集群hadoop ubuntu版
搭建ubuntu版hadoop集群
用到的工具:VMware、hadoop-2.7.2.tar、jdk-8u65-linux-x64.tar、ubuntu-16.04-desktop-amd64.iso
1、 在VMware上安装ubuntu-16.04-desktop-amd64.iso
单击“创建虚拟机”è选择“典型(推荐安装)”è单击“下一步”




è点击完成
修改/etc/hostname
vim hostname
保存退出

修改etc/hosts

127.0.0.1 localhost
192.168.1.100 s100
192.168.1.101 s101
192.168.1.102 s102
192.168.1.103 s103
192.168.1.104 s104
192.168.1.105 s105
配置NAT网络
查看window10下的ip地址及网关

配置/etc/network/interfaces
#interfaces(5) file used by ifup(8) and ifdown(8)
#The loopback network interface
auto lo
iface lo inet loopback #iface eth0 inet static
iface eth0 inet static
address 192.168.1.105
netmask 255.255.255.0
gateway 192.168.1.2
dns-nameservers 192.168.1.2
auto eth0
也可以通过图形化界面配置

配置好后执行ping www.baidu.com看网络是不是已经起作用
当网络通了之后,要想客户机宿主机之前进行Ping通,只需要做以下配置
修改宿主机c:\windows\system32\drivers\etc\hosts文件
文件内容
127.0.0.1 localhost
192.168.1.100 s100
192.168.1.101 s101
192.168.1.102 s102
192.168.1.103 s103
192.168.1.104 s104
192.168.1.105 s105
安装ubuntu 163 14.04 源
$>cd /etc/apt/
$>gedit sources.list
切记在配置之前做好备份
deb http://mirrors.163.com/ubuntu/ trusty main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-security main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-updates main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-proposed main restricted universe multiverse
deb http://mirrors.163.com/ubuntu/ trusty-backports main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-security main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-updates main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-proposed main restricted universe multiverse
deb-src http://mirrors.163.com/ubuntu/ trusty-backports main restricted universe multiverse
更新
$>apt-get update
在家根目录下新建soft文件夹 mkdir soft
但是建立完成后,该文件属于root用户,修改权限 chown enmoedu:enmoedu soft/
安装共享文件夹

将该文件放到桌面,右键,点击“Extract here”

切换到enmoedu用户的家目录,cd /Desktop/vmware-tools-distrib

执行./vmware-install.pl文件
Enter键执行
安装完成
拷贝hadoop-2.7.2.tar、jdk-8u65-linux-x64.tar到enmoedu家目录下的/Downloads
$> sudo cp hadoop-2.7.2.tar.gz jdk-8u65-linux-x64.tar.gz ~/Downloads/
分别解压hadoop-2.7.2.tar、jdk-8u65-linux-x64.tar到当前目录
$> tar -zxvf hadoop-2.7.2.tar.gz
$>tar -zxvf jdk-8u65-linux-x64.tar.gz
$>cp -r hadoop-2.7.2 /soft
$>cp -r jdk1.8.0_65/ /soft
建立链接文件
$>ln -s hadoop-2.7.2/ hadoop
$>ln -s jdk1.8.0_65/ jdk
$>ls -ll

配置环境变量
$>vim /etc/environment
JAVA_HOME=/soft/jdk
HADOOP_HOME=/soft/hadoop
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/soft/jdk/bin:/soft/hadoop/bin:/soft/hadoop/sbin"
让环境变量生效
$>source environment
检验安装是否成功
$>java –version

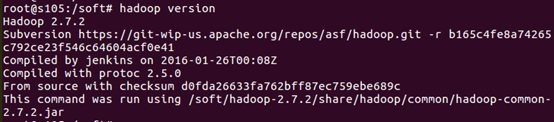
$>hadoop version
配置/soft/hadoop/etc/hadoop/ 下的配置文件
[core-site.xml]
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s100/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/enmoedu/hadoop</value>
</property>
</configuration>
[hdfs-site.xml]
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s104:50090</value>
<description>
The secondary namenode http server address and port.
</description>
</property>
</configuration>
[mapred-site.xml]
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[yarn-site.xml]
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s100</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置ssh无密码登录
安装ssh
$>sudo apt-get install ssh
生成秘钥对
在enmoedu家目录下执行
$>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
导入公钥数据到授权库中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

测试localhost成功后,将master节点上的供钥拷贝到授权库中
其中root一样执行即可
$>ssh localhost

从master节点上测试是否成功。

修改slaves文件
[/soft/hadoop/etc/hadoop/slaves]
s101
s102
s103
s105
其余机器,通过克隆,修改hostname和网络配置即可
塔建完成后
格式化hdfs文件系统
$>hadoop namenode –format
启动所有进程
start-all.sh
最终结果:

自定义脚本xsync(在集群中分发文件)
[/usr/local/bin]
循环复制文件到所有节点的相同目录下。
[usr/local/bin/xsync]
#!/bin/bash
pcount=$#
if (( pcount<1 ));then
echo no args;
exit;
fi
p1=$1;
fname=`basename $p1`
#echo $fname=$fname; pdir=`cd -P $(dirname $p1) ; pwd`
#echo pdir=$pdir cuser=`whoami`
for (( host=101;host<106;host=host+1 )); do
echo ------------s$host----------------
rsync -rvl $pdir/$fname $cuser@s$host:$pdir
done
测试
xsync hello.txt


自定义脚本xcall(在所有主机上执行相同的命令)
[usr/local/bin]
#!/bin/bash
pcount=$#
if (( pcount<1 ));then
echo no args;
exit;
fi
echo -----------localhost----------------
$@
for (( host=101;host<106;host=host+1 )); do
echo ------------s$host-------------
ssh s$host $@ done
测试 xcall rm –rf hello.txt


集群搭建完成后,测试次运行以下命令
touch a.txt
gedit a.txt
hadoop fs -mkdir -p /user/enmoedu/data
hadoop fs -put a.txt /user/enmoedu/data
hadoop fs -lsr /

也可以进入浏览器查看


集群hadoop ubuntu版的更多相关文章
- CentOS7安装CDH 第七章:CDH集群Hadoop的HA配置
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- Linux下搭建mpi集群(ubuntu下用虚拟机测试)
一 建立SSH连接(无密码登陆) 1 SSH连接的简单介绍 SSH 为 Secure Shell 的缩写,中文翻译为安全外壳协议,建立在应用层,是一种远程连接安全协议.传统的telnet,pop,ft ...
- HBASE分布式集群搭建(ubuntu 16.04)
1.hbase是依赖Hadoop运行的,因此先确保自己已搭建好Hadoop集群环境 没安装的可以参考这里:https://www.cnblogs.com/chaofan-/p/9740408.html ...
- 三台linux集群hadoop,在此上面运行hive
---恢复内容开始--- 一,准备 先有三台linux,对hadoop集群的搭建. eddy01:开启一个hdfs的老大namenode,yarn的老大ResourceManager其中进程包括(No ...
- 集群搭建_02_集群多机版安装 HDFS HA+Federation-YARN
1.配置hosts 至少四个节点(机器) 每个节点的hosts文件都要配置这些 10.10.64.226 SY-0217 10.10.64.234 SY-0225 10.10.64.235 SY-02 ...
- Hadoop-HA 搭建高可用集群Hadoop Zookeeper
Hadoop Zookeeper 搭建(一) 一.准备工作 VMWARE虚拟机 CentOS 7 系统 虚拟机1:master 虚拟机2:node1 虚拟机3:node2 时间同步 ntpdate n ...
- Kafka集群配置---Windows版
Kafka是一种高吞吐量的分布式发布订阅的消息队列系统,Kafka对消息进行保存时是通过tipic进行分组的.今天我们仅实现Kafka集群的配置.理论的抽空在聊 前言 最近研究kafka,发现网上很多 ...
- 利用shell脚本[带注释的]部署单节点多实例es集群(docker版)
文章目录 目录结构 install_docker_es.sh elasticsearch.yml.template 没事写写shell[我自己都不信,如果不是因为工作需要,我才不要写shell],努力 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
随机推荐
- Maven 运行启动时****找不到符号*com.xxx.user.java
Maven 运行启动时****找不到符号*com.xxx.user.java maven项目更改后没有安装 (install) 重新安装解决问题!
- mysql-新增表前判断同名表是否存在
新增多个表时,如果有同名表会报错,导致其中一个表不能正确创建,此时可以用以下语句进行判断: DROP TABLE IF EXISTS USER; --判断表是否存在,如果存在就删除! CREATE T ...
- Sonarqube中文插件-Linux[20180105]
前言 上次安装了Sonarqube英文版使用起来不方便,这次为Sonarqube安装中文插件. 前期准备: 软件下载: https://github.com/SonarQubeComm ...
- 初学Splunk
splunk简介 https://www.splunk.com/zh-hans_cn/download.html splunk 简体中文版手册 http://docs.splunk.com/Docum ...
- 利用nginx使ftp可以通过http访问
./nginx 启动服务./nginx -s stop 关闭服务./nginx -s reload 重新加载配置文件 搭建nginx映射ftp服务:打开nginx的配置文件nginx.conf(位于n ...
- python3 练习题100例 (二十一)打印一定范围内的水仙花数
题目内容: 水仙花数是指一个n位数 (n≥3),它的每个位上的数字的n次幂之和等于它本身. 例如:153是一个“水仙花数”,因为 153 是个 3位数,而1**3+5**3+3**3==153. 输入 ...
- MariaDB数据库服务
一.初始化mariaDB服务程序: yum install mariadb mariadb-server //安装mariaDB systemctl start mariadb ...
- python, pycharm, virtualenv 的使用
创建虚拟环境,一次安装多个库 pip freeze > requirements.txt (库的名字都在里面) 产生requirements.txt文件 在另一个环境下使用 pip instal ...
- 设计模式——模版方法模式详解(论沉迷LOL对学生的危害)
. 实例介绍 在本例中,我们使用一个常见的场景,我们每个人都上了很多年学,中学大学硕士,有的人天生就是个天才,中学毕业就会微积分,因此得了诺贝尔数学奖:也有的人在大学里学了很多东西,过得很充实很满意 ...
- Dubbo原理及配置
技术交流群:233513714 Dubbo的背景 随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进 ...