吴恩达《Machine Learning Yearning》总结(31-40章)
31.解读学习曲线:其他情况
下图反映了高方差,通过增加数据集可以改善。

下图反映了高偏差和高方差,需要找到一种方法来同时减少方差和偏差。
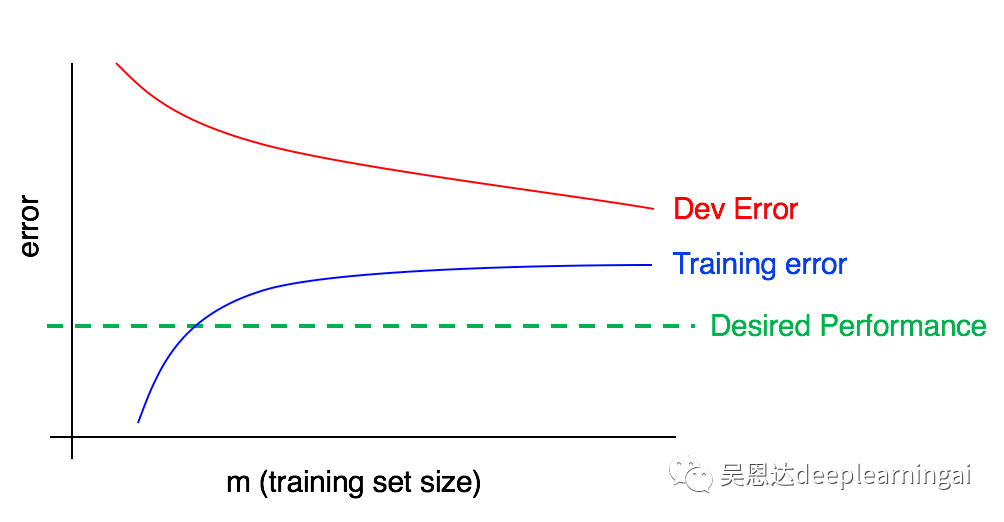
32.绘制学习曲线
情况:当数据集非常小时,比如只有100个样本,这时绘制出来的学习曲线可能噪声非常大。
解决方法:
(1)与其只使用10个样本训练单个模型,不如从你原来的100个样本中进行随机有放回抽样,选择几批(比如3-10)不同的10个样本进行组合。在这些数据上训练不同的模型,并计算每个模型的训练和开发错误,最终计算和绘制平均训练集误差和平均开发集误差。
(2)如果你的训练集偏向于一个类,或许它有许多类,那么选择一个“平衡”子集,而不是从100个样本中随机抽取10个训练样本。例如,你可以确保这些样本中的2/10是正样本,8/10是负样本。更常见的做法是,确保每个类的样本比例尽可能的接近原始训练集的总体比例。
33.为何与人类表现水平进行对比
对于人类擅长的事情,例如图像识别,语音识别等。
(1)易于从认为标签中获取数据。
(2)基于人类直接进行误差分析。
(3)使用人类表现水平来估计最优错误率,并设置可达到的“期望错误率”。
对于人类也不擅长的事情,例如推进书籍电影,股票市场预测。
(1)获取标签数据很难。
(2)人类的直觉难以依靠。
(3)最优错误率和合理的期望错误率难以估计。
34.如何定义人类表现水平
应该用人类的最高水平去衡量人类的水平(即期望误差率)。举例:医学图像疾病诊断,普通人错误率20%,医生10%,专家5%,专家讨论小左2%,此时人类水平应该为2%。
35.超越人类表现水平
举例:语音识别人类错误率是10%,而你的算法错误率是8%,此时已经超越人类,但这时某个子集(即某些方面,如转录语音很快时)人类仍然优于算法,在这些方面仍然可以用前面提到的一些技术进行提升。在语音转录上,仍然可以(1)从输出质量比你的算法高的人那儿获取转录数据。(2)你可以利用人类的直觉来理解,为什么你的系统没能欧识别这些数据,而人类做到了。(3)你可以使用该子集上的人类表现作为期望表现目标。
吴恩达《Machine Learning Yearning》总结(31-40章)的更多相关文章
- 吴恩达Machine Learning 第一周课堂笔记
1.Introduction 1.1 Example - Database mining Large datasets from growth of automation/ ...
- 吴恩达Machine Learning学习笔记(一)
机器学习的定义 A computer program is said to learn from experience E with respect to some class of tasks T ...
- 吴恩达Machine Learning学习笔记(四)--BP神经网络
解决复杂非线性问题 BP神经网络 模型表示 theta->weights sigmoid->activation function input_layer->hidden_layer ...
- 吴恩达Machine Learning学习笔记(三)--逻辑回归+正则化
分类任务 原始方法:通过将线性回归的输出映射到0-1,设定阈值来实现分类任务 改进方法:原始方法的效果在实际应用中表现不好,因为分类任务通常不是线性函数,因此提出了逻辑回归 逻辑回归 假设表示--引入 ...
- 吴恩达Machine Learning学习笔记(二)--多变量线性回归
回归任务 多变量线性回归 公式 h为假设,theta为模型参数(代表了特征的权重),x为特征的值 参数更新 梯度下降算法 影响梯度下降算法的因素 (1)加速梯度下降:通过让每一个输入值大致在相同的范围 ...
- 吴恩达 Deep learning 第二周 神经网络基础
逻辑回归代价函数(损失函数)的几个求导特性 1.对于sigmoid函数 2.对于以下函数 3.线性回归与逻辑回归的神经网络图表示 利用Numpy向量化运算与for循环运算的显著差距 import nu ...
- 吴恩达 Deep learning 第一周 深度学习概论
知识点 1. Relu(Rectified Liner Uints 整流线性单元)激活函数:max(0,z) 神经网络中常用ReLU激活函数,与机器学习课程里面提到的sigmoid激活函数相比有以下优 ...
- Github | 吴恩达新书《Machine Learning Yearning》完整中文版开源
最近开源了周志华老师的西瓜书<机器学习>纯手推笔记: 博士笔记 | 周志华<机器学习>手推笔记第一章思维导图 [博士笔记 | 周志华<机器学习>手推笔记第二章&qu ...
- 我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)【中英双语】
我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)[中英双语] 视频地址:https://www.bilibili.com/video/av9912938/ t ...
- Coursera课程《Machine Learning》吴恩达课堂笔记
强烈安利吴恩达老师的<Machine Learning>课程,讲得非常好懂,基本上算是无基础就可以学习的课程. 课程地址 强烈建议在线学习,而不是把视频下载下来看.视频中间可能会有一些问题 ...
随机推荐
- 数组中 reduce累计运算
let arr = [1,2,3,4]; let sum = (a, b) => a + b; arr.reduce(sum, 0); 最后输出10
- 变量声明和定义的关系------c++ primer
为了允许把程序分成多个逻辑部分来编写,c++语言支持分离式编译机制 为了支持分离式编译,c++语言把声明和定义区分开来.声明(declaration)使得名字为程序所知,一个文件如果想使用别处定义的名 ...
- Mybatis 延迟加载策略
延迟加载: 就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据.延迟加载也称懒加载. 好处: 先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速 ...
- Mybatis中的连接池
Mybatis中DataSource的存取 MyBatis是通过工厂模式来创建数据源DataSource对象的,MyBatis定义了抽象的工厂接口:org.apache.ibatis.datasour ...
- [Swift实际操作]九、完整实例-(1)在iTunesConnect网站中创建产品
本文将通过一个实例项目,演示移动应用开发的所有步骤.首先要做的是打开浏览器,并进入[iTunesConnect网站],需要通过它创建一款自己的应用. 在iTunesConnect的登录页面中,输入自己 ...
- [Swift]八大排序算法(二):快速排序
排序分为内部排序和外部排序. 内部排序:是指待排序列完全存放在内存中所进行的排序过程,适合不太大的元素序列. 外部排序:指的是大文件的排序,即待排序的记录存储在外存储器上,待排序的文件无法一次装入内存 ...
- Spring框架的核心模块的作用
Spring框架由7个定义良好的模块(组件)组成,各个模块可以独立存在,也可以联合使用. (1)Spring Core:核心容器提供了Spring的基本功能.核心容器的核心功能是用Ioc容器来管理类的 ...
- Liunux疑问
Liunux疑问 其中的各种软件的安装有模糊的点,待解决 待解决 待解决 待解决 ... ...
- 【离散数学】 SDUT OJ 偏序关系
偏序关系 Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Problem Description 给定有限集上二元关系的关系矩 ...
- django form tips
1.form将获取的参数传递到field 2.field中的函数 to_python 数据库到python中变量 get_prep_value python变量到数据库 validate 验证,也可以 ...