http协议、web服务器、并发服务器(上)
1. HTTP格式
每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。HTTP协议是一种文本协议,所以,它的格式也非常简单。
1.1 HTTP GET请求的格式:
GET /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
1.2 HTTP POST请求的格式:
POST /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
当遇到连续两个\r\n时,Header部分结束,后面的数据全部是Body。
1.3 HTTP响应的格式:
HTTP/1.1 200 OK
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
HTTP响应如果包含body,也是通过\r\n\r\n来分隔的。
请再次注意,Body的数据类型由Content-Type头来确定,如果是网页,Body就是文本,如果是图片,Body就是图片的二进制数据。
当存在Content-Encoding时,Body数据是被压缩的,最常见的压缩方式是gzip,所以,看到Content-Encoding: gzip时,需要将Body数据先解压缩,才能得到真正的数据。压缩的目的在于减少Body的大小,加快网络传输。
2. Web静态服务器-显示固定的页面
import socket
def handle_client(new_client):
"""处理客户端请求"""
recv_data = new_client.recv(1024)
print(recv_data)
# 组装响应的内容
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "\r\n"
response_body = "6666"
response = response_headers + response_body
new_client.send(response.encode("utf-8"))
new_client.close()
def main():
# 创建套接字
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定本地消息
tcp_socket_server.bind(("", 8090))
# 套接字由主动变被动
tcp_socket_server.listen(128)
while True:
# 接收新的请求
new_client, client_addr = tcp_socket_server.accept()
handle_client(new_client)
# 关闭套接字
tcp_socket_server.close()
if __name__ == "__main__":
main()
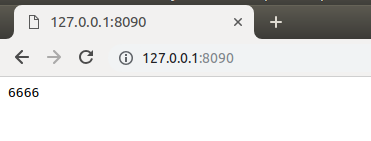
如上的代码仅仅只是向浏览器发送了简单的文本内容:6666
在浏览器中访问:
3. Web静态服务器-显示需要的页面
import socket
import re
def handle_client(new_client):
"""处理客户端请求"""
recv_data = new_client.recv(1024).decode("utf-8")
# GET / HTTP/1.1
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
http_request_line = request_header_lines[0];
get_file_name = re.match("[^/]+(/[^ ]*)", http_request_line).group(1)
print("file name is -> " + get_file_name)
# print(recv_data)
if get_file_name == "/":
get_file_name = "/index.html"
root_path = "./html"
get_file_name = root_path + get_file_name;
try:
f = open(get_file_name, "rb")
except:
response_headers = "HTTP/1.1 404 NOT FOUND\r\n"
response_headers += "\r\n"
response_body = b"page not found"
else:
# 组装响应的内容
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "\r\n"
response_body = f.read()
f.close()
new_client.send(response_headers.encode("utf-8"))
new_client.send(response_body)
new_client.close()
def main():
# 创建套接字
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定本地消息
tcp_socket_server.bind(("", 8090))
# 套接字由主动变被动
tcp_socket_server.listen(128)
while True:
# 接收新的请求
new_client, client_addr = tcp_socket_server.accept()
handle_client(new_client)
# 关闭套接字
tcp_socket_server.close()
if __name__ == "__main__":
main()
在浏览器中访问:
4. Web静态服务器-多进程版
import socket
import re
import multiprocessing
def handle_client(new_client):
"""处理客户端请求"""
recv_data = new_client.recv(1024).decode("utf-8")
# GET / HTTP/1.1
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
http_request_line = request_header_lines[0];
get_file_name = re.match("[^/]+(/[^ ]*)", http_request_line).group(1)
print("file name is -> " + get_file_name)
# print(recv_data)
if get_file_name == "/":
get_file_name = "/index.html"
root_path = "./html"
get_file_name = root_path + get_file_name;
try:
f = open(get_file_name, "rb")
except:
response_headers = "HTTP/1.1 404 NOT FOUND\r\n"
response_headers += "\r\n"
response_body = b"page not found"
else:
# 组装响应的内容
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "\r\n"
response_body = f.read()
f.close()
new_client.send(response_headers.encode("utf-8"))
new_client.send(response_body)
new_client.close()
def main():
# 创建套接字
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定本地消息
tcp_socket_server.bind(("", 8090))
# 套接字由主动变被动
tcp_socket_server.listen(128)
while True:
# 接收新的请求
new_client, client_addr = tcp_socket_server.accept()
p = multiprocessing.Process(target=handle_client, args=(new_client,))
p.start()
new_client.close()
# 关闭套接字
tcp_socket_server.close()
if __name__ == "__main__":
main()
5. Web静态服务器-多线程版
import socket
import re
import threading
def handle_client(new_client):
"""处理客户端请求"""
recv_data = new_client.recv(1024).decode("utf-8")
# GET / HTTP/1.1
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
http_request_line = request_header_lines[0];
get_file_name = re.match("[^/]+(/[^ ]*)", http_request_line).group(1)
print("file name is -> " + get_file_name)
# print(recv_data)
if get_file_name == "/":
get_file_name = "/index.html"
root_path = "./html"
get_file_name = root_path + get_file_name;
try:
f = open(get_file_name, "rb")
except:
response_headers = "HTTP/1.1 404 NOT FOUND\r\n"
response_headers += "\r\n"
response_body = b"page not found"
else:
# 组装响应的内容
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "\r\n"
response_body = f.read()
f.close()
new_client.send(response_headers.encode("utf-8"))
new_client.send(response_body)
new_client.close()
def main():
# 创建套接字
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定本地消息
tcp_socket_server.bind(("", 8090))
# 套接字由主动变被动
tcp_socket_server.listen(128)
while True:
# 接收新的请求
new_client, client_addr = tcp_socket_server.accept()
t = threading.Thread(target=handle_client, args=(new_client,))
t.start()
# 关闭套接字
tcp_socket_server.close()
if __name__ == "__main__":
main()
6. Web静态服务器-gevent版
import socket
import re
import gevent
from gevent import monkey
monkey.patch_all()
def handle_client(new_client):
"""处理客户端请求"""
recv_data = new_client.recv(1024).decode("utf-8")
# GET / HTTP/1.1
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
http_request_line = request_header_lines[0];
get_file_name = re.match("[^/]+(/[^ ]*)", http_request_line).group(1)
print("file name is -> " + get_file_name)
# print(recv_data)
if get_file_name == "/":
get_file_name = "/index.html"
root_path = "./html"
get_file_name = root_path + get_file_name;
try:
f = open(get_file_name, "rb")
except:
response_headers = "HTTP/1.1 404 NOT FOUND\r\n"
response_headers += "\r\n"
response_body = b"page not found"
else:
# 组装响应的内容
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "\r\n"
response_body = f.read()
f.close()
new_client.send(response_headers.encode("utf-8"))
new_client.send(response_body)
new_client.close()
def main():
# 创建套接字
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定本地消息
tcp_socket_server.bind(("", 8090))
# 套接字由主动变被动
tcp_socket_server.listen(128)
while True:
# 接收新的请求
new_client, client_addr = tcp_socket_server.accept()
g = gevent.spawn(handle_client, new_client)
g.join()
# 关闭套接字
tcp_socket_server.close()
if __name__ == "__main__":
main()
http协议、web服务器、并发服务器(上)的更多相关文章
- web服务器-并发服务器2
阅读目录 1.Web静态服务器-5-非堵塞模式 2.Web静态服务器-6-epoll 3.Web静态服务器-7-gevent版 4.知识扩展-C10K问题 一.Web静态服务器-5-非堵塞模式 单进程 ...
- 14_Web服务器-并发服务器
1.服务器概述 1.硬件服务器(IBM,HP): 主机 集群 2.软件服务器(HTTPserver Django flask): 网络服务器,在后端提供网络功能逻辑处理数据处理的程序或者架构等 3.服 ...
- Python复习笔记(十)Http协议--Web服务器-并发服务器
1. HTTP协议(超文本传输协议) 浏览器===>服务器发送的请求格式如下:(浏览器告诉服务器,浏览器的信息) GET / HTTP/1.1 Host: www.baidu.com Conne ...
- Web服务器-并发服务器-Epoll(3.4.5)
@ 目录 1.介绍 2.代码 关于作者 1.介绍 epoll是一种解决方案,nginx就是用的这个 中心思想:不要再使用多进程,多线程了,使用单进程,单线程去实现并发 在上面博客实现的代码中使用过的轮 ...
- Web服务器-并发服务器-单进程单线程非堵塞方式(3.4.3)
@ 目录 1.分析 2.代码 关于作者 1.分析 当socket去监听的时候,是堵塞的状态 通过tcp_sever_socket.setblocking(False)去设置不堵塞 当socket发现没 ...
- Web服务器-并发服务器-长连接(3.4.4)
@ 目录 1.说明 2.代码 关于作者 1.说明 每次new_socket都被强制关闭,造成短连接 所提不要关闭套接字 但是不关闭的话,浏览器不知道发完没有啊 此时用到header的属性Content ...
- Web服务器-并发服务器-协程 (3.4.2)
@ 目录 1.分析 2.代码 关于作者 1.分析 随着网站的用户量越来愈多,通过多进程多线程的会力不从心 使用协程可以缓解这一问题 只要使用gevent实现 2.代码 from socket impo ...
- Web服务器-并发服务器-多进程(3.4.1)
@ 目录 1.优化分析 2.代码 3. 关于作者 1.优化分析 在单进程的时候,相当于 是来一个客户,派一个人去服务一下 效率低,现在使用多进程来服务 假设场景 100个人同时访问页面 单进程:一次处 ...
- linux学习之多高并发服务器篇(一)
高并发服务器 高并发服务器 并发服务器开发 1.多进程并发服务器 使用多进程并发服务器时要考虑以下几点: 父最大文件描述个数(父进程中需要close关闭accept返回的新文件描述符) 系统内创建进程 ...
- 手把手让你实现开源企业级web高并发解决方案(lvs+heartbeat+varnish+nginx+eAccelerator+memcached)
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://freeze.blog.51cto.com/1846439/677348 此文凝聚 ...
随机推荐
- Java-异常初步练习
案例一: package com.esandinfo; /** * 自定义一个Exception类 */ class MyCustomException extends RuntimeExceptio ...
- c#图像处理入门(-bitmap类和图像像素值获取方法)
c#图像处理入门 -bitmap类和图像像素值获取方法 一.Bitmap类 Bitmap对象封装了GDI+中的一个位图,此位图由图形图像及其属性的像素数据组成.因此Bitmap是用于处理由像素数据定义 ...
- JAVA RSA加密AES加密
RSA加密: import sun.misc.BASE64Decoder; import sun.misc.BASE64Encoder; import javax.crypto.Cipher; imp ...
- 背水一战 Windows 10 (113) - 锁屏: 将 Application 的 Badge 通知和 Tile 通知发送到锁屏, 将 secondary tile 的 Badge 通知和 Tile 通知发送到锁屏
[源码下载] 背水一战 Windows 10 (113) - 锁屏: 将 Application 的 Badge 通知和 Tile 通知发送到锁屏, 将 secondary tile 的 Badge ...
- 双十一福利,阿里云1核2G一年最低只要99
活动期间,新用户可任选1款购买,限购1台,拼团后团内每增加1名新购用户,全团再享10%优惠 (50%封顶),买贵返差 又是只给新用户的福利,比上次的699一年的活动要差一点.如果之前注册了没下手的用户 ...
- 微博第三方登录使用social_django实现显示登陆的用户名
首先修改social_soce源码,将用户信息添加进cookie 将其修改为: response = backend.strategy.redirect(url) payload = jwt ...
- php--include 、require
一.include .require 定义:包含并运行指定文件 问题:查询了这两个语言结构的资料,有人说,什么require 先执行,什么include后执行. 思考:我觉得官方文档已经解释的很清楚 ...
- 什么 是JavaScript中的字符串类型之间的转换问题详解? 部分4
字符串类型 单双引号都可以!建议使用单引号!(本人建议:个人觉得单个字符串更利于网页优化@特别地方特别处理!); 判断字符串的长度获取方式:变量名.length html中转义符: < < ...
- python(leetcode)-48旋转图像
给定一个 n × n 的二维矩阵表示一个图像. 将图像顺时针旋转 90 度. 说明: 你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵.请不要使用另一个矩阵来旋转图像. 示例 1: 给定 m ...
- vue 项目实战 (vue全家桶之--- vuex)
老规矩先安装 npm install vuex --save 在看下面内容之前 你应该大概的看了一边vuex官方的文档对vuex有个大概对了解 首先 vuex 是什么? vuex 是属于vue中的什么 ...