Python数据采集——提取页面内容的几种手段
前言
在我们获取了网页的信息后,往往需要对原始信息进行提取,得到我们想要的数据。对信息的提取方式主要有以下几种:正则表达式、XPath、BeautifulSoup。本篇博客主要总结这三种方式的基本语法,以及举一些例子来说明如何使用这些方法。
正则表达式
什么是正则表达式?
正则表达式是使用某种预定义的模式去匹配一类具有共同特征的字符串,主要用于处理字符串,可以快速、准确地完成复杂的查找、替换等要求。
在Python中,re模块提供了正则表达式操作所需要的功能。所以,在Python中使用正则表达式需要先import re。
在使用正则表达式提取信息时可以概括为以下三步(大部分提取信息方法的步骤也是如此):
- 寻找规律
- 使用正则符号表示规律
- 提取信息
正则表达式的基本符号
这里主要介绍正则中的基本符号,高级的语法的部分会在后面附上链接供大家参考学习。
一般符号
名称 描述 示例 点号. 匹配除换行符 \n以外任意单个字符,若是要匹配.则需要使用转义字符\a.c -> abc, a#c 方括号[] 字符集(字符类)。对应的位置可以是指定字符集中的任意字符,[]中的字符可以逐个列出,也可以给出范围。^符号表示取反,即除指定字符以外的其他字符。 a[bcd]e -> abe; a[b-f]g -> abg; a[^bc]d -> aefd ad之间不可以出现bc字符 数量相关
名称 描述 示例 星号* 星号表示它前面的一个子表达式(普通字符、另一个或几个正则表达式符号)0次或任意多次 abc* -> ab, abc, abcc 问号? 问号表示它前面的子表达式0次或者1次。 abc? -> ab, abc ; ab?c ->ac, abc 加号+ 加号表示它前面的子表达式1次或者任意多次 abc+ ->abc, abcc, abccc 花括号{m} 匹配前一个子表达式m次 ab{3}c -> abbbc 花括号{m, n} 匹配前一个子表达式m至n次,m和n可以省略,若省略m,则匹配0至n次,若省略n,则匹配m至无限次 ab{2,3}c ->abbc, abbbc 边界匹配
名称 描述 示例 hat符号^ 匹配字符串的开头,在多行模式下匹配每一行的开头 ^a->ab dollar符号$ 匹配字符串的末尾,在多行模式下匹配每一行的末尾 $a->bca \b 匹配一个单词边界 er\b可以匹配never但是不可以匹配verb \B 匹配非单词边界 er\B可以匹配verb但是不可以匹配never 预定义字符集
名称 描述 示例 \d 数字0-9 a\dc->a1c \D 非数字 a\Dc->a#c aec \s 空白字符(空格、\t、\r、\n、\f(换页)、\v(垂直跳格(垂直制表))) a\sc ->a c \S 非空白字符 a\Sc ->abc, a1c, a#c \w 单词字符(A-Z,a-z,0-9,_(下划线)) a\wc ->a0c, abc, a2c \W 非单词字符 a\Wc ->a c, a#c 逻辑、分组
名称 描述 示例 | 代表左右表达式任意匹配一个。注:它总是先尝试匹配左边的表达式,一旦成功匹配,则跳过右边的匹配 abc|def->abc, def () 被括起来的表达式将作为分组,从表达式左边开始每遇到一个分组的左括号,编号+1,分组表达式作为一个整体,可以后面接数量词,通常用于提取内容 (abc){3} ->abcabcabc; a(123|456)->a123c a456c 复杂一点的用法
名称 示例 .和*共用 . a.*d ->ad,and,amnopqd []和*共用 a[bc]*d ->abd, acd, abbbbd, acbccd .*和.*?的区别:.*:贪婪模式,获取最长的满足条件的字符串.*?:非贪婪模式,获取最短的能满足条件的字符串例如:
<div>
<a>123</a>
<a>456</a>
</div>
使用
<a>(.*)</a>匹配出来的结果为:123</a><a>456使用
<a>(.*?)</a>匹配出来的结果为:123 和 456在使用正则表达式提取文本内容时,也常常使用
.*?(最小匹配)
RE模块的常用方法
使用re模块时,记得先导入import re
re.match方法
match(pattern,string[,flags]):
尝试从字符串的起始位置进行匹配,若匹配成功,则返回一个匹配的对象,若匹配不成功,则返回none并且可以使用group(num)或 groups()匹配对象函数来获取匹配表达式
>>> import re
>>> print(re.match('www', 'www.cnblog.com'))
<_sre.SRE_Match object; span=(0, 3), match='www'>
>>> print(re.match('com', 'www.cnblog.com'))
None
>>> line = 'Who are you ?.'
>>> macth = re.match(r'(.*) are (.*?) ', line)
>>> macth.group()
'Who are you '
>>> macth.groups()
('Who', 'you')
>>> macth.group(1)
'Who'
>>> macth.group(2)
'you'
re.search方法
search(pattern,string[,flags]):
扫描整个字符串并返回第一个成功的匹配,若匹配成功则返回一个匹配的对象,否则返回None。
>>> print(re.search('www', 'www.cnblog.com'))
<_sre.SRE_Match object; span=(0, 3), match='www'>
>>> print(re.search('cn', 'www.cnblog.com'))
<_sre.SRE_Match object; span=(4, 6), match='cn'>
re.findAll方法
findall(pattern,string[,flags]):
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
>>> line = 'cnblog->123sakuraone456'
>>> print(re.findall(r'\d', line))
['1', '2', '3', '4', '5', '6']
>>> print(re.findall(r'\d+', line))
['123', '456']
>>> print(re.findall(r'\D+', line))
['cnblog->', 'sakuraone']
re.split方法
split(pattern,string[,maxsplit=0]):
按照能够匹配的子串将字符串分割后返回列表。maxsplit指定分割次数。若是没有匹配的,则不分割。
>>> line = 'www.cnblog.com'
>>> print(re.split(r'\W+', line))
['www', 'cnblog', 'com']
>>> print(re.split(r'\W+', line, 2))
['www', 'cnblog', 'com']
>>> print(re.split(r'\W+', line, 1))
['www', 'cnblog.com']
>>> print(re.split(r'\d+', line, 1))
['www.cnblog.com']
re.sub方法
sub(pattern,repl,string[,count=0]):
将字符串中所有pattern的匹配项用repl替换
line = "wodfj1234djsig808"
print(re.sub(r'\D','',line))
1234808
使用XParh
在复杂的文档结构中去使用正则表达式获取内容,可能需要花费大量的时间去构造正确的正则表达式。此时我们可能就需要换一种方式提取。
XPath使用路径表达式来选取XML文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。要获取一个节点就需要构造它的路径。
主要在Python中,要使用XPath就需要先安装一个第三方库lxml。
节点类型
因为XPath是依靠路径来选取节点,我们首先就需要知道XPath中的节点类型:
- 元素
- 属性
- 文本
- 命名空间
- 处理指令
- 注释
- 文档节点(根节点)
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
<bookstore> (文档节点)
<author>J K. Rowling</author> (元素节点)
lang="en" (属性节点)
节点之间的关系
XML 文档是被作为节点树来对待的,节点之间的关系如下
- 父:bookstore元素是book、title、author、year 以及price元素的父
- 子:book、title、author、year 以及 price 元素都是bookstore元素的子
- 同胞:title、author、year 以及price元素都是同胞
- 先辈:title 元素的先辈是book元素和bookstore
- 后代:bookstore 的后代是book、title、author、year以及price
使用路径表达式选取节点
| 表达式 | 描述 | 示例 | 示例说明 |
|---|---|---|---|
| nodename | 选取nodename节点的所有子节点 | ||
| / | 从根节点开始选取 | xpath('/div') | 从根节点上选取div节点 |
| // | 选取所有的当前节点,不考虑他们的位置 | xpath('//div') | 选取所有div节点 |
| . | 选取当前节点 | xpath(‘./div’) | 选取当前节点下的div节点 |
| .. | 选取当前节点的父节点 | xpath('..') | 回到上一个节点 |
| @ | 选取属性 | xpath(‘//@calss’) | 选取所有的class属性 |
XPath谓词查找特定的节点
谓语被嵌在方括号内,用来查找特定的节点。
| 表达式 | 结果 |
|---|---|
| xpath(‘/body/div[1]’) | 选取body下的第一个div节点 |
| xpath(‘/body/div[last()]’) | 选取body下的最后一个div节点 |
| xpath(‘/body/div[last()-1]’) | 选取body下的倒数第二个div节点 |
| xpath(‘/body/div[positon()❤️]’) | 选取body下的前两个div节点 |
| xpath(‘/body/div[@class]’) | 选取body下带有class属性的div节点 |
| xpath(‘/body/div[@class=‘main’]’) | 选取body下class属性是main的div节点 |
| xpath(‘/body/div[price>35.00]’) | 选取body下price元素大于35的div节点 |
XPath通配符
| 通配符 | 描述 | 示例 | 示例说明 |
|---|---|---|---|
| * | 匹配任何元素节点 | xpath(‘/div/*’) | 选取div下的所有子节点 |
| @* | 匹配任何属性节点 | xpath(‘/div[@*]’) | 选取所有带属性的div节点 |
选取多个路径的节点
使用 | 运算符可以选取多个路径
| 表达式 | 结果 |
|---|---|
| xpath(‘//div丨//table’) | 选取所有div和table节点 |
| //book/title丨//book/price | 选取 book 元素的所有 title 和 price 元素 |
| /bookstore/book/title丨//price | 选取属于 bookstore元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素 |
使用功能函数进行模糊搜索
| 函数 | 用法 | 说明 |
|---|---|---|
| starts-with | xpath(‘//div[starts-with(@id,‘ma’)]’) | 选取id值以ma开头的div节点 |
| contains | xpath(‘//div[contains(@id, ‘ma’)]’) | 选取id值包含ma的div节点 |
| and | xpath(‘//div[contains(@id, ‘ma’) and contains(@id,”in”)]’) | 选取id值包含ma和in的div节点 |
| text() | xpath(‘//div[contains(text(),‘ma’)]’) | 选取节点文本包含ma的div节点 |
获取节点的文本内容和属性值
前面讲了那么多获取节点的方式,都是为了最终获取到想要的文本数据做准备。XPath中获取节点文本信息使用text(),获取节点的属性值使用@属性。

from lxml import etree
import requests
html = requests.get('https://movie.douban.com/top250').content.decode('utf8')
print(html)
selector = etree.HTML(html)
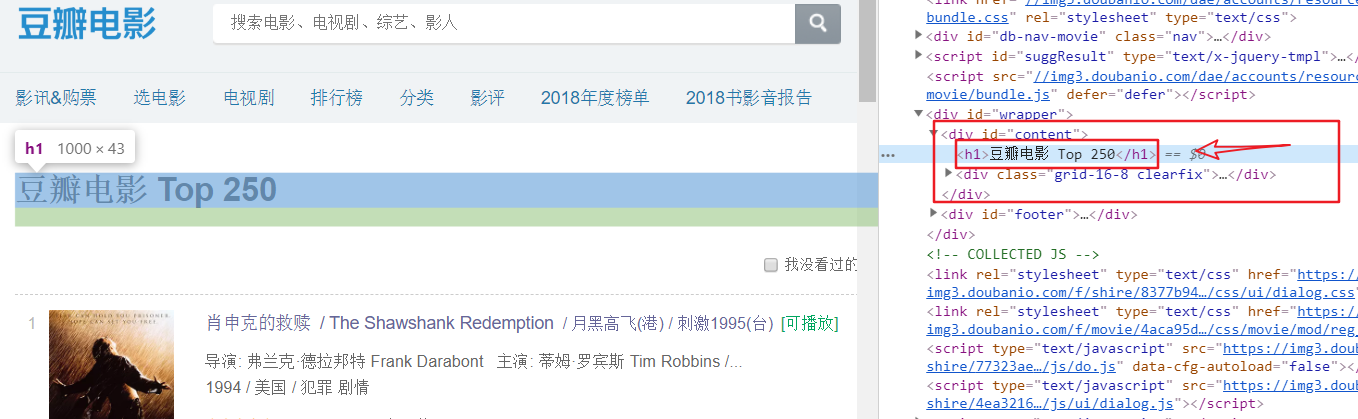
title = selector.xpath('//div[@id="content"]/h1/text()')
print(title) # ['豆瓣电影 Top 250']
link = selector.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/@href')
print(link) # ['https://movie.douban.com/subject/1292052/']
如上图所示,我们使用获取一个节点文本信息以及一个节点的属性值。为了方便我们使用XPath,在浏览器中的开发者模式下,选中节点,右键,就可以Copy我们的想要路径。不过,这种路径有时并不是我们想要的,因为只能获取到当前这个的节点,所以我们更多时候需要对xpath路径进行构造。
使用BeautifulSoup
BeautifulSoup4(BS4)是Python的一个第三方库,用来从HTML和XML中提取数据。BeautifulSoup4在某些方面比XPath易懂,但是不如XPath简洁,而且由于它是使用Python开发的,因此速度比XPath慢。
使用Beautiful Soup4提取HTML内容,一般要经过以下两步:
处理源代码生成BeautifulSoup对象
soup = BeautifulSoup(网页源代码, ‘解析器’)
解析器可以使用
html.parser也可以使用lxml常使用find_all()、find()和select来查找内容
import requests
from bs4 import BeautifulSoup
html = requests.get('https://movie.douban.com/top250').content.decode('utf8')
print(html)
soup = BeautifulSoup(html, 'lxml')
title = soup.select('#content > h1')[0].text
print(title) # 豆瓣电影 Top 250
print(soup.find('h1').text) # 豆瓣电影 Top 250
link = soup.select('#content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a')[0].get('href')
print(link) # https://movie.douban.com/subject/1292052/
关于BeautifulSoup库的使用完全可以参考文档学习,附上中文文档链接:https://docs.pythontab.com/beautifulsoup4/
小结
花了小半下午整理了对信息的提取方式。其中,最令我头疼的还是正则表达式,学习正则表达式已经有好几遍了,但是在需要使用的时候仍然需要去看手册。可能这就是一个反复的过程吧。下面附上这三种方式的一些参考学习链接:
正则表达式:
- http://www.runoob.com/python3/python3-reg-expressions.html
- https://www.tutorialspoint.com/python3/python_reg_expressions.htm
XPath:
BeautifulSoup:
Python数据采集——提取页面内容的几种手段的更多相关文章
- python爬虫解析页面数据的三种方式
re模块 re.S表示匹配单行 re.M表示匹配多行 使用re模块提取图片url,下载所有糗事百科中的图片 普通版 import requests import re import os if not ...
- C#获取页面内容的几种方式
常见的Web页面获取页面内容用 WebRequest 或者 HttpWebRequest 来操作 Http 请求. 例如,获取百度网站的 html 页面 var request = WebReques ...
- python爬虫-提取网页数据的三种武器
常用的提取网页数据的工具有三种xpath.css选择器.正则表达式 1.xpath 1.1在python中使用xpath必须要下载lxml模块: lxml官方文档 :https://lxml.de/i ...
- 使用jQuery编辑删除页面内容,两种方式
第一种,比较少的编辑用这种,直接在那块内容上编辑,失去焦点即完成 前几天做编辑框的时候,需要只修改一个状态 //编辑角色 function editTr($this){ thatTd=$($this) ...
- python 正则表达式提取返回内容
import re re.findall(' <input name="address_id" type="hidden" value="(.* ...
- python爬取页面内容
from selenium import webdriverimport xlwt driver = webdriver.Chrome(r'D:\chromedriver.exe')driver.ma ...
- Python 爬取页面内容
import urllib.request import requests from bs4 import BeautifulSoup url = "http://www.stats.gov ...
- [实战演练]python3使用requests模块爬取页面内容
本文摘要: 1.安装pip 2.安装requests模块 3.安装beautifulsoup4 4.requests模块浅析 + 发送请求 + 传递URL参数 + 响应内容 + 获取网页编码 + 获取 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(2)
上半部分内容链接 : https://www.cnblogs.com/lowmanisbusy/p/9069330.html 四.json和jsonpath的使用 JSON(JavaScript Ob ...
随机推荐
- Rmq Problem/mex BZOJ3339 BZOJ3585
分析: 一开始没看懂题... 后来想用二分答案却不会验证... 之后,想到用主席树来维护... 建一个权值线段树,维护出这个权值以前所有的点最晚在哪里出现... 之后,查一下是不是比查询区间的l断点大 ...
- Git----GitHub上传本地文件到git
1.首先在git上创建一个库,用来保存上传的本地文件 2.通过命令 git init 把这个目录变成git可以管理的仓库 git init 3.将远程git库克隆一份保存到本地 git clone x ...
- 大数据技术之_19_Spark学习_02_Spark Core 应用解析小结
1.RDD 全称 弹性分布式数据集 Resilient Distributed Dataset它就是一个 class. abstract class RDD[T: ClassTag]( @tra ...
- React 虚拟 DOM 的差异检测机制
React 使用虚拟 DOM 将计算好之后的更新发送到真实的 DOM 树上,减少了频繁操作真实 DOM 的时间消耗,但将成本转移到了 JavaScript 中,因为要计算新旧 DOM 树的差异嘛.所以 ...
- (leetcode:选择不相邻元素,求和最大问题):打家劫舍(DP:198/213/337)
题型:从数组中选择不相邻元素,求和最大 (1)对于数组中的每个元素,都存在两种可能性:(1)选择(2)不选择,所以对于这类问题,暴力方法(递归思路)的时间复杂度为:O(2^n): (2)递归思路中往往 ...
- 服务端预渲染之Nuxt(介绍篇)
现在前端开发一般都是前后端分离,mvvm和mvc的开发框架,如Angular.React和Vue等,虽然写框架能够使我们快速的完成开发,但是由于前后台分离,给项目SEO带来很大的不便,搜索引擎在检索的 ...
- 号称“新至强,可拓展,赢当下”的Xeon可拓展处理器有多逆天?
目前企业数据中心正在发生重大变化,许多企业正在经历基于在线服务和数据的广泛转型.他们将这些数据用于功能强大的人工智能和分析应用程序,这些应用程序可以将其转化为改变业务的洞察力,然后推出可以使这些洞察力 ...
- js防抖和节流
今天在网上看到的,里面的内容非常多.说下我自己的理解. 所谓的防抖就是利用延时器来使你的最后一次操作执行.而节流是利用时间差的办法,每一段时间执行一次.下面是我的代码: 这段代码是右侧的小滑块跟随页面 ...
- java工作流引擎Jflow流程事件和流程节点事件设置
流程实例的引入和设置 关键词: 开源工作流引擎 Java工作流开发 .net开源工作流引擎 流程事件 工作流节点事件 应用场景: 在一些复杂的业务逻辑流程中需要在某个节点或者是流程结束后做一些 ...
- apache-jmeter-5.0的简单压力测试使用方法
同事交接工作,压测部分交给我,记录一下使用方法 我将下载下来的压缩包解压后放置在E盘 然后配置环境变量: 变量名JMETER_HOME,变量值 E:\javatool\apache-jmeter-5. ...