redis的持久化之RDB的配置和原理
Redis优秀的性能是由于其将所有的数据都存储在内存中,同样memcached也是这样做的,内存中的数据会在服务器重启后就没有了,也就是不能保证持久化。但是为什么Redis能够脱颖而出呢,很大程度上是因为Redis有出色的持久化机制,能够保证服务器重启后,数据不会丢失。Redis持久化是将内存中的数据写入到磁盘(也就是文件)中。下面来看看Redis是如何持久化的。
Redis支持两种方式的持久化,一种是RDB方式,一种是AOF方式。这两种方式可以单独使用其中一种,或者混合使用。
RDB方式介绍
RDB方式是通过快照完成的,当符合一定条件时Redis会自动将内存中的所有数据进行快照,并且存储到硬盘上。就像拍照一样,将这一瞬间的所有东西都保存下来。进行快照的条件在配置文件中指定。主要有两个参数构成:时间和改动的键值的个数,即当在指定时间内被更改的键的个数大于执行数值时,就会进行快照。RDB是Redis的默认持久化方式。
RDB方式配置
找到Redis的配置文件:redis.conf
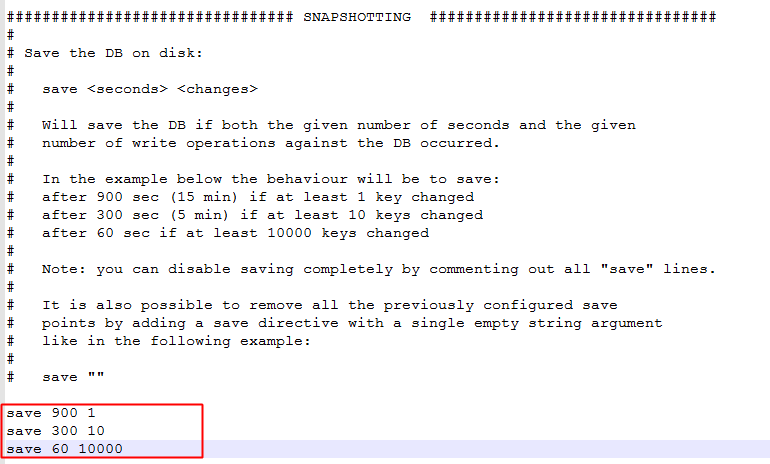
1) 设置触发条件:

2) 设置rdb文件路径
默认rdb文件存放路径是当前目录,文件名是:dump.rdb。可以在配置文件中修改路径和文件名,分别是dir和dbfilename

Redis启动后会读取RDB快照文件,将数据从硬盘载入到内存,一般情况下1GB的快照文件载入到内存的时间大约20-30秒钟。
当条件满足,redis需要执行RDB的时候,服务器会执行以下操作:
1. redis调用系统函数fork() ,创建一个子进程进行持久化。
2.子进程将数据集写入到一个临时 RDB 文件中(持久化,也就是写入文件)。
3.当子进程完成对临时RDB文件的写入时,redis 用新的临时RDB 文件替换原来的RDB 文件,并删除旧 RDB 文件。
注:fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
在执行fork的时候操作系统(类Unix操作系统)会使用写时复制(copy-on-write)策略,即fork函数发生的一刻父子进程共享同一内存数据,当父进程要更改其中某片数据时(如执行一个写命令 ),操作系统会将该片数据复制一份以保证子进程的数据不受影响,所以新的RDB文件存储的是执行fork那一刻的内存数据。
Redis在进行快照的过程中不会修改RDB文件,只有快照结束后才会将旧的文件替换成新的,也就是说任何时候RDB文件都是完整的。这使得我们可以通过定时备份RDB文件来实 现Redis数据库备份。RDB文件是经过压缩(可以配置rdbcompression参数以禁用压缩节省CPU占用)的二进制格式,所以占用的空间会小于内存中的数据大小,更加利于传输。
除了自动快照,还可以手动发送SAVE或BGSAVE命令让Redis执行快照,两个命令的区别在于,前者是由主进程进行快照操作,会阻塞住其他请求,后者会通过fork子进程进行快照操作。
Redis启动后会读取RDB快照文件,将数据从硬盘载入到内存。根据数据量大小与结构和服务器性能不同,这个时间也不同。通常将一个记录一千万个字符串类型键、大小为1GB的快照文件载入到内 存中需要花费20~30秒钟。
通过RDB方式实现持久化,一旦Redis异常退出,就会丢失最后一次快照以后更改的所有数据。这就需要开发者根据具体的应用场合,通过组合设置自动快照条件的方式来将可能发生的数据损失控制在能够接受的范围。如果数据很重要以至于无法承受任何损失,则可以考虑使用AOF方式进行持久化。
RDB的优点是:
1.RDB是一个非常紧凑(compact)的文件,它保存了redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复。
2.生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
3.RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB缺点:
1.如果你需要尽量避免在服务器故障时丢失数据,那么RDB 不适合你。 虽然Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。 因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据(最后一次的数据)。
2.每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
参考:https://blog.csdn.net/u010028869/article/details/51792197
https://blog.csdn.net/aitangyong/article/details/52045251
redis的持久化之RDB的配置和原理的更多相关文章
- Redis:持久化之RDB和AOF
Redis:持久化之RDB和AOF RDB(Redis DataBase) 在指定的时间间隔内将内存中的数据集快照写入硬盘 也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里. R ...
- redis的持久化方式RDB和AOF的区别
1.前言 最近在项目中使用到Redis做缓存,方便多个业务进程之间共享数据.由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能, ...
- Redis的持久化之RDB方式
RDB方式 Redis是默认支持的 优势:只有一个文件,时间间隔的数据,可以归档为一个文件,方便压缩转移(就一个文件) 劣势:如果宕机,数据损失比较大,因为它是没一个时间段进行持久化操作的.也就是积攒 ...
- 11、Redis的持久化(RDB、AOF)
写在前面的话:读书破万卷,编码如有神 --------------------------------------------------------------------------------- ...
- NoSql数据库Redis系列(3)——Redis数据持久化(RDB)
大家都知道 Redis 是一个内存数据库,所谓内存数据库,就是将数据库中的内容保存在内存中,这与传统的MySQL,Oracle等关系型数据库直接将内容保存到硬盘中相比,内存数据库的读写效率比传统数据库 ...
- 分布式缓存Redis的持久化方式RDB和AOF
一.前言 Redis支持两种方式的持久化,RDB和AOF.RDB会根据指定的规则“定时”将内存中的数据存储到硬盘上,AOF会在每次执行命令后将命令本身记录下来.两种持久化方式可以单独使用其中一种,但更 ...
- 详细分析Redis的持久化操作——RDB与AOF
一.前言 由于疫情的原因,学校还没有开学,这也就让我有了很多的时间.趁着时间比较多,我终于可以开始学习那些之前一直想学的技术了.最近这几天开始学习Redis,买了本<Redis实战>, ...
- redis的持久化(RDB与AOF)
1.为什么redis要实现持久化? 避免因宕机.断电等场景导致进程退出后数据丢失,如果redis的数据都只存放于内存,那么进程退出后数据就丢失了.持久化机制可以持久化内存数据到硬盘,重启redis后基 ...
- Redis的持久化之RDB
1.什么是Redis的持久化 Redis是一种高级key-value数据库,是一个高性能的(key/value)分布式内存数据库,基于内存运行并支持持久化的NoSQL数据库,所以Redis的所有数据都 ...
随机推荐
- javascript语法之字符串转换成数字
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- C语言中 sscanf 的用法
名称: sscanf() - 从一个字符串中读进与指定格式相符的数据. 函数原型: Int sscanf( string str, string fmt, mixed var1, mixed var2 ...
- python-inotify 在linux上安装
python-inotify 在linux上安装 0 下载 $ wget --no-check-certificate https://pypi.python.org/packages/source/ ...
- Java-ServletContextAttributeListener
/** Implementations of this interface receive notifications of ** changes to the attribute list on t ...
- 运行Myeclipse时,如何删除IVM窗口
windows------>preference------>run/debug------->lauching--------->percpectives,改成never,n ...
- java集合类中的迭代器模式
不说模式的问题,看一个<<设计模式之禅>>里面的例子. 老板要看到公司了各个项目的情况.(我知道我这个概述很让人头大,看代码吧) 示例程序 v1 package Iterato ...
- LeetCode之“动态规划”:Valid Parentheses && Longest Valid Parentheses
1. Valid Parentheses 题目链接 题目要求: Given a string containing just the characters '(', ')', '{', '}', '[ ...
- Gradle 1.12用户指南翻译——第四十章. ANTLR 插件
本文由CSDN博客万一博主翻译,其他章节的翻译请参见: http://blog.csdn.net/column/details/gradle-translation.html 翻译项目请关注Githu ...
- Linux权限与命令间的关系
极重要!权限与命令间的关系: 我们知道权限对於使用者帐号来说是非常重要的,因为他可以限制使用者能不能读取/创建/删除/修改文件或目录! 在这一章我们介绍了很多文件系统的管理命令,第六章则介绍了很多文件 ...
- Http的会话跟踪和跨站攻击(xss)
会话跟踪 什么是会话? 客户端打开与服务器的连接发出请求到服务器响应客户端请求的全过程称之为会话. 什么是会话跟踪? 会话跟踪指的是对同一个用户对服务器的连续的请求和接受响应的监视. 为什么需要会话跟 ...