Generative Adversarial Nets[pix2pix]
本文来自《Image-to-Image Translation with Conditional Adversarial Networks》,是Phillip Isola与朱俊彦等人的作品,时间线为2016年11月。
作者调研了条件对抗网络,将其作为一种通用的解决image-to-image变换方法。这些网络不止用来学习从输入图像到输出图像的映射,同时学习一个loss函数去训练这个映射。这让传统需要各种不同loss函数的问题变成了可以采用统一方法来解决成为可能。作者发现这种方法在基于标签maps合成图片,从边缘图像重建目标以及着色图像等方面非常有效。
0 引言
图像处理,计算机图形学,计算机视觉中很多问题可以看成是将输入图像“转换”到输出图像上。如将RGB图像转换到梯度图像,边缘图像,或者语义标签map等等。而传统解决image-to-image的问题是将该问题划分成几个子问题(如[15, 24, 19, 8,10, 52, 32, 38, 17, 57, 61]),其实都是一样的,即从pixels预测pixels。

本文的目标是提倡一种通用架构来解决这些问题。而基于CNN的方法,还必须告知目标函数是什么,但是却必须小心的设计,因为假如让CNN最小化预测值和ground-truth之间的欧式距离,那么回导致得到模糊的预测图片,因为欧式距离最小化时基于所有可能的输出上平均值最小,那么就会导致模糊图片生成。随之而来的loss函数就强制让CNN做一些设定的行为,如输出图片的锐化等等,而这是一直未完美解决的问题。
而如果让模型自己去学习所需要的loss函数,我们只需要告知这个图片是真的还是假的,那么就十分完美了,最近的GAN[12,23,43,51,62]就是干这个事情的。这时候模糊的图片就会很容易被判别器给否掉了。即让生成器自己去学习内在的loss函数去自适应对应的数据集。本文作者两个目的:
- 证明条件GAN可以解决很多这类问题,并生成可以接受的结果;
- 提出一个简单的框架去得到好的结果,并分析几个重要的结构选择。
0.5 前人工作
关于图像建模的结构化loss
image-to-image变换问题通常被整理成逐像素分类或者回归问题[27,34,38,57,61]。这些形式化描述将输出空间视为“非结构化”,即在给定输入图像的情况下,每个输出像素被视为在条件上独立于所有其他输出像素。条件GAN是学习一个结构化loss(structured loss),结构化loss会惩罚输出的联合设置。大量的文献都考虑这种loss,如条件随机场[9],SSIM指标[55],特征匹配[14],非参数化loss[36],卷积伪先验[56],基于匹配协方差统计的损失[29]。条件GAN不同于学到的loss,理论上,其实惩罚介于输出和目标之间任何可能的不同结构。
条件GAN
前人早就将条件GAN用在如离散标签[12,22,40],文本[45],和图像等等。图像条件的模型是从一个标准map进行图像预测[54],未来帧预测[39],产品照片生成[58],从稀疏标注中进行图片生成[30,47](文献[46]中式用一个自动回归方法来解决这个问题)。其他虽然也有将GAN用在image-to-image上,但是只用无约束GAN,并依赖其他项(如L2回归)来强制输出是约束于输入的。这些文献在如图像修复[42],未来状态预测[63],基于用户操作的图像编辑[64],风格转换[37]和超分辨率[35]。每个方法都只适用具体领域。本文方法希望做到普适,同时这就需要比那些方法相对简单。
不同于之前的几种生成器和判别器的结构选择,本文的生成器使用的是U-Net结构[49];判别器使用的是卷积“PatchGAN”分类器,其只惩罚在图像块尺度规模上的结构。一个类似的PatchGAN结构在文献[37]中早就有所提及,其实为了抓取局部类型统计。本文展示该方法可以适用更广泛的问题,还分析了更改patch size带来的影响。
1 本文方法
GAN是生成模型,可以学习一个随机噪音向量\(z\)到输出图像\(y\)的映射:\(G:z \rightarrow y\)。而条件GAN是基于观测的图片\(x\)和随机噪音向量\(z\),学习映射到\(y\):\(G:\{x,z\}\rightarrow y\)。该训练过程如图2.
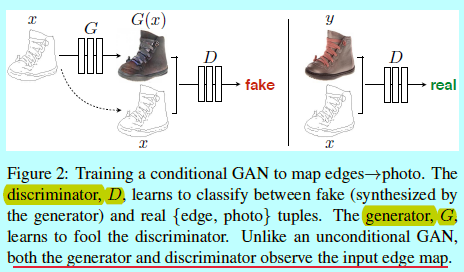
1.1 目标函数
一个条件GAN的目标函数可以表示为:
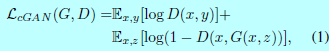
这里G试图最小化该目标函数,而D试图最大化该目标函数,即\(G^*=\arg \min_G\max_D\mathcal{L}_cGAN(G,D)\)
为了测试条件(conditioning)判别器的重要性,需要对比一个无条件变化的判别器,即其没有观测变量\(x\):
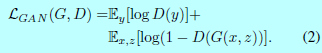
之前的文献已经证实将GAN的目标函数与一些其他loss(如l2距离)混合起来是有好处的[42]。判别器的工作依然没变,但是生成器不止需要愚弄判别器,还需要在受到L2约束下接近ground-truth。本文采用L1距离,因为L1能减少输出的图片模糊:
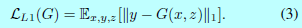
最终的目标函数为:
\[G^*=\arg\min_G\max_D\mathcal{L}_cGAN(G,D)+\lambda\mathcal{L}_{L1}(G), \,\, \tag{4}\]
没有\(z\),该GAN还是学到从\(x\)映射到\(y\)的映射,不过会生成判别性输出,因此会无法匹配除了delta函数的其他任何分布。之前的条件GAN意识到了这点,所以给生成器在\(x\)之外,提供高斯噪音\(z\)作为输入。在初始实验中,作者并未找到该策略的有效性,即让生成器简单忽略该噪音,这与Mathieu的论证吻合[39]。在本文最终模型中,作者只在在训练和测试阶段的生成器的几层的dropout项中采用噪音。尽管存在dropout噪音,作者只在输出上观察到微小的随机性。设计的条件GAN可以提供高随机性输出,从而捕获它们建模的条件分布的完整熵,是当前工作还没解决的问题。
1.2 网络结构
作者调整了[43]中的生成器和判别器结构,判别器和生成器同时使用convolution-BatchNorm-ReLU形式的模块。
1.2.1 带有skips的生成器
image-to-image转换问题的一个定义特征是它们将高分辨率输入网格映射到高分辨率输出网格。另外,输入和输出虽然看起来结果不同,不过底层结构都是差不多的。因此,作者设计生成器的结构也是这个思路。
许多前人的工作[29,42,54,58,63]都是基于编码器-解码器网络。这样的网络结构中,输入经过许多层慢慢下采样,直到一个bottleneck层,然后再逆转这个操作。这样的网络需要所有的信息经过所有层,包含bottleneck。对于许多图像转换问题,在输入和输出之间共享大量低级信息是一个很好的想法,并且希望直接在网络上传送该信息。例如,图像着色桑,输入和输出是共享突出边缘的位置的。
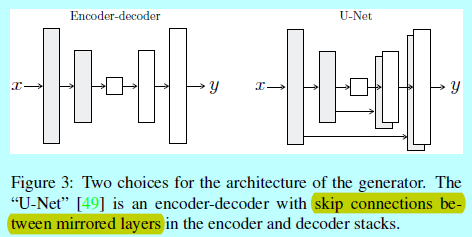
为了让生成器有一种规避bottleneck的方法,增加了skip的连接,形状如U-Net[49](如图3)。特别的,在层\(i\)和层\(n-i\)之间增加skip 连接,这里\(n\)是层的总量。每个skip连接简单的将层\(i\)与层\(n-i\)之间所有的通道进行concatenation。
1.2.2 马尔可夫判别器(PatchGAN)
众所周知L2 loss(看图4,L1也会模糊)会让图像生成问题中生成的图像变得模糊,虽然这些loss不能准确的抓取高频纹理,可是他们还是能够抓取低频轮廓的。对于这种情况,不需要一个全新的框架来强制低频的正确性,L1就够了。

那么受其启发,让GAN判别器只对高频结构进行建模,让L1项去对低频进行建模,如式子4。为了对高频进行建模,需要将注意力限制到局部图像块上。因此,作者设计出一个判别器结构,这里称其为PatchGAN,只惩罚图像块尺度上的结构。该判别器试图区分是否图像中每个\(N\times N\)块是真的还是假的。将该判别器以卷积方式划过整个图像,平均所有的响应来提供判别器最终的输出。
在后面,证明了虽然N可以远小于图片的完整size,可是仍然可以生成高质量的结果。这是有利的,因为更小的PatchGAN有着更少的参数,运行更快,可以应用在任意大的图像。
这样鉴别器有效地将图像建模为马尔可夫随机场,其是假设像素之间的独立可分性性超过了块的直径。这种联系在文献[37]中有所探讨,同样对纹理模型[16,20]和风格[15,21,24,36]也有常见假设。PatchGAN因此可以理解成一种纹理/风格 loss形式。
1.3 优化和推论
为了优化该网络,遵循标准方法:交替的迭代,先在D上迭代一次,然后在G上迭代一次。如最初始GAN中所述,训练G时,不最小化\(log(1-D(x,G(x,z)))\),而是最大化\(\log D(x,G(x,z))\)。另外,在优化D时,将目标除以2,这让D相对G而言减慢了速度。本文使用minibatch SGD和Adam解析器,学习率为0.0002,动量参数分别为\(\beta_1=0.5,\beta_2=0.999\)。
在推论阶段,运行生成器,其配置如训练过程一致。这不同于传统的,在测试时候也还是用dropout,并且基于测试batch使用BN,而不是用训练时候的batch。当batchsize设置为1时,BN被称为“实例标准化”,并且已被证明在图像生成任务中有效[53]。 在本实验中,根据实验使用1到10之间的batchsize。
2 实验
为了研究条件GAN的泛化性,作者在很多任务和数据集上进行了测试,包含图形任务,如相片生成;视觉任务,如语义分割:
- 语义 labels$\leftrightarrow $photo, 基于Cityscapes数据集[11];
- 建筑 labels$\leftrightarrow $photo,基于CMP Facades[44];
- Map$\leftrightarrow $aerial photo, 从谷歌地图爬取的数据;
- BW$\rightarrow $color photos,基于[50]训练;
- Edges$\rightarrow $ photo, 训练数据来自[64,59];二值边缘使用HED边缘检测器[57]加上后处理完成的;
- Sketch$\rightarrow \(photo,测试 edges\)\rightarrow $photo 人类绘制的模型来自[18];
- Day$\rightarrow $ night,基于[32];
- thermal$\rightarrow $color photos,训练数据来自[26];
- photo withmissing pixels $\rightarrow $ inpainted photo,基于Paris streetview,来自[13].
每个数据集的详细训练过程在附录材料中。在所有情况中,输入和输出都是1-3通道的图片。结果在图8,9,10,11,12,13,14,15,16,17,18,19中。











在图20中,是几个失败的案例。

数据要求和速度
即使在小型数据集上也可以获得不错的结果。
其中正面训练集只包含400张图片(结果在图13)。
而day to night训练集之包含91张图片(结果在图14)。这种量级的数据集下,训练自然是很快的;例如图13中的结果只需要在单张titian x gpu上训练小于2个小时就够了,在测试阶段,所有的模型之需要少于1s的时间。
2.1 评估指标
评估合成图片的质量一直是一个未解决的难题[51]。传统的评估指标如逐像素均值平方误差不会评估结果的联合统计信息,所以不会测量这个意在抓取结构化loss的结构。为了更全面地评估结果的视觉质量,作者采用了两种策略:
- 首先,在亚马逊标注平台上(Amazon Mechanical Turk,AMT)运行"real vs fake"项目,其中涉及的图形问题,如着色和照片生成,让真人来给出结果,这里的map生成,aerial photo 生成和图像着色都是用这个方法;
- 其次,基于现有的识别系统测量是否生成的cityscapes足够真实。该指标相似于[51]中的"inception score",[54]中的目标检测评估,[61,41]中的“semantic interpretability”评估。
AMT perceptual studies
对于AMT实验,遵循[61]的协议方式:给Turker展现的是一系列图片,其实包含真实和生成的。每次测试,每张图片只出现1s,然后图片会消失,这时候让Turker在后续时间中给出那一张是假的。略
在着色实验中,真实和假的图片都从同样的灰度输入上生成;对于Map$\leftrightarrow $aerial photo,真实和假的图片不是从同样的输入上生成的,为了让任务变得更困难,和避免floor-level现象,是基于256x256分辨率图片训练的,但是利用全卷积变换在512x512的分辨率上测试,然后下采样并以256x256分辨率呈现给Turker。对于着色,是在256x256分辨率上训练和测试,并以同样的分辨率呈现给Turker。
FCN-score
近些的工作[51,54,61,41]尝试使用预训练的语义分类器去测量。直观的原理是如果生成的图像是真实的,基于真实图片训练的分类器可以很好的区分合成的图片。本文采用主流的做语义分割的FCN-8s[38]结构,基于cityscapes数据集训练。然后通过对合成的图片进行分类来区分是否是合成的。
2.2 目标函数的分析
那么式子4中哪部分是最重要的?作者通过每次丢失一项来分别研究L1项,GAN项的影响,然后将无条件GAN(式子2)与条件GAN(式子1)上的判别器进行对比。
图4表示在\(labels \rightarrow photo\)问题上不同变化的影响,L1会生成合理但是很模糊的结果。cGAN(此时式子4中\(\lambda=0\))会生成更锐化的结果,但是在某些应用上会引入视觉造假的情况。将这两项合起来(\(、lambda=100\))可以减少这种造假现象。
作者在cityscapes \(labels \rightarrow photo\)任务上使用FCN-score方式进行评估质量(如表1)。
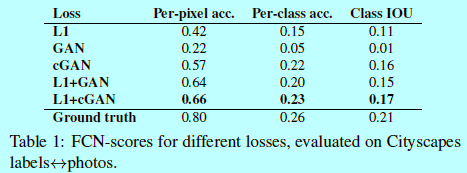
如表1,基于GAN的目标可以获得更高的得分,表明合成的图片包含更多可识别的结构。同时作者测试了从判别器D上移除条件之后(称其为GAN)的影响。在这种情况下,loss不会惩罚输入和输出之间的误匹配,而这种结果十分不好;通过检测该结果发现生成器会坍缩到接近准确输出的位置,而全不顾输入是什么情况(即骗过判别器,可是没视觉意义)。所以可以发现这种情况下,loss实际上是测量输入和输出之间的匹配质量,的确cGAN比GAN好太多。然而,增加的L1项表明输出会更关心输入,因为L1 loss会惩罚ground-truth与合成输出之间的距离(其中ground-truth与输入是项匹配的,而合成输出并不是,所以通过惩罚合成输出与ground-truth,等于间接强制合成输出去匹配输入部分)。L1+GAN同样会生成关于输入label的合成输出。所以结合所有项,L1+cGAN是最好的。
色彩
条件GAN的一个影响是它还能生成清晰的图片,超分辨空间结构即使在输入label map中并不存在。我们可以想象cGAN在空间维度上有类似"锐化"的效果,即让图像更具色彩性。就如L1在某个位置不确定是什么边缘纹理时会赋予模糊一样,当不确定像素应该采用的几个合理颜色值中的哪一个时,它也会赋予平均的浅灰色。具体而言,L1会通过选择基于可能的颜色基础上条件概率密度函数的中值来达到最小化的目的。另一方不,对抗Loss可以在实际中对那些非真实浅灰色输出变得敏感,并倾向匹配真实颜色分布。
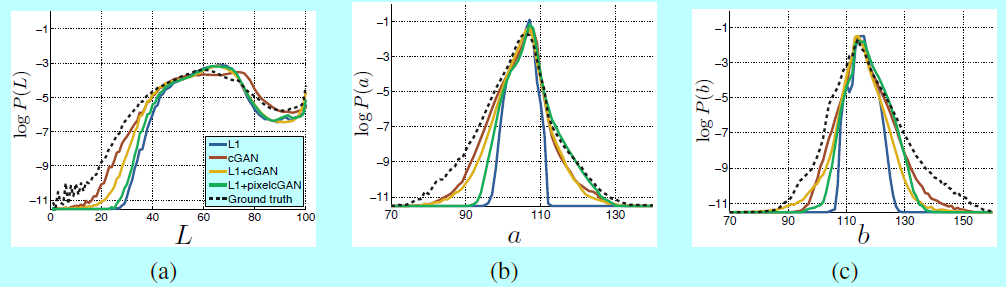


图7中,作者调研了是否cGAG可以在Cityscapes数据集上获得这样的效果。该图显示了在Lab颜色空间中基于输出颜色上的边际距离。很明显L1会生成ground-truth更窄的分布,这也证明了L1的确会倾向生成平均,浅灰色颜色。另一方面,使用cGAN会将输出分布更推向ground-truth。
2.3 生成器结构的分析
U-Net结构运行low-level的信息能够快捷(shortcuts)的穿插于网络中。不过这会让结果更好么?

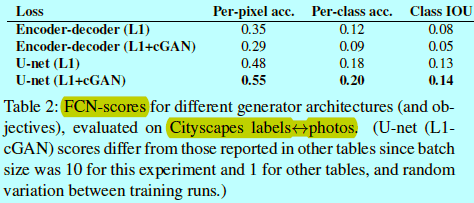
图5和表2对比了在cityscape生成上编码-解码器与U-Net的结构效果。其中编码-解码器是基于U-Net切断其中的skip连接实现的。可以发现编码-解码器不能生成真实的图片,而U-Net的优势不只限于让cGAN变得更好:不过当U-Net和编码-解码器都基于L1 loss训练时,U-Net获得更好的效果。
2.4 从pixelGAN到PatchGAN到ImageGAN
作者测试了变化判别器感受野的patch size N带来的影响,从1x1的PixelGAN到一个完整的286x286的ImageGAN。

图6显示了这些差别的结果。
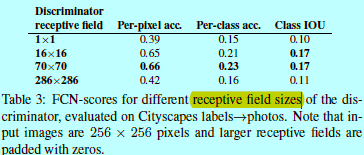
表3基于FCN-score对结果进行了评估。除非特别之处,本文中都基于70x70的PatchGAN进行实验,并采用L1+cGAN作为loss。
PixelGAN无意于空间清晰度,但是提升了结果的多彩性(如图7)。例如图6中,bus在使用L1 loss时是灰色的,而用PixelGAN是红色的。颜色直方图匹配是图像处理中一个常见的问题,PixelGAN是一个轻量级的解决方法。
使用16x16的PatchGAN足以提升结果的锐化程度并获得好的FCN-scores,但是也会生成造假的现象。70x70 PatchGAN会减轻造假现象,并获得稍微更好的得分结果。对于286x296的ImageGAN,不会明显提升结果的视觉质量,的确也会得到相对较低的FCN-scores。这可能是因为ImageGAN有更多参数和更深的通道,所以更难训练。
全卷积变换
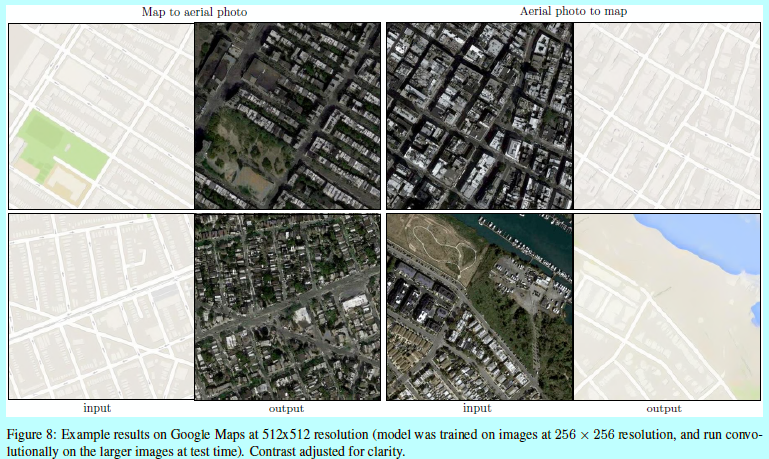
PatchGAN的一个优势是一个固定size的patch 判别器可以应用到任意大小的图像上。同样作者会将该生成器应用在比训练时候更大的图像上。作者在\(map \leftrightarrow aerial photo\)任务上。在256x256图像上训练好一个生成器,在512x512上进行测试。图8展示了该方法的效果。
2.5 感知验证(Perceptual validation)
作者在\(map \leftrightarrow aerial photograph\)和\(grascale \rightarrow color\)任务结果上进行了感性真实性的验证。基于AMT对\(map \leftrightarrow aerial photograph\)进行评估的结果在表4。

aerial photos中用算法生成的图片愚弄了18.9%的真人,明显高于L1的结果;在\(photo \rightarrow map\)方向中,本方法只愚弄了6.1%的真人,这相比L1的方法就并没高太多。这可能是因为在map中微小的结构化误差会更明显,因为map(地图)有网格几何,而aerial photographs相比更混乱一些。
作者在ImageNet上训练了着色,并通过[61,34]引入了测试分割进行测试。本文方法,基于L1+cGAN,愚弄了22.5%的真人(表5).

同时测试了[61]的结果,和基于[61]的方法使用L2 loss的变种。cGAN得分相似于[61]的L2变种(不过在自举测试上有明显的不同),但是要比[61]的方法要短,只愚弄了27.8%的贞二年。作者发现他们的方法在着色上有特别的工程实现。
2.6 语义分割
cGAN在那些输出是高度细节相关或者photographic的问题上有效果,而这在图像处理和图形任务中是很普遍的,那么对于视觉任务,如语义分割,其中输出要比输入相对简单。
为了做该任务测试,在cityscape \(photo \rightarrow labels\)上训练cGAN(分有和没L1 loss)。图10就是对应结果,定量分类准确度在表6.
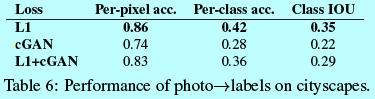
有趣的是,基于没有L1 loss下训练的cGAN得到一个相对合理的准确度结果。虽然cGAN获得不少成功,还远不到最好解决的程度:如表6中,简单实用L1回归可以得到比cGAN更好的结果。作者认为对于视觉任务,目标(预测的输出接近ground-truth)相比图形任务没那么模糊,所以重构loss如L1会更有效。
2.7 社区驱动研究
略
reference:
[1] Bertrand gondouin. https://twitter.com/ bgondouin/status/818571935529377792. Accessed, 2017-04-21. 9
[2] Brannon dorsey. https://twitter.com/ brannondorsey/status/806283494041223168. Accessed, 2017-04-21. 9
[3] Christopher hesse. https://affinelayer.com/ pixsrv/. Accessed: 2017-04-21. 9
[4] Gerda bosman, tom kenter, rolf jagerman, and daan gosman. https://dekennisvannu.nl/site/artikel/ Help-ons-kunstmatige-intelligentie-testen/ 9163. Accessed: 2017-08-31. 9
[5] Jack qiao. http://colormind.io/blog/. Accessed: 2017-04-21. 9
[6] Kaihu chen. http://www.terraai.org/ imageops/index.html. Accessed, 2017-04-21. 9
[7] Mario klingemann. https://twitter.com/ quasimondo/status/826065030944870400. Accessed, 2017-04-21. 9
[8] A. Buades, B. Coll, and J.-M. Morel. A non-local algorithm for image denoising. In CVPR, volume 2, pages 60–65. IEEE, 2005. 1
[9] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In ICLR, 2015. 2
[10] T. Chen, M.-M. Cheng, P. Tan, A. Shamir, and S.-M. Hu. Sketch2photo: internet image montage. ACM Transactions on Graphics (TOG), 28(5):124, 2009. 1
[11] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR), 2016. 4, 16
[12] E. L. Denton, S. Chintala, R. Fergus, et al. Deep generative image models using a laplacian pyramid of adversarial networks. In NIPS, pages 1486–1494, 2015. 2
[13] C. Doersch, S. Singh, A. Gupta, J. Sivic, and A. Efros. What makes paris look like paris? ACM Transactions on Graphics, 31(4), 2012. 4, 13, 17
[14] A. Dosovitskiy and T. Brox. Generating images with perceptual similarity metrics based on deep networks. arXiv preprint arXiv:1602.02644, 2016. 2
[15] A. A. Efros and W. T. Freeman. Image quilting for texture synthesis and transfer. In SIGGRAPH, pages 341–346. ACM, 2001. 1, 4
[16] A. A. Efros and T. K. Leung. Texture synthesis by nonparametric sampling. In ICCV, volume 2, pages 1033–1038. IEEE, 1999. 4
[17] D. Eigen and R. Fergus. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, pages 2650–2658, 2015. 1
[18] M. Eitz, J. Hays, and M. Alexa. How do humans sketch objects? SIGGRAPH, 31(4):44–1, 2012. 4, 12
[19] R. Fergus, B. Singh, A. Hertzmann, S. T. Roweis, and W. T. Freeman. Removing camera shake from a single photograph. ACM Transactions on Graphics (TOG), 25(3):787– 794, 2006. 1
[20] L. A. Gatys, A. S. Ecker, and M. Bethge. Texture synthesis and the controlled generation of natural stimuli using convolutional neural networks. arXiv preprint arXiv:1505.07376, 12, 2015. 4
[21] L. A. Gatys, A. S. Ecker, and M. Bethge. Image style transfer using convolutional neural networks. CVPR, 2016. 4
[22] J. Gauthier. Conditional generative adversarial nets for convolutional face generation. Class Project for Stanford CS231N: Convolutional Neural Networks for Visual Recognition, Winter semester, 2014(5):2, 2014. 2
[23] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D.Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, 2014. 2, 4, 6, 7
[24] A. Hertzmann, C. E. Jacobs, N. Oliver, B. Curless, and D. H. Salesin. Image analogies. In SIGGRAPH, pages 327–340. ACM, 2001. 1, 4
[25] G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 313(5786):504–507, 2006. 3
[26] S. Hwang, J. Park, N. Kim, Y. Choi, and I. So Kweon. Multispectral pedestrian detection: Benchmark dataset and baseline. In CVPR, pages 1037–1045, 2015. 4, 13, 16
[27] S. Iizuka, E. Simo-Serra, and H. Ishikawa. Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification. ACM Transactions on Graphics (TOG), 35(4), 2016. 2
[28] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. 2015. 3, 4
[29] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. 2016. 2, 3
[30] L. Karacan, Z. Akata, A. Erdem, and E. Erdem. Learning to generate images of outdoor scenes from attributes and semantic layouts. arXiv preprint arXiv:1612.00215, 2016. 2
[31] D. Kingma and J. Ba. Adam: A method for stochastic optimization. ICLR, 2015. 4
[32] P.-Y. Laffont, Z. Ren, X. Tao, C. Qian, and J. Hays. Transient attributes for high-level understanding and editing of outdoor scenes. ACM Transactions on Graphics (TOG), 33(4):149, 2014. 1, 4, 16
[33] A. B. L. Larsen, S. K. Sønderby, and O. Winther. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015. 3
[34] G. Larsson, M. Maire, and G. Shakhnarovich. Learning representations for automatic colorization. ECCV, 2016. 2, 8, 16
[35] C. Ledig, L. Theis, F. Husz´ar, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv preprint arXiv:1609.04802, 2016. 2
[36] C. Li and M. Wand. Combining markov random fields and convolutional neural networks for image synthesis. CVPR, 2016. 2, 4
[37] C. Li and M. Wand. Precomputed real-time texture synthesis with markovian generative adversarial networks. ECCV, 2016. 2, 4
[38] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431– 3440, 2015. 1, 2, 5
[39] M. Mathieu, C. Couprie, and Y. LeCun. Deep multi-scale video prediction beyond mean square error. ICLR, 2016. 2, 3
[40] M. Mirza and S. Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014. 2
[41] A. Owens, P. Isola, J. McDermott, A. Torralba, E. H. Adelson, and W. T. Freeman. Visually indicated sounds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2405–2413, 2016. 5
[42] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros. Context encoders: Feature learning by inpainting. CVPR, 2016. 2, 3, 13, 17
[43] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015. 2, 3, 16
[44] R. ˇ S. Radim Tyleˇcek. Spatial pattern templates for recognition of objects with regular structure. In Proc. GCPR, Saarbrucken, Germany, 2013. 4, 16
[45] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee. Generative adversarial text to image synthesis. arXiv preprint arXiv:1605.05396, 2016. 2
[46] S. Reed, A. van den Oord, N. Kalchbrenner, V. Bapst, M. Botvinick, and N. de Freitas. Generating interpretable images with controllable structure. Technical report, Technical report, 2016. 2, 2016. 2
[47] S. E. Reed, Z. Akata, S. Mohan, S. Tenka, B. Schiele, and H. Lee. Learning what and where to draw. In Advances In Neural Information Processing Systems, pages 217–225, 2016. 2
[48] E. Reinhard, M. Ashikhmin, B. Gooch, and P. Shirley. Color transfer between images. IEEE Computer Graphics and Applications, 21:34–41, 2001. 7
[49] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, pages 234–241. Springer, 2015. 2, 3
[50] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. IJCV, 115(3):211–252, 2015. 4, 8, 16
[51] T. Salimans, I. Goodfellow,W. Zaremba, V. Cheung, A. Radford, and X. Chen. Improved techniques for training gans. arXiv preprint arXiv:1606.03498, 2016. 2, 4, 5
[52] Y. Shih, S. Paris, F. Durand, andW. T. Freeman. Data-driven hallucination of different times of day from a single outdoor photo. ACM Transactions on Graphics (TOG), 32(6):200, 2013. 1
[53] D. Ulyanov, A. Vedaldi, and V. Lempitsky. Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022, 2016. 4
[54] X. Wang and A. Gupta. Generative image modeling using style and structure adversarial networks. ECCV, 2016. 2, 3, 5
[55] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600–612, 2004. 2
[56] S. Xie, X. Huang, and Z. Tu. Top-down learning for structured labeling with convolutional pseudoprior. 2015. 2
[57] S. Xie and Z. Tu. Holistically-nested edge detection. In ICCV, 2015. 1, 2, 4
[58] D. Yoo, N. Kim, S. Park, A. S. Paek, and I. S. Kweon. Pixellevel domain transfer. ECCV, 2016. 2, 3
[59] A. Yu and K. Grauman. Fine-Grained Visual Comparisons with Local Learning. In CVPR, 2014. 4
[60] A. Yu and K. Grauman. Fine-grained visual comparisons with local learning. In CVPR, pages 192–199, 2014. 16
[61] R. Zhang, P. Isola, and A. A. Efros. Colorful image colorization. ECCV, 2016. 1, 2, 5, 7, 8, 16
[62] J. Zhao, M. Mathieu, and Y. LeCun. Energy-based generative adversarial network. arXiv preprint arXiv:1609.03126, 2016. 2
[63] Y. Zhou and T. L. Berg. Learning temporal transformations from time-lapse videos. In ECCV, 2016. 2, 3, 8
[64] J.-Y. Zhu, P. Kr¨ahenb¨uhl, E. Shechtman, and A. A. Efros. Generative visual manipulation on the natural image manifold. In ECCV, 2016. 2, 4, 16
Generative Adversarial Nets[pix2pix]的更多相关文章
- Generative Adversarial Nets[content]
0. Introduction 基于纳什平衡,零和游戏,最大最小策略等角度来作为GAN的引言 1. GAN GAN开山之作 图1.1 GAN的判别器和生成器的结构图及loss 2. Condition ...
- 论文笔记之:Conditional Generative Adversarial Nets
Conditional Generative Adversarial Nets arXiv 2014 本文是 GANs 的拓展,在产生 和 判别时,考虑到额外的条件 y,以进行更加"激烈 ...
- (转)Deep Learning Research Review Week 1: Generative Adversarial Nets
Adit Deshpande CS Undergrad at UCLA ('19) Blog About Resume Deep Learning Research Review Week 1: Ge ...
- 论文笔记之:Generative Adversarial Nets
Generative Adversarial Nets NIPS 2014 摘要:本文通过对抗过程,提出了一种新的框架来预测产生式模型,我们同时训练两个模型:一个产生式模型 G,该模型可以抓住数据分 ...
- Generative Adversarial Nets[BEGAN]
本文来自<BEGAN: Boundary Equilibrium Generative Adversarial Networks>,时间线为2017年3月.是google的工作. 作者提出 ...
- Generative Adversarial Nets[CycleGAN]
本文来自<Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks>,时间线为2017 ...
- Generative Adversarial Nets[CAAE]
本文来自<Age Progression/Regression by Conditional Adversarial Autoencoder>,时间线为2017年2月. 该文很有意思,是如 ...
- Generative Adversarial Nets[Wasserstein GAN]
本文来自<Wasserstein GAN>,时间线为2017年1月,本文可以算得上是GAN发展的一个里程碑文献了,其解决了以往GAN训练困难,结果不稳定等问题. 1 引言 本文主要思考的是 ...
- Generative Adversarial Nets[Pre-WGAN]
本文来自<towards principled methods for training generative adversarial networks>,时间线为2017年1月,第一作者 ...
随机推荐
- error 2593 operator << 不明确的可能的解决方法
编译Martinez算法时遇到该问题,提示重载的<<操作符调用不明确. 解决方法为:在cpp文件中将重载的该操作符的实现前添加完整的命名空间路径.
- Postgresql的隐藏系统列
转自 https://www.2cto.com/database/201206/137301.html Postgresql的隐藏系统列 和oracle数据库一样,postgresql也有自身 ...
- timeout 命令
命令简介 运行指定的命令,如果在指定时间后仍在运行,则杀死该进程.用来控制程序运行的时间. 使用方法 1 2 3 timeout [选项] 数字[后缀] 命令 [参数]... 后缀 s 代表秒(默认值 ...
- python scapy的用法之ARP主机扫描和ARP欺骗
python scapy的用法之ARP主机扫描和ARP欺骗 目录: 1.scapy介绍 2.安装scapy 3.scapy常用 4.ARP主机扫描 5.ARP欺骗 一.scapy介绍 scapy是一个 ...
- IO测试工具之fio详解
目前主流的第三方IO测试工具有fio.iometer和Orion,这三种工具各有千秋. fio在Linux系统下使用比较方便,iometer在window系统下使用比较方便,Orion是oracle的 ...
- IPerf——网络测试工具介绍与源码解析(2)
对于IPerf源码解析,我是基于2.0.5版本在Windows下执行的情况进行分析的,提倡开始先通过对源码的简单修改使其能够在本地编译器运行起来,这样可以打印输出一些中间信息,对于理解源码的逻辑,程序 ...
- 力扣算法题—060第K个排列
给出集合 [1,2,3,…,n],其所有元素共有 n! 种排列. 按大小顺序列出所有排列情况,并一一标记,当 n = 3 时, 所有排列如下: "123" "132&qu ...
- 微信小程序多层嵌套循环,二级数组遍历
小程序中的遍历循环类似于angularJS的遍历. 二级数组遍历有一个坑.二级遍历wx:for循环的时候,需要注意.(代码如下) JS代码: data: { groups: [ [ { title: ...
- WPF设计の自定义窗体
效果图如下: 实现思路: 1.继承Window类 2.为自定义的CustomWindow类设计窗体样式(使用Blend很方便!) 3.为窗体增加最大最小化和关闭按钮,并实现鼠标拖拽改变窗体大小(使用D ...
- eclipse导入maven项目, A resource exists with a different case: '/xxx'.
eclipse 导入maven 项目出现 这是由于你的workspace里有相同的项目, 这时在metadata里可以看到所有的project信息 只需在eclipse的package explore ...