第一章:python基础语法| 字符编码| 条件语句...
1、编程语言介绍
编程就是写代码,让计算机帮你做事情。计算机底层是电路,只认识二进制0和1.
机器语言&汇编语言
语言进化历史:机器、汇编、高级。机器语言只接受二进制代码;汇编语言是采用英文缩写的标识符,更容易识别和记忆,只是对0和1进行代替;高级语言,把好多机器指令变成一句话了,如C\C++、java、PHP、python、GO等。
它们的区别:在于转换二进制的方式不同。C\C++运行速度快,python、Java、php运行速度比较慢。
编译类:先翻译成二进制,产生两个文件,运行的时候是二进制文件。程序执行效率高,编译后程序运行时不需要重新翻译,直接使用编译的结果就可以了,但是跨平台性能差。如C\C++、Delphi等。
通过操作系统把它运行起来,操作系统下面才是CPU、运行内存等
解释型:“同声翻译”,一边翻译成目标代码即机器语言一边执行,运行效率比较低且不能生成可独立执行的可执行文件,应用程序不能脱离解释器,这种方式比较灵活,可以动态调整、修改应用程序。可以跨平台,开发效率高。如:java、python等。
2、python简介和安装
Python解释器:
CPython官方版本;IPython在交互方式上有所增强;PyPy执行速度快,使用JIT技术,进行动态编译;Jython;IronPython。
安装:
在python官网上面https://www.python.org/downloads/windows/找你所需要的版本。
测试安装是否成功
windows --> 运行 --> 输入cmd ,然后回车,弹出cmd程序,输入python,如果能进入交互环境 ,代表安装成功。
如果不成功,应该设置环境变量:右击我的电脑—属性,选择高级系统设置—环境变量—找到path
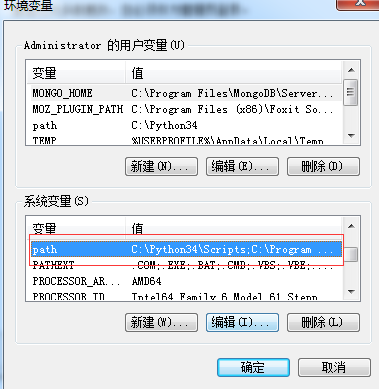
找到python安装文件,前边要加分号,复制粘贴其路径,然后,再复制Scripts的路径加在后边,最后加分号即可,确实,设置成功。
3、变量
作用:存数据,占内存,存储程序运行的中间结果,然后以备后边的代码调用。
表示方法:数字、字母和下划线的组合;数字不能开头;以下关键字不能声明为变量名['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']。
常量,全部大写。
4、格式化输出| 浮点数和科学计数法
input()里边默认是字符串
#格式化输出
name = input("Name:")
age = input("Age:")
job = input("Job:")
info = '''
---------------info of %s-----------
Name:%s
Age:%s
Job:%s
-----------------end----------------
''' %(name, name, age, job)
print(info)
## 格式化字符:数字格式化的那些坑
>>> m = 3.1416926
>>> print("pi is %f" %m)
pi is 3.141693
>>> print("pi is %.2f" %m)
pi is 3.14
# 我只想输出2位小数:%.2f,此处是四舍五入 >>>
>>> m = 10.6
>>> print("pi is %i" %m)
pi is 10
>>> print("pi is %.0f" %m)
pi is 11
# 区别:%i 不四舍五入,直接切掉小数部分 >>>
>>> m = 100
>>> print("have fun %+i" %m)
have fun +100
>>> print("have fun %.2f" % -0.01)
have fun -0.01
# 显示正号,负号根据数字直接显示 >>>
>>>
>>> m = 100
>>> print("have fun % i" %m)
have fun 100
>>> print("have fun % +i" %m)
have fun +100
>>> print("have fun % .2f" %-0.01)
have fun -0.01
# 加空格,空格和正好只能显示一个 >>>
>>> m = 123.123123123
>>> print("have fun %.2e" %m)
have fun 1.23e+02
>>> print("have fun %.4E" %m)
have fun 1.2312E+02
# 科学计数法 %e %E >>>
>>> m1 = 123.123123123
>>> m2 = 1.2
>>> print("have fun %g" %m1)
have fun 123.123
>>> print("have fun %g" %m2)
have fun 1.2
# 小数位数少的时候自动识别用浮点数,数据复杂的时候自动识别用科学计数法
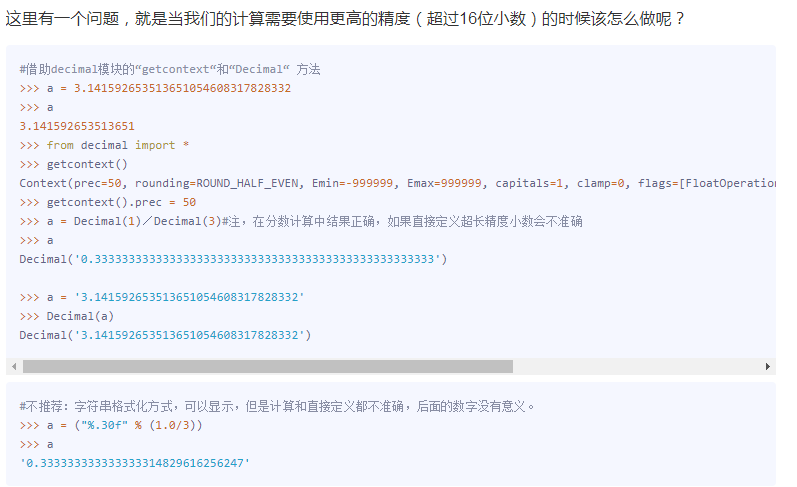
浮点数:有限小数或无限循环。
prec表示精度。
5、运算符
算术运算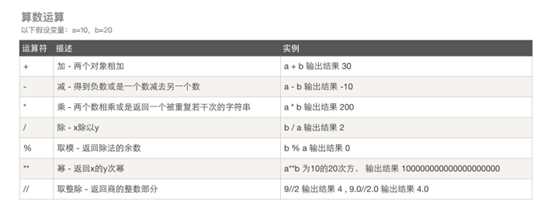
比较运算

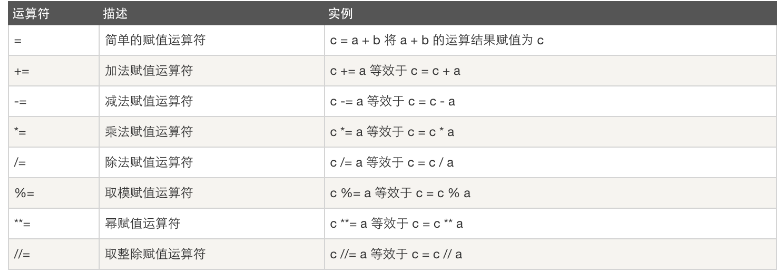
赋值运算
逻辑运算

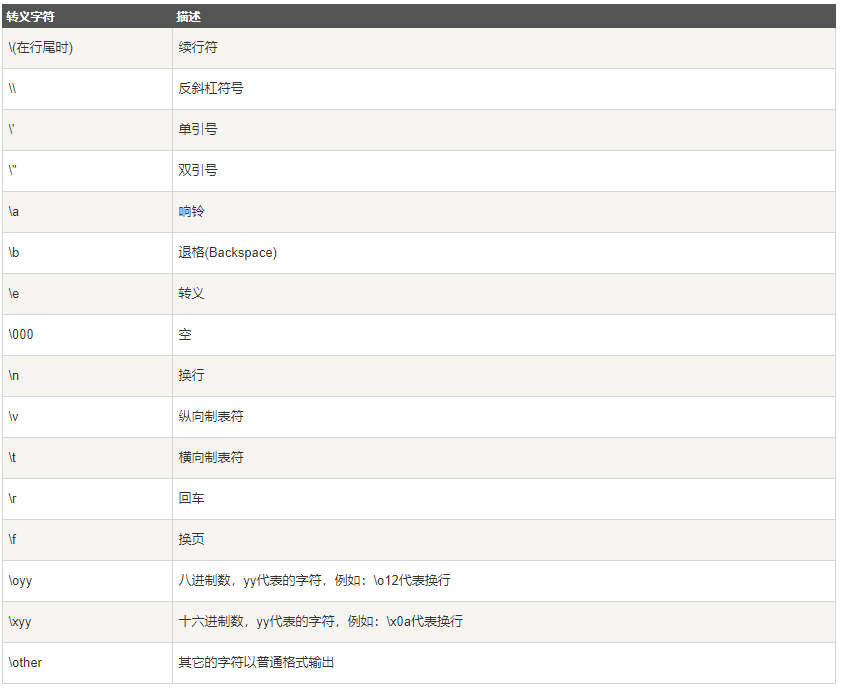
转义字符
6、Bool值
bool布尔型:True,False,用于做判断;
布尔型的本质:True的值等于1,False的值等于0
bool()函数:将值转换为布尔型,其中只有以下情况bool()返回False:0, 0.0, None,'', [] , {}
>>> print(bool(), bool(), bool(-), bool([, ,]), bool(''), bool({}))
False True True True False False
>>> print(bool(()))
False
7、二进制| 进制拾遗
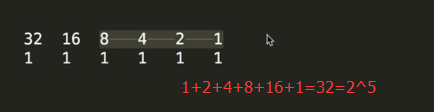
八进制、16进制



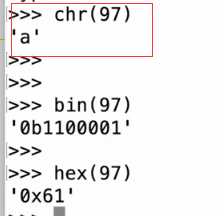
16进制与2进制的转换:https://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
8、ASCII码
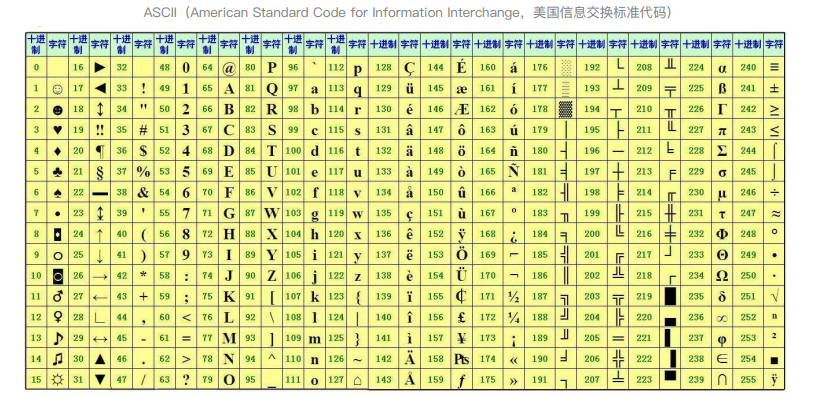
每一位0或者1所占的空间单位为bit(比特),这是计算机中最小的表示单位;
每8个bit组成一个字符,这是计算机中最小的存储单位。

9、字符编码
GB2312----gbk---gb18030---Unicode---GTF-8
py2里默认ASCII码,如果想写中文,把默认编码改了 #! -*- coding: utf-8 -*- 或者 #! encoding:UTF-8 ;py3默认UTF-8
alex博客:http://www.cnblogs.com/alex3714/articles/7550940.html
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- Unicode 2-4字节 已经收录136690个字符,并还在一直不断扩张中...
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个。 字符怎么传到硬盘上
无论以什么编码在内存里显示字符,存到硬盘上都是2进制。
字符编码的转换
Unicode的两个作用:包含所有国家的语言和跟所有国家的语言有一个对应关系。

unicode与gbk的映射表 http://www.unicode.org/charts/
python3代码执行流程
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
- 把代码字符串按照语法规则进行解释,
- 所有的变量字符都会以unicode编码声明
编码转换
Py3 自动把文件编码转为unicode必定是调用了什么方法,这个方法就是,decode(解码) 和encode(编码)
UTF-8 --> decode 解码 --> Unicode
Unicode --> encode 编码 --> GBK / UTF-8 .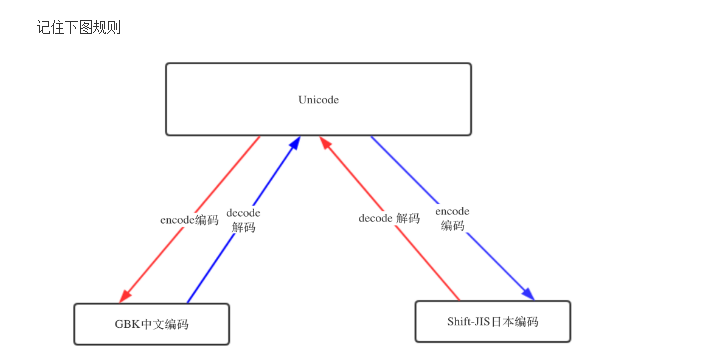
python的bytes类型
bytes类型,即字节类型, 它把8个二进制一组称为一个byte,用16进制来表示。python2的字符串其实更应该称为字节串。 通过存储方式就能看出来, 但python2里还有一个类型是bytes呀,难道又叫bytes又叫字符串? 嗯 ,是的,在python2里,bytes == str , 其实就是一回事。
python3比python2做了非常多的改进,其中一个就是终于把字符串变成了unicode,文件默认编码变成了utf-8,这意味着,只要用python3,无论你的程序是以哪种编码开发的,都可以在全球各国电脑上正常显示,真是太棒啦!
PY3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制啦。
为什么在py3里,把unicode编码后,字符串就变成了bytes格式? 你直接给我直接打印成gbk的字符展示不好么?我想其实py3的设计真是煞费苦心,就是想通过这样的方式明确的告诉你,想在py3里看字符,必须得是unicode编码,其它编码一律按bytes格式展示。
10、流程控制
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。
Python代码的缩进规则:具有相同缩进的代码被视为代码块;
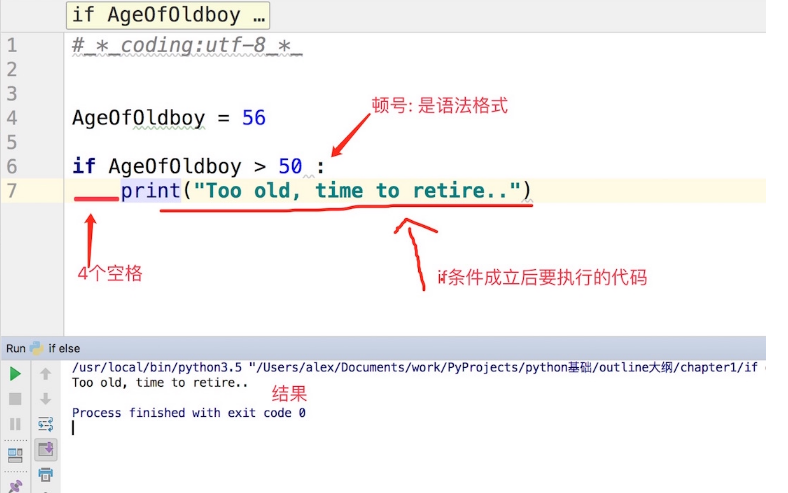
单分支
IF条件:
满足条件后要执行的代码。
双分支
if 条件:
满足条件执行代码
else:
if条件不满足就走这段
# 两种条件判断:if-else flag = False
name = 'luren'
if name == 'python': # 判断变量否为'python'
flag = True # 条件成立时设置标志为真
print( 'welcome boss') # 并输出欢迎信息
else:
print(name) # 条件不成立时输出变量名称
多分支
回到流程控制上来,if...else ...可以有多个分支条件
if 条件:
满足条件执行代码
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
else:
上面所有的条件不满足就走这段
score = int(input("输入分数-->>:"))
if score > 100:
print("最高分数才100哦")
elif score > 90:
print("A")
elif score > 80:
print("B")
elif score > 60:
print("C")
elif score > 40:
print("D")
else:
print("E")
While循环
while 条件:
执行代码...count = 0
while count <= 100 : #只要count<=100就不断执行下面的代码
print("loop ", count )
count +=1 #每执行一次,就把count+1,要不然就变成死循环啦,因为count一直是0
如果我想实现打印1到100的偶数呢?
加上 if count % 2 == 0: #是偶数
死循环
while 是只要后边条件成立(也就是条件结果为真)就一直执行,怎么让条件一直成立呢?
count = 0
while True: #True本身就是真呀
print("你是风儿我是沙,缠缠绵绵到天涯...",count)
count +=1
循环终止语句
- break用于完全结束一个循环,跳出循环体执行循环后面的语句
- continue和break有点类似,区别在于continue只是终止本次循环,接着还执行后面的循环,break则完全终止循环
- pass是空语句,是为了保持程序结构的完整性((不中断也不跳过))
while...else 语句
while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句
猜年龄游戏:age = 24
count = 0
while count < 3:
guess_age = int(input("your guess_age:"))
if guess_age == age:
print("恭喜抱得美人归")
break
else:
count += 1
age = 24
count = 0
while count < 3:
guess_age = int(input("your guess_age:"))
if guess_age == age:
print("恭喜抱得美人归")
break
elif guess_age > age:
print("猜小一点")
else:
print("try bigger")
count += 1
if count == 3:
choice = input("你个笨蛋,还想玩吗?(y|Y)")
if choice == "y"or choice == "Y":
count = 0
else:
break
9、练习题:
- 简述编译型与解释型语言的区别,且分别列出你知道的哪些语言属于编译型,哪些属于解释型 答:编译类:先翻译成二进制,产生两个文件,运行的时候是二进制文件。程序执行效率高,编译后程序运行时不需要重新翻译,直接使用编译的结果就可以了,但是跨平台性能差。如C\C++、Delphi等。
解释型:“同声翻译”,一边翻译成目标代码即机器语言一边执行,运行效率比较低且不能生成可独立执行的可执行文件,应用程序不能脱离解释器,这种方式比较灵活,可以动态调整、修改应用程序。可以跨平台,开发效率高。如:java、python等
- 执行 Python 脚本的两种方式是什么 答:一进入解释器的交互式模式:调试方便,无法永久保存代码;二脚本文件的方式(使用nodpad++演示):永久保存代码,但是不方便调试
- Pyhton 单行注释和多行注释分别用什么? 答:单行注释用#,多行注释用 ‘’’ '''
- 布尔值分别有什么? 答:布尔值有True 和False
- 声明变量注意事项有那些? 答:一数字、字母和下划线的组合;二是数字不能开头;三是以下关键字不能声明为变量名['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']。
- 如何查看变量在内存中的地址? 答:
id(变量名)#查看内存地址。 - 写代码
- 实现用户输入用户名和密码,当用户名为 seven 且 密码为 123 时,显示登陆成功,否则登陆失败!
_username = "seven"
_passworld = "123"
username = input("username:")
passworld = input("passworld:")
if username == _username and passworld == _passworld:
print("登录成功") - 实现用户输入用户名和密码,当用户名为 seven 且 密码为 123 时,显示登陆成功,否则登陆失败,失败时允许重复输入三次
_username = "seven"
_passworld = "123"
count = 0
while count < 3:
username = input("username:")
passworld = input("passworld:")
if username == _username and passworld == _passworld:
print("登录成功")
break
else:
print("登录失败,请重新输入")
count += 1 - 实现用户输入用户名和密码,当用户名为 seven 或 alex 且 密码为 123 时,显示登陆成功,否则登陆失败,失败时允许重复输入三次
#_username = ["seven" , "alex"] #运用列表
_username = "seven" or "alex"
_passworld = "123"
count = 0
while count < 3:
username = input("username:")
passworld = input("passworld:")
if username == "seven" or "alex" and passworld == _passworld:
#if username in _username and passworld == _passworld: #判断
print("登录成功")
break
else:
print("登录失败,请重新输入")
count += 1
- 实现用户输入用户名和密码,当用户名为 seven 且 密码为 123 时,显示登陆成功,否则登陆失败!
写代码
a. 使用while循环实现输出2-3+4-5+6...+100 的和
i = 2
total_1 = 0
total_2 = 0
while i <=100:
if i%2 == 0:
total_1 += i
else:
total_2 += -i
i += 1
total = total_1 + total_2
print(total)b. 使用 while 循环实现输出 1,2,3,4,5, 7,8,9, 11,12
count = 1
while count <= 12:
if count == 10 or count==6:
pass
else:
print("loop",count)
count +=1c. 使用while 循环输出100-50,从大到小,如100,99,98...,到50时再从0循环输出到50,然后结束
i = 101
while i >= 51:
i -=1
print(i)
i = 0
while i <= 50:
print(i)
i +=1d. 使用 while 循环实现输出 1-100 内的所有奇数
i = 1
while i <= 100:
if i %2==1:
print(i)
i+=1e. 使用 while 循环实现输出 1-100 内的所有偶数
i = 0
while i <= 100:
if i %2==0:
print(i)
i+=1现有如下两个变量,请简述 n1 和 n2 是什么关系?
n1 = 123456
n2 = n1 关系是给数据123456起了另外一个别名n2,相当于n1和n2都指向该数据的内存地址
制作趣味模板程序(编程题)
需求:等待用户输入名字、地点、爱好,根据用户的名字和爱好进行任意显示
如:敬爱可爱的xxx,最喜欢在xxx地方干xxxusername = input("name:")
place = input("place:")
love = input("love:")
info = '''
敬爱的%s最喜欢在 %s干 %s
'''% (username,place,love)
print(info)输入一年份,判断该年份是否是闰年并输出结果。(编程题)
注:凡符合下面两个条件之一的年份是闰年。 (1) 能被4整除但不能被100整除。 (2) 能被400整除。year = int(input("please input a year:"))
if (year %2==0 and year %100!=0) or (year %400==0):
print(year,"是闰年")
else:
print(year,"不是闰年")假设一年期定期利率为3.25%,计算一下需要过多少年,一万元的一年定期存款连本带息能翻番?(编程题)
money = 10000
year = 0
while money <= 20000:
year +=1
money = money * (1+0.0325)
print(year,money)
print(year,"年以后,一万元的一年定期存款连本带息能翻番")
第一章:python基础语法| 字符编码| 条件语句...的更多相关文章
- 第1章 Python基础之字符编码
阅读目录 一.什么是字符编码 二.字符编码分类 三.字符编码转换关系 3.1 程序运行原理 3.2 终极揭秘 3.3 补充 总结 回到顶部 一.什么是字符编码 计算机要想工作必须通电,也就是说'电'驱 ...
- web前端学习python之第一章_基础语法(一)
web前端学习python之第一章_基础语法(一) 前言:最近新做了一个管理系统,前端已经基本完成, 但是后端人手不足没人给我写接口,自力更生丰衣足食, 所以决定自学python自己给自己写接口哈哈哈 ...
- web前端学习python之第一章_基础语法(二)
web前端学习python之第一章_基础语法(二) 前言:最近新做了一个管理系统,前端已经基本完成, 但是后端人手不足没人给我写接口,自力更生丰衣足食, 所以决定自学python自己给自己写接口哈哈哈 ...
- [Python笔记][第一章Python基础]
2016/1/27学习内容 第一章 Python基础 Python内置函数 见Python内置函数.md del命令 显式删除操作,列表中也可以使用. 基本输入输出 input() 读入进来永远是字符 ...
- 第一章 –– Java基础语法
第一章 –– Java基础语法 span::selection, .CodeMirror-line > span > span::selection { background: #d7d4 ...
- 第一章 Python基本语法
寒假不能荒废,终于静下心来认真地开始学习Python,在这里与大家分享一下所学知识,希望能对像我这样的小白有所帮助,如有错误之处,谢大佬不吝赐教!! 编程语言包括机器语言.汇编语言.高级语言.超 ...
- python基础_字符编码
字符编码的历史 阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII 阶段二:为了满足中文,中国人定制了GBK 阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的 ...
- 第一模块·开发基础-第1章 Python基础语法
Python开发工具课前预习 01 Python全栈开发课程介绍1 02 Python全栈开发课程介绍2 03 Python全栈开发课程介绍3 04 编程语言介绍(一) 05 编程语言介绍(二)机器语 ...
- Python笔记·第一章—— Python基础(一)
一.Python的简介 1.Python的由来与版本 1.1 python的由来 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆(中文 ...
随机推荐
- Spring Cloud构建微服务架构(五)服务网关
通过之前几篇Spring Cloud中几个核心组件的介绍,我们已经可以构建一个简略的(不够完善)微服务架构了.比如下图所示: 我们使用Spring Cloud Netflix中的Eureka实现了服务 ...
- Codeforces 671D Roads in Yusland [树形DP,线段树合并]
洛谷 Codeforces 这是一个非正解,被正解暴踩,但它还是过了. 思路 首先很容易想到DP. 设\(dp_{x,i}\)表示\(x\)子树全部被覆盖,而且向上恰好延伸到\(dep=i\)的位置, ...
- Vue项目构建开发笔记(vue-lic3.0构建的)
1.router.js里面 { path: '/about', name: 'about', // route level code-splitting // this generates a sep ...
- SSM框架应用
一.更新用户密码功能的实现 1. 新建页面 profile.jsp,添加三个输入框和提交按钮:用户输入当前密码.输入新密码.再次确认密码和重置按钮.修改密码按钮: 2. 前台 js(JavaScrip ...
- 状态压缩dp小结
最近一段时间算是学了一些状态压缩的题目,在这里做个小结吧 首先是炮兵布阵类题目,这类题目一开始给定一个矩形,要求在上面放置炮兵,如果在一格放了炮兵那么周围的某些格子就不能放炮兵,求最大能放置炮兵的数量 ...
- solt插槽简单使用实例
在父组件内可以定义方法,变量 等,还可以在父组件中使用呢. 样式可以在子组件里写,也可以在父组件写. 子组件: <template> <div class="admin-u ...
- Python之yield简明详解
yield在Python中被称之为生成器(只能在函数中使用),他的作用是将函数中每次执行的结果以类似元组的形式保存起来一遍后续使用. 什么是生成器? 通过列表生成式,我们可以直接创建一个列表.但是,受 ...
- OrCAD Capture CIS 为库里的元器件添加新属性
1.进入元器件编辑界面 2.菜单:Options > Part Properties... 3.在窗口User Properties中,点击按钮New... 4.在弹出的子窗口NewProper ...
- Gson解决字段为空是报错的问题
json解析有很多工具,这里说的是最常用也是解析速度最快的Gson,Gson是google家出的,有一个缺点就是无法设置null替换, 我们只能手动的批量替换服务器返回的null了,正常的接口定义的时 ...
- springboot配置Druid监控
整体步骤: (1) —— Druid简单介绍,具体看官网: (2) —— 在pom.xml配置druid依赖包: (3) —— 配置application.propertie ...