Python爬虫学习之正则表达式爬取个人博客
实例需求:运用python语言爬取http://www.eastmountyxz.com/个人博客的基本信息,包括网页标题,网页所有图片的url,网页文章的url、标题以及摘要。
实例环境:python3.7
requests库(内置的python库,无需手动安装)
re库(内置的python库,无需手动安装)
实例网站:
第一步,点击网站地址http://www.eastmountyxz.com/,查看页面有哪些信息,网页标题、图片以及摘要等
第二步,查看网页源代码,即可看到想要爬取的基本信息


实例代码:
#encoding:utf-8
import re
#import urllib.request
import requests def getHtmlStr(url):
#content = urllib.request.urlopen(url).read().decode("utf-8")
res = requests.get(url)
res.encoding = res.apparent_encoding
return res.text def parseHtml(content):
#爬取整个网页的标题
title = re.findall(r'<title>(.*?)</title>', content)
print(title[0])
#爬取图片地址
urls = re.findall(r'<img .*src="\./(.*?)"', content)
baseUrl = 'http://www.eastmountyxz.com/' for i in range(len(urls)):
urls[i] = baseUrl + urls[i]
print(urls) #爬取文章信息
p = r'<div class="essay.*?">(.*?)</div>'
artcles = re.findall(p, content, re.S)
for a in artcles:
res = r'<a .*href="(.*?)">'
t1 = re.findall(res, a, re.S) #超链接
print(t1[0])
t2 = re.findall(r'<a .*?>(.*?)</a>', a, re.S) #标题
print(t2[0])
t3 = re.findall('<p style=.*?>(.*?)</p>', a, re.S) #摘要(
print(t3[0].replace(' ',''))
print('') if __name__ == '__main__':
url = "http://www.eastmountyxz.com/"
htmlString = getHtmlStr(url)
parseHtml(htmlString)
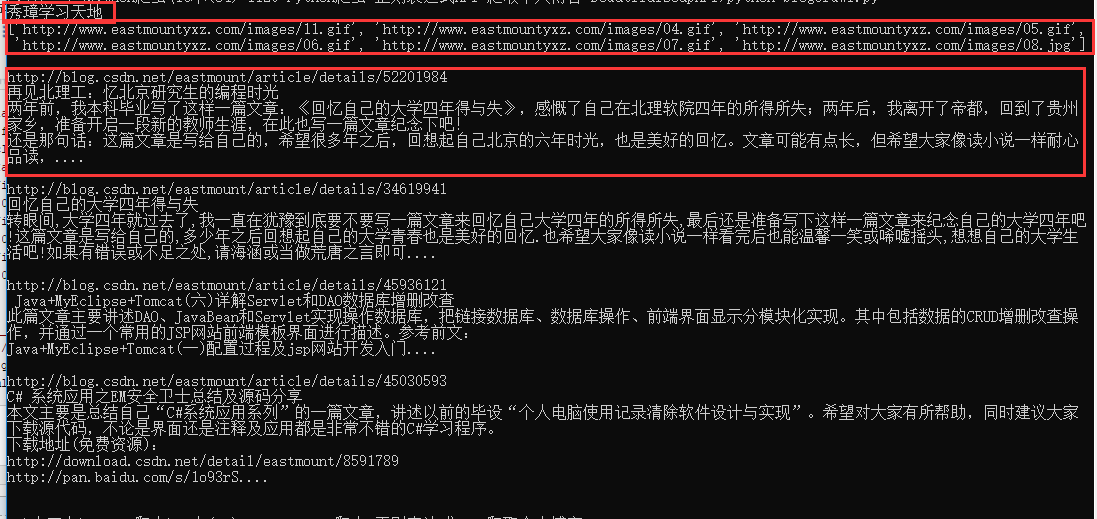
实例结果:
Python爬虫学习之正则表达式爬取个人博客的更多相关文章
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- Python爬虫之利用正则表达式爬取内涵吧
首先,我们来看一下,爬虫前基本的知识点概括 一. match()方法: 这个方法会从字符串的开头去匹配(也可以指定开始的位置),如果在开始没有找到,立即返回None,匹配到一个结果,就不再匹配. 我们 ...
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- Python爬虫学习笔记之爬取新浪微博
import requests from urllib.parse import urlencode from pyquery import PyQuery as pq from pymongo im ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
随机推荐
- 分析easyswoole3.0源码,体验es3(三)
demo在手,总得去试试看效果吧.我们先把默认的服务改成webserver,并且添加数据库的配置. 建立数据库,github里面有相关内容 CREATE TABLE `user_list` ( `us ...
- rpm --rebuilddb
rpm -ivh .....rpm 报Bus Error rpm --rebuilddb
- angular的json
在angular从servlet中获取的list数据是字符串格式,需要转为json格式,于是使用语法: $scope.findOne=function(id){ typeTemplateService ...
- AX_CreateAndPostPurch
static void CreateAndPostPurch(Args _args) { List il = new List(Types::Record); DocumentNum Document ...
- Spring Beans和依赖注入
您可以自由地使用任何标准的Spring框架技术来定义您的bean及其注入的依赖项.为简单起见,我们经常发现使用@ComponentScan(找到您的bean)和使用@Autowired(做构造函数注入 ...
- Python从入门到精通之Seventh!
函数浅析:可以减少代码重用,保持一致性,可扩展性,易维护性. 定义方法:def 函数名(形参): '''功能注释''' 代码块 打印函数名时,会出现函数的内存地址.两个函数名相同时, ...
- 移动端各种滚动场景需求的插件better-scroll
移动端各种滚动场景需求的插件: 文档地址: better-scroll:https://ustbhuangyi.github.io/better-scroll/doc/zh-hans/#better- ...
- Lua5.2&Lua5.3中废除的方法
Lua5.2和Lua5.3中居然把 table.getn() 废除了, webAdd = {"QQ", "BaiDu", "SMW"} fo ...
- 前台js接收后台的json数据
后台返回的json数据,如php的: return json_encode($data); 在前台 js接收如下: function json2object(str){ var jsstr = str ...
- 再谈docker基本命令
子曰,温故而知新 今日,再次看书之际,又寻得docker的几条使用命令,用小本本记下来 配置docker镜像源 当我们在拉去一些共有镜像时,默认,docker会向docker.io去获取,如果在拉取的 ...