Python中Celery 的基本用法以及Django 结合 Celery 的使用和实时监控进程
celery是什么
1 celery是一个简单,灵活且可靠的,处理大量消息的分布式系统
2 专注于实时处理的异步任务队列
3 同时也支持任务调度
执行流程
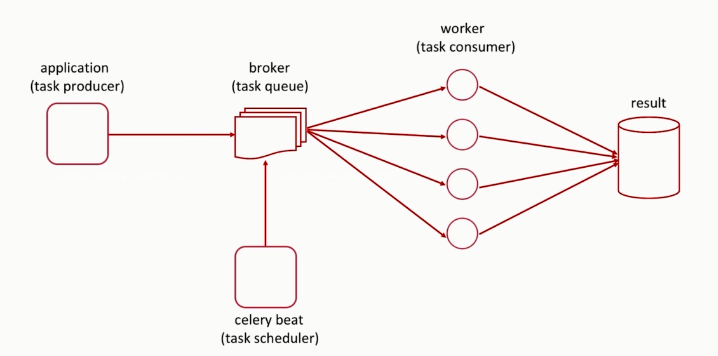

Celery 基本使用
tasks.py
import time
from celery import Celery
# 消息中间件
broker = 'redis://localhost:6379/1'
# 存取任务执行的结果
backend = 'redis://localhost:6379/2'
app = Celery('my_task',broker=broker,backend=backend)
@app.task
def add(x,y):
print('enter call func......')
time.sleep(4)
return x+y
app.py
import time
from tasks import add
if __name__ == '__main__':
print('start task')
result = add.delay(2,3)
print(result)
启动 worker - —A 表示指定celery 实例位置
celery worker -A tasks -l INFO
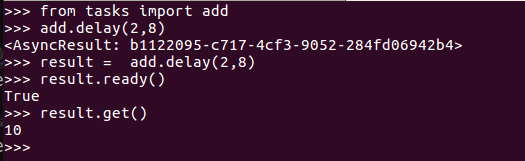
result.ready # 是否执行完成 result.get() # 获取执行的结果
终端celery 打印结果

Celery 配置文件
目录结构如下
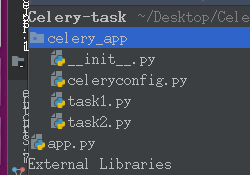
celery_app/celeryconfig.py
BROKER_URL = 'redis://localhost:6379/1'
CELERY_RESULT_BACKEND = 'redis://localhost:6379/2'
CELERY_TIMEZONE = 'Asia/Shanghai' # 指定时区
# 导入指定模块
CELERY_IMPORTS = (
'celery_app.task1',
'celery_app.task2'
)
celery_app/__init__.py
from celery import Celery
app = Celery('demo')
app.config_from_object('celery_app.celeryconfig') #通过celery实例加载配置
celery_app/task1.py
from celery_app import app
import time
@app.task
def add(x,y):
print('enter call func......')
time.sleep()
return x+y
celery_app/task2.py
from celery_app import app
import time
@app.task
def multiply(x,y):
print('enter call func......')
time.sleep()
return x*y
app.py
from celery_app.task1 import add
from celery_app.task2 import multiply
if __name__ == '__main__':
print('start task')
result1 = add.delay(,)
result2 = multiply.delay(,)
print('end')
启动worker
celery worker -A celery_app -l INFO
执行app.py

worker控制台打印

Celery 定时任务
在celery 4.10中有一个时区的bug在这里我用的是4.0.2
celery_app/celerycongig.py 增加以下代码
实现每隔3s执行一次task1,每天在23:33执行task2
from datetime import timedelta
from celery.schedules import crontab
# 配置定时任务列表
CELERYBEAT_SCHEDULE = {
"task1":{
"task": "celery_app.task1.add",
"schedule": timedelta(seconds=3), # 每3S执行一次
'args': (2,8)
},
"task2": {
"task": "celery_app.task2.multiply",
"schedule": crontab(hour=23,minute=33), # 每天23:33执行
'args': (4, 5)
}
}
完整配置代码
from datetime import timedelta
from celery.schedules import crontab
BROKER_URL = 'redis://localhost:6379/1'
CELERY_RESULT_BACKEND = 'redis://localhost:6379/2'
# 导入指定模块
CELERY_IMPORTS = (
'celery_app.task1',
'celery_app.task2'
)
CELERY_TIMEZONE = 'Asia/Shanghai'
# 配置定时任务列表
CELERYBEAT_SCHEDULE = {
"task1":{
"task": "celery_app.task1.add",
), # 每3S执行一次
,)
},
"task2": {
"task": "celery_app.task2.multiply",
,minute=), # 每天23:33执行
, )
}
}
运行beat 发送定时任务
celery beat -A celery_app -lNFO
启动worker
celery worker -A celery_app -l INFO
用一条命令来启动 beat 和worker
celery -B -A celery_app worker -l INFO
在Django中使用 Celery
安装依赖
pip install django-celery
创建django项目
django-admin startproject immoc
创建一个cource的app
python manage.py startapp course
在setiing.py中注册cource和djcelery应用
INSTALLED_APPS = (
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'djcelery',
'course'
)
在应用couse下创建tasks.py 任务文件
import time
from celery import shared_task
@shared_task()
def course_task():
print('start_cource')
time.sleep(4)
print('end_cource')
在immoc/immoc下创建celeryconfig.py 配置celery
from datetime import timedelta
import djcelery
from celery.schedules import crontab
djcelery.setup_loader()
# 定义队列
CELERY_QUEUES = {
'beat_tasks':{
'exchange':"beat_tasks",
'exchange_type':"direct",
'binding_key':'beat_tasks'
},
"work_queue":{
'exchange':'work_queue',
'exchange_type':"direct",
'binding_key':"work_queue"
}
}
# 指定默认的队列
CELERY_DEFAULT_QUEUE = 'work_queue'
# 有些情况下可以防止死锁
CELERYD_FORCE_EXECV = True
# 设置并发的worker数
CELERYD_CONCURRENCY =
# 允许重试
CELERY_ACKS_LATE = True
# 每个worker执行100个任务就销毁,防止内存泄露
CELERYD_MAX_TASKS_PER_CHILD =
# 单个任务最大的运行时间
CELERYD_TASK_TIME_LIMIT = *
CELERY_TIMEZONE = 'Asia/Shanghai'
# 配置定时任务列表
CELERYBEAT_SCHEDULE = {
"task1":{
"task": "couse.tasks.course_task",
), # 每3S执行一次'options': {
"queue": "work_queue"
}
}
}
在settings.py中加载配置
# 配置celery from .celeryconfig import * BROKER_BACKEND='redis' BROKER_URL = 'redis://localhost:6379/1' CELERY_RESULT_BACKEND = 'redis://localhost:6379/2'
启动worker
python manage.py celery worker -l INFO
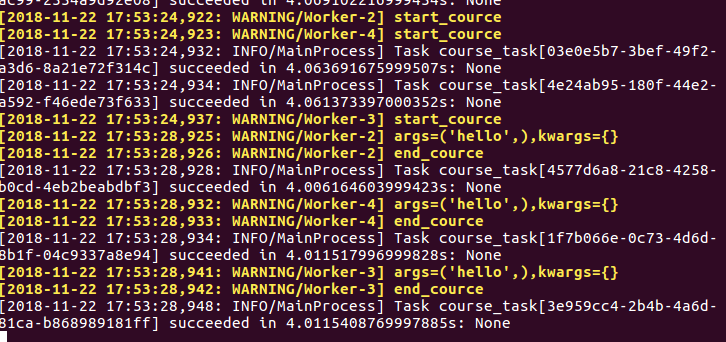
运行定时任务beat
python manage.py celery beat -l INFO
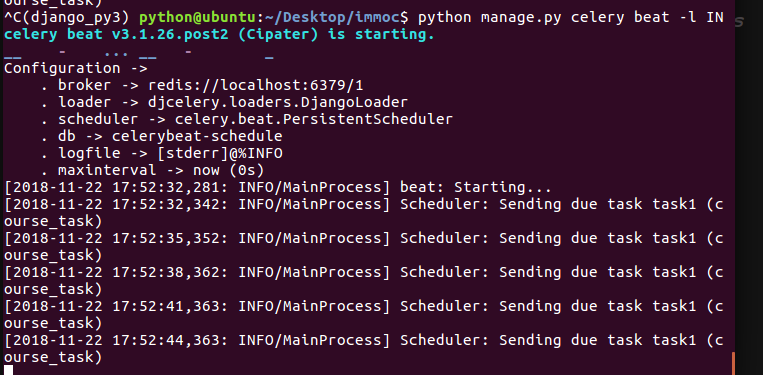
在django中调用任务
immoc/views.py
from django.shortcuts import render
# Create your views here.
from course.tasks import CourseTask
from django.views.generic import View
from django.http import JsonResponse
class DoView(View):
"""注册"""
def get(self, request):
"""对应get请求方式,提供注册页面"""
# 执行任务
print('start request')
# res = CourseTask.delay()
res = CourseTask.apply_async(args=('hello',),queue='work_queue')
print(res)
print('end request')
return JsonResponse({'name':'zhang'})
配置路由
from django.conf.urls import include, url
from django.contrib import admin
from course.views import DoView
urlpatterns = [
url(r'^admin/', include(admin.site.urls)),
url(r'^do/$', DoView.as_view(),name='do'),
]
访问
http://127.0.0.1:8000/do/
worker输出结果
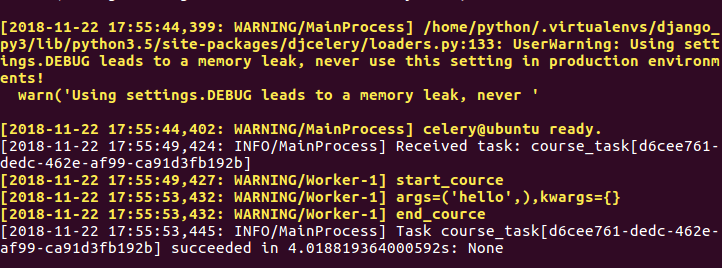
使用 django_celery_results 存取 celery 结果
安装
pip install django_celery_results
注册到django app中
INSTALLED_APPS = (
''''
'django_celery_results'
''''
)
配置存放到django数据库中,存取的格式为 json (settings.py)
CELERY_TASK_SERIALIZER = 'json' CELERY_RESULT_SERIALIZER = 'json' CELERY_ACCEPT_CONTENT = ['json'] CELERY_TASK_ACKS_LATE = True CELERY_RESULT_BACKEND = 'django-db'
注意 CELERY_RESULT_BACKEND 是celery 存放的结果,这里因为我是存取到django 的数据库中所以值为 django-db ,可以直接操作 django_celery_results_taskresult 进行查询,
要是选择存放在 redis 中的话,需要到 redis 中获取结果
生成数据表
python manage.py migrate
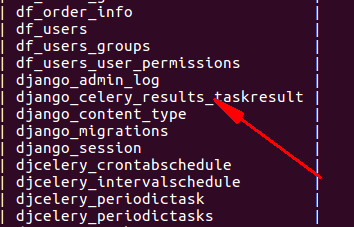
异步的任务结果会自动的存取到 django_celery_results_taskresult 表中
启动 worker
python manage.py celery worker -l INFO
可能会出现一下报错信息
from .celeryconfig import *
File "/home/python/Desktop/tiantianshengxian_onliyone/dailyfresh_13/dailyfresh_13/celeryconfig.py", line 8, in <module>
from djcelery.management.commands import celery
File "/home/python/.virtualenvs/django_py3/lib/python3.5/site-packages/djcelery/management/commands/celery.py", line 11, in <module>
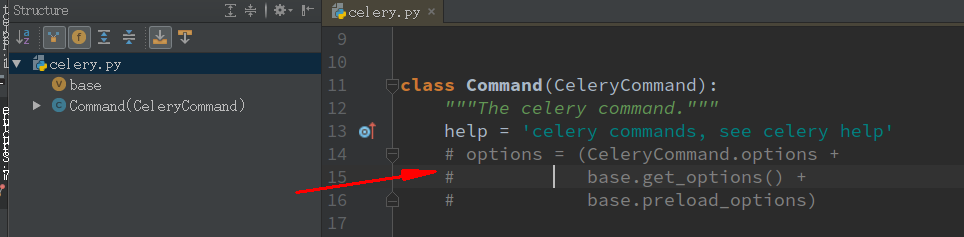
class Command(CeleryCommand):
File "/home/python/.virtualenvs/django_py3/lib/python3.5/site-packages/djcelery/management/commands/celery.py", line 15, in Command
base.get_options() +
TypeError: can only concatenate tuple (not "NoneType") to tuple
解决方法 把 djcelery.management.commands.celery import Command 中的 options 注释掉即可
简单测试
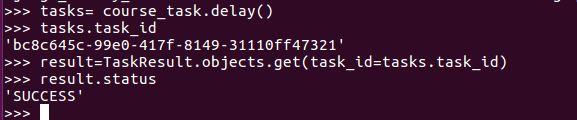
from django_celery_results.models import TaskResult tasks= course_task.delay() tasks.task_id result=TaskResult.objects.get(task_id=tasks.task_id) result.status
监控工具 Flower 的使用

在 django中使用Flwor
安装
pip install flower==0.9
启动worker
python manage.py celery worker -l INFO
运行flower
python manage.py celery flower
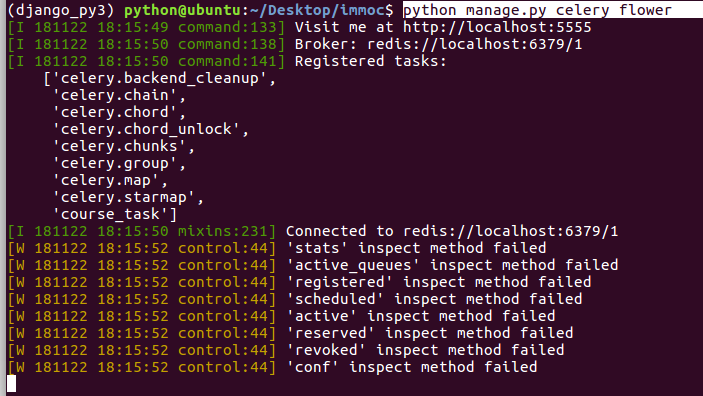
运行定时任务
python manage.py celery beat -l INFO
在浏览器输入
http://127.0.0.1:5555/
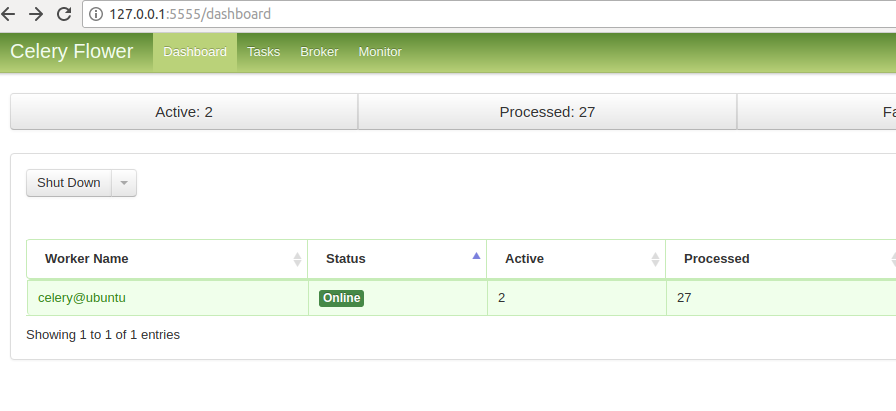
可以对任务实时监控
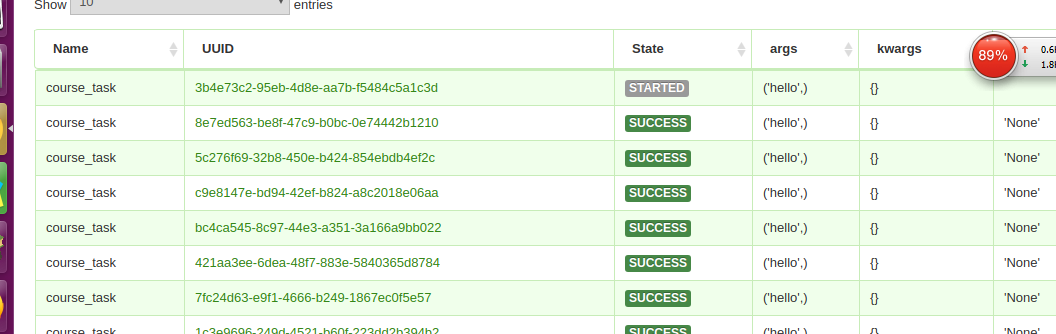
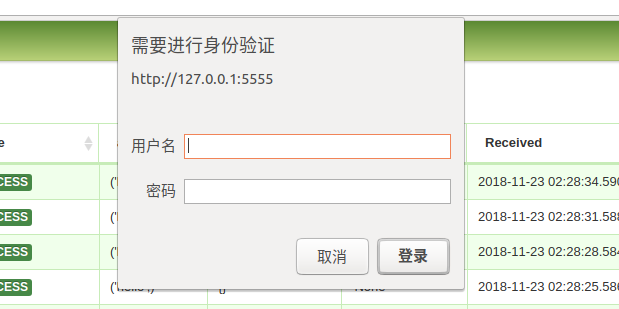
对登陆的用户进行basic_auth认证
python manage.py celery flower --bic_auth=name:zhangbiao
Supervisor部署celery
官方网站
http://supervisord.org/
supervisor是一个非常优秀的进程管理工具
安装
pip3 install git+https://github.com/Supervisor/supervisor
新建一个目录conf 把 supervisor 配置文件重定向到conf目录下
mkdir conf echo_supervisord_conf > conf/supervisord.conf
开启进程管理界面把conf/supervisord_conf中的22和23行的分号去掉
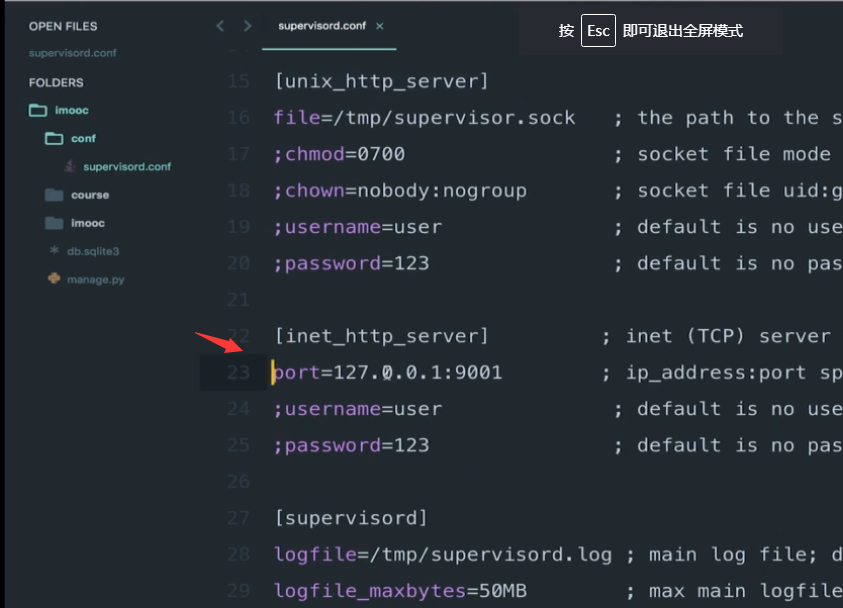
把下面的分号也去掉改为 (把当前目录下的所有以.ini结尾的配置文件都包含进来)
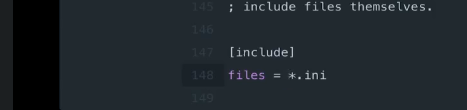
在immoc下创建logs目录
mkdir logs
在conf下创建 supervisor_celery_worker.ini 的配置文件
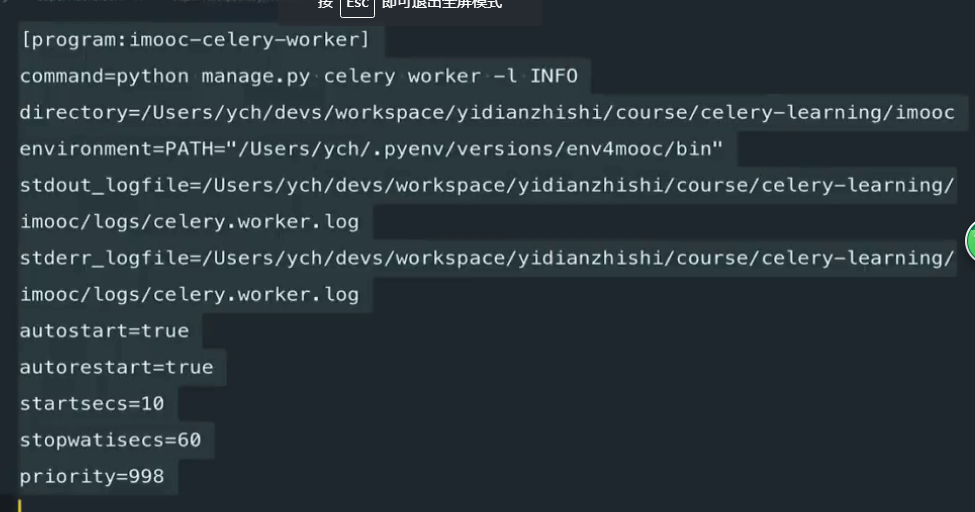
[program:immoc-celery-worker] command= python manage.py celery worker -l INFO directory=/home/python/Desktop/immoc environment=PATH='/home/python/.virtualenvs/django_py3/bin' stdout_logfile=/home/python/Desktop/immoc/logs/celery.worker.log stderr_logfile=/home/python/Desktop/immoc/logs/celery.worker.log autostart=true autorestart=true startsecs= stopwatises= pripority=
启动 supervisor
supervisord -c conf/supervisord.conf
报错信息:
error: <class 'socket.error'>, [Errno 2] No such file or directory: file: <string> line: 1
解决办法:
这个可能有多种原因,可能是已经启动过了也可能是没权限,解决步骤如下:
1. 先要确认是否已经启动过了:’ps -ef | grep supervisord’
2. 如果有的话先kill掉
3. 运行下面命令:
sudo touch /var/run/supervisor.sock sudo chmod 777 /var/run/supervisor.sock
4. 再尝试重新启动:
supervisord -c /etc/supervisord.conf(如果没有文件找个别人的配置拷贝过来或者运行echo_supervisord_conf > /conf/supervisord.conf)
在浏览器输入
http://127.0.0.1:9001
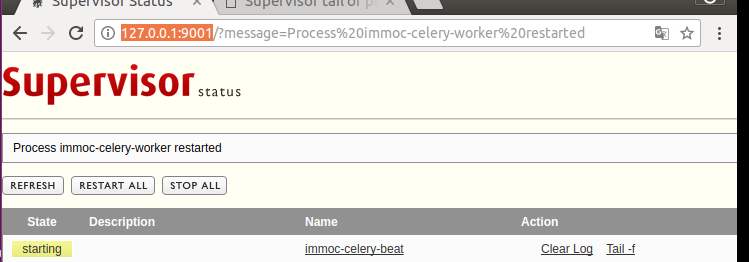
在config目录下创建supervisor_celery_beat.ini
[program:immoc-celery-beat] command= python manage.py celery beat -l INFO directory=/home/python/Desktop/immoc environment=PATH='/home/python/.virtualenvs/django_py3/bin' stdout_logfile=/home/python/Desktop/immoc/logs/celery.beat.log stderr_logfile=/home/python/Desktop/immoc/logs/celery.beat.log autostart=true autorestart=true startsecs=10 stopwatises=60 pripority=997
在终端输入 把supervisor_celery_beat.ini 添加到supervisor进程组中
supervisorctl update

查看状态 有两个进程运行

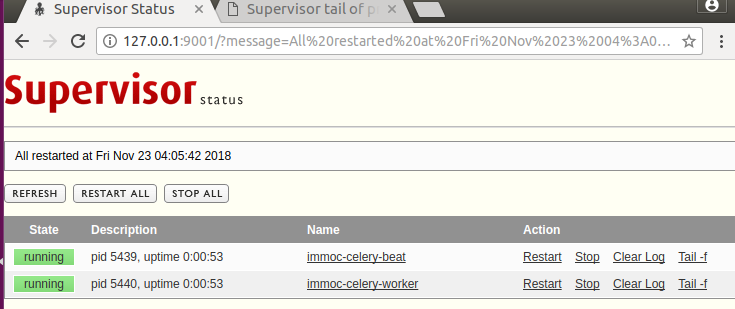
添加flower进程
在conf下创建supervisor_celery_flower.ini
[program:immoc-celery-flower] command= python manage.py celery flower directory=/home/python/Desktop/immoc environment=PATH='/home/python/.virtualenvs/django_py3/bin' stdout_logfile=/home/python/Desktop/immoc/logs/celery.flower.log stderr_logfile=/home/python/Desktop/immoc/logs/celery.flower.log autostart=true autorestart=true startsecs= stopwatises= pripority=
在终端输入 把supervisor_celery_flower.ini 添加到supervisor进程组中
updata status
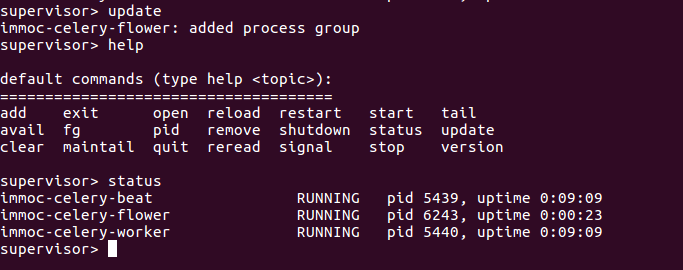
刷新页面
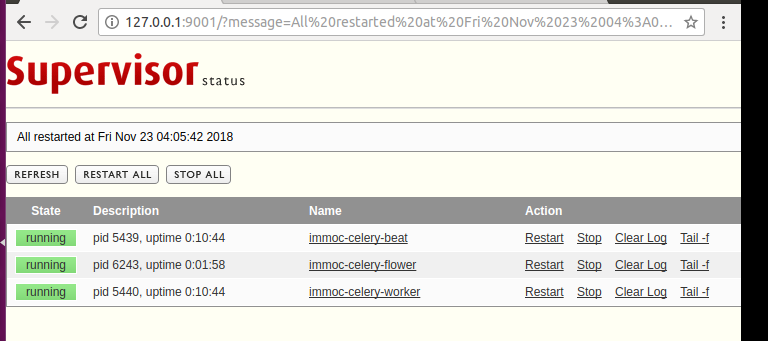
进入flwor查看
http://127.0.0.1:5555/
可以把uwsgi等进程配置在conf中进行管理
Python中Celery 的基本用法以及Django 结合 Celery 的使用和实时监控进程的更多相关文章
- Python中 sys.argv[]的用法
Python中 sys.argv[]的用法 因为是看书自学的python,开始后不久就遇到了这个引入的模块函数,且一直在IDLE上编辑了后运行,试图从结果发现它的用途,然而结果一直都是没结果,也在网上 ...
- 31 Python中 sys.argv[]的用法简明解释(转)
Python中 sys.argv[]的用法简明解释 因为是看书自学的python,开始后不久就遇到了这个引入的模块函数,且一直在IDLE上编辑了后运行,试图从结果发现它的用途,然而结果一直都是没结果, ...
- Python中sorted()方法的用法
Python中sorted()方法的用法 2012-12-24 22:01:14| 分类: Python |字号 订阅 1.先说一下iterable,中文意思是迭代器. Python的帮助文档中对i ...
- Python中int()函数的用法浅析
int()是Python的一个内部函数 Python系统帮助里面是这么说的 >>> help(int) Help on class int in module __builti ...
- Python中 sys.argv的用法简明解释
Python中 sys.argv[]的用法简明解释 sys.argv[]说白了就是一个从程序外部获取参数的桥梁,这个“外部”很关键,所以那些试图从代码来说明它作用的解释一直没看明白.因为我们从外部取得 ...
- python中super()的一些用法
在看python高级编程这本书的时候,在讲到super的时候,产生了一些疑惑,super在python中的用法跟其他的语言有一些不一样的地方,在网上找了一些资料,发现基本上很少有文章能把我的疑惑讲明白 ...
- Python中return self的用法
在Python中,有些开源项目中的方法返回结果为self. 对于不熟悉这种用法的读者来说,这无疑使人困扰,本文的目的就是给出这种语法的一个解释,并且给出几个例子. 在Python中,retur ...
- (数据科学学习手札53)Python中tqdm模块的用法
一.简介 tqdm是Python中专门用于进度条美化的模块,通过在非while的循环体内嵌入tqdm,可以得到一个能更好展现程序运行过程的提示进度条,本文就将针对tqdm的基本用法进行介绍. 二.基本 ...
- python中reload(module)的用法,以及错误提示
1.Python2中可以和Python3中关于reload()用法的区别. Python2 中可以直接使用reload(module)重载模块. Pyhton3中需要使用如下两种方式: 方式(1) ...
随机推荐
- 基于WIN8.1:新手篇→tomcat安装配置
一.JDK配置 下载安装JDK和tomcat 打开电脑属性,高级系统设置进行环境变量配置 新建系统变量,变量值为JDK安装路径,并在系统变量path最后加上“%JAVA_HOME%\bin;%JAVA ...
- C语言 大小写字母转换
//凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 方法1: #include<stdio.h> #include<stdlib.h> ...
- Windows10反安装报错error code 2502 2503
先找系统TEMP目录,一般为C:\windows\temp,打开这个目录的权限,为这个目录中的User用户添加权限为完全控制,现在再反安装就不会报错了. 注:原因就是因为系统运行时需要用到临时文件的目 ...
- props default 数组/对象的默认值应当由一个工厂函数返回
export default {props: { slides:{ type:Array, default:[] } },这是我的代码 报错是Invalid default value for pro ...
- git pull的理解 以及 git conflict的解决
git pull:相当于是从远程获取最新版本并merge到本地 即: git fetch -> 与本地的分支(比如master)merge 如果有conflict报错 1 先查看statue - ...
- SDOI2016 R1做题笔记
SDOI2016 R1做题笔记 经过很久很久的时间,shzr终于做完了SDOI2016一轮的题目. 其实没想到竟然是2016年的题目先做完,因为14年的六个题很早就做了四个了,但是后两个有点开不动.. ...
- P1678 烦恼的高考志愿(二分)
emmmm,我感觉我在解题的过程中还是有点吃亏的,因为,我知道是二分,只是大概知道怎么分,没有管这道到底是需要怎样的二分.然后在题上卡了很久. 思路:要找到填报学校的录取线x和自己的分数y的绝对值最小 ...
- leetCode练习1
代码主要采用C#书写 题目: 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标. 你可以假设每种输入只会对应一个答案.但是,你 ...
- Linux 查看物理 CPU、内存信息
可以通过本文如下方法查看云服务器 Linux 系统的 CPU.内存相关信息: 说明: 总核数 = 物理CPU个数 × 每颗物理CPU的核数 总逻辑CPU数 = 物理CPU个数 × 每颗物理CPU的核数 ...
- Spring Security(十二):5. Java Configuration
General support for Java Configuration was added to Spring Framework in Spring 3.1. Since Spring Sec ...