python 精华梳理(已理解并手写)--全是干货--已结
基础部分
map,reduce,filter,sort,推导式,匿名函数lambda , 协程,异步io,上下文管理
自定义字符串转数字方法一不使用reduce
import re
def str2int(s):
if not re.match(r'^\d+$',s):
raise ValueError('请检查数字格式是否正确')
else:
digital={'0':0,"1":1,"2":2,"3":3,"4":4,"5":5,"6":6,"7":7,"8":8,"9":9}
int_list = list(map(lambda k:digital[k] or 0,s))
sum=0
for i,v in enumerate(int_list):
sum+=v*(10**(len(int_list)-i-1))
return sum
print(str2int('456'))
自定义字符串转数字方法二使用reduce
from functools import reduce
import re
def str2int(s):
if not re.match(r'^\d+$',s):
raise ValueError('请检查数字格式是否正确')
else:
digital={'0':0,"1":1,"2":2,"3":3,"4":4,"5":5,"6":6,"7":7,"8":8,"9":9}
int_list = list(map(lambda k:digital[k] or 0,s))
return reduce(lambda a,b:a+b,[v*(10**(len(int_list)-i-1))for i,v in enumerate(int_list)])
print(str2int('456'))
import re
from functools import reduce
def digital(c):
return {'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9}.get(c,0)
def str2int(s):
if not re.match(r'^\d+$',s):
raise TypeError('类型不是数字!')
return reduce(lambda x,y:x+y,[v*(10**i) for i,v in enumerate(list(map(lambda c:digital(c),s))[::-1])])
print('%s-->%d' %(type(str2int('123')),str2int('123')))
assert isinstance(str2int('123'),int)
<class 'int'>-->123
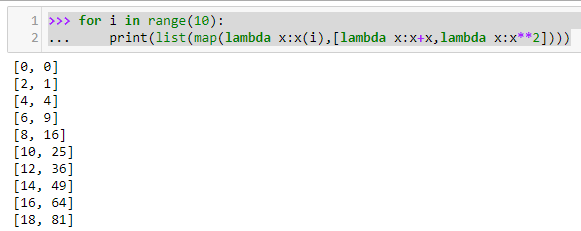
让人眼前一亮的匿名函数
>>> for i in range(10):
... print(list(map(lambda x:x(i),[lambda x:x+x,lambda x:x**2])))
列表推导式与 filter 相互等价
[i for i in range(30) if i%2==0]
list(filter(lambda x:x%2==0,range(30)))
# 0,1,2,3,4,5...
# 累加
accumulate = lambda x:x+fib(x-1) if x!=0 else 0
accumulate(3)
# 0,1,2,3,4,5...
# 阶乘
factorical = lambda x:x*factorical(x-1) if x!=1 else 1
factorical(6)
# 斐波拉契数列
# 0,1,1,2,3,5...
fib = lambda x: 1 if x==1 or x==2 else fib(x-1)+fib(x-2)
fib(6)
#生成器斐波拉契
def fib(x):
n=0
a,b = 0,1
while n<x:
b,a = a,a+b
yield a
n+=1
for i in fib(6):
print(i,end=',')
#协程写斐波拉契
>>> def fib():
... a,b = 0,1
... r = 'start...'
... yield r
... while True:
... yield b
... a,b = b,a+b
...
>>> f = fib()
>>> f.send(None)
'start...'
>>> for i in range(1,10):
... print('index {}-->{}'.format(i,f.send(i)))
...
index 1-->1
index 2-->1
index 3-->2
index 4-->3
index 5-->5
index 6-->8
index 7-->13
index 8-->21
index 9-->34
>>> f.close()
异步 io
>>> import asyncio
>>> @asyncio.coroutine
... def say(greet_str):
... print(greet_str)
... r = yield from asyncio.sleep(1)
... print(greet_str,'again')
... print('r:{}'.format(r))
...
>>> loop = asyncio.get_event_loop()
>>> tasks = [say('hello world!'),say('hello frank')]
>>> loop.run_until_complete(asyncio.wait(tasks))
hello frank
hello world!
hello frank again
r:None
hello world! again
r:None
({<Task finished coro=<say() done, defined at <stdin>:1> result=None>, <Task finished coro=<say() done, defined at <stdin>:1> result=None>}, set())
>>> loop.close()
3.5 及以后
把@asyncio.coroutine替换为async;
把yield from替换为await。
通过async定义的协程被称为原生协程跟
通过@asyncio.coroutine定义的协程函数被称为基于生成器的协程
两者不是一个概念
查找文件名包含某字符串的文件并输出器文件名
import os
def findstr_in_file(path):
for child in os.listdir(path):
qualified_child = os.path.join(path,child)
if os.path.isdir(qualified_child):
tmp = findstr_in_file(qualified_child)
for item in tmp:
yield item
else:
yield qualified_child
for name in findstr_in_file('.'):
if 'diabetes' in name:
print(name)
os os.path 学习
#
os.environ.get('PATH')
if 'Linux' in os.name:
os.system('clear')
elif 'nt' in os.name:
os.system('cls')
# 查看当前目录的绝对路径:
os.path.abspath('.')
os.path.join('/Users/michael', 'testdir')
os.mkdir('/Users/michael/testdir')
# 删掉一个目录:
os.rmdir('/Users/michael/testdir')
os.path.split('/Users/michael/testdir/demo.txt')
os.path.splitext('/Users/michael/testdir/demo.txt')
os.rename('text.txt','test.py')
os.remove('test.py')
[x for x in os.listdir('.') if os.path.isdir(x)] # 查出当前目录下子目录
[x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py'] # 查出当前目录下 py 文件
序列化与反序列化
import json
class Student(object):
def __init__(self,name,age,score):
self._name = name
self._age = age
self._score = score
def __repr__(self):
return 'Student(name={},age={},score={})'.format(self._name,self._age,self._score)
def __str__(self):
return self.__repr__()
def student2dict(self,std):
return {'name':std._name
,'age':std._age
,'score':std._score}
s = Student('frank','18',100)
json.dumps(s,default=s.student2dict)
json.dumps(s,default=lambda obj:obj.__dict__)
print(eval(s.__repr__()))
json_str = '{"name":"frank","age":18,"score":100}'
def dict2student(d):
return Student(d['name'],d['age'],d['score'])
print(json.loads(json_str,object_hook=dict2student))
另一种形式的 迭代器,注意字符串也是序列
a = 'baidu'
try:
g = iter(a)
while True:
print(next(g))
except StopIteration as stopIter:
print(stopIter)
print('no more!')
map filter lambda 综合点运用
from functools import reduce
import re
exp = '99 + 88 + 7.6 ='
reduce(lambda x,y:x+y,list(map(int,filter(lambda x: x if x else None,map(lambda s:s.replace('.','').strip(),re.split(r'[\+|=]',exp))))))
sorted 排序
>>> sorted(d.items(),key=lambda t:t[1])
[('g', 20), ('f', 21), ('e', 22), ('d', 23), ('c', 24), ('b', 25), ('a', 26)]
>>> dict(sorted(d.items(),key=lambda t:t[1]))
{'g': 20, 'f': 21, 'e': 22, 'd': 23, 'c': 24, 'b': 25, 'a': 26}
>>> {}.fromkeys([1,2,2,3,1,4,5])
{1: None, 2: None, 3: None, 4: None, 5: None}
>>> set([1,2,3,1,2,1,4,5])
{1, 2, 3, 4, 5}
>>> import os
>>> with open(os.path.join(baseDir,'test.txt')) as f:
... for line in f:
... print(line)
自己写冒泡+快速排序
import time
from functools import wraps
def time_count(func):
@wraps(func)
def execute_func(*args,**kw):
t1 = time.time()
result = func(*args,**kw)
t2 = time.time()
print('共花费:{} 秒'.format(t2-t1))
return result
return execute_func
l = [9,8,7,6,5,4,3,2,1]
@time_count
def bubble_sort(l):
for i in range(len(l)):
for j in range(len(l)-i-1):
if l[j]>l[j+1]:
l[j],l[j+1] = l[j+1],l[j]
return l
bubble_sort(l)
@time_count
def quick_sort(array,low=0,high=None):
high = len(array)-1 if high is None else high
if low>=high:
return
l,r = low,high
base_value = array[l]
while l<r:
while l<r and array[r]>=base_value:
r-=1
array[l] = array[r]
while l<r and array[r]<base_value:
l+=1
array[r] = array[l]
array[l] = base_value
quick_sort(array,low,l)
quick_sort(array,l+1,high)
return array
l = [9,8,7,6,5,4,3,2,1]
quick_sort(l)
较为奢华版
from functools import wraps
from time import time
def time_count(func):
@wraps(func)
def wrapper_func(*args,**kw):
start = time()
result = func(*args,**kw)
end = time()
print('{} cost {} seconds in total...'.format(func.__name__,(end-start)))
return result
return wrapper_func
@time_count
def quick_sort(array,low=0,high=None):
high = len(array)-1 if high is None else high
if low>=high:
return
l,r = low,high
base = array[l]
while l<r:
while all([l<r,base<=array[r]]):
r-=1
array[l] = array[r]
while all([l<r,base>=array[l]]):
l+=1
array[r] = array[l]
array[l] = base
quick_sort(array,low,l-1)
quick_sort(array,l+1,high)
return array
array = [9,8,7,6,5,4,3,2,1]
quick_sort(array)
from functools import reduce
import re
out_str = """quick_sort cost 1.9073486328125e-06 seconds in total...
quick_sort cost 2.384185791015625e-06 seconds in total...
quick_sort cost 1.9073486328125e-06 seconds in total...
quick_sort cost 1.6689300537109375e-06 seconds in total...
quick_sort cost 1.9073486328125e-06 seconds in total...
quick_sort cost 0.0007488727569580078 seconds in total...
quick_sort cost 1.9073486328125e-06 seconds in total...
quick_sort cost 0.0014128684997558594 seconds in total...
quick_sort cost 0.002044200897216797 seconds in total...
quick_sort cost 1.9073486328125e-06 seconds in total...
quick_sort cost 0.0027604103088378906 seconds in total...
quick_sort cost 0.003480195999145508 seconds in total...
quick_sort cost 1.9073486328125e-06 seconds in total...
quick_sort cost 0.003975629806518555 seconds in total...
quick_sort cost 0.005151271820068359 seconds in total...
quick_sort cost 1.9073486328125e-06 seconds in total...
quick_sort cost 0.005714893341064453 seconds in total..."""
reduce(lambda x,y:float(x)+float(y),[item.strip() for item in re.findall(r'(\d.*)(?:second)',out_str)])
一句话简单版
quick_sort = lambda array: array if len(array) <= 1 else quick_sort([item for item in array[1:] if item <= array[0]]) + [array[0]] + quick_sort([item for item in array[1:] if item > array[0]])
l = [9,8,7,6,5,4,3,2,1]
quick_sort(l)
# 等价于:
def quick_sort2(arr):
if len(arr) <= 1:
return arr
else:
base = arr[0]
left = [item for item in arr[1:] if item<base]
right = [item for item in arr[1:] if item>=base]
return quick_sort2(left)+[base]+quick_sort2(right)
l = [9,8,7,6,5,4,3,2,1]
quick_sort2(l)
比较精简版水仙花数(原创)
from functools import reduce
[x for x in range(100,1000) if reduce(lambda x,y:x+y,map(lambda i:int(i)**3,str(x))) == x]
杨辉三角之前准备,先打印一下99乘法表
>>> def g_mul():
... for i in range(1,10):
... l = []
... for j in range(1,i+1):
... l.extend('{}*{}={}\t'.format(j,i,j*i))
... yield l
...
>>> for i in g_mul():
... print(''.join(i))
一句话版99乘法表
print ('\n'.join([' '.join(['%s*%s=%-2s' % (y,x,x*y) for y in range(1,x+1)]) for x in range(1,10)]))
print('\n'.join([ '\t'.join([str(j)+'*'+str(i)+'='+str(j*i) for j in range(1,i+1)]) for i in range(1,10)]))
print('\n'.join([ '\t'.join(['{}*{}={}'.format(j,i,j*i) for j in range(1,i+1)]) for i in range(1,10)]))
杨辉三角
>>> def triangle(x):
... l=[1]
... while x>0:
... yield l
... l.append(0)
... l = [l[i-1]+l[i] for i in range(len(l))]
... x-=1
...
>>> for i in triangle(10):
... print(i)
三元运算符的另一种写法
>>> a = 1
>>> b = (2,3)[a==1]
>>> b
3
>>> b = (2,3)[a==13]
>>> b
2
注意
reload(sys)
sys.setdefaultencoding("utf-8")12
在Python 3.x中不好使了 提示 name ‘reload’ is not defined
在3.x中已经被毙掉了被替换为
import importlib
importlib.reload(sys)
上下文管理
#方式一:
# 第1个参数保存异常类型;
# 第2个参数保存异常对象的值;
# 第3个参数保存异常的traceback信息。
class OpenObj(object):
def __init__(self,filename,model):
self.fp = open(filename,model)
def __enter__(self):
return self.fp
def __exit__(self,exc_type,exc_val,exc_traceback):
self.fp.close()
with OpenObj('./test.py','r') as f:
for line in f:
print(line)
#方式二:
from contextlib import contextmanager
@contextmanager
def make_open_context(filename,model):
fp = open(filename,model)
try:
yield fp
finally:
fp.close()
with make_open_context('./test.py','r') as f:
for line in f:
print(line)
# 扩展 mysql 数据库游标
from pymysql import connect
class DBHelper:
def __init__(self):
self.conn = connect(host='localhost', port=3306, user='user', password='password', database='database', charset='utf8')
self.csr = self.conn.cursor()
def __enter__(self):
return self.csr
def __exit__(self, exc_type, exc_val, exc_tb):
self.csr.close()
self.conn.close()
with DBHelper() as csr:
sql = """select * from table;"""
csr.execute(sql)
all_datas = csr.fetchall()
for item in all_datas:
print(item)
@contextmanager
def conn_db():
conn = connect(host='localhost', port=3306, user='user', password='password', database='database', charset='utf8')
csr = conn.cursor()
yield csr
csr.close()
conn.close()
with conn_db() as csr:
sql = """select * from table"""
csr.execute(sql)
all_datas = csr.fetchall()
for item in all_datas:
print(item)
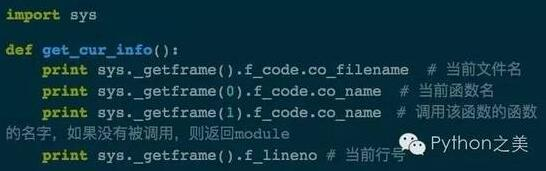
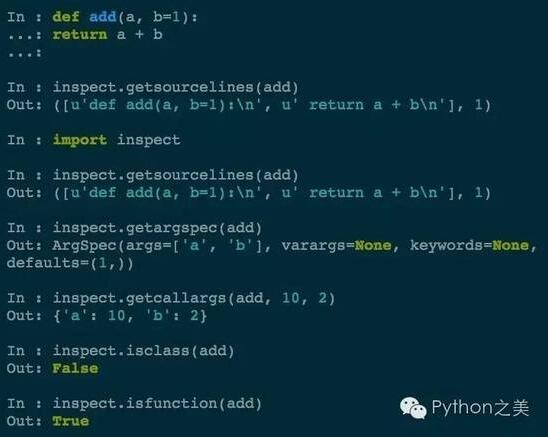

深度遍历与宽度遍历
class Node(object):
def __init__(self,sName):
self._lChildren = []
self.sName = sName
def __repr__(self):
return "<Node '{}'>".format(self.sName)
def append(self,*args,**kwargs):
self._lChildren.append(*args,**kwargs)
def print_all_1(self):
print(self)
for oChild in self._lChildren:
oChild.print_all_1()
def print_all_2(self):
def gen(o):
lAll = [o,]
while lAll:
oNext = lAll.pop(0)
lAll.extend(oNext._lChildren)
yield oNext
for oNode in gen(self):
print(oNode)
oRoot = Node("root")
oChild1 = Node("child1")
oChild2 = Node("child2")
oChild3 = Node("child3")
oChild4 = Node("child4")
oChild5 = Node("child5")
oChild6 = Node("child6")
oChild7 = Node("child7")
oChild8 = Node("child8")
oChild9 = Node("child9")
oChild10 = Node("child10")
oRoot.append(oChild1)
oRoot.append(oChild2)
oRoot.append(oChild3)
oChild1.append(oChild4)
oChild1.append(oChild5)
oChild2.append(oChild6)
oChild4.append(oChild7)
oChild3.append(oChild8)
oChild3.append(oChild9)
oChild6.append(oChild10)
# 说明下面代码的输出结果
oRoot.print_all_1()
oRoot.print_all_2()
验证下parquet 与 csv 读写效率
import psycopg2
from contextlib import contextmanager
import pandas as pd
import numpy as np
import time
from functools import wraps
@contextmanager
def get_cur(**kw):
conn = psycopg2.connect(**kw)
crs = conn.cursor()
yield crs
crs.close
conn.close()
field_list = ['person_id',xxx
'survival_36m', 'survival_60m', 'survival_120m', 'survival_months', 'recurrence_months',
'recurrence_site']
kw = dict(dbname='demodb'
, host='devxxxom'
, port=5439
, user='user'
, password='password')
def get_frame():
with get_cur(**kw) as crs:
sql = 'select "'+'","'.join(field_list)+'" from ml_sample limit 10000'
print(sql)
crs.execute(sql)
df = pd.DataFrame(list(crs.fetchall()))
df.columns = field_list
return df
def save_file(df,filename,file_ex):
if file_ex.strip()=='parquet':
# from os import path
# if path.exits(filename):
# os.remove(filename)
df.to_parquet(filename, compression='gzip')
elif file_ex.strip() == 'csv':
df.to_csv(filename)
else:
print('not implement~...')
#
# pd.read_parquet('df.parquet.gzip')
def magnify_file(src,target,tn):
for i in range(tn):
print(src)
with open(src,'rb') as fr:
with open(target,'ab') as fw:
for blk in fr:
fw.write(blk)
def time_count(func):
@wraps(func)
def func_wrapper(*args,**kw):
start = time.time()
result = func(*args,**kw)
end = time.time()
print('{} cost {} seconds...'.format(func.__name__,(end-start)))
return result
return func_wrapper
@time_count
def parquet_test(tn):
df = get_frame()
parquet_file = 'dataset.gzip'
save_file(df,parquet_file,'parquet')
from os import path
parquet_file_magnif,_= path.splitext(parquet_file)
magnify_file(parquet_file,parquet_file_magnif+'_magnif.gzip',tn)
df = pd.read_parquet(parquet_file_magnif+'_magnif.gzip')
df.head()
@time_count
def csv_test(tn):
df = get_frame()
csv_file = 'dataset.csv'
save_file(df,csv_file,'csv')
from os import path
csv_file_magnif,_ = path.splitext(csv_file)
print(csv_file_magnif)
magnify_file(csv_file,csv_file_magnif+'_magnif.csv',tn)
print('.....herer ....')
df = pd.read_csv(csv_file_magnif+'_magnif.csv')
df.head()
csv_test(10)
parquet_test(10)
csv_test(100)
parquet_test(100)
回文数的n种写法
def palindrome(s):
return s == s[::-1]
def palindrome2(s):
flag = True
l,r = 0,len(s)-1
while l<=r:
if s[l] != s[r]:
flag = False
l+=1
r-=1
return flag
# 存在闭包问题,下面这种是错误的
def palindrome3(s,low=0,high=None):
flag = True
high = len(s)-1 if high is None else high
l,r = low, high
if l<r:
if s[l] == s[r]:
palindrome3(s,l+1,r-1)
else:
flag = False
return flag
palindrome3('aba')
True
# 解决了闭包问题
def palindrome3(s,low=0,high=None):
global flag
high = len(s)-1 if high is None else high
l,r = low, high
print(l,'--',r)
if l<r:
if s[l] == s[r]:
flag = True
palindrome3(s,l+1,r-1)
else:
flag = False
print(flag)
return flag
argparse 模块用来做命令行工具挺方便
import argparse
import time
if __name__ == '__main__':
start_time = time.time()
#PATIENT SIMILARITY REQUEST INPUT
parser = argparse.ArgumentParser(description="input to experiments")
parser.add_argument('--organization_id', type=int, help='org id for filter')
parser.add_argument('--save_cluster', type=int, help='if save cluster, please provide org_model_id')
parser.add_argument('--threshold', type=float, help='initial threshold ')
parser.add_argument('--bin', type=float, help='degree of freedom to do chi-squared test')
parser.add_argument('--list_of_features', type=str, nargs='*',help='features could be demographic, tumor-related and gene related')
parser.add_argument('--organization_model_id', type=int, help='organization_model_id from ml_organization_model table')
args = parser.parse_args()
print(args.list_of_features)
end_time = time.time()
print('cost {} s in total...'.format(end_time-start_time))
实用代码片段
# 屏蔽标准输出流标准错误流
def shield_print(func):
@wraps(func)
def main_func(*args,**kw):
with open('outprint.log','w') as fw:
old_stdout = sys.stdout
old_stderr = sys.stderr
sys.stdout = sys.stderr = fw
result = func(*args,**kw)
sys.stdout = old_stdout
sys.stderr = old_stderr
return result
return main_func
自定义 精度条显示
import sys,time
def progress_bar(num,total):
rate = float(num)/total
rate_num = int(rate*100)
out = '\r[{}{}] 已完成 {} %'.format('*'*rate_num,' '*(100-rate_num),rate_num)
stdout = sys.stdout
stdout.write(out)
stdout.flush()
def test_progress_bar(start,end):
i = start
for i in range(end):
time.sleep(0.1)
progress_bar(i+1,end)
if __name__ == '__main__':
start = 0
end = 200
test_progress_bar(start,end)
类似于 log4j
# -*- coding: utf-8 -*-
"""
%(levelno)s: 打印日志级别的数值
%(levelname)s: 打印日志级别名称
%(pathname)s: 打印当前执行程序的路径,其实就是sys.argv[0]
%(filename)s: 打印当前执行程序名
%(funcName)s: 打印日志的当前函数
%(lineno)d: 打印日志的当前行号
%(asctime)s: 打印日志的时间
%(thread)d: 打印线程ID
%(threadName)s: 打印线程名称
%(process)d: 打印进程ID
%(message)s: 打印日志信息
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
"""
import logging
import datetime
def getLog(path='.'):
dt=datetime.datetime.now()
dtstr=dt.strftime('%Y-%m-%d')
#dtstr=dt.strftime('%Y-%m-%d_%H_%M_%S')
#创建一个logger实例
logger = logging.getLogger("mllogger")
logging.basicConfig(filemode='wa')
hds=logger.handlers
for h in hds:
logger.removeHandler(h)
logger.setLevel(logging.INFO)
#创 建一个handler,用于写入日志文件,handler可以把日志内容写到不同的地方
logName ="%s/%s.ml.log"%(path,dtstr)
fh = logging.FileHandler(logName)
fh.setLevel(logging.ERROR)
#再 创建一个handler,用于输出控制台
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
log_format=logging.Formatter("[%(asctime)s-%(filename)s:%(lineno)d]\n%(message)s",datefmt='%d %H:%M:%S')
fh.setFormatter(log_format) #setFormatter() selects a Formatter object for this handler to use
ch.setFormatter(log_format)
logger.addHandler(fh)
logger.addHandler(ch)
return logger
if __name__=='__main__':
log=getLog()
try:
with open('./test.txt') as f:
pass
except (FileNotFoundError,EOFError) as e:
log.error(e)
log.info(a)
log.info('test1')
log.info('test2')
log.info('test3')
自己写好的 工具 py 脚本 放到对应目录下去
有时候我们在liunx上想修改查看python的包路径可以试试以下命令
from distutils.sysconfig import get_python_lib
print(get_python_lib())
1024 == 2**10
65535 == 2**16-1
4294967295 == 2**32-1
[chr(i) for i in range(65,91)]+[chr(i) for i in range(97,123)]
b'\xe4\xb8\xad\xff'.decode('utf-8',errors='ignore')
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
思考
eval exec zip 的应用场景
不可变参数通过值传递,可变参数通过引用传递 list=[] 与 list =None 做参数的例子
上下文管理器+各种编码问题+异常处理深入
第三方模块
谷歌的 fire 模块
import dis 分析函数过程等...
from __future__ import printfunction 等 用来兼容 py2 与 py3
代码统计 cloc
excel 读写 pandas + xlrd , xlsxwriter
lxml
shutil
f-string
框架部分
相见恨晚
python 精华梳理(已理解并手写)--全是干货--已结的更多相关文章
- 理解并手写 call() 函数
手写自己的call,我们要先通过call的使用,了解都需要完成些什么功能? call()进行了调用,是个方法,已知是建立在原型上的,使用了多个参数(绑定的对象+传递的参数). 我们把手写的函数起名为m ...
- python机器学习使用PCA降维识别手写数字
PCA降维识别手写数字 关注公众号"轻松学编程"了解更多. PCA 用于数据降维,减少运算时间,避免过拟合. PCA(n_components=150,whiten=True) n ...
- 理解并手写 bind() 函数
有了对call().apply()的前提分析,相信bind()我们也可以手到擒来. 参考前两篇:'对call()函数的分析' 和 '对apply()函数的分析',我们可以先得到以下代码: Functi ...
- 理解并手写 apply() 函数
apply()函数,在功能上类似于call(),只是传递参数的格式有所不同. dog.eat.call(cat, '鱼', '肉'); dog.eat.apply(cat, ['鱼', '肉']); ...
- react纯手写全选与取消全选
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 2 手写Java LinkedList核心源码
上一章我们手写了ArrayList的核心源码,ArrayList底层是用了一个数组来保存数据,数组保存数据的优点就是查找效率高,但是删除效率特别低,最坏的情况下需要移动所有的元素.在查找需求比较重要的 ...
- 30个类手写Spring核心原理之依赖注入功能(3)
本文节选自<Spring 5核心原理> 在之前的源码分析中我们已经了解到,依赖注入(DI)的入口是getBean()方法,前面的IoC手写部分基本流程已通.先在GPApplicationC ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 使用神经网络来识别手写数字【译】(三)- 用Python代码实现
实现我们分类数字的网络 好,让我们使用随机梯度下降和 MNIST训练数据来写一个程序来学习怎样识别手写数字. 我们用Python (2.7) 来实现.只有 74 行代码!我们需要的第一个东西是 MNI ...
随机推荐
- 在 CentOS 上编写 init.d service script [转]
背景:之前编写了一些脚本,下载了一些开源软件,想把它们做成系统服务,通过 service your_prog_name start 这样的方式来后台运行,并在开机时自动启动.在了解了 daemon 命 ...
- 计算几何细节梳理&模板
点击%XZY巨佬 向量的板子 #include<bits/stdc++.h> #define I inline using namespace std; typedef double DB ...
- Codeforces | CF1037D 【Valid BFS?】
题目大意:给定一个\(n(1\leq n\leq 2\cdot10^5)\)个节点的树的\(n-1\)条边和这棵树的一个\(BFS\)序\(a_1,a_2,\dots,a_n\),判断这个\(BFS\ ...
- POJ2411 铺地砖 Mondriaan's Dream
Mondriaan's Dream Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 15962 Accepted: 923 ...
- Java复习总结——详细理解Java反射机制
反射是什么 反射的作用用一句简单的话来讲就是可以对代码进行操作的代码,这个特性经常在被用于创建JavaBean中,通常造轮子的人会用到这个特性,而应用程序员用到这个特性的场景则较少. 能够分析类能力的 ...
- Python学习day3 数据类型Ⅰ(str,int,bool)
day3 数据类型 @上节内容补充 每周一个思维导图-xmind.exe in / not in #示例:(是否包含敏感字符)while True: text = input('请输入你要说的 ...
- webpack入门(二)what is webpack
webpack is a module bundler.webpack是一个模块打包工具,为了解决上篇一提到的各种模块加载或者转换的问题. webpack takes modules with dep ...
- mybatis 二级缓存
Mybatis读取缓存次序: 先从二级缓存中获取数据,如果有直接获取,如果没有进行下一步: 从一级缓存中取数据,有直接获取,如果没有进行下一步: 到数据库中进行查询,并保存到一级缓存中: 当sqlSe ...
- bzoj3467: Crash和陶陶的游戏
就一篇题解: BZOJ3467 : Crash和陶陶的游戏 - weixin_34248487的博客 - CSDN博客 1.离线,建出Atrie树:B树的倍增哈希数组,节点按照到根路径字典序排序 2. ...
- tfs 2013 利用 web deploy 完成asp.net站点自动发布
课题起因: 目前我们团队使用visual studio 2013开发asp.net项目, 使用tfs2013 做源码管理, 每天早上手动发布项目文件包,复制到测试服务器的站点文件夹下覆盖老文件,用此方 ...