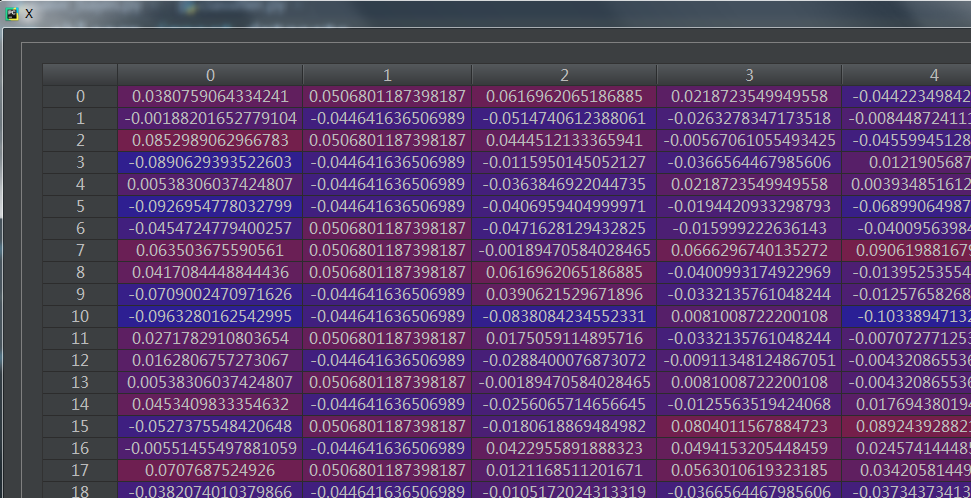
因变量y:

1.4 手写数字数据集(适用于分类任务)
这个数据集是结构化数据的经典数据,共有1797个样本,每个样本有64的元素,对应到一个8x8像素点组成的矩阵,每一个值是其灰度值,我们都知道图片在计算机的底层实际是矩阵,每个位置对应一个像素点,有二值图,灰度图,1600万色图等类型,在这个样本中对应的是灰度图,控制每一个像素的黑白浓淡,所以每个样本还原到矩阵后代表一个手写体数字,这与我们之前接触的数据有很大区别;在这里我们使用load_digits(return_X_y)来导出数据:
from sklearn import datasets '''载入手写数字数据''' data,target = datasets.load_digits(return_X_y=True) print(data.shape) print(target.shape)

这里我们利用matshow()来绘制这种矩阵形式的数据示意图:
import matplotlib.pyplot as plt
import numpy as np '''绘制数字0'''
num = np.array(data[0]).reshape((8,8))
plt.matshow(num)
print(target[0]) '''绘制数字5'''
num = np.array(data[15]).reshape((8,8))
plt.matshow(num)
print(target[15]) '''绘制数字9'''
num = np.array(data[9]).reshape((8,8))
plt.matshow(num)
print(target[9])

1.5 Fisher的鸢尾花数据(适用于分类问题)
著名的统计学家Fisher在研究判别分析问题时收集了关于鸢尾花的一些数据,这是个非常经典的数据集,datasets中自然也带有这个数据集;这个数据集包含了150个鸢尾花样本,对应3种鸢尾花,各50个样本(target),以及它们各自对应的4种关于花外形的数据(自变量);这里我们使用load_iris(return_X_y)来导出数据:
from sklearn import datasets '''载入Fisher的鸢尾花数据''' data,target = datasets.load_iris(return_X_y=True) '''显示自变量的形状'''
print(data.shape) '''显示训练目标的形状'''
print(target.shape)
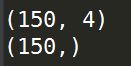
自变量:
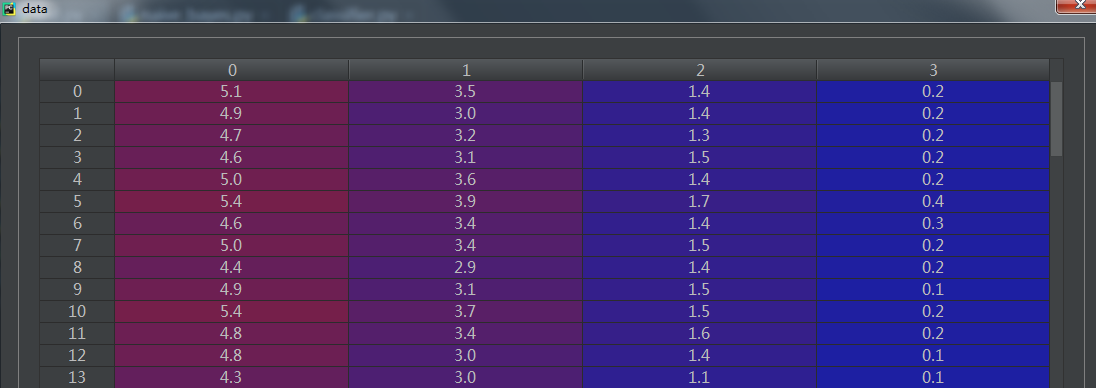
训练目标:

1.6 红酒数据(适用于分类问题)
这是一个共178个样本,代表了红酒的三个档次(分别有59,71,48个样本),以及与之对应的13维的属性数据,非常适合用来练习各种分类算法;在这里我们使用load_wine(return_X_y)来导出数据:
from sklearn import datasets '''载入wine数据''' data,target = datasets.load_wine(return_X_y=True) '''显示自变量的形状'''
print(data.shape) '''显示训练目标的形状'''
print(target.shape)

2 自定义数据集
前面我们介绍了几种datasets自带的经典数据集,但有些时候我们需要自定义生成服从某些分布或者某些形状的数据集,而datasets中就提供了这样的一些方法:
2.1 产生服从正态分布的聚类用数据
datasets.make_blobs(n_samples=100, n_features=2, centers=3, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None),其中:
n_samples:控制随机样本点的个数
n_features:控制产生样本点的维度(对应n维正态分布)
centers:控制产生的聚类簇的个数
from sklearn import datasets
import matplotlib.pyplot as plt X,y = datasets.make_blobs(n_samples=1000, n_features=2, centers=4, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None) plt.scatter(X[:,0],X[:,1],c=y,s=8)
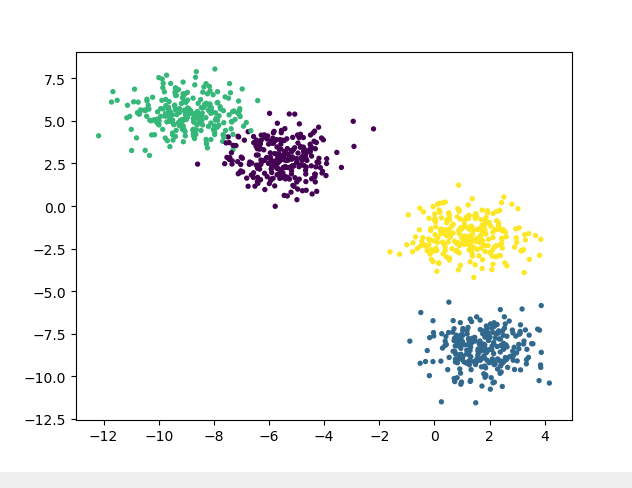
2.2 产生同心圆样本点
datasets.make_circles(n_samples=100, shuffle=True, noise=0.04, random_state=None, factor=0.8)
n_samples:控制样本点总数
noise:控制属于同一个圈的样本点附加的漂移程度
factor:控制内外圈的接近程度,越大越接近,上限为1
from sklearn import datasets
import matplotlib.pyplot as plt X,y = datasets.make_circles(n_samples=10000, shuffle=True, noise=0.04, random_state=None, factor=0.8) plt.scatter(X[:,0],X[:,1],c=y,s=8)

2.3 生成模拟分类数据集
datasets.make_classification(n_samples=100, n_features=20, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None)
n_samples:控制生成的样本点的个数
n_features:控制与类别有关的自变量的维数
n_classes:控制生成的分类数据类别的数量
from sklearn import datasets X,y = datasets.make_classification(n_samples=100, n_features=20, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None) print(X.shape)
print(y.shape)
set(y)

2.4 生成太极型非凸集样本点
datasets.make_moons(n_samples,shuffle,noise,random_state)
from sklearn import datasets
import matplotlib.pyplot as plt X,y = datasets.make_moons(n_samples=1000, shuffle=True, noise=0.05, random_state=None) plt.scatter(X[:,0],X[:,1],c=y,s=8)
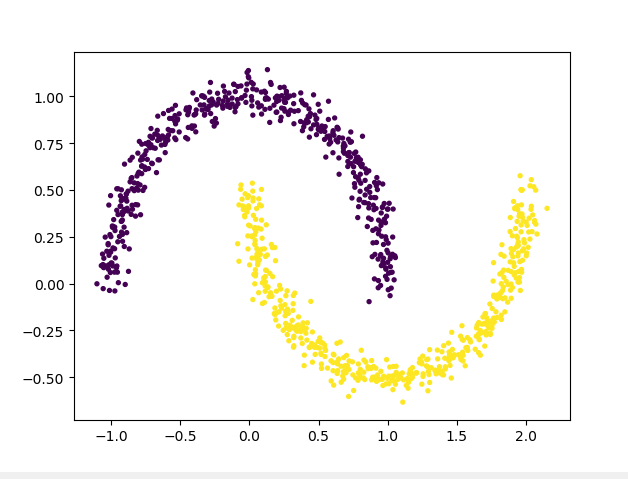
以上就是sklearn.datasets中基本的数据集方法,如有笔误之处望指出。
(数据科学学习手札21)sklearn.datasets常用功能详解的更多相关文章
- (数据科学学习手札23)决策树分类原理详解&Python与R实现
作为机器学习中可解释性非常好的一种算法,决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方 ...
- (数据科学学习手札34)多层感知机原理详解&Python与R实现
一.简介 机器学习分为很多个领域,其中的连接主义指的就是以神经元(neuron)为基本结构的各式各样的神经网络,规范的定义是:由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
随机推荐
- June 05th 2017 Week 23rd Monday
No great discovery was ever made without a bold guess. 没有大胆的猜测就没有伟大的发现. I've read this sentence just ...
- 到底哪种类型的错误信息会阻止business transaction的保存
当试图在CRM WebUI保存一个business transaction比如Opportunity时,可能会遇到各种各样的错误消息.有的错误消息会阻止Business transaction被sav ...
- Jmeter入门16 数据构造之随机数Random Variable & __Random函数
接口测试有时参数使用随机数构造.jmeter添加随机数两种方式 1 添加配置 > Random Variable 2 __Random函数 ${__Random(1000,9999) ...
- BZOJ3874:[AHOI2014&JSOI2014]宅男计划(爬山法)
Description [故事背景] 自从迷上了拼图,JYY就变成了个彻底的宅男.为了解决温饱问题,JYY 不得不依靠叫外卖来维持生计. [问题描述] 外卖店一共有N种食物,分别有1到N编号.第i种 ...
- python 3+djanjo 2.0.7简单学习(五)--Django投票应用
1.编写一个简单的表单 编写的投票详细页面的模板 ("votes/detail.html") ,让它包含一个 HTML <form> 元素: <!DOCTYPE ...
- 【luogu P3366 最小生成树】 模板
这里是kruskal做法 当然prim也可以,至于prim和kruskal的比较: Prim在稠密图中比Kruskal优,Kruskal在稀疏图中比Prim优. #include<bits/st ...
- 10474 - Where is the Marble?(模拟)
传送门: UVa10474 - Where is the Marble? Raju and Meena love to play with Marbles. They have got a lot o ...
- Git错误
$ rm -rf .git $ git config --global core.autocrlf false $git init $git add . ---------------------- ...
- oracle聚簇表的理解 (转自:https://blog.csdn.net/gumengkai/article/details/51009345 )
Oracle支持两种类型的聚簇:索引聚簇和哈希聚簇 一.索引聚簇表的原理 聚簇:如果一些表有一些共同的列,则将这样一组表存储在相同的数据块中 聚簇还表示把相关的数据存储在同一个块上.利用聚簇,一个块可 ...
- Oracle闪回恢复误删除的表、存储过程、包、函数...
在日常的数据库开发过程汇总难免会出现一些误删除的动作, 对于一些误删的操作我们可以通过oracle提供的闪回机制恢复误删数据, 从而避免出现较大的生产事故. 下面是本人平时工作中积累的一些常用的操作, ...