Cayley图数据库的简介及使用
图数据库
在如今数据库群雄逐鹿的时代中,非关系型数据库(NoSQL)已经占据了半壁江山,而图数据库(Graph Database)更是攻城略地,成为其中的佼佼者。
所谓图数据库,它应用图理论(Graph Theory)可以存储实体的相关属性以及它们之间的关系信息。最常见例子就是社会网络中人与人之间的关系。相比于关系型数据库(比如MySQL等),图数据库更能胜任这方面的任务。
图数据库现已涌现出许多出众的软件,比如笔者写过的文章Neo4j入门之中国电影票房排行浅析中的Neo4j,Twitter为进行关系数据分析而构建的FlockDB,高度可扩展的分布式图数据库JanusGraph以及Google的开源图数据库Cayley等。
本文将具体介绍Cayley图数据库。
Cayley图数据库的简介
Cayley图数据库是 Google 的一个开源图(Graph)数据库,其灵感来自于 Freebase 和 Google 的知识图谱背后的图数据库。它采用Go语言编写而成,运行命令简单,一般只需要3到4个命令即可。同时,它拥有RESTful API,内建查询编辑器和可视化界面,支持多种查询语言,比如JavaScript,MQL等。另外,它还能支持多种后端数据库储存,比如MySQL,MongoDB, LevelDB等,性能良好,测试覆盖率也OK,功能十分丰富且强大。
当然,对于我们而言,最重要的特性应该是开源。Cayley图数据库的官方Github地址为:https://github.com/cayleygraph/cayley 。
下面将具体介绍如何安装及使用Cayley图数据库。
安装及说明
关于Cayley图数据库的安装,不同的操作系统的安装方式不一样。下载的网址为:https://github.com/cayleygraph/cayley/releases, 截图如下:
读者可依据自己的电脑系统下载相应的文件,笔者的电脑为Mac,因此选择cayley_0.7.5_darwin_amd64.tar.gz文件。同时你的电脑上需要安装一款Cayley用来储存后台数据的数据库,笔者选择了MongoDB数据库。
当然,Cayley还为你提供了完整的使用说明文档,可以参考网址:https://github.com/cayleygraph/cayley/blob/master/docs/Quickstart-As-Application.md, 它能帮你快速熟悉Cayley的操作,助你快快上手。笔者会用更简单的方式帮你熟悉该图数据库。
So, let's begin!
数据准备
为了能够更好地了解Cayley图数据库,我们应该从数据开始一步步地来构建图数据库,并实现查询功能。本文的数据来源于文章Neo4j入门之中国电影票房排行浅析, 其中爬取了中国电影票房信息,如下:

以及每部电影中的主演信息,如下:
得到了两个表格文件movies.csv和actor.csv,文件的内容如下:
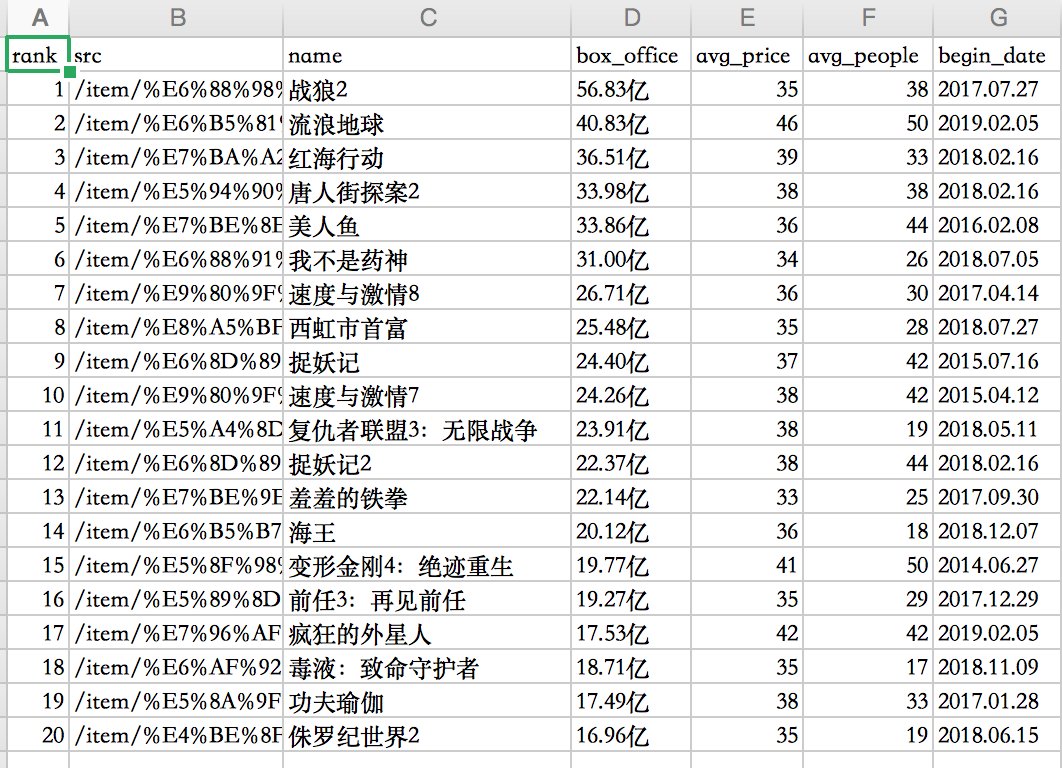

数据准备完毕。如读者需要下载该数据,可以参考网址:https://github.com/percent4/Neo4j_movie_demo 。
三元组文件
Cayley数据库支持三元组文件导入,所谓三元组,指的是主语subject,谓语predicate 以及宾语object,每个三元组为一行。
Cayley数据库支持的三元组文件以nq为后缀,每个三元组为一行,主语、谓语、宾语中间用空格分开,同时还需要注意一下事项(笔者亲自踩坑的经历):
- 注意空格,空格是划分实体的标志;
- 注意","是关键字,也不能在实体中出现;
- 不能在实体中出现换行符(比如\n);
- 不能出现重复的数据(实体重复、三元组重复都不行)。
接着我们利用Python程序将movies.csv和actors.csv文件处理成三元组。我们抽取的原则如下:
- 电影名,演员名为实体;
- 电影名与电影的关系为ISA,即电影名 ISA Movie;
- 演员名与电影名的关系为ACT_IN,即演员名 ACT_IN 电影名;
- 电影名的其余为属性对,即电影名 属性 属性名, 比如战狼2 rank 1.
实现的Python程序如下:
# -*- coding: utf-8 -*-
import pandas as pd
# 读取文件
movies = pd.read_csv('movies.csv')
actors = pd.read_csv('actors.csv')
# print(movies.head())
# 处理电影数据为三元组,抽取的三运组如下:
# 电影名 ISA Movie
# 电影名 属性 属性值
with open('China_Movie.nq', 'w') as f:
name_df = movies['name']
for i in range(name_df.shape[0]):
f.write('<%s> <ISA> <Movie> .\n'%name_df[i])
for col in movies.columns:
if col != 'name':
f.write('<%s> <%s> "%s" .\n'%(name_df[i], col, movies[col][i]))
# 处理演员数据为三元组,抽取的三运组如下:
# 演员名 ISA Actor
# 演员名 ACT_IN 电影名
with open('China_Movie.nq', 'a') as f:
for i in range(actors.shape[0]):
for actor in actors['actors'][i].split(','):
f.write('<%s> <ACT_IN> <%s> .\n' % (actor, actors['name'][i]))
在China_Movie.nq中,共有276个三元组,文件的前几行如下:
<战狼2> .
<战狼2> "1" .
<战狼2> "/item/%E6%88%98%E7%8B%BC2" .
<战狼2> <box_office> "56.83亿" .
<战狼2> <avg_price> "35" .
<战狼2> <avg_people> "38" .
<战狼2> <begin_date> "2017.07.27" .
<流浪地球> .
<流浪地球> "2" .
<流浪地球> "/item/%E6%B5%81%E6%B5%AA%E5%9C%B0%E7%90%83" .
<流浪地球> <box_office> "40.83亿" .
<流浪地球> <avg_price> "46" .
<流浪地球> <avg_people> "50" .
<流浪地球> <begin_date> "2019.02.05" .
<红海行动> .
导入数据
将China_Movie.nq文件移动至Cayley的data目录下,同时配置cayley_example.yml文件,内容如下:
store:
# backend to use
backend: mongo
# address or path for the database
address: "localhost:27017"
# open database in read-only mode
read_only: false
# backend-specific options
options:
nosync: false
query:
timeout: 30s
load:
ignore_duplicates: false
ignore_missing: false
batch: 10000
在该配置文件中,声明了Cayley的后台数据库为MongoDB,同时制定了ip及端口。
接着运行命令:
./cayley load -c cayley_example.yml -i data/China_Movie.nq
等待数据导入,接着前往MongoDB中查看,如发现MongoDB中存在cayley数据库,则表明数据导入成功。
使用查询语句
接着再输入命令:
./cayley http -i ./data/China_Movie.nq -d memstore --host=:64210
这样就支持在浏览器中进行查询了,只需要在浏览器中输入http://localhost:64210/ 即可,界面如下:
关于查询语句,它是图数据库的精华所在,而对于Cayley而言,它的查询语句相对来说就比较简单且好理解,具体的查询语句命令可以参考官网: https://github.com/cayleygraph/cayley/blob/master/docs/GizmoAPI.md
,本文将通过几个简单的查询语句来说明怎样对Cayley图数据库进行查询。
查询一共有多少条数据
命令为:
var n = g.V().Count();
g.Emit(n);
其中g代表图,V代表顶点,g.Emit()会将结果以JSON格式返回。输出的结果如下:
{
"result": [
521
]
}
查询全部电影
命令为:
var movies = g.V('<Movie>').In('<ISA>').ToArray();
g.Emit(movies);
返回的结果如下:
{
"result": [
[
"<战狼2>",
"<流浪地球>",
"<红海行动>",
"<唐人街探案2>",
"<美人鱼>",
"<我不是药神>",
"<速度与激情8>",
"<西虹市首富>",
"<捉妖记>",
"<速度与激情7>",
"<复仇者联盟3:无限战争>",
"<捉妖记2>",
"<羞羞的铁拳>",
"<海王>",
"<变形金刚4:绝迹重生>",
"<前任3:再见前任>",
"<疯狂的外星人>",
"<毒液:致命守护者>",
"<功夫瑜伽>",
"<侏罗纪世界2>"
]
]
}
查询电影《流浪地球》的所有属性值
命令为:
var movie = "<流浪地球>";
var attrs = g.V(movie).OutPredicates().ToArray(); //类型为object,即字典
values = new Array();
for (i in attrs) {
var value = g.V(movie).Out(attrs[i]).ToValue();
values[i] = value;
}
key_val_json = new Object();
for (i in attrs) {
key_val_json[attrs[i]]= values[i];
}
g.Emit(key_val_json)
输出结果如下:
{
"result": [
{
"<ISA>": "<Movie>",
"<avg_people>": "50",
"<avg_price>": "46",
"<begin_date>": "2019.02.05",
"<box_office>": "40.83亿",
"<rank>": "2",
"<src>": "/item/%E6%B5%81%E6%B5%AA%E5%9C%B0%E7%90%83"
}
]
}
查询沈腾主演的电影
命令为:
var movies = g.V('<沈腾>').Out('<ACT_IN>').ToArray();
g.Emit(movies);
输出为:
{
"result": [
[
"<西虹市首富>",
"<羞羞的铁拳>",
"<疯狂的外星人>"
]
]
}
查询《捉妖记》与《捉妖记2》的共同演员
命令为:
var actors1 = g.V('<捉妖记>').In('<ACT_IN>');
var actors2 = g.V('<捉妖记2>').In('<ACT_IN>');
var common_actor = actors2.Intersect(actors1).ToArray();//集合交集
g.Emit(common_actor);
输出为:
{
"result": [
[
"<白百何>",
"<井柏然>",
"<曾志伟>",
"<吴君如>"
]
]
}
总结
在本文中,笔者介绍了一种新的图数据库Cayley,并介绍了它的安装方式,以及如何导入三元组数据,进行查询。希望能够给读者一些参考~
虽然是Google开源的图数据库,但在网上关于Cayley图数据库的介绍并不多,而且都未能深入地讲解,大多是照搬官方文档的讲解,希望笔者的讲解能够带来一些进步,这也是笔者写此文的目的。希望此文能多少帮到读者~
注意:不妨了解下笔者的微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注~
Cayley图数据库的简介及使用的更多相关文章
- Cayley图数据库的可视化(Visualize)
引入 在文章Cayley图数据库的简介及使用中,我们已经了解了Cayley图数据库的安装.数据导入以及进行查询等. Cayley图数据库是Google开发的开源图数据库,虽然功能还没有Neo4 ...
- JanusGraph : 图和图数据库的简介
JanusGraph:图数据库系统简介 图(graph)是<数据结构>课中第一次接触到的一个概念,它是一种用来描述现实世界中个体和个体之间网络关系的数据结构. 为了在计算机中存储图,< ...
- 图数据库Neo4j简介
图数据库Neo4j简介 转自: 图形数据库Neo4J简介 - loveis715 - 博客园https://www.cnblogs.com/loveis715/p/5277051.html 最近我在用 ...
- Google Cayley图数据库使用方法
最近在用Golang做流程引擎,对于流程图的存储,我看到了Google的Cayley图数据库,感觉它可能会比较适合我的应用,于是便拿来用了用. 项目地址在这里:https://github.com/g ...
- Neo4j图数据库简介和底层原理
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系.地图数据.或是基因信息等等.RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘.NoSQL数据库的兴起,很好地解决了海 ...
- 图数据库cayley+mongo的起航之旅
图数据库,目前比较主流的可能是Neo4j以及cayley了.但是,由于Neo4j只有社区版是免费的,所以,选择cayley作为项目的最终选择! 今天就简单的介绍下,我的起航之旅. 1.安装go语言环境 ...
- 开源软件:NoSql数据库 - 图数据库 Neo4j
转载自原文地址:http://www.cnblogs.com/loveis715/p/5277051.html 最近我在用图形数据库来完成对一个初创项目的支持.在使用过程中觉得这种图形数据库实际上挺有 ...
- JanusGraph 图数据库安装小记 ——以 JanusGraph 0.3.0 为例
由于近期项目中有使用图数据的需求,经过对比,我们选择尝试使用 JanusGraph.本篇小记记录了我们安装 JanusGraph 以及需要一起集成的 Cassandra + Elasticsearch ...
- google Cayley图谱数据库初试
一.安装 mkdir cayley cd cayley mkdir src export GOPATH=$(pwd) go get github.com/google/cayley go build ...
随机推荐
- Ubuntu16.04 下搭建git服务器及gitweb+nginx配置
本文转自:http://blog.csdn.net/water_horse/article/details/68958140 1.安装所需软件 fengjk@water:~$ sudo apt-get ...
- Laravel分页带参数的实现方法
控制器: $data['type'] = 5;$data['member_list'] = Member::orderBy('id', 'desc')->paginate(10);return ...
- 微服务(入门四):identityServer的简单使用(客户端授权)
IdentityServer简介(摘自Identity官网) IdentityServer是将符合规范的OpenID Connect和OAuth 2.0端点添加到任意ASP.NET核心应用程序的中间件 ...
- 同源策略 & 高效调试CORS实现
# 目录 为什么有同源策略? 需要解决的问题 CORS跨域请求方案 preflight withCredentials 附:高效.优雅地调试CORS实现 ----------------------- ...
- Docker入门学习
Python爬虫 最近断断续续的写了几篇Python的学习心得,由于有开发经验的同学来说上手还是比较容易,而且Python提供了强大的第三方库,做一个小的示例程序还是比较简单,这不我之前就是针对Pyt ...
- .NET Core使用Quartz执行调度任务进阶
一.前言运用场景 Quartz.Net是一个强大.开源.轻量的作业调度框架,在平时的项目开发当中也会时不时的需要运用到定时调度方面的功能,例如每日凌晨需要统计前一天的数据,又或者每月初需要统计上月的数 ...
- TensorFlow从1到2(四)时尚单品识别和保存、恢复训练数据
Fashion Mnist --- 一个图片识别的延伸案例 在TensorFlow官方新的教程中,第一个例子使用了由MNIST延伸而来的新程序. 这个程序使用一组时尚单品的图片对模型进行训练,比如T恤 ...
- Python进阶:如何将字符串常量转化为变量?
前几天,我们Python猫交流学习群 里的 M 同学提了个问题.这个问题挺有意思,经初次讨论,我们认为它无解. 然而,我认为它很有价值,应该继续思考怎么解决,所以就在私密的知识星球上记录了下来. 万万 ...
- ajax分页借鉴
大家好这是我分页是用的代码希望大家可以相互交流ajax局部刷新 var pageindex = 1; var where = ""; var Pname = "" ...
- Angular(03)-- lint风格规范和WebStorm小技巧
在开始讲 Angular 各个核心知识点之前,想先来讲讲开发工具 WebStorm 的一些配置以及相应配置文件如 tslint.json 的配置. 因为我个人比较注重代码规范.代码风格,而对于这些规范 ...