Python写爬虫爬妹子
1.下载数据

有的网站做了反爬的处理,可以添加User-Agent :判断浏览器
self.user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
# 初始化 headers
self.headers = {'User-Agent': self.user_agent}
如果不行,在Chrome上按F12分析请求头、请求体,看需不需要添加别的信息,例如有的网址添加了referer:记住当前网页的来源,那么我们在请求的时候就可以带上。按Ctrl + Shift + C,可以定位元素在HTML上的位置
动态网页
下载数据的模块有urllib、urllib2及Requests
html = requests.get(url, headers=headers) #没错,就是这么简单
urllib2以我爬取淘宝的妹子例子来说明:
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
# 注意:form data请求参数
params = 'q&viewFlag=A&sortType=default&searchStyle=&searchRegion=city%3A&searchFansNum=¤tPage=1&pageSize=100' def getHome():
url = 'https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8'
req = urllib2.Request(url, headers=headers)
# decode(’utf - 8’)解码 把其他编码转换成unicode编码
# encode(’gbk’) 编码 把unicode编码转换成其他编码
# ”gbk”.decode(’gbk’).encode(’utf - 8')
# unicode = 中文
# gbk = 英文
# utf - 8 = 日文
# 英文一 > 中文一 > 日文,unicode相当于转化器
html = urllib2.urlopen(req, data=params).read().decode('gbk').encode('utf-8')
# json转对象
peoples = json.loads(html)
for i in peoples['data']['searchDOList']:
#去下一个页面获取数据
getUseInfo(i['userId'], i['realName'])
2.解析数据
def getUseInfo(userId, realName):
url = 'https://mm.taobao.com/self/aiShow.htm?userId=' + str(userId)
req = urllib2.Request(url)
html = urllib2.urlopen(req).read().decode('gbk').encode('utf-8') pattern = re.compile('<img.*?src=(.*?)/>', re.S)
items = re.findall(pattern, html)
x = 0
for item in items:
if re.match(r'.*(.jpg")$', item.strip()):
tt = 'http:' + re.split('"', item.strip())[1]
down_image(tt, x, realName)
x = x + 1
print('下载完毕')
正则表达式说明
search:在string中进行搜索,成功返回Match object, 失败返回None, 只匹配一个。
findall:在string中查找所有 匹配成功的组, 即用括号括起来的部分。返回list对象,每个list item是由每个匹配的所有组组成的list。
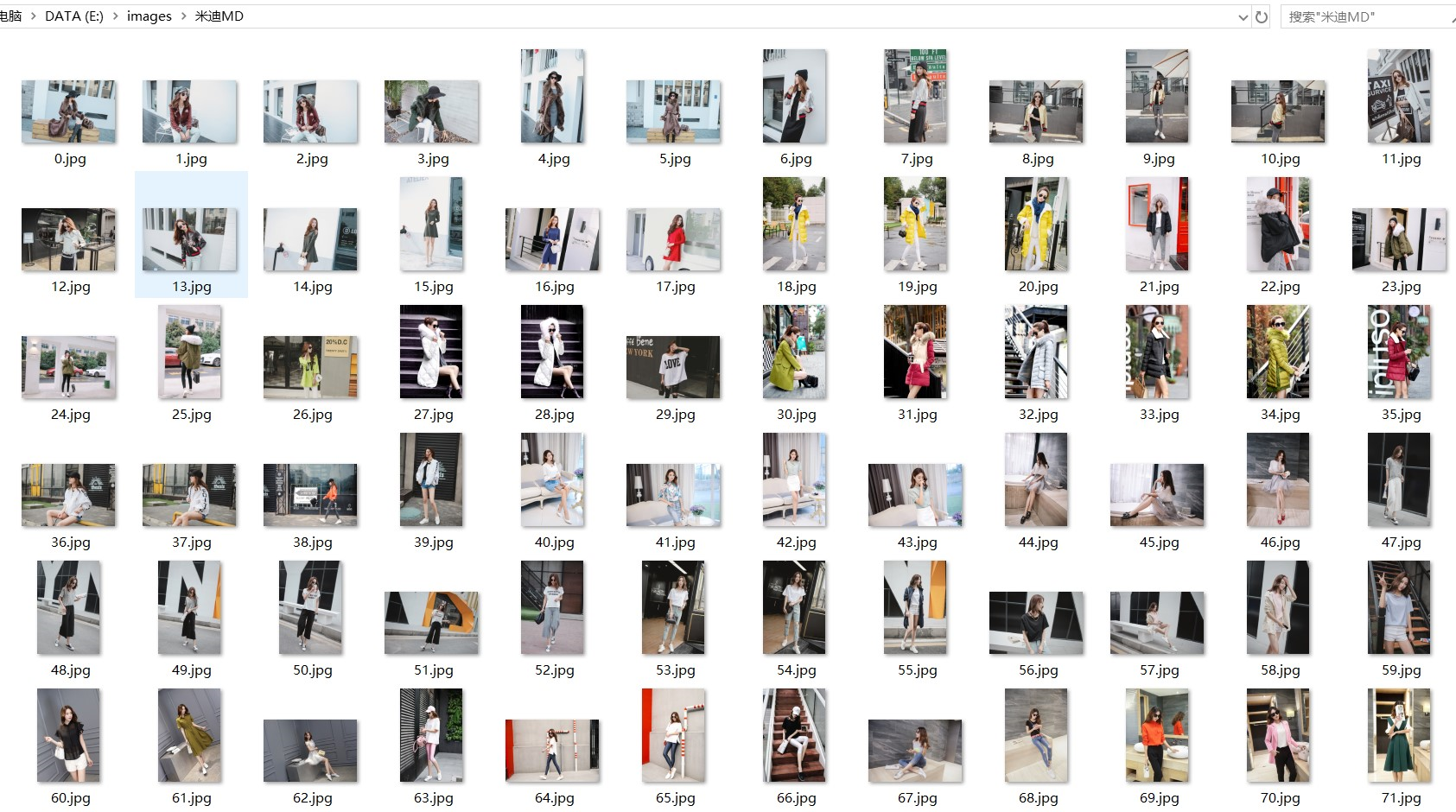
3.保存数据
def down_image(url, filename, realName):
req = urllib2.Request(url=url)
folder = 'e:\\images\\%s' % realName
if os.path.isdir(folder):
pass
else:
os.makedirs(folder) f = folder + '\\%s.jpg' % filename
if not os.path.isfile(f):
print f
binary_data = urllib2.urlopen(req).read()
with open(f, 'wb') as temp_file:
temp_file.write(binary_data)
GitHub地址,还有其他网站爬虫,欢迎star:https://github.com/peiniwan/Spider2
Python写爬虫爬妹子的更多相关文章
- Python写爬虫-爬甘农大学校新闻
Python写网络爬虫(一) 关于Python: 学过C. 学过C++. 最后还是学Java来吃饭. 一直在Java的小世界里混迹. 有句话说: "Life is short, you ne ...
- 用Python写爬虫爬取58同城二手交易数据
爬了14W数据,存入Mongodb,用Charts库展示统计结果,这里展示一个示意 模块1 获取分类url列表 from bs4 import BeautifulSoup import request ...
- python写爬虫时的编码问题解决方案
在使用Python写爬虫的时候,常常会遇到各种令人抓狂的编码错误问题.下面给出一些简单的解决编码错误问题的思路,希望对大家有所帮助. 首先,打开你要爬取的网站,右击查看源码,查看它指定的编码是什么,如 ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 《用Python写爬虫》学习笔记(一)
注:纯文本内容,代码独立另写,属于本人学习总结,无任何商业用途,在此分享,如有错误,还望指教. 1.为什么需要爬虫? 答:目前网络API未完全放开,所以需要网络爬虫知识. 2.爬虫的合法性? 答:爬虫 ...
- 怎么用Python写爬虫抓取网页数据
机器学习首先面临的一个问题就是准备数据,数据的来源大概有这么几种:公司积累数据,购买,交换,政府机构及企业公开的数据,通过爬虫从网上抓取.本篇介绍怎么写一个爬虫从网上抓取公开的数据. 很多语言都可以写 ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- Python练习册 第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-),(http://tieba.baidu.com/p/2166231880)
这道题是一道爬虫练习题,需要爬链接http://tieba.baidu.com/p/2166231880里的所有妹子图片,点进链接看一下,这位妹子是日本著名性感女演员--杉本由美,^_^好漂亮啊,赶紧 ...
随机推荐
- java.lang.IllegalArgumentException: Request header is too large
tomcat运行项目时,有一个请求过去后,后台报这样的错java.lang.IllegalArgumentException: Request header is too large原因:请求头超过了 ...
- WebSocket和Socket
WebSocket和Socket tags:WebSocket和Socket 引言:好多朋友想知道WebSocket和Socket的联系和区别,下面应该就是你们想要的 先来一张之前收集的图,我看到这张 ...
- python中RabbitMQ的使用(安装和简单教程)
1,简介 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现的产品,RabbitMQ是一个消息代理,从"生产者"接收消息 ...
- Python startswith()方法
描述 Python startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False.如果参数 beg 和 end 指定值,则在指定范围内检查. 语法 ...
- index_levedb.go
) binary.BigEndian.PutUint64(key, fid) return l.db.Delete(key, nil) } //关闭资源 func (l *LevelD ...
- 如何使用Docker部署一个Go Web应用程序
熟悉Docker如何提升你在构建.测试并部署Go Web应用程序的方式,并且理解如何使用Semaphore来持续部署. 简介 大多数情况下Go应用程序被编译成单个二进制文件,web应用程序则会包括模版 ...
- Hadoop问题:DataNode进程不见了
DataNode进程不见了 问题描述 最近配置Hadoop的时候出现了这么一个现象,启动之后,使用jps命令之后是这样的: 看不到DataNode进程,但是能够正常的工作,是不是很神奇啊? 在一番 ...
- HTML标题
HTML 标题 在 HTML 文档中,标题很重要. HTML 标题 标题(Heading)是通过 <h1> - <h6> 标签进行定义的. <h1> 定义最大的标题 ...
- set的便捷操作
认识集合 由一个或多个确定的元素所构成的整体叫做集合. 集合中的元素有三个特征: 1.确定性(集合中的元素必须是确定的) 2.互异性(集合中的元素互不相同.例如:集合A={1,a},则a不能等于1) ...
- Cocoa包管理器之CocoaPods详解
CocoaPods在Cocoa开发日常工作中经常用到的包管理器,即依赖管理工具.有的项目也有用Carthage的,Carthage是一个比较新的依赖管理工具,是使用Swift语言开发的.Carthag ...