Apache Kafka简介与安装(二)
Kafka在Windows环境上安装与运行
简介
Apache kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速、可扩展、可持久化的特点。它现在是Apache旗下的一个开源系统,作为hadoop生态系统的一部分,被各种商业公司广泛应用。它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/spark流式处理引擎。
特性
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
应用场景
1.日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
2.消息系统:解耦和生产者和消费者、缓存消息等。
3.用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过
4.订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
5.运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
6.流式处理:比如spark streaming和storm
7.事件源
安装
1.安装JDK
关于JDK的安装及环境变量配置,这里就不赘述了。不清楚的可以查看JDK安装与环境变量配置。(建议下载Oracle官方发布的Java,下载地址是:http://www.java.com/download/)。
2.安装Zookeeper
先从Zookeeper官网下载Zookeeper安装包。
下载完成之后, 在D盘新建一个bigData目录(D:\bigData),用于作为安装zookeeper和kafka的目录,直接解压zookeeper安装包。注意:路径中最好不要出现空格,比如D:\Program Files,尽量别用,运行脚本时会有问题。
3.配置Zookeeper
a. 进入zookeeper的相关设置所在的文件目录,例如本文的:D:\bigData\zookeeper-3.4.10\conf,将zoo_sample.cfg重命名为zoo.cfg。打开zoo.cfg,修改配置如下:
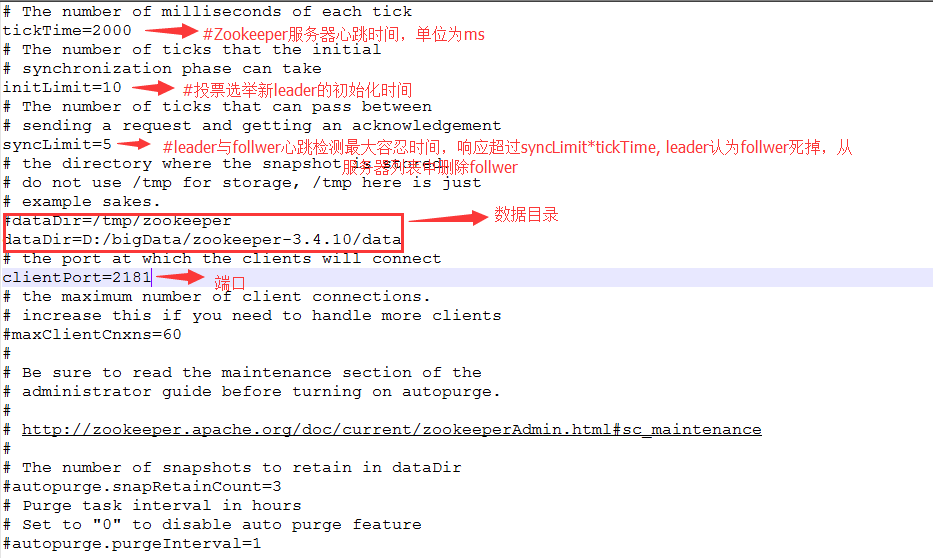
注:此处只是修改dataDir=/tmp/zookeeper的配置。
b. 配置zookeeper环境变量:
ZOOKEEPER_HOME=D:\bigData\zookeeper-3.4.10
编辑系统变量中的path变量,增加%ZOOKEEPER_HOME%\bin
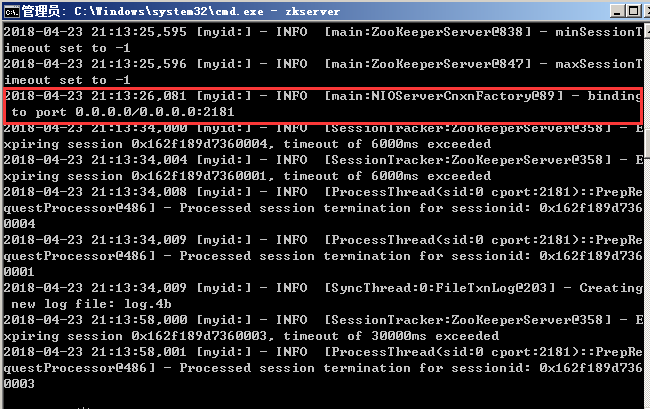
此时zookeeper已经配置完成,打开cmd,输入zkserver,运行zookeeper,运行结果如下:
4.安装Kafka
首先从Kafka官网http://kafka.apache.org/downloads下载Kafka安装包。(要下载Binary downloads这个类型,不要下载源文件,方便使用)
修改Kafka配置文件:
a. 修改config目录下的server.properties文件,修改log.dirs=D:/bigData/kafka_2.11-1.1.0/kafka-logs 。
注:在server.properties文件中,zookeeper.connect=localhost:2181代表kafka所连接的zookeeper所在的服务器IP以及端口,可根据需要更改。本文在同一台机器上使用,故不
用修改。
b.修改config目录下的log4j.properties文件,修改log4j.appender.kafkaAppender.File=D:/bigData/kafka_2.11-1.1.0/logs/server.log

其他地方暂时先不用修改,kafka会按照默认配置,在9092端口上运行,并连接zookeeper的默认端口2181。
运行Kafka
注:在启动kafka服务器前,必须确保Zookeeper实例已经在运行,因为kafka的运行是需要zookeeper这种分布式应用程序协调服务。
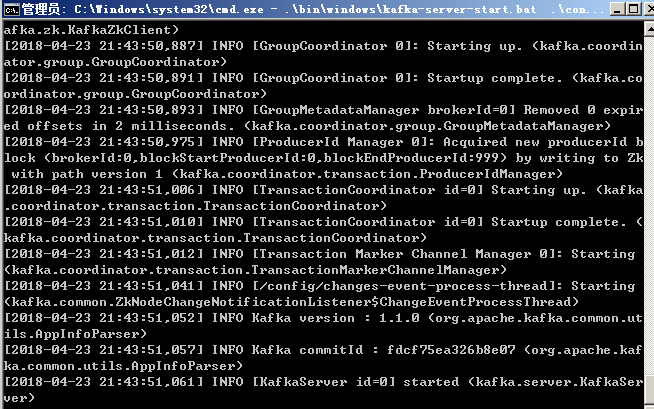
进入kafka安装目录D:\bigData\kafka_2.11-1.1.0,按下shift+鼠标右键,选择"在此处打开命令窗口",打开命令行,在命令行中输入:.\bin\windows\kafka-server-start.bat .\config\server.properties回车。正常启动界面如图:
注意:windows下kafka启动报错,找不到或无法加载主类 Files\Java\jdk1.8.0_121\lib\dt.jar;C:\Program的问题。
解决方法:
打开路径D:\bigData\kafka_2.11-1.1.0\bin\windows 下的文件kafka-run-class.bat,搜索-cp %CLASSPATH%,修改成-cp "%CLASSPATH%" 
验证kafka
创建主题(Topic)
- 创建主题,命名为"test2018",replicationfactor=1(因为只有一个kafka服务器在运行)。可根据集群中kafka服务器个数来修改replicationfactor的数量,以便提高系统容错性等。
- 在D:\bigData\kafka_2.11-1.1.0\bin\windows目录下打开新的命令行,输入命令:kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test2018回车。

此时Topic创建完成,可以在kafka安装目录查看到该topic对应的目录。
创建生产者(producer)
- 在D:\bigData\kafka_2.11-1.1.0\bin\windows目录下打开新的命令行,输入命令:kafka-console-producer.bat --broker-list localhost:9092 --topic test2018 回车。(该窗口不要关闭)
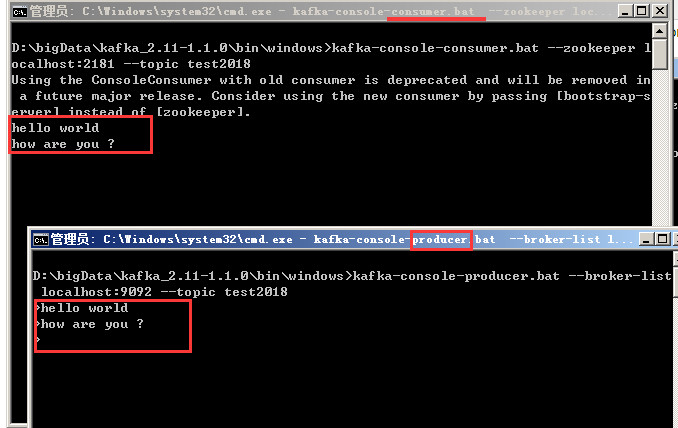
创建消费者(consumer)
- 在D:\bigData\kafka_2.11-1.1.0\bin\windows目录下打开新的命令行,输入命令:kafka-console-consumer.bat --zookeeper localhost:2181 --topic test2018回车。

现在生产者、消费者均已创建完成。在生产者命令行窗口输入信息,观察消费者命令行窗口。
以上为kafka在windows下的安装和基本的使用。
其实新版本的Kafka已经自带zookeeper。Kafka使用zookeeper作为其分布式协调框架,很好的将消息生产、消息存储、消息消费的过程结合在一起。同时借助zookeeper,kafka能够生产者、消费者和broker在内的所以组件在无状态的情况下,建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
因此,在上边步骤中,我们可以不安装zookeeper,直接修改Kafka的config目录中(D:\bigData\kafka_2.11-1.1.0\config)的zookeeper.properties文件
#dataDir=/tmp/zookeeper
dataDir=D:/bigData/kafka_2.11-1.1.0/data/zookeeper
在D:\bigData\kafka_2.11-1.1.0\bin\windows目录下打开新的命令行,输入命令:zookeeper-server-start.bat ../../config/zookeeper.properties回车。同样可以启动zookeeper。
Apache Kafka简介与安装(二)的更多相关文章
- Apache Kafka简介与安装(一)
介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计. 首先让我们看几个基本的消息系统术语: Kafka将消息以topic为单位进行归纳. 将向 ...
- Kafka简介、安装
一.Kafka简介 Kafka是一个分布式.可分区的.可复制的消息系统.几个基本的消息系统术语:1.消费者(Consumer):从消息队列(Kafka)中请求消息的客户端应用程序.2.生产者(Prod ...
- Apache Hive 简介及安装
简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能. 本质是将 SQL 转换为 MapReduce 程序. 主要用途:用来 ...
- Apache Flume简介及安装部署
概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件. Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目 ...
- 【Apache Kafka】二、Kafka安装及简单示例
(一)Apache Kafka安装 1.安装环境与前提条件 安装环境:Ubuntu16.04 前提条件: ubuntu系统下安装好jdk 1.8以上版本,正确配置环境变量 ubuntu系统下安 ...
- 【Apache Kafka】一、Kafka简介及其基本原理
对于大数据,我们要考虑的问题有很多,首先海量数据如何收集(如Flume),然后对于收集到的数据如何存储(典型的分布式文件系统HDFS.分布式数据库HBase.NoSQL数据库Redis),其次存储 ...
- Apache Kafka(二)- Kakfa 安装与启动
安装并启动Kafka 1.下载最新版Kafka(当前为kafka_2.12-2.3.0)并解压: > wget http://mirror.bit.edu.cn/apache/kafka/2.3 ...
- Windows OS上安装运行Apache Kafka教程
Windows OS上安装运行Apache Kafka教程 下面是分步指南,教你如何在Windows OS上安装运行Apache Zookeeper和Apache Kafka. 简介 本文讲述了如何在 ...
- zookeeper+kafka集群安装之二
zookeeper+kafka集群安装之二 此为上一篇文章的续篇, kafka安装需要依赖zookeeper, 本文与上一篇文章都是真正分布式安装配置, 可以直接用于生产环境. zookeeper安装 ...
随机推荐
- 剑指offer-面试题7:俩个栈实现队列(c)
- FFmpeg源代码结构图 - 解码
===================================================== FFmpeg的库函数源代码分析文章列表: [架构图] FFmpeg源代码结构图 - 解码 F ...
- 【移动开发】startForeground()让服务保持前台级别
最近在使用android 4.1系统的时候,发现在手机休眠一段时间后(1-2小时),后台运行的服务被强行kill掉,有可能是系统回收内存的一种机制,要想避免这种情况可以通过startForegroun ...
- java中小数的处理:高精度运算用bigDecimal类,精度保留方法,即舍入方式的指定
一. 计算机的小数计算一定范围内精确,超过范围只能取近似值: 计算机存储的浮点数受存储bit位数影响,只能保证一定范围内精准,超过bit范围的只能取近似值. java中各类型的精度范围参见:http: ...
- MySQL设计软件登录模块
学了一段时间的Java了,思量着做一点简单的小模块的东西吧,于是就有了下面的这个简单的小案例. 大致实现的功能就是注册于登录还有就是用到了一点,分层思想.仅此而已,所以非常的适合新手围观. 建立好数据 ...
- xml特殊字符处理 如&
写了个request2XML的方法,每当数据中有'<'.'&'符号时,封装的XML就无法解析.发现了XML里的CDATA属性,问题迎刃而解!在XML文档中的所有文本都会被解析器解析 ...
- 初识WCF之使用配置文件部署WCF应用程序
二月份的开头,小编依旧继续着项目开发之路,开始接触全新的知识,EF,WCF,MVC等,今天小编来简单的总结一下有关于WCF的基础知识,学习之前,小编自己给自己提了两个问题,WCF是什么?WCF能用来做 ...
- 利用openssl管理证书及SSL编程第1部分: openssl证书管理
利用openssl管理证书及SSL编程第1部分 参考:1) 利用openssl创建一个简单的CAhttp://www.cppblog.com/flyonok/archive/2010/10/30/13 ...
- (NO.00003)iOS游戏简单的机器人投射游戏成形记(十七)
现在玩家选择机器人后,可以在屏幕上或手臂上点击来移动robot's arm了. 但是玩家选择一个机器人后没有视觉效果来表明哪个机器人被选中.玩家做了一个操作后没有视觉反馈会惹恼强迫症用户滴 ;) 这篇 ...
- Android用AlarmManager实现后台任务-android学习之旅(63)
因为Timer不能唤醒cpu,所以会在省电的原因下失效,所以需要唤醒cpu在后台稳定化的执行任务,AlarmManager能够唤醒cpu 这个例子讲解了如何通过Service来在后他每一个小时执行.特 ...