python 数据结构简介
栈(stack)
定义:
数据集合,只能在一端(首尾)进行删除和插入的列表。
特点:
后进先出(LIFO)
典型作用:
括号匹配:左括号进栈,右括号跟左括号对应则出栈,例如:(({{[]}}))匹配
队列(queue)
定义:
线性表,只能在表的一端进行插入,在另一端进行删除操作。
特点:
先进先出(FIFO)
栈和队列的比较:
1遍历速度方向:栈只能从头部取数据,如果要取第一个数据则需要遍历整个栈,队列则可以从头部或尾部遍历,但不能同时遍历
2遍历空间:栈遍历时需要另行开辟临时空间,保持数据在遍历前的一致性,队列则是基于地址指针进行遍历,无需临时空间则可保持一致性
3两者均是线性表,即数据元素之间的关系相同,但是由因为对插入和删除的限定条件,则成为有限定的线性表。
下面时对队列和栈的一个对比应用:迷宫(maze)
假设有这么一个迷宫地图:
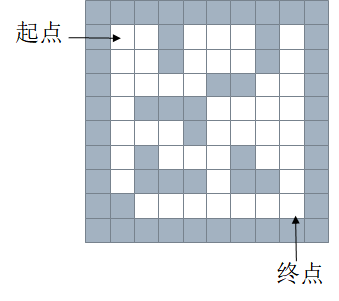
嘉定灰色为0,白色为1,用一个列表来表示为:
maze = [
[1,1,1,1,1,1,1,1,1,1],
[1,0,0,1,0,0,0,1,0,1],
[1,0,0,1,0,0,0,1,0,1],
[1,0,0,0,0,1,1,0,0,1],
[1,0,1,1,1,0,0,0,0,1],
[1,0,0,0,1,0,0,0,0,1],
[1,0,1,0,0,0,1,0,0,1],
[1,0,1,1,1,0,1,1,0,1],
[1,1,0,0,0,0,0,0,0,1],
[1,1,1,1,1,1,1,1,1,1]
]
首先使用栈的方法,指定一个方向优先级,比如下,右,左,上的顺序,向栈中不断push数据,直到到达终点的位置为止。
定义四个方向
dirs = [lambda x, y: (x + 1, y),
lambda x, y: (x, y + 1),
lambda x, y: (x - 1, y),
lambda x, y: (x, y - 1),
]
主程序:
def map_path(x1,y1,x2,y2):
stack=[]
stack.append((x1,y1))#添加起始点
while len(stack)> 0: #如果栈中有数据的话
curNode=stack[-1] #取最外面一个栈值
if curNode[0]==x2 and curNode[1]==y2: #如果到达终点
print('found path')
for p in stack:
print(p)
return True
for dir in dirs: #循环四个方向,注意优先级
nextNode=dir(curNode[0],curNode[1]) #定义下一个点
if maze[nextNode[0]][nextNode[1]]==0: #如果下一个点可以走通
stack.append(nextNode) #添加进栈中
maze[nextNode[0]][nextNode[1]] = -1 #改变值使不重复添加
break
else:
stack.pop()
print('found failed')
return False map_path(1,1,8,8)
最后的结果输出为:
found path
(1, 1)
(2, 1)
(3, 1)
(4, 1)
(5, 1)
(5, 2)
(5, 3)
(6, 3)
(6, 4)
(6, 5)
(7, 5)
(8, 5)
(8, 6)
(8, 7)
(8, 8)
输出结果
在这里注意到如果更改dir的顺序,即可调整走出迷宫的优先级,路径就会不一样,我在这里只能根据相对位置(左下方)进行一个寻位的排序。如果有大神知道如何在此基础上能找到绝对的最有路径,还望赐教。
讲完了栈,下面使用队列来实现同样的功能:
def print_p(path):
curNode = path[-1] #包含了所有的路径
realpath=[] #只记录走到终点的真实路径
while curNode[2]!=-1: #只要不是第一个
realpath.append(curNode[0:2])
curNode=path[curNode[2]] #继续找下一个
realpath.append(curNode[0:2]) #拿到最后一个源头
realpath.reverse()
print(realpath)
def map_path(x1,y1,x2,y2):
queue = deque()
path=[] #创建列表记录路径
queue.append((x1,y1,-1)) #-1是设置用于路径来源搜搜索
while len(queue)>0:
curNode=queue.popleft()
path.append(curNode)
if curNode[0]==x2 and curNode[1]==y2:
print_p(path)
return True
for dir in dirs:
nextNode = dir(curNode[0],curNode[1])
if maze[nextNode[0]][nextNode[1]]==0: #如果找到有空
queue.append((*nextNode,len(path)-1)) #len用于记录产生这个新node的来源
maze[nextNode[0]][nextNode[1]] = -1 #如果没有空
print('found failed')
return False map_path(1,1,8,8)
最后结果为:
[(1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (5, 2), (5, 3), (6, 3), (6, 4), (6, 5), (7, 5), (8, 5), (8, 6), (8, 7), (8, 8)]
根据两种不同的方法实现迷宫的解答凸显了两种查找方式:深度查找和广度查找,栈体现的就是深度,一直到底然后再返回查询,队列则体现的是广度查找,把每个点的可能性都列出来,然后找到最后一个可以到达重点的,再通过反向溯源找到路径。
python 数据结构简介的更多相关文章
- python数据结构树和二叉树简介
一.树的定义 树形结构是一类重要的非线性结构.树形结构是结点之间有分支,并具有层次关系的结构.它非常类似于自然界中的树.树的递归定义:树(Tree)是n(n≥0)个结点的有限集T,T为空时称为空树,否 ...
- [Python] heapq简介
[Python] heapq简介 « Lonely Coder [Python] heapq简介 judezhan 发布于 2012 年 8 月 8 日 暂无评论 发表评论 假设你需要维护一个列表,这 ...
- [转]Redis 数据结构简介
Redis 数据结构简介 Redis可以存储键与5种不同数据结构类型之间的映射,这5种数据结构类型分别为String(字符串).List(列表).Set(集合).Hash(散列)和 Zset(有序集合 ...
- Python列表简介和遍历
一.Python3列表简介 1.1.Python列表简介 序列是Python中最基本的数据结构 序列中的每个值都有对应的位置值,称之为索引,第一个索引是0,第二个索引是1,以此类推. Python有6 ...
- python数据结构与算法
最近忙着准备各种笔试的东西,主要看什么数据结构啊,算法啦,balahbalah啊,以前一直就没看过这些,就挑了本简单的<啊哈算法>入门,不过里面的数据结构和算法都是用C语言写的,而自己对p ...
- python数据结构与算法——链表
具体的数据结构可以参考下面的这两篇博客: python 数据结构之单链表的实现: http://www.cnblogs.com/yupeng/p/3413763.html python 数据结构之双向 ...
- python数据结构之图的实现
python数据结构之图的实现,官方有一篇文章介绍,http://www.python.org/doc/essays/graphs.html 下面简要的介绍下: 比如有这么一张图: A -> B ...
- Python数据结构与算法--List和Dictionaries
Lists 当实现 list 的数据结构的时候Python 的设计者有很多的选择. 每一个选择都有可能影响着 list 操作执行的快慢. 当然他们也试图优化一些不常见的操作. 但是当权衡的时候,它们还 ...
- Python数据结构与算法--算法分析
在计算机科学中,算法分析(Analysis of algorithm)是分析执行一个给定算法需要消耗的计算资源数量(例如计算时间,存储器使用等)的过程.算法的效率或复杂度在理论上表示为一个函数.其定义 ...
随机推荐
- Linux常用命令详解(一) -- 处理目录常用命令
ls:列出目录 作用:查看linux文件夹包含的文件以及其权限(包括目录.文件夹.文件权限)和目录信息等 命令格式:ls [选项] [文件或目录] 选项或参数: ...
- 【JavaWeb】图书管理系统【总结】
感想 该项目是目前为止,我写过代码量最多的项目了.....虽然清楚是没有含金量的[跟着视频来写的],但感觉自己也在进步中...... 写的过程中,出了不少的问题.....非常多的Servlet,JSP ...
- R学习笔记:了解R的使用
R是一种区分大小写的解释性语言,只支持单行注释,注释由符号#开头,当前行出现在#之后的任何文本都会被R解释器忽略.R脚本的一次执行叫做一个会话(Session),可以通过函数quit()退出当前的会话 ...
- 利用alias在Linux下设置命令别名
alias //自定义命令="Linux命令" alias //查看当前系统里所有的自定义命令 unalias //自定义命 ...
- hihoCoder 1288 Font Size 二分
题意:给定一个宽度为和高度为的屏幕,如果字体的大小为,那么一行可以显示个字,每一页可以显示行.给出段文本段落,每段有个文字,问现在能设置的最大字体并且总的页数不能超过? 思路:如果知道字体大小很容易求 ...
- java网络编程(3)——UDP
UDP在java中主要使用DatagramSocket来实现通讯,数据一般是通过DatagramPacket来封装: 发送方只需指定接受方的地址和端口,然后通过send()方法就可以把封装在Datag ...
- java编程思想第四版第二章要点总结
1. 基本类型 基本类型 二进制位数 包装器类 boolean - Boolean byte 8 Byte char 16 Character short 16 Short int 32 Intege ...
- MySQL之pymysql模块
MySQL之pymysql模块 import pymysql #s链接数据库 conn = pymysql.connect( host = '127.0.0.1', #被连接数据库的ip地址 po ...
- 微信Token小识
在调用自定义菜单接口的时候,调用接口 https://api.weixin.qq.com/cgi-bin/menu/create?access_token=ACCESS_TOKEN返回: " ...
- MAVEN自动发布更新本地和远程仓库
1.本地仓库 的更新 mvn clean package install 2.远程 仓库 的更新 mvn clean package deploy 2.1工程文件pom.xml的设置 <bu ...