python中令人惊艳的小众数据科学库
Python是门很神奇的语言,历经时间和实践检验,受到开发者和数据科学家一致好评,目前已经是全世界发展最好的编程语言之一。简单易用,完整而庞大的第三方库生态圈,使得Python成为编程小白和高级工程师的首选。
在本文中,我们会分享不同于市面上的python数据科学库(如numpy、padnas、scikit-learn、matplotlib等),尽管这些库很棒,但是其他还有一些不为人知,但同样优秀的库需要我们去探索去学习。
1. Wget
从网络上获取数据被认为是数据科学家的必备基本技能,而Wget是一套非交互的基于命令行的文件下载库。ta支持HTTP、HTTPS和FTP协议,也支持使用IP代理。因为ta是非交互的,即使用户未登录,ta也可以在后台运行。所以下次如果你想从网络上下载一个页面,Wget可以帮到你哦。
安装
pip isntall wget
用例
import wget
url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
filename = wget.download(url)
Run and output
100% [................................................] 3841532 / 3841532
filename
'razorback.mp3'
2. Pendulum
对于大多数python用户来说处理时期(时间)数据是一件令人抓狂的事情,好在Pendulum专为你而来。它是python内置时间类的良好备选方案,更多内容可查看官方文档 https://pendulum.eustace.io/docs/
安装
pip install pendulum
用例
import pendulum
dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto')
dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver')
print(dt_vancouver.diff(dt_toronto).in_hours())
Run and output
3
3.imbalanced-learn
常见的机器学习分类算法都默认输入的数据是均衡数据,即假设训练集数据有A和B两个类别,A和B数据量大体相当。如果A和B数据量差别巨大,那么训练的效果会不理想。在实际收集和整理的数据,其实绝大多数是非均衡数据,这对于机器学习分类算法真的是个很大的问题。好在有imbalanced-learn库可以很好的解决这个问题。该库兼容scikit-learn,并且是作为scikit-learn-contrib项目的一部分。当你再遇到非均衡数据,记得试试它哦!
安装
pip install -U imbalanced-learn
#或者
conda install -c conda-forge imbalanced-learn
该库有高质量的文档 http://imbalanced-learn.org/en/stable,目前该库支持scikit-learn、keras、tensorflow库
4. FlashText
在NLP任务重经常会遇到替换指代同一个意思的多个词语,或者从句子中抽取关键词。通常我们一般的做法是使用正则表达式来完成这些脏活累活,但如果要操作的词语数量达到几千上万,使用正则这种方法就会变得很麻烦。FlashText库是基于FlashText算法,该库的最强大之处在于程序运行时间不受操作词语数量影响,即运行时间与操作的词汇数量无关。 因此特别适合应用到 python文本分析 中去。
4.1 安装
pip install flashtext
4.2 用例
4.2.1 抽取关键词
我们都知道 Big Apple 指代纽约。所以抽取纽约这个城市词时候,我们要考虑到相同意思的不同词语。
from flashtext import KeywordProcessor
#设置关键词处理器
keyword_processor = KeywordProcessor()
#设置关键词及其近义词
keyword_processor.add_keyword('Big Apple', 'New York') #遇到Big Apple就会识别为New York
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords("I love Big Apple and Bay Area.")
keywords_found
Run and output
['New York', 'Bay Area']
4.2.2 替换关键词
我们也经常需要将原始文本进行处理,比如将New Delhi(新德里)替换为NCR region(国家首都区)
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
Run and output
'I love New York and NCR region.'
想了解更多,请查看FlastText官方文档
https://flashtext.readthedocs.io/en/latest/#
5. Fuzzywuzzy
这个库的名字就有点怪,但ta拥有强大的字符串匹配功能。可以轻松实现字符串比较比率(comparison ratios),分词比率(token ratios)等操作。它还可以方便地匹配保存在不同数据库中的记录。
安装
pip install fuzzywuzzy
用例
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# Simple Ratio
print(fuzz.ratio("this is a test", "this is a test!"))
# Partial Ratio
print(fuzz.partial_ratio("this is a test", "this is a test!"))
Run and output!
97
100
更多有趣的例子可见 fuzzywuzzy库github账号 https://github.com/seatgeek/fuzzywuzzy
6.PyFlux/PyFTS.
在机器学习领域中经常遇到时间序列分析这种问题。PyFlux是专门为解决时间序列问题而开发的python库。这个库提供了很多现代时间序列算法,单不仅仅限于ARIMA、GARCH和VAR这三种模型。简而言之,PyFlux为我们分析时间序列数据提供了可能,你值得拥有。
安装
pip install pyflux
PyFlux用例可查看该库的文档 https://pyflux.readthedocs.io/en/latest/index.html
类似的时间序列库还有PyFTS, 教程链接
https://towardsdatascience.com/a-short-tutorial-on-fuzzy-time-series-dcc6d4eb1b15
文档链接
https://pyfts.github.io/pyFTS/.
7.Ipyvolume
数据科学中一个重要的部分就是分析结果的展示与交流,而良好的视觉传达是很有优势的。IPyvolume是3D可视化库,可以以最小的初始化设置就能在jupyter notebook中使用。做一个恰当的类比:matplotlib的imshow是2d数组,而IPyvolume的volshow是3d数组。
安装
pip install ipyvolume
#或者
conda install -c conda-forge ipyvolume
用例
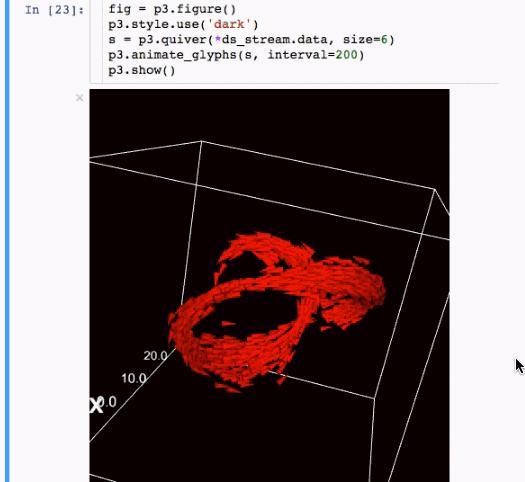
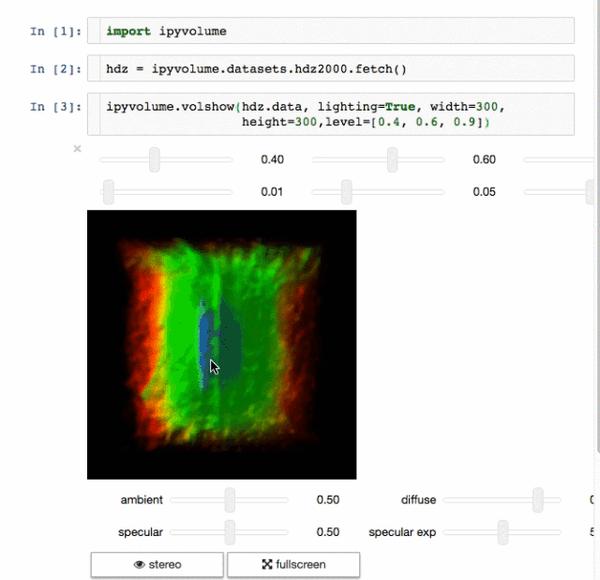
8. Dash
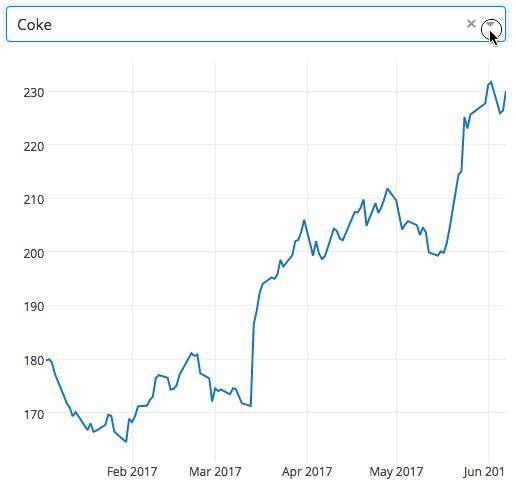
Dash是用来为开发web应用的高生产率工具库,该库基于Flask、Plotly.js和React.js,不需要懂javascript只用python就能让我们制作出美美的的UI元素,如下来列表、滑动条和图表。这些应用可以在浏览器中渲染,具体文档可查看 https://dash.plot.ly/
安装
pip install dash==0.29.0
pip install dash-html-components==0.13.2 #Dash库的HTML组件
pip install dash-core-components==0.36.0 #Dash库核心组件
pip install dash-table==3.1.3 #交互数据库表单(新)
用例
下面是一个下拉式菜单,可以选择股票代码的pandas Dataframe数据类型作为输入,渲染成动态交互的折线图
9. Gym
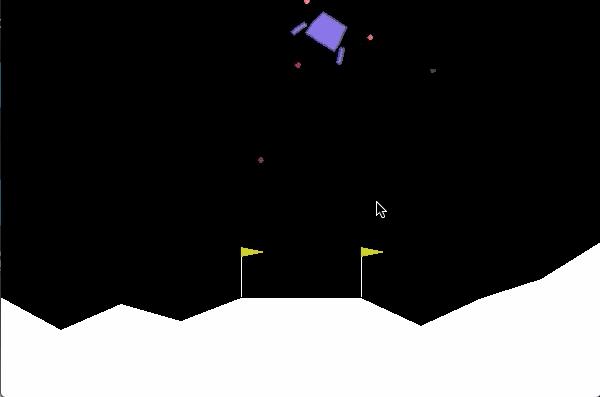
Gym是一个可以开发强化学习算法的工具包。 它兼容数值计算库,如TensorFlow或Theano。我们可以据此设计出强化学习算法,这些环境(测试问题)有公开的接口,允许我们写出通用的算法。
安装
pip install gym
用例
比如研究探月飞行器着落月球,科学家需要考虑如何才能准确着落到某个位置,并且保证安全降落。这就需要用到gym来做强化学习,学到规律
python中令人惊艳的小众数据科学库的更多相关文章
- python中使用tabula爬取pdf数据并导出表格
Tabula是专门用来提取PDF表格数据的,同时支持PDF导出CSV.Excel格式. 首先安装tabula-py: tabula-py依赖库包括Java.pandas.numpy所以需要保证运行环境 ...
- python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)
//2019.07.19/20 python中pandas数据分析基础(数据重塑与轴向转化.数据分组与分组运算.离散化处理.多数据文件合并操作) 3.1 数据重塑与轴向转换1.层次化索引使得一个轴上拥 ...
- Python中令人迷惑的4个引用
第一个:执行时机的差异 1. array = [1, 8, 15] g = (x for x in array if array.count(x) > 0) array = [2, 8, 22] ...
- 9 个鲜为人知的 Python 数据科学库
除了 pandas.scikit-learn 和 matplotlib,还要学习一些用 Python 进行数据科学的新技巧. Python 是一种令人惊叹的语言.事实上,它是世界上增长最快的编程语言之 ...
- Python中Cookie的处理(二)cookielib库
Python中cookielib库(python3中为http.cookiejar)为存储和管理cookie提供客户端支持. 该模块主要功能是提供可存储cookie的对象.使用此模块捕获cookie并 ...
- Python中Cookie的处理(一)Cookie库
Cookie用于服务器实现会话,用户登录及相关功能时进行状态管理.要在用户浏览器上安装cookie,HTTP服务器向HTTP响应添加类似以下内容的HTTP报头: Set-Cookie:session= ...
- 完爆Excel!一个令人惊艳的数据展示工具,让你做图更轻松高效
数据展示应该是最常见的需求,我们经常利用数据做总结.用数据做分享.但是我们该如何更好地展示给我们需要展示的人,如何才能让我们的数据表达更加动人,这个值得让人思索. 说到数据表达,常用的数据展示方式无非 ...
- 那些令人惊艳的TensorFlow扩展包和社区贡献模型
随着TensorFlow发布的,还有一个models库(仓库地址:https://github.com/tensorflow/models),里面包含官方及社群所发布的一些基于TensorFlow实现 ...
- 【Python开发】使用python中的matplotlib进行绘图分析数据
matplotlib 是python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地进行制图.而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中. 它的文档相当完备, ...
随机推荐
- POJ1064 Cable master(二分 浮点误差)
题目链接:传送门 题目大意: 给出n根长度为1-1e5的电线,想要从中切割出k段等长的部分(不可拼接),问这个k段等长的电线最长可以是多长(保留两位小数向下取整). 思路: 很裸的题意,二分答案即可. ...
- Linux系统一些常用命令(持续增加)
这些命令什么的全是从网上找的,防止忘记,留下来备忘 1.linux服务器如何从另一台服务器拷东西:可以用scp命令scp user@remote.machine:/remote/path /local ...
- Linux压缩和解压缩
1.tar.gz tar.gz这种格式是Linux下使用得最多的压缩格式.它在压缩时不会占用太多CPU的,而且可以得到一个非常理想的压缩率. tar -zcvf archive_name.tar.gz ...
- Actifio OnVault 8.0
- ubuntu下Qt链接MySQL: QMYSQL driver not loaded(不用重新编译源码)
先切换到qt数据库驱动目录即:qt安装目录下的gcc_64/plugins/sqldrivers,然后 ldd libqsqlmysql.so 若libmysqlclient.so.18 not fo ...
- C#编程时应注意的性能处理
GC堆回收 那么除了通过new对象而达到代的阈(临界)值时,还有什么能够导致垃圾堆进行垃圾回收呢? 还可能windows报告内存不足.CLR卸载AppDomain.CLR关闭等其它特殊情况. 或者,我 ...
- wireless
思科的AP分为胖AP和瘦AP,但其实只是AP中的Image不一样而已,硬件都是一样的,胖AP和瘦AP之间可以互相转换.即使你下单的时候下的是胖AP,拿到货要当瘦AP用,转换一下即可. [相互转换] 详 ...
- [ZZ] matlab中小波变换函数dwt2和wavedec2 系数提取函数appcoef2和detcoef2
https://zhidao.baidu.com/question/88038464.html DWT2是二维单尺度小波变换,其可以通过指定小波或者分解滤波器进行二维单尺度小波分解. 而WAVEDEC ...
- MPU9250九轴陀螺仪--读接口数据
1.使用i2c链接到树莓派的scl , sda 接口vcc给3v引脚,gnd接树莓派gnd就ok. 2.要操作mpu必须使用mpu的寄存器实现对参数的设定以及读取,取官方下载资料看了一下,在githu ...
- python3-基础1
eval() --- 返回表达式计算结果 实际上就是把括号中的命令提取出来执行一遍. eval("print('ok')") ok 可变类型: 在ID不变的情况下,value可变 ...