JVM 调优-给你的java应用看看病
java 应用
1 cpu 负载过高
1.1 分析问题
首先我们通过top 命令进行分析,找出消耗最多cpu的java 进程id 。
找出对应的进程id 后,我们可以通过 top -Hp 进程id 命令来找出该进程中占用cpu最多的前几个线程id。
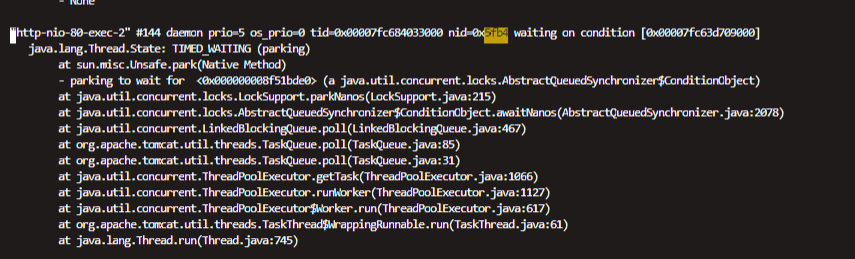
我们使用 jstack -l 进程pid > /tmp/java_pid.log 输出java的堆栈日志到文件 /tmp/java_pid.log。
我们将刚刚查询到的java进程中占用cpu最多的前几个线程id。进行转化为16进制。
printf "%X" 线程id
我们在java堆栈日志文件中找到上面转化为16进制的线程的pid对应的 日志。
实际操作步骤流程图:

补充:有时可能是我们代码创建线程过多导致的问题:
# 查看该进程有多少线程
ps p 9534 -L -o pcpu,pmem,pid,tid,time,tname,cmd|wc -l
1.2 解决方案
我们把对应的线程id的日志拿给我们的开发,进行定位错误,这里容易定位出的错误是:
- 线程处于WAITING(等待状态)
- 线程BLOCKED(阻塞)
我可以把定位到代码位置,告诉开发,让开发查看对应的代码是否有问题。
2 内存占用过多
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域。
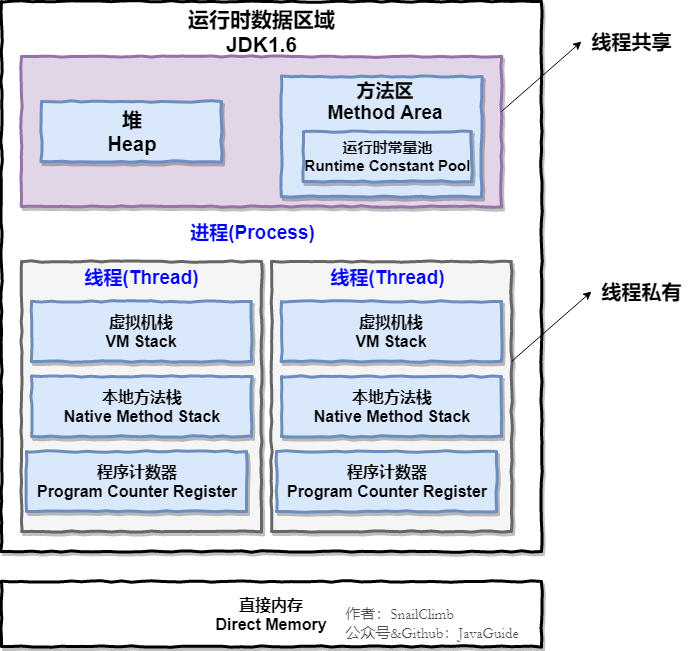
这些组成部分一些是线程私有的,其他的则是线程共享的。
线程私有的:
- 程序计数器
- 虚拟机栈
- 本地方法栈
线程共享的:
- 堆
- 方法区
- 直接内存
2.1 从内存回收方面
Java 堆是垃圾收集器管理的主要区域,因此也被称作GC堆(Garbage Collected Heap).从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以Java堆还可以细分为:新生代和老年代:再细致一点有:Eden空间、From Survivor、To Survivor空间等。进一步划分的目的是更好地回收内存,或者更快地分配内存。
在 JDK 1.8中移除整个永久代,取而代之的是一个叫元空间(Metaspace)的区域(永久代使用的是JVM的堆内存空间,而元空间使用的是物理内存,直接受到本机的物理内存限制)。关于metaspace的详细讲解看:JVM源码分析之Metaspace解密
java 实际的内存使用是这样的,大多数情况下,对象在新生代中 eden 区分配。当 eden 区没有足够空间进行分配时,虚拟机将发起一次Minor GC(新生代GC).将eden 区的一些存活对象移动到Survivor 区,当Survivor区的大小,不够储存eden 区的存活对象时,那么就会将它移动到老年区(Old Generation ),当老年区满了时候将触发一次 Full GC .
在实际工作中,我们可以使用 jmap -heap pid 来查看当前的进程的 java 堆的分布情况。
[root@iz23nb5ujp69 ~]# jmap -heap 11764
Attaching to process ID 11764, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.73-b02
using thread-local object allocation.
Parallel GC with 2 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0 #GC后,如果发现空闲堆内存占到整个预估堆内存的40%,则放大堆内存的预估最大值,但不超过固定最大值。默认该值是40
MaxHeapFreeRatio = 100 #GC后,如果发现空闲堆内存占到整个预估堆内存的100%,则收缩堆内存预估最大值。默认的是70
MaxHeapSize = 2147483648 (2048.0MB) # 最大的堆内存
NewSize = 715653120 (682.5MB) # 新生代初始大小
MaxNewSize = 715653120 (682.5MB) # 新生代最大大小
OldSize = 1431830528 (1365.5MB) #老年代
NewRatio = 2 # 新生代和老年代的 内存比例: 1:2 默认值
SurvivorRatio = 8 # Eden区与Survivor区的大小比值,设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10,Eden区和Survivor区 的实际比例值是会变动的
MetaspaceSize = 21807104 (20.796875MB) # 元空间大小
CompressedClassSpaceSize = 1073741824 (1024.0MB) # 压缩时可用的最大的内存
MaxMetaspaceSize = 17592186044415 MB #元空间可用最大大小
G1HeapRegionSize = 0 (0.0MB) #G1 收集器的内存大小
Heap Usage:
PS Young Generation # 新生代
Eden Space: # Eden
capacity = 372768768 (355.5MB)
used = 185979712 (177.36407470703125MB)
free = 186789056 (178.13592529296875MB)
49.89144154909459% used # eden 可用区使用率,该值满了将触发 young gc
From Space: # Survivor1
capacity = 175112192 (167.0MB)
used = 47983120 (45.76026916503906MB)
free = 127129072 (121.23973083496094MB)
27.401358781460516% used
To Space: # Survivor2
capacity = 167772160 (160.0MB)
used = 0 (0.0MB)
free = 167772160 (160.0MB)
0.0% used
PS Old Generation # 老年代
capacity = 1431830528 (1365.5MB)
used = 257274632 (245.35620880126953MB)
free = 1174555896 (1120.1437911987305MB)
17.9682320616089% used # 老年代 可用区使用率,该值满了将触发 full gc
适当的young gc 可以让清理一些不存活的对象,但是短时间大量的 young GC 是会导致 Full GC 的,那么Full gc 是尽量不要产生的,当一个应用,产生大量的full GC是不正常的, 过多的GC和Full GC是会占用很多的系统资源(主要是CPU),影响系统的吞吐量。
young gc:

Metadata GC

full gc :

GC 日志解析
对了,如何在日志中打印GC日志,我们在后面的配置中会讲到。
[GC (Allocation Failure) [DefNew: 279616K->19156K(314560K), 0.0595827 secs] 279616K->19256K(1013632K), 0.0601044 secs] [Times: user=0.03 sys=0.02, real=0.06 secs]
GC:
表明进行了一次垃圾回收,前面没有Full修饰,表明这是一次Minor GC。
Allocation Failure:
表明本次引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了。
279616K->19156K(314560K) 260460
三个参数分别为:GC前该内存区域(这里是年轻代)使用容量,GC后该内存区域使用容量,该内存区域总容量。
0.0595827 secs
表示GC耗时
279616K->19256K(1013632K)
堆区垃圾回收前的大小,堆区垃圾回收后的大小,堆区总大小。
0.0071945 secs
Times: user=0.01 sys=0.00, real=0.01 secs
分别表示用户态耗时,内核态耗时和总耗时
新生代清理的内存:279616 - 19156 = 260460k
堆区减少的内存:279616 - 19256 = 260360k
新生代存到老年代的 数据为 260460k - 260360k
那么如何查询一个应用发生young Gc 和Full GC 的次数和耗时时间。我们可以使用jstat 。
jstat 查询GC 次数和Full Gc 次数
jstat -gcutil pid 2000 10 (每隔2秒输出一次结果,输出10次)
[root@iz23nb5ujp69 ~]# jstat -gcutil 3626 2000 10
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
56.01 0.00 8.21 88.19 98.44 96.92 27350 353.229 41 32.416 385.645
56.01 0.00 8.30 88.19 98.44 96.92 27350 353.229 41 32.416 385.645
56.01 0.00 8.41 88.19 98.44 96.92 27350 353.229 41 32.416 385.645
56.01 0.00 8.56 88.19 98.44 96.92 27350 353.229 41 32.416 385.645
56.01 0.00 9.00 88.19 98.44 96.92 27350 353.229 41 32.416 385.645
56.01 0.00 9.27 88.19 98.44 96.92 27350 353.229 41 32.416 385.645
56.01 0.00 9.34 88.19 98.44 96.92 27350 353.229 41 32.416 385.645
56.01 0.00 9.46 88.19 98.44 96.92 27350 353.229 41 32.416 385.645
56.01 0.00 9.57 88.19 98.44 96.92 27350 353.229 41 32.416 385.645
56.01 0.00 9.70 88.19 98.44 96.92 27350 353.229 41 32.416 385.645
S0 — Heap上的 Survivor space 0 区已使用空间的百分比
S1 — Heap上的 Survivor space 1 区已使用空间的百分比
E — Heap上的 Eden space 区已使用空间的百分比
O — Heap上的 Old space 区已使用空间的百分比
M - 表示的是Klass Metaspace以及NoKlass Metaspace两者总共的使用率
CSS -表示的是NoKlass Metaspace的使用率
YGC — 从应用程序启动到采样时发生 Young GC 的次数
YGCT– 从应用程序启动到采样时 Young GC 所用的时间(单位秒)
FGC — 从应用程序启动到采样时发生 Full GC 的次数
FGCT– 从应用程序启动到采样时 Full GC 所用的时间(单位秒)
GCT — 从应用程序启动到采样时用于垃圾回收的总时间(单位秒)
FGC Scavenge GC要慢,因此应该尽可能减少Full GC。
导致young Gc 和 full GC 的原因有哪些:
- young 可用区 设置的太小 ,young gc 设置的太小就会导致 ,多次young gc,多次young gc 也就导致 oldGeneration 不断增大,最终导致full gc
- Old Generation 设置的太小, 当 Old Generation 太小的话就会导致 经常占满,然后会进行full GC 。
- System.gc()被显示调用 , 垃圾回收不要手动触发,尽量依靠JVM自身的机制。
- Meta(元数据)区可用内存设置的太少。
jvm 默认使用的配置
我们拿我们的tomcat 应用来说,我们如果使用默认的配置,我们使用jmap -heap 线程 查看
[root@www apache-tomcat-8.5.38]# jmap -heap 7568
Attaching to process ID 7568, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.131-b11
using thread-local object allocation.
Mark Sweep Compact GC
Heap Configuration:
MinHeapFreeRatio = 40 # 这个默认值在上面已经说到了,对于heap,我们尽量不要让它自动调整
MaxHeapFreeRatio = 70 # 这个默认值在上面已经说到了,对于heap,我们尽量不要让它自动调整
MaxHeapSize = 480247808 (458.0MB)
NewSize = 10485760 (10.0MB)
MaxNewSize = 160038912 (152.625MB)
OldSize = 20971520 (20.0MB) # 默认的值分配不合理
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
上面的配置很大一部分是不合理的,对于线上应用来说。
JVM配置参数(根据自己的项目情况调整)
-Xms2048m # 堆的最小内存,建议和最大内存设置的一致,以避免每次垃圾回收完成后JVM重新分配内存,提高GC运行的效率。
-Xmx2048m # 堆的最大内存,建议和最小内存设置的一致,以避免每次垃圾回收完成后JVM重新分配内存,提高GC运行的效率。
-XX:MaxHeapFreeRatio=100 #GC后,如果发现空闲堆内存占到整个预估堆内存的100%,则收缩堆内存预估最大值。默认的是70
-XX:MinHeapFreeRatio=0 #GC后,如果发现空闲堆内存占到整个预估堆内存的0%,则放大堆内存的预估最大值,但不超过固定最大值。默认该值是40
-Xmn900m #设置新生代的内存,如果我们设置了Xmx 和Xms为一致的话,那么该值的默认值为Xmx值的1/3。
-XX:MetaspaceSize=64M # 初始化的Metaspace大小,也是最小大小 java 8 后,用Meta代替了永久代,默认该值为20M(因系统而异),如果日志中出现了Meta GC,那么可以提高该值。
-XX:MaxMetaspaceSize= # 这个参数用于限制Metaspace增长的上限,防止因为某些情况导致Metaspace无限的使用本地内存,影响到其他程序。
-XX:MinMetaspaceFreeRatio=40 #GC后,如果发现空闲Meta内存占到整个预估Meta内存的40%,则放大Meta内存的预估最大值,但不超过固定最大值。默认该值是40
-XX:MaxMetaspaceFreeRatio=70 #GC后,如果发现空闲Meta内存占到整个预估Meta内存的70%,则收缩Meta内存预估最大值。默认的是70
-XX:MaxNewSize= #设置新生代的最大值,一般默认为整个堆的1/3
-XX:NewRatio=N #设置新生代和老年代的比值,默认为2 表示 新生代占用1/3
-XX:SurvivorRatio=N #设置新生代中的 Eden 和两个Survivor 的比值,默认为8表示,eden占用 8/10,时间中jvm会自动调整Eden 和Survivor 的值的。
-XX:MaxTenuringThreshold=N #新生代的对象的年龄(年龄计数器)达到N值后移动到老年代,默认值为15
-XX:ParallelGCThreads=n #设置垃圾收集器在并行阶段使用的线程数,建议设置为与处理器数目相等
-XX:+DisableExplicitGC #关闭System.gc() 看你的程序是否需要System.gc(),再来决定
-XX:MaxDirectMemorySize # 来指定最大的堆外内存
选用GC 回收器,不同的回收器,对应的延迟和内存不一致
## 针对Meta 细化设置
-XX:CompressedClassSpaceSize #这个参数主要是设置Klass Metaspace的大小,不过这个参数设置了也不一定起作用,前提是能开启压缩指针,假如-Xmx超过了32G,压缩指针是开启不来的。如果有Klass Metaspace,那这块内存是和Heap连着的。
## 垃圾收集器的选择
Parallel Scavenge收集器关注点是吞吐量(高效率的利用CPU)。CMS等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验,减少回收的停顿时间),CMS GC算法主要是针对老生代,持久代。所谓吞吐量就是CPU中用于运行用户代码的时间与CPU总消耗时间的比值。还有G1 收集器是(java1.9的默认收集器)。jdk1.8 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)
如果要使用CMS收集器的话,
-XX:+UseConcMarkSweepGC # 开启CMS GC 垃圾收集器
-XX:+UseCMSInitiatingOccupancyOnly #只有开启了这个参数,CMSInitiatingOccupancyFraction这个参数才会生效
-XX:CMSInitiatingOccupancyFraction= #触发cms gc的老生代使用率,当老生代使用达到该阈值之后,就将触发GC,该参数必须配合UseCMSInitiatingOccupancyOnly使用才有效
-XX:+CMSClassUnloadingEnabled/-XX:-CMSClassUnloadingEnabled # 在使用CMS时,是否开启类卸载 如果开启 在full gc是会顺带扫描metaSpace/PermGen
-XX:+ParallelRefProcEnabled # 尽量开启并行处理在任何地方
-XX:+CMSScavengeBeforeRemark #开启在cms gc remark之前做一次ygc,减少gc roots扫描的对象数,从而提高remark的效率
-XX:+UseCMSCompactAtFullCollection # 默认开启,在full gc时使用 Mark-Sweep-Compact 算法。
其它参数
-Xss256k # 每个线程的堆栈大小,Xss越大,每个线程的大小就越大,占用的内存越多,能容纳的线程就越少
#Xss越小,则递归的深度越小,容易出现栈溢出 java.lang.StackOverflowError,减少局部变量的声明,可以节省栈帧大小,增加调用深度
-XX:+PrintGCDetails # 日志中输入GC详情日志。
-XX:+PrintHeapAtGC # 打印GC前后的详细堆栈信息
-XX:+PrintGCTimeStamps # 打印GC发生的时间戳
-XX:+PrintGCDateStamps # 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
# 指定GC 日志和错误日志,OOM
-XX:ErrorFile=/tmp/gc/hs_err_pid%p.log # 发生错误时错误日志保存的地方
-Xloggc:/tmp/gc/gc.log # gc 日志记录的地方
-XX:+HeapDumpOnOutOfMemoryError #启用当抛出OutOfMemoryError异常时,将堆转储到文件
-XX:HeapDumpPath=/tmp/gc #当启用 HeapDumpOnOutOfMemoryError 时,储存dump文件的路径
-XX:+PrintGCApplicationStoppedTime # 启用打印应用暂停的时间
-XX:+TraceClassLoading # 记录你的类到底是从哪个文件加载进来的
还有一些参数见文章:https://blog.csdn.net/see__you__again/article/details/51998038
希望达成的: young gc 频率适中,如果young gc 次数较少的话,一次young gc 的耗时就会比较长,那么最求的平衡就是: young gc 频率和 young gc 耗时 达到两者的平衡值。Full Gc 尽量不要有。
参考配置
-Xms2048m -Xmx2048m -XX:MaxHeapFreeRatio=100 -XX:MinHeapFreeRatio=0 -Xmn900m -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m -XX:MinMetaspaceFreeRatio=0 -XX:SurvivorRatio=7 -XX:MaxMetaspaceFreeRatio=100 -XX:MaxTenuringThreshold=14 -XX:ParallelGCThreads=2 -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -XX:+PrintGCDetails
调优完之后的效果是 ,20-30分钟发生一次Minor GC(young gc ) 每次的GC 耗时,无Full GC 和Meta 导致的GC。
案例分析:
GC 日志
[GC (Metadata GC Threshold) [PSYoungGen: 282234K->101389K(523264K)] 589068K->410894K(1921536K), 0.1611903 secs] [Times: user=0.18 sys=0.00, real=0.16 secs]
[Full GC (Metadata GC Threshold) [PSYoungGen: 101389K->0K(523264K)] [ParOldGen: 309505K->258194K(1398272K)] 410894K->258194K(1921536K), [Metaspace: 268611K->268101K(1294336K)], 1.8562117 secs] [Times: user=1.80 sys=0.08, real=1.86 secs]
我们可以在日志中看到触发了一次普通的GC 和一次 Full GC ,两次GC的原因都是Meta区GC导致的,我们看Full Gc 的日志, young 区的内存没有使用完,old区的内存也没有占用满,只有Meta 区的内存占用满了,那么导致这个问题的就是Meta 区设置的太小。
**扩展: **
查看 java 的一些默认配置
java -XX:+PrintFlagsInitial
示例: 查看Meta(元空间的默认大小)
java -XX:+PrintFlagsInitial |grep MetaspaceSize
2.2 从代码层面
从代码层面的话,我们就需要分析出 每个程序的内存分布情况,每个类的实例数,占用内存最大的类,和他们活动的时长,是否有内存泄漏啊,内存泄漏的疑点。
内存泄漏:对象已经死了,无法通过垃圾收集器进行自动回收,无法释放内存。
内存溢出:程序在申请内存时,没有足够的内存空间供其使用。
1 生成堆
分析的前提是我们需要拿到分析的数据:
jmap -dump:live,format=b,file=/tmp/dump1628.dat pid
**2 下载并安装MAT **
然后我们可以使用MAT分析工具进行分析堆文件。
MAT下载链接 :http://www.eclipse.org/mat/(需要java环境)
3 将堆信息导入到MAT 进行分析
内容借鉴于:https://www.cnblogs.com/AloneSword/p/3821569.html
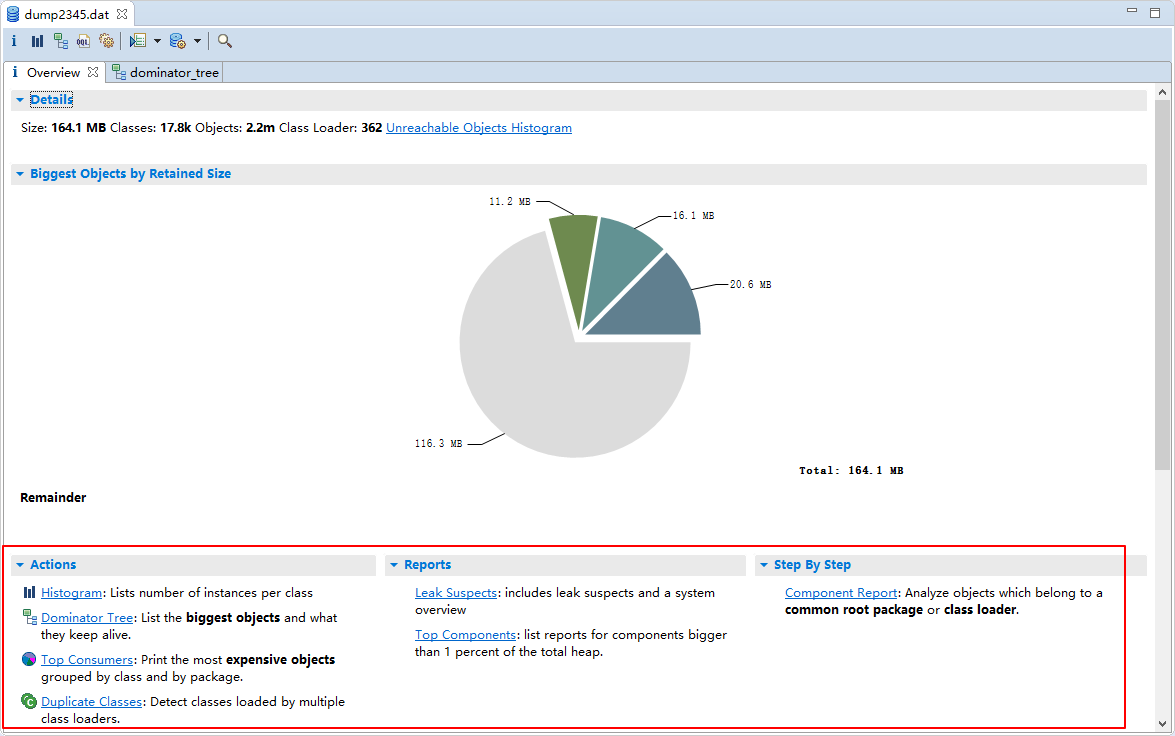
Histogram: 列出内存中的对象,对象的个数以及大小。
Dominator Tree: 可以列出那个线程,以及线程下面的那些对象占用的空间.
Top Consumers: 以图形的形式列出最大的object
Duplicate Classes: 列出一个类被多个类加载引用的类名
Leak Suspects: 包含疑似内存泄漏和系统概述的报告
Top Components:列出占用超过总堆1%的组件
关于每一个分类的详情见博客:https://www.cnblogs.com/AloneSword/p/3821569.html
关于内存的调优,我们还可以使用工具 JConsole和Java VisualVM。 等等
JVM 调优-给你的java应用看看病的更多相关文章
- [转] JVM 调优系列 & 高并发Java系列
1.JVM调优总结(1):一些概念:http://www.importnew.com/18694.html 2.JVM调优总结(2):基本垃圾回收算法:http://www.importnew.com ...
- 《深入理解Java虚拟机》(五)JVM调优 - 工具
JVM调优 - 工具 JConsole:Java监视与管理控制台 JConsole是一个机遇JMX(Java Management Extensions,即Java管理扩展)的JVM监控与管理工具,监 ...
- JVM调优-Java垃圾回收之分代回收
为什么要进行分代回收? JVM使用分代回收测试,是因为:不同的对象,生命周期是不一样的.因此不同生命周期的对象采用不同的收集方式. 可以提高垃圾回收的效率. Java程序运行过程中,会产生大量的对象, ...
- java虚拟机学习-JVM调优总结-调优方法(12)
JVM调优工具 Jconsole,jProfile,VisualVM Jconsole : jdk自带,功能简单,但是可以在系统有一定负荷的情况下使用.对垃圾回收算法有很详细的跟踪.详细说明参考这里 ...
- java虚拟机学习-JVM调优总结-分代垃圾回收详述(9)
为什么要分代 分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的.因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率. 在Java程序运行的过程中,会产生大量的对象, ...
- 深入理解JAVA虚拟机(内存模型+GC算法+JVM调优)
目录 1.Java虚拟机内存模型 1.1 程序计数器 1.2 Java虚拟机栈 局部变量 1.3 本地方法栈 1.4 Java堆 1.5 方法区(永久区.元空间) 附图 2.JVM内存分配参数 2.1 ...
- Java虚拟机(七):JVM调优案列
Eclispe启动优化 概述 什么是jvm调优呢?jvm调优就是根据gc日志分析jvm内存分配.回收的情况来调整各区域内存比例或者gc回收的策略:更深一层就是根据dump出来的内存结构和线程栈来分析代 ...
- Java虚拟机(六):JVM调优工具
工具做为图形化界面来展示更能直观的发现问题,另一方面一些耗费性能的分析(dump文件分析)一般也不会在生产直接分析,往往dump下来的文件达1G左右,人工分析效率较低,因此利用工具来分析jvm相关问题 ...
- Java虚拟机(五):JVM调优命令
运用jvm自带的命令可以方便的在生产监控和打印堆栈的日志信息帮忙我们来定位问题!虽然jvm调优成熟的工具已经有很多:jconsole.大名鼎鼎的VisualVM,IBM的Memory Analyzer ...
随机推荐
- Confluence 6 SQL Server 数据库驱动修改
从 Confluence 6.4 开始,我们使用官方的 Microsoft SQL Server JDBC 驱动来替换掉开源的 jTDS 驱动.从这个版本开始所有的安装都会默认使用官方的 Micros ...
- Confluence 6 升级自定义的站点和空间仔细测试你的修改
修改可能对 Confluence 的后续版本不兼容,当你对 Confluence 进行升级的时候,你应该总是对你自定义修改的模板文件进行仔细的测试来确定所有的修改对新版本的 Confluence 兼容 ...
- usrp-B210
sudo add-apt-repository ppa:ettusresearch/uhd sudo apt-get update sudo apt-get install libuhd-dev li ...
- ERROR 1044 (42000): Access denied for user 'root'@'%' to database 'mysql'
原因:修改数据库账号时删除了默认的localhost root, 新建了% root 但没有赋予全部权限; 解决方法: 1.关闭数据库# mysqld stop 2.在my.cnf里加入skip-g ...
- bzoj2973转移矩阵构造法!
/* 构造单位矩阵(转移矩阵) 给定n*m网格,每个格子独立按照长度不超过6的操作串循环操作 对应的操作有 0-9:拿x个石头到这个格子 nwse:把这个格子的石头推移到相邻格子 d:清空该格石子 开 ...
- selenium+python-autoit文件上传
前言 关于非input文件上传,点上传按钮后,这个弹出的windows的控件了,已经跳出三界之外了,不属于selenium的管辖范围(selenium不是万能的,只能操作web上元素).autoit工 ...
- Exchange Server Notes
以下信息来自Option响应: HTTP/1.1 200 OK Cache-Control: private Allow: OPTIONS,POST Server: Microsoft-IIS/7.0 ...
- 集腋成裘-01-html -html基础
1 标签 1.1 单标签 注释标签 <!-- 注释标签 --> 换行标签 <br/> 水平线 <hr/> <img src="图片来源" ...
- Django_Admin操作
Django_Admin 创建Django_Admin 管理账户 D:\github\Django_Aadmin>python manage.py createsuperuser Usernam ...
- tp3.2上传图片生成缩略图
//引入 use think\Image; /* * $name为表单上传的name值 * $filePath为为保存在入口文件夹public下面uploads/下面的文件夹名称,没有的话会自动创建 ...