Hadoop2.41的HA的配置与启动
我配置HA机制创建了7台虚拟机
1.修改Linux主机名
2.修改IP
3.修改主机名和IP的映射关系
######注意######如果你们公司是租用的服务器或是使用的云主机(如华为云主机、阿里云主机等)
/etc/hosts里面要配置的是内网IP地址和主机名的映射关系
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等
集群规划:
主机名 IP 安装的软件 运行的进程
slave1 192.168.202.20 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
slave2 192.168.202.30 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
slave3 192.168.202.40 jdk、hadoop ResourceManager
slave4 192.168.202.50 jdk、hadoop ResourceManager
slave5 192.168.202.60 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
slave6 192.168.202.70 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
slave7 192.168.202.80 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
说明:
1.在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态
2.hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.4.1解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调
安装步骤:
1.安装配置zooekeeper集群(在slave5上)
1.1解压
tar -zxvf zookeeper-3.4.5.tar.gz -C /zookeeper/
1.2修改配置
cd /weekend/zookeeper-3.4.5/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:dataDir=/weekend/zookeeper-3.4.5/tmp
在最后添加:
server.1=slave5:2888:3888
server.2=slave6:2888:3888
server.3=slave7:2888:3888
保存退出
然后创建一个tmp文件夹
mkdir /weekend/zookeeper-3.4.5/tmp
再创建一个空文件
touch /weekend/zookeeper-3.4.5/tmp/myid
最后向该文件写入ID
echo 1 > /weekend/zookeeper-3.4.5/tmp/myid
1.3将配置好的zookeeper拷贝到其他节点(首先分别在slave6、slave7根目录下创建一个weekend目录:mkdir /weekend)
scp -r /weekend/zookeeper-3.4.5/ slave6:/weekend/
scp -r /weekend/zookeeper-3.4.5/ slave7:/weekend/
注意:修改slave6、slave7对应/weekend/zookeeper-3.4.5/tmp/myid内容
slave6:
echo 2 > /weekend/zookeeper-3.4.5/tmp/myid
slave7:
echo 3 > /weekend/zookeeper-3.4.5/tmp/myid
2.安装配置hadoop集群(在slave1上操作)
2.1解压
tar -zxvf hadoop-2.4.1.tar.gz -C /home/hadoop/cloud/
2.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_131
export HADOOP_HOME=/home/hadoop/cloud/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /home/hadoop/cloud/hadoop-2.4.1/etc/hadoop
2.2.1修改hadoo-env.sh
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_131
2.2.2修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/cloud/hadoop-2.4.1/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>slave5:2181,slave6:2181,slave7:2181</value>
</property>
</configuration>
2.2.3修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>slave1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>slave1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>slave2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>slave2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave5:8485;slave6:8485;slave7:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/cloud/hadoop-2.4.1/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
2.2.4修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.2.5修改yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>slave3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave4</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>slave5:2181,slave6:2181,slave7:2181</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2.2.6修改slaves(slaves是指定子节点的位置,因为要在slave1上启动HDFS、在slave3启动yarn,所以slave1上的slaves文件指定的是datanode的位置,slave3上的slaves文件指定的是nodemanager的位置)
slave5
slave6
slave7
2.2.7配置免密码登陆
#首先要配置slave1到slave2、slave3、slave4、slave5、slave6、slave7的免密码登陆
#在slave1上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点,包括自己
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id slave3
ssh-copy-id slave4
ssh-copy-id slave5
ssh-copy-id slave6
ssh-copy-id slave7
#配置slave3到slave4、slave5、slave6、slave7的免密码登陆
#在slave3上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点
ssh-copy-id slave4
ssh-copy-id slave5
ssh-copy-id slave6
ssh-copy-id slave7
#注意:两个namenode之间要配置ssh免密码登陆,别忘了配置slave2到slave1的免登陆
在slave2上生产一对钥匙
ssh-keygen -t rsa
ssh-copy-id -i slave1
2.4将配置好的hadoop拷贝到其他节点(这里的hadoop是系统的用户名,slaveX是主机名,可以直接写成slave2:/weekend/)
scp -r /weekend/hadoop-2.4.1/ hadoop@slave2:/weekend/
scp -r /weekend/hadoop-2.4.1/ hadoop@slave3:/weekend/
scp -r /weekend/hadoop-2.4.1/ hadoop@slave4:/weekend/
scp -r /weekend/hadoop-2.4.1/ hadoop@slave5:/weekend/
scp -r /weekend/hadoop-2.4.1/ hadoop@slave6:/weekend/
scp -r /weekend/hadoop-2.4.1/ hadoop@slave7:/weekend/
###注意:严格按照下面的步骤
2.5启动zookeeper集群(分别在slave5、slave6、tcast07上启动zk)
cd /zookeeper-3.4.5/bin/
./zkServer.sh start
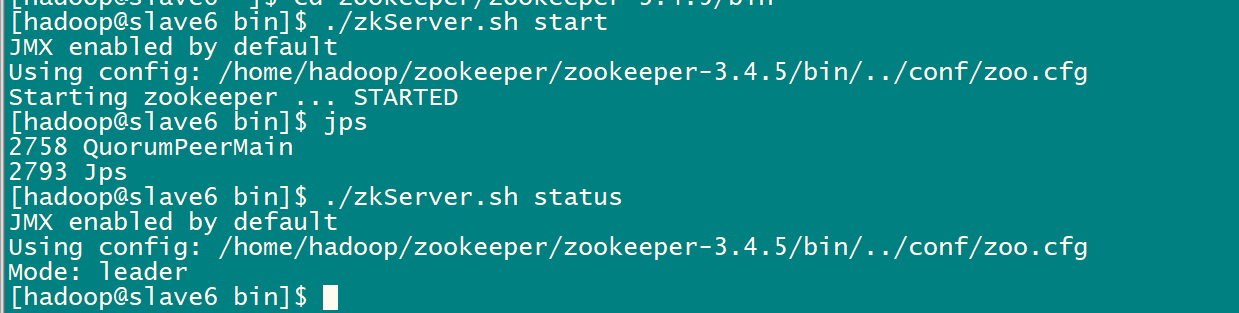
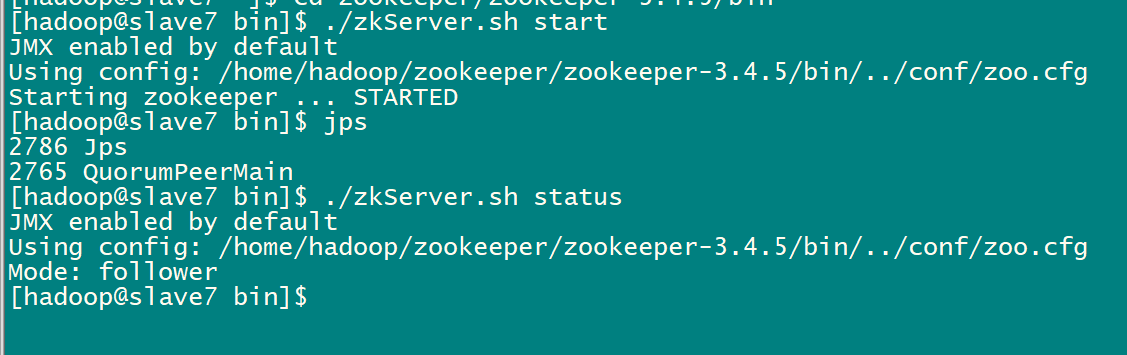
#查看状态:一个leader,两个follower
./zkServer.sh status


2.6启动journalnode(分别在在slave5、slave6、slave7上执行)
cd /hadoop-2.4.1
sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,slave5、slave6、slave7上多了JournalNode进程

2.7格式化HDFS
#在slave1上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/cloud/hadoop-2.4.1/tmp,然后将/cloud/hadoop-2.4.1/tmp拷贝到slave2的/cloud/hadoop-2.4.1/下。为了保证两个namenode保持在一致的状态下。如果是第二次启动就是说已经将namenode格式化了,第二次就不需要在格式化了
scp -r tmp/ slave2:/home/hadoop/app/hadoop-2.4.1/
2.8格式化ZKFC(在slave1上执行即可)(同理第二次也不需要)
hdfs zkfc -formatZK
2.9启动HDFS(在slave1上执行)
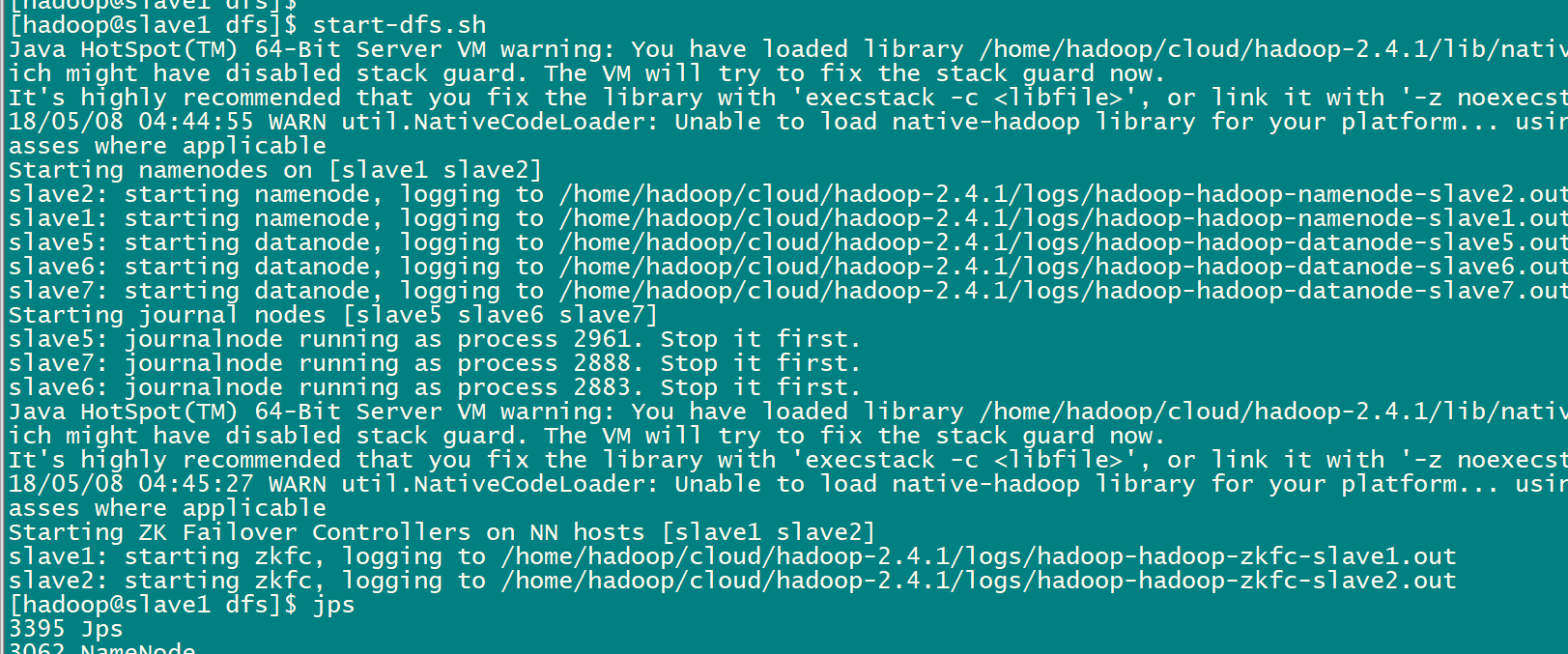
sbin/start-dfs.sh
启动成功后的情况slave1上:
2.10启动YARN(#####注意#####:是在slave3上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
sbin/start-yarn.sh
到此,hadoop-2.4.1配置完毕,可以统计浏览器访问:
http://192.168.202.20:50070
NameNode 'slave1:9000' (active)
http://192.168.202.30:50070
NameNode 'slave2:9000' (standby)
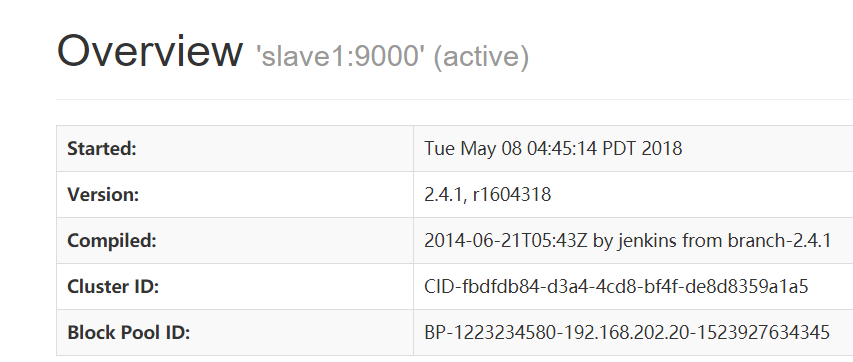
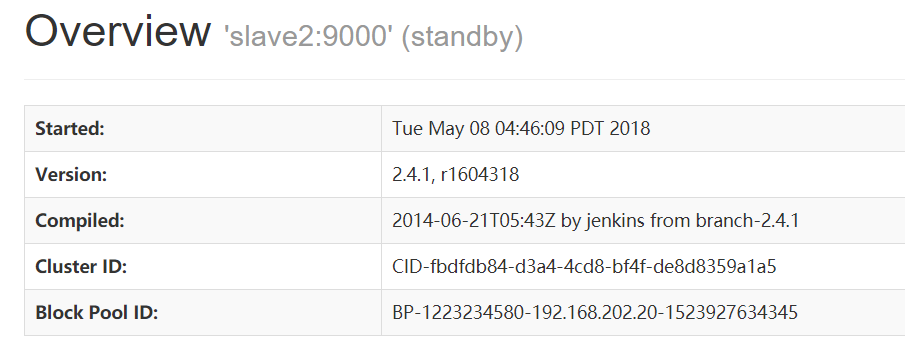
验证HDFS HA
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然后再kill掉active的NameNode
kill -9 <pid of NN>
通过浏览器访问:http://192.168.1.202:50070
NameNode 'slave2:9000' (active)
这个时候slave2上的NameNode变成了active
在执行命令:
hadoop fs -ls /
-rw-r--r-- 3 root supergroup 1926 2014-02-06 15:36 /profile
刚才上传的文件依然存在!!!
手动启动那个挂掉的NameNode
sbin/hadoop-daemon.sh start namenode
通过浏览器访问:http://192.168.1.201:50070
NameNode 'slave1:9000' (standby)
验证YARN:
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar wordcount /profile /out
OK,大功告成!!!
测试集群工作状态的一些指令 :
bin/hdfs dfsadmin -report 查看hdfs的各节点状态信息
bin/hdfs haadmin -getServiceState nn1 获取一个namenode节点的HA状态
sbin/hadoop-daemon.sh start namenode 单独启动一个namenode进程
./hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
Hadoop2.41的HA的配置与启动的更多相关文章
- 国内第一篇详细讲解hadoop2的automatic HA+Federation+Yarn配置的教程
前言 hadoop是分布式系统,运行在linux之上,配置起来相对复杂.对于hadoop1,很多同学就因为不能搭建正确的运行环境,导致学习兴趣锐减.不过,我有免费的学习视频下载,请点击这里. hado ...
- hadoop2的automatic HA+Federation+Yarn配置的教程
前言 hadoop是分布式系统,运行在linux之上,配置起来相对复杂.对于hadoop1,很多同学就因为不能搭建正确的运行环境,导致学习兴趣锐减.不过,我有免费的学习视频下载,请点击这里. hado ...
- hadoop2.5.0 HA高可用配置
hadoop2.5.0 HA配置 1.修改hadoop中的配置文件 进入/usr/local/src/hadoop-2.5.0-cdh5.3.6/etc/hadoop目录,修改hadoop-env.s ...
- Hadoop2.5.2+HA+zookeeper3.4.6详细配置过程
心血之作,在熟悉hadoop2架构的过程耽误了太长时间,在搭建环境过程遇到一些问题,这些问题一直卡在那儿,不得以解决,耽误了时间.最后,千寻万寻,把问题解决,多谢在过程提供帮助的大侠.这篇文章中,我也 ...
- Hadoop-1.2.1 升级到Hadoop-2.6.0 HA
Hadoop-1.2.1到Hadoop-2.6.0升级指南 作者 陈雪冰 修改日期 2015-04-24 版本 1.0 本文以hadoop-1.2.1升级到hadoop-2.6.0 Z ...
- ubuntu + hadoop2.5.2分布式环境配置
ubuntu + hadoop2.5.2分布式环境配置 我之前有详细写过hadoop-0.20.203.0rc1版本的环境搭建 hadoop学习笔记——环境搭建 http://www.cnblogs. ...
- Hadoop2.0 Namenode HA实现方案
Hadoop2.0 Namenode HA实现方案介绍及汇总 基于社区最新release的Hadoop2.2.0版本,调研了hadoop HA方面的内容.hadoop2.0主要的新特性(Hadoop2 ...
- Hadoop2.2.0分布式安装配置详解[2/3]
前言 本文主要通过对hadoop2.2.0集群配置的过程加以梳理,所有的步骤都是通过自己实际测试.文档的结构也是根据自己的实际情况而定,同时也会加入自己在实际过程遇到的问题.搭建环境过程不重要,重要点 ...
- 初识Hadoop一,配置及启动服务
一.Hadoop简介: Hadoop是由Apache基金会所开发的分布式系统基础架构,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS:Hadoo ...
随机推荐
- BeautifulSoup详解
BeautifulSoup BeautifulSoup是一个模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后遍可以使用他提供的方法进行快速查找指定元素,从而使得在HTML或XM ...
- tomcat启动非常慢;连接oracle数据库失败,jdbc错误日志提示connection reset;测试主机间网络互通及数据库端口都正常
[判断确认:这时候大家可能要去检查一下/dev/random 这个设备档案.可以用cat /dev/random 来看它的内容,如果你发现他一直没显示任何内容﹝可能是乱码数字之类的﹞,那就是它出问 ...
- Django单元测试简明实践
1.准备数据模式,Django空库测试需要所有相关数据模式必须在Django中定义,说白了,model不能有managed=Fasle,为了解决这个问题,你必须得有一个managed全部为True的S ...
- Python 3 利用 Dlib 19.7 实现摄像头人脸识别
0.引言 利用python开发,借助Dlib库捕获摄像头中的人脸,提取人脸特征,通过计算欧氏距离来和预存的人脸特征进行对比,达到人脸识别的目的: 可以自动从摄像头中抠取人脸图片存储到本地: 根据抠取的 ...
- Python 函数和相关用法笔记
python中%r和%s的区别 总结:%r打印时能够重现它所代表的对象 __str__和__repr__的用法
- 实现对ASP.NETMvc及Asp.NetCore的权限控制
AccessControlHelper Build Status Intro 由于项目需要,需要在 基于 Asp.net mvc 的 Web 项目框架中做权限的控制,于是才有了这个权限控制组件. 项目 ...
- Code Review Checklist
左按:当年需要一份详细的代码评审清单作参考,翻译了此文. 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] General Code Smoke Test 通用测试 Comm ...
- restrict关键字(暗示编译器,某个指针指向的空间,只能从该指针访问)
我们希望某个对象(内存空间)不被修改的通常做法是什么?声明该空间的const类型,但是这样真的可以吗?是不是的,由于const空间对象的指针是可以付给一个非const值指针的.所以这仍然无法不让该空间 ...
- PAT1037:Magic Coupon
1037. Magic Coupon (25) 时间限制 100 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue The magi ...
- 附录C--拉格朗日对偶性
1.原始问题 假设$f(x)$,$c_i(x)$,$h_j(x)$是定义在$R^n$上的连续可微函数,$x \in R^n$.考虑以下三类优化问题. 1.无约束的优化问题: \begin{align* ...