【NIFI】 Apache NiFI 集群搭建
NiFI 集群介绍
NiFi集群架构
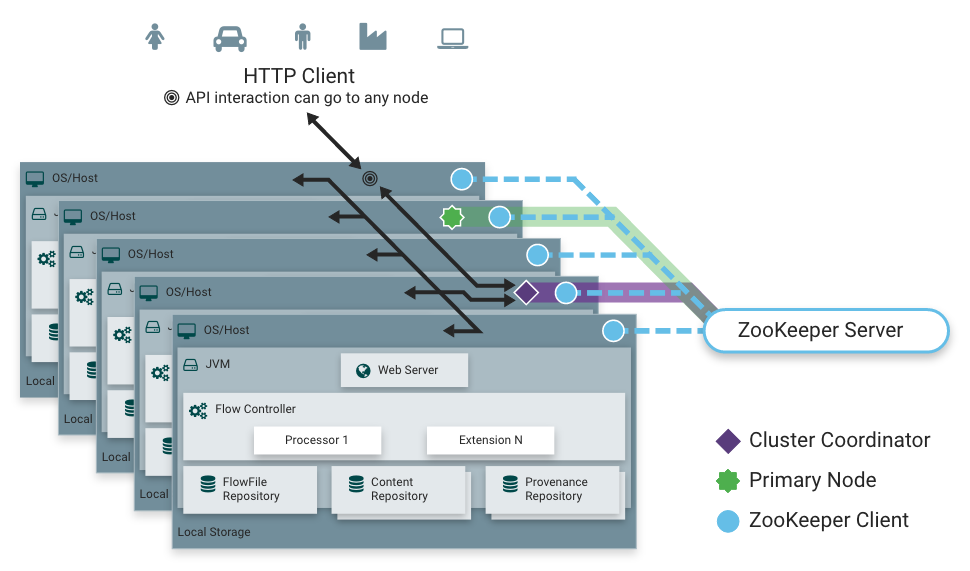
NiFi采用Zero-Master Clustering范例。集群中的每个节点对数据执行相同的任务,但每个节点都在不同的数据集上运行。其中一个节点自动选择(通过Apache ZooKeeper)作为集群协调器。然后,群集中的所有节点都会向此节点发送心跳/状态信息,并且此节点负责断开在一段时间内未报告任何心跳状态的节点。此外,当新节点选择加入群集时,新节点必须首先连接到当前选定的群集协调器,以获取最新流。如果群集协调器确定允许该节点加入(基于其配置的防火墙文件),则将当前流提供给该节点,并且该节点能够加入群集,假设节点的流副本与群集协调器提供的副本匹配。如果节点的流配置版本与群集协调器的版本不同,则该节点将不会加入群集。
NiFI 集群搭建
环境
1、系统:CentOS 7.4
2、Java环境:JDK8
单机NIFI搭建,请参考:【NIFI】 Apache NiFI 安装及简单的使用
学会搭建ZooKeeper集群,更加容易理解NIFI集群搭建,请参考:【ZooKeeper】ZooKeeper安装及简单操作
使用NiFi集成的zookeeper
由于本例搭建三个节点的集群,且在一台机器上搭建,所以不同节点的相同功能端口会不同,如果搭建在三台机器上,IP不同,那么不同节点的相同功能端口可以相同
1、准备三个单机NIFI实例,如下:

2、编辑实例中,conf/zookeeper.properties文件,不同节点改成对应内容,内容如下:
# 1节点2181,2节点2182,1节点2183
clientPort=12181
initLimit=10
autopurge.purgeInterval=24
syncLimit=5
tickTime=2000
dataDir=./state/zookeeper
autopurge.snapRetainCount=30 # 不同机器使用不同IP
server.1=127.0.0.1:12888:13888
server.2=127.0.0.1:14888:15888
server.3=127.0.0.1:16888:17888
3、在单个实例中新建文件夹,${NIFI_HOME}/state/zookeeper,在此文件夹中新建文件myid,且输入内容如下:
1
节点2内容为:2,节点3内容为:3

4、编辑节点conf/nifi.properties文件,修改内容如下:
####################
# State Management #
####################
nifi.state.management.configuration.file=./conf/state-management.xml
nifi.state.management.provider.local=local-provider
nifi.state.management.provider.cluster=zk-provider
# 指定此NiFi实例是否应运行嵌入式ZooKeeper服务器,默认是false
nifi.state.management.embedded.zookeeper.start=true
nifi.state.management.embedded.zookeeper.properties=./conf/zookeeper.properties # web properties #
nifi.web.war.directory=./lib
# HTTP主机。默认为空白
nifi.web.http.host=127.0.0.1
# HTTP端口。默认值为8080
nifi.web.http.port=18001 # cluster node properties (only configure for cluster nodes) #
# 如果实例是群集中的节点,请将此设置为true。默认值为false
nifi.cluster.is.node=true
# 节点的完全限定地址。默认为空白
nifi.cluster.node.address=127.0.0.1
# 节点的协议端口。默认为空白
nifi.cluster.node.protocol.port=28001 # 指定在选择Flow作为“正确”流之前等待的时间量。如果已投票的节点数等于nifi.cluster.flow.election.max.candidates属性指定的数量,则群集将不会等待这么长时间。默认值为5 mins
nifi.cluster.flow.election.max.wait.time= mins
# 指定群集中所需的节点数,以便提前选择流。这允许群集中的节点避免在开始处理之前等待很长时间,如果我们至少达到群集中的此数量的节点
nifi.cluster.flow.election.max.candidates=1 # cluster load balancing properties #
nifi.cluster.load.balance.host=
nifi.cluster.load.balance.port=16342 # zookeeper properties, used for cluster management #
# 连接到Apache ZooKeeper所需的连接字符串。这是一个以逗号分隔的hostname:port对列表
nifi.zookeeper.connect.string=127.0.0.1:12181,127.0.0.1:12182,127.0.0.1:12183
nifi.zookeeper.connect.timeout=3 secs
nifi.zookeeper.session.timeout=3 secs
nifi.zookeeper.root.node=/nifi
节点2,节点3内容跟节点1相同,只是nifi.web.http.port,nifi.cluster.node.protocol.port,nifi.cluster.load.balance.port,这三个端口区分开来,避免端口重复
5、编辑实例conf/state-management.xml文件,内容如下:
<cluster-provider>
<id>zk-provider</id>
<class>org.apache.nifi.controller.state.providers.zookeeper.ZooKeeperStateProvider</class>
<property name="Connect String">127.0.0.1:12181,127.0.0.1:12182,127.0.0.1:12183</property>
<property name="Root Node">/nifi</property>
<property name="Session Timeout">10 seconds</property>
<property name="Access Control">Open</property>
</cluster-provider>
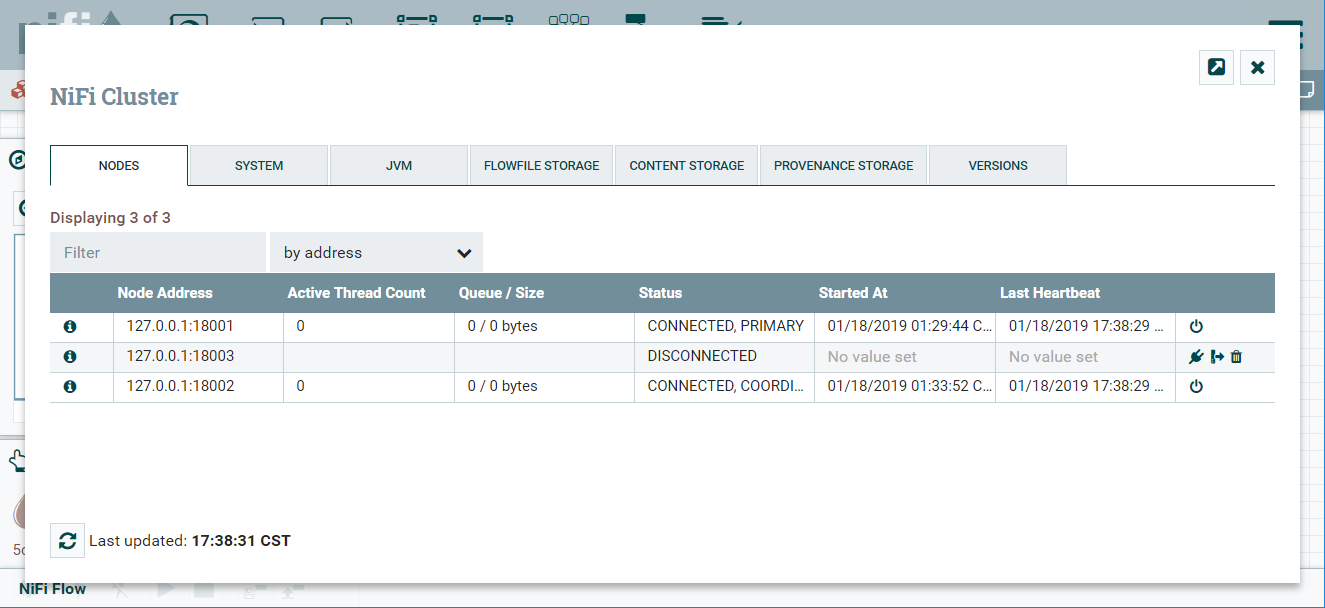
6、启动三个实例,浏览器输入:127.0.0.1:18001,访问即可
注意:如果不是在本机上访问,需要把配置中,配置本机IP(Linux命令:ifconfig)
nifi.web.http.host=192.168.1.2
nifi.cluster.node.address=192.168.1.2
使用外部zookeeper
1、开起集群Zookeeper,参考【ZooKeeper】ZooKeeper安装及简单操作
2、准备三个单机NIFI实例
3、实例中,conf/zookeeper.properties文件,可以不用编辑
4、编辑节点conf/nifi.properties文件
####################
# State Management #
####################
nifi.state.management.configuration.file=./conf/state-management.xml
nifi.state.management.provider.local=local-provider
nifi.state.management.provider.cluster=zk-provider
# 指定此NiFi实例是否应运行嵌入式ZooKeeper服务器,默认是false
# 连接外部的时候,设置为false
nifi.state.management.embedded.zookeeper.start=false
nifi.state.management.embedded.zookeeper.properties=./conf/zookeeper.properties # web properties #
nifi.web.war.directory=./lib
# HTTP主机。默认为空白
nifi.web.http.host=127.0.0.1
# HTTP端口。默认值为8080
nifi.web.http.port=18001 # cluster node properties (only configure for cluster nodes) #
# 如果实例是群集中的节点,请将此设置为true。默认值为false
nifi.cluster.is.node=true
# 节点的完全限定地址。默认为空白
nifi.cluster.node.address=127.0.0.1
# 节点的协议端口。默认为空白
nifi.cluster.node.protocol.port=28001 # 指定在选择Flow作为“正确”流之前等待的时间量。如果已投票的节点数等于nifi.cluster.flow.election.max.candidates属性指定的数量,则群集将不会等待这么长时间。默认值为5 mins
nifi.cluster.flow.election.max.wait.time= mins
# 指定群集中所需的节点数,以便提前选择流。这允许群集中的节点避免在开始处理之前等待很长时间,如果我们至少达到群集中的此数量的节点
nifi.cluster.flow.election.max.candidates=1 # cluster load balancing properties #
nifi.cluster.load.balance.host=
nifi.cluster.load.balance.port=16342 # zookeeper properties, used for cluster management #
# 连接到Apache ZooKeeper所需的连接字符串。这是一个以逗号分隔的hostname:port对列表
# 连接外部的时候使用外部ZooKeeper连接地址
nifi.zookeeper.connect.string=127.0.0.1:12181,127.0.0.1:12182,127.0.0.1:12183
nifi.zookeeper.connect.timeout=3 secs
nifi.zookeeper.session.timeout=3 secs
nifi.zookeeper.root.node=/nifi
5、编辑实例conf/state-management.xml文件,内容如下:
<cluster-provider>
<id>zk-provider</id>
<class>org.apache.nifi.controller.state.providers.zookeeper.ZooKeeperStateProvider</class>
<!-- 使用外部zookeeper连接地址 -->
<property name="Connect String">127.0.0.1:12181,127.0.0.1:12182,127.0.0.1:12183</property>
<property name="Root Node">/nifi</property>
<property name="Session Timeout">10 seconds</property>
<property name="Access Control">Open</property>
</cluster-provider>
6、启动三个实例,浏览器输入:127.0.0.1:18001,访问即可
注意:如果不是在本机上访问,需要把配置中,配置本机IP(Linux命令:ifconfig)
nifi.web.http.host=192.168.1.2
nifi.cluster.node.address=192.168.1.2
问题排查
1、查看nifi日志
$NIFI_HOME/log/nifi-app.log
2、查看官网文档
http://nifi.apache.org/docs.html ==》 Admin Guide ==》 搜索cluster或其他关键字
【NIFI】 Apache NiFI 集群搭建的更多相关文章
- Centos下Apache+Tomcat集群--搭建记录
一.目的 利用apache的mod_jk模块,实现tomcat集群服务器的负载均衡以及会话复制,这里用到了<Cluster>. 二.环境 1.基础:3台主机,系统Centos6.5,4G内 ...
- Tomcat:基于Apache+Tomcat的集群搭建
根据Tomcat的官方文档说明可以知道,使用Tomcat配置集群需要与其它Web Server配合使用才可以完成,典型的有Apache和IIS. 这里就使用Apache+Tomcat方式来完成基于To ...
- nginx+apache+php+mysql服务器集群搭建
由于需要搭建了一个基本的服务器集群.具体的配置方案先不说了,到有时间的时候再介绍.下面介绍下整 个方案的优点. 我总共准备了四台阿里云的主机,架设分别是A,B1,B2,C,A在集群的最前面,B1和B2 ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- (三)Spark-Hadoop集群搭建-Java&Python版Spark
Spark-Hadoop集群搭建 视频教程: 1.优酷 2.YouTube 配置java 启动ftp [root@master ~]# /etc/init.d/vsftpd restart 关闭 vs ...
- 分布式架构中一致性解决方案——Zookeeper集群搭建
当我们的项目在不知不觉中做大了之后,各种问题就出来了,真jb头疼,比如性能,业务系统的并行计算的一致性协调问题,比如分布式架构的事务问题, 我们需要多台机器共同commit事务,经典的案例当然是银行转 ...
- kafka集群搭建和使用Java写kafka生产者消费者
1 kafka集群搭建 1.zookeeper集群 搭建在110, 111,112 2.kafka使用3个节点110, 111,112 修改配置文件config/server.properties ...
- Kafka 0.9+Zookeeper3.4.6集群搭建、配置,新Client API的使用要点,高可用性测试,以及各种坑 (转载)
Kafka 0.9版本对java client的api做出了较大调整,本文主要总结了Kafka 0.9在集群搭建.高可用性.新API方面的相关过程和细节,以及本人在安装调试过程中踩出的各种坑. 关于K ...
- 28.zookeeper单机(Standalones模式)和集群搭建笔记
zookeeper单机(Standalones模式)和集群搭建: 前奏: (1).zookeeper也可以在windows下使用,和linux一样可以单机也可以集群,具体就是解压zookeeper-3 ...
随机推荐
- frist Django app — 三、 View
前面已经说过了Django中model的一些用法,包括orm,以及操作的api,接下来就是搭一些简单的界面学习view——Django中的view.主要介绍以下两个方面: url映射 请求处理 模板文 ...
- FLV 格式导入 视频
- Linux安装Intel Threading Building Blocks(TBB)
编译安装: wget https://codeload.github.com/01org/tbb/tar.gz/2019_U3 tar zxvf 2019_U3 cd tbb-2019_U3 make ...
- card布局解决复杂操作的布局问题
一直不是很待见直接使用card布局,直到对于一些稍微复杂点的业务, 通过border布局和弹窗体的方式解决特别费劲之后,才想起了card布局, 发现card布局真是一个很好的解决办法. 那个使用起来很 ...
- html5下F11全屏化的几点注意
1.实现全屏化 var docElm = document.documentElement; //W3C if (docElm.requestFullscreen) { docElm.requestF ...
- Ubuntu 18.04 安装部署Net Core、Nginx全过程
Ubuntu 18.04 安装部署Net Core.Nginx全过程 环境配置 Ubuntu 18.04 ,Nginx,.Net Core 2.1, Let's Encrypt 更新系统 sudo a ...
- Codeforces Round #436 C. Bus
题意:一辆车在一条路上行驶,给你路的总长度a,油箱的容量b,加油站在距离起点的距离f,以及需要走多少遍这条路k(注意:不是往返) 问你最少加多少次油能走完. Examples Input 6 9 2 ...
- Vue和后台交互的方式
1 vue-resource https://segmentfault.com/a/1190000007087934 2 axios 3 ajax
- 认识socket
socket socket也称套接字,网络编程的基础.一般情况下我不喜欢直接去说socket的函数都是怎么用的,那个很多人都写出来了,而且肯定比我好的有的是. 但是今天想写的是我的理解中,产生sock ...
- Hillstone防火墙sslvpn配置与使用
1.山石的sslvpn称为Secure Connect VPN,即scvpn. 2.WEB界面登陆防火墙,“用户”,“AAA服务器”,新建用户: 3.定义源IP池 即用户通过sslvpn拨号成功后获取 ...