Coursera-AndrewNg(吴恩达)机器学习笔记——第二周
一.多变量线性回归问题(linear regression with multiple variables)
- 搭建环境Octave
Windows的安装包可由此链接获取:https://ftp.gnu.org/gnu/octave/windows/,可以选择一个比较新的版本进行安装,本人win10操作系统,安装版本4.2.1,没有任何问题。注意不要安装4.0.0这个版本。当然安装MATLAB也是可以的,我两个软件都安装了,在本课程中只使用Octave就已经足够用了! - 符号标记:n(样本的特征数/属性数目),
 表示第i个训练样本的第j个特征。样本可能有多个属性值,在房价预测案例中,可能有多种因素如房屋大小、楼层、装修程度等共同决定最终房价。
表示第i个训练样本的第j个特征。样本可能有多个属性值,在房价预测案例中,可能有多种因素如房屋大小、楼层、装修程度等共同决定最终房价。 预测函数(Hypothesis):hθ(x)=θ0+θ1x1+θ2x2+……+θnxn,记x0=1(
 )
)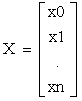
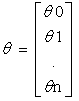
所以预测函数使用矩阵相乘的形式可写为:hθ(x)=ΘTX.代价函数(Cost Function)形式:其中参数θn的数目和特征数n相同。
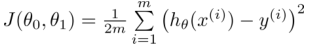
- 梯度下降算法:(注意同时更新所有θ值)
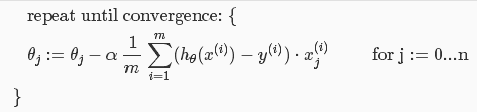
- Feature Scaling(特征缩放):确保各个特征的取值近似,否则收敛速度会很慢。建议:将所有特征取值近似缩放到[-1,1]之间,当然也不必特别精准,只是为了梯度下降运算速度更快。
方法(Mean Normalization):xi=(xi-μi)/si,μi是xi的平均值,si是xi的标准差或者是xi的范围(xmax-xmin)。x0不需要进行特征缩放,因为我们在前面将x0记为1。 - 学习速率α:α过大,梯度下降难以收敛,代价函数J(θ)甚至会变大。α过小,梯度下降收敛速度慢。如何判断已经收敛:两次迭代代价函数J(θ)差值是否小于某一个阈值(不好找)。
- 正规方程(Normal Equation):求解θ的解析方法,该方法不需要做特征缩放。
公式如下:θ=(XTX)-1XTY Octave代码:pinv(X`*X)*X`*Y,或者使用inv函数
正规方程和梯度下降方法求解θ特点:不需要选择学习速率α,不需要进行迭代求解。当特征数目n>106很大时,梯度下降可以很好的求解,但是正规方程的求解速度将会很慢。
当存在冗余的特征,十分的接近的特征或者特征过多(n>m)时,XTX会不可逆,这时使用Octave的pinv函数依旧可以求出结果。
二.Octave的简单使用
变量的赋值
%后内容表示注释 ~=为不等号 &&逻辑与 ||逻辑或 xor( , )逻辑异或 format long/short控制输出格式
PSI('>>'); %简化命令行显示
a=3 %变量赋值
a=3; %末尾;可以抑制打印输出
disp(a); %打印变量值,或者直接输出字母a
disp(sprintf('2 decimals: %0.2f',a)) %类似C语言的形式输出两位小数
A=[1 2;3 4;5 6] %定义一个矩阵
V=1:0.1:2 %定义一个1行11列矩阵
C=2*ones(2,3) %定义一个2行3列的矩阵,所有元素都是2
W=zeros(1,3) %定义一个1行3列的矩阵,所有元素都是0
rand(3,3) %随机赋值3*3矩阵
randn(3,3) %随机赋值3*3矩阵,符合高斯分布,平均值为0,方差为1
w=-6+sqrt(9)*(randn(1,1000)); 变量w赋值,w是一个均值为-6,方差为3的矩阵
hist(w) %画直方图,hist为统计函数,默认统计10个区间中,出现w的个数,纵轴值为个数
eye(4)%设置4阶单位矩阵
- 数据的处理
pwd命令显示当前路径 cd命令转换路径 ls命令显示文件列表 who命令显示工作空间中的变量 whos命令显示变量的详细信息
clear features X删除变量X 导入数据命令load featuresX.dat或load('featuresX.dat') clear命令清空工作空间中所有变量
size(A) %求矩阵的维数,返回的值也是一个矩阵,也可用于求向量的维数
length(v) %求向量的维数,一般不用于矩阵
v=priceY(1:10) %将priceY中前10个数据存入v中
save hello.mat v; %将v的数据存入硬盘中,.mat格式文件按照二进制形式存取,占用空间小
save hello.txt v -ascii %将v中的数据按照字符形式进行存储
A(3,2) %矩阵A3行2列的元素值
A(2,:) %矩阵A2行上所有元素的值
A([1 3],:) %矩阵A中1,3行所有元素的值
A(:,2)=[10;11;12] %对矩阵A第二列所有元素重新赋值
A=[A,[1;2;3]] %矩阵A新增一列
A(:) %将矩阵A中元素按列拼接,输出一个向量
C=[A B] %将矩阵A,B左右拼接
C=[A;B] %将矩阵A,B上下拼接
A.*B %矩阵A,B同阶,对应元素相乘
A.^2 %矩阵A中元素做平方
1./A %矩阵A中元素取到数
log(v) %求自然对数,e为底 exp(v) %求指数 abs(v) %求绝对值 A`为A的转置 pinv(A)为A的逆
val=max(a) %返回向量中的最大值
[val ind]=max(a) %返回向量中的最大值和最大值的索引
a<3 %该操作对向量中的元素逐个进行比较 find(a<3) %显示满足条件的下标
A=magic(3)%生成一个3*3维的magic matrix,每行每列值的和相等
[r,c]=find(A>7) %返回满足条件的行列向量索引
sum(a) %将向量所有元素值相加 prod(a) %求向量所有元素值的乘积 floor(a) %将所有元素指向下取整 ceil(a) %将所有元素值向上取整
max(A,[],1) %求每列最大值 max(A,[],2) %求每行最大值 max(max(A)) %求矩阵A中的最大值,也可写为max(A(:))
sum(A,1) %求矩阵A每列的和 sum(A,2) %求矩阵A每行的和
sum(sum(A.*eye(9))) %计算对角线值的和 sum(sum(A.*flipud(eye(9)))) %计算反向对角线的和
绘制数据




- 语句和函数
v=zeros(,)
for i=:, %for语句
v(i)=^i;
end; i=1;
while i<=5, %while语句
v(i)=100;
i=i+1;
end; i=1;
while true, %break语句
v(i)=999;
i=i+1;
if i==6,
break;
end;
end; v(1)=2;
if v(1)==1, %if-elseif-if语句
disp('the value is one');
elseif v(1)==2,
disp('the value is two');
else
disp('the value is not one or two')
end;
- 函数:创建文件,以函数名来命名,以.m后缀结尾。
- 创建Octave搜索路径:% Octave search path (advanced/optimal)
addpath('c:\Users\ang\Desktop')
函数文件在该路径下,自动检索。 - Octave语法中函数可以返回多个值。
- 向量化:建议计算时进行向量计算,不使用循环。
Coursera-AndrewNg(吴恩达)机器学习笔记——第二周的更多相关文章
- Coursera-AndrewNg(吴恩达)机器学习笔记——第二周编程作业
一.准备工作 从网站上将编程作业要求下载解压后,在Octave中使用cd命令将搜索目录移动到编程作业所在目录,然后使用ls命令检查是否移动正确.如: 提交作业:提交时候需要使用自己的登录邮箱和提交令牌 ...
- Coursera-AndrewNg(吴恩达)机器学习笔记——第二周编程作业(线性回归)
一.准备工作 从网站上将编程作业要求下载解压后,在Octave中使用cd命令将搜索目录移动到编程作业所在目录,然后使用ls命令检查是否移动正确.如: 提交作业:提交时候需要使用自己的登录邮箱和提交令牌 ...
- Coursera-AndrewNg(吴恩达)机器学习笔记——第一周
一.初识机器学习 何为机器学习?A computer program is said to learn from experience E with respect to some task T an ...
- 吴恩达机器学习笔记(六) —— 支持向量机SVM
主要内容: 一.损失函数 二.决策边界 三.Kernel 四.使用SVM (有关SVM数学解释:机器学习笔记(八)震惊!支持向量机(SVM)居然是这种机) 一.损失函数 二.决策边界 对于: 当C非常 ...
- Machine Learning|Andrew Ng|Coursera 吴恩达机器学习笔记
Week1: Machine Learning: A computer program is said to learn from experience E with respect to some ...
- Machine Learning|Andrew Ng|Coursera 吴恩达机器学习笔记(完结)
Week 1: Machine Learning: A computer program is said to learn from experience E with respect to some ...
- 吴恩达机器学习笔记 —— 19 应用举例:照片OCR(光学字符识别)
http://www.cnblogs.com/xing901022/p/9374258.html 本章讲述的是一个复杂的机器学习系统,通过它可以看到机器学习的系统是如何组装起来的:另外也说明了一个复杂 ...
- [吴恩达机器学习笔记]12支持向量机5SVM参数细节
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.5 SVM参数细节 标记点选取 标记点(landma ...
- [吴恩达机器学习笔记]12支持向量机3SVM大间距分类的数学解释
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.3 大间距分类背后的数学原理- Mathematic ...
随机推荐
- Java实现堆的封装,进行插入,调整,删除堆顶以完成堆排序实例
简介 堆对于排序算法是一个比较常用的数据结构,下面我就使用Java语言来实现这一算法 首先,我们需要知道堆的数据结构的形式,其实就是一个特殊的二叉树.但是这个二叉树有一定的特点,除了是完全二叉树以外, ...
- JAVA集合类——难得的总结
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/41346969 以下资料是在学习中总结出来的,希望对你有所帮 ...
- Linux Shell 脚本攻略学习--四
linux中(chattr)创建不可修改文件的方法 在常见的linux扩展文件系统中(如ext2.ext3.ext4等),可以将文件设置为不可修改(immutable).某些文件属性可帮助我们将文件设 ...
- AngularJS进阶(二十八)解决AngualrJS页面刷新导致异常显示问题
解决AngualrJS页面刷新导致异常显示问题 绪 俗话说,细节决定成败,编程亦是如此.编程过程中我们可能会不自觉的忽视一些细节问题,殊不知,这些细节正是导致页面显示出现问题的地方.今略举一例,与君共 ...
- How Many Processes Should Be Set For The Receiving Transaction Manager (RTM)
In this Document Goal Solution References APPLIES TO: Oracle Inventory Management - Version 10 ...
- Material Design之NavigationView和DrawerLayout实现侧滑菜单栏
本文将介绍使用Google最新推出规范式设计中的NavigationView和DrawerLayout结合实现侧滑菜单栏效果,NavigationView是android-support-design ...
- MulticastSocket 使用
/** * ServerMulticastSocketTest.java * 版权所有(C) 2014 * 创建者:cuiran 2014-1-9 下午3:22:01 */ package com.u ...
- 程序员的视角:java 线程
在我们开始谈线程之前,不得不提下进程. 无论进程还是线程都是很抽象的概念,有一个关于进程和线程很形象的比喻能帮我们更好的理解. 进程就像个房子,房子是一个包含了特定属性的容器,例如空间大小.卧室数量等 ...
- Order&Shipping Transactions Status Summary
Order&Shipping Transactions Status Summary Step Order Header Status Order Line Status Order Flow ...
- iOS监听模式之KVO、KVC的高阶应用
KVC, KVO作为一种魔法贯穿日常Cocoa开发,笔者原先是准备写一篇对其的全面总结,可网络上对其的表面介绍已经够多了,除去基本层面的使用,笔者跟大家谈下平常在网络上没有提及的KVC, KVO进阶知 ...