Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录:
Python爬虫与数据分析之python教学视频、python源码分享,python
Python爬虫与数据分析之基础教程:Python的语法、字典、元组、列表
Python爬虫与数据分析之进阶教程:文件操作、lambda表达式、递归、yield生成器
Python爬虫与数据分析之模块:内置模块、开源模块、自定义模块
Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
Python爬虫与数据分析之京东爬虫实战:爬取京东商品并存入sqlite3数据库
Python爬虫与数据分析之二手车平台数据获取和分析
Python爬虫与数据分析之python开源爬虫项目汇总
HTTP和HTTPS
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
浏览器发送HTTP请求的过程:
1. 当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种方法。
2. 当我们在浏览器输入URL http://www.baidu.com 的时候,浏览器发送一个Request请求去获取 http://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
3. 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
4. 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
URL(Uniform / Universal Resource Locator的缩写)
定义:统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
基本格式:scheme://host[:port#]/path/…/[?query-string][#anchor]
- scheme:协议(例如:http, https, ftp)
- host:服务器的IP地址或者域名
- port#:服务器的端口(如果是走协议默认端口,缺省端口80)
- path:访问资源的路径
- query-string:参数,发送给http服务器的数据
- anchor:锚(跳转到网页的指定锚点位置)
客户端HTTP请求
URL只是标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括以下格式:
请求行、请求头部、空行、请求数据
一个典型的HTTP请求
GET https://www.baidu.com/ HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh,zh-CN;q=0.8,ar;q=0.6,zh-TW;q=0.4
Cookie: BAIDUID=AE4D1DA6B2D6689BB8C557B3436893E3:FG=1; BIDUPSID=AE4D1DA6B2D6689BB8C557B3436893E3; PSTM=1501466227; BD_UPN=12314353; BD_CK_SAM=1; PSINO=1; H_PS_PSSID=1420_25548_21080_20929; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDSVRTM=0
HTTP请求方法
序号 方法 描述
1 GET 请求指定的页面信息,并返回实体主体。
2 HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
3 POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
4 PUT 从客户端向服务器传送的数据取代指定的文档的内容。
5 DELETE 请求服务器删除指定的页面。
6 CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
7 OPTIONS 允许客户端查看服务器的性能。
8 TRACE 回显服务器收到的请求,主要用于测试或诊断。
主要方法get和post请求
- GET是从服务器上获取数据,POST是向服务器传送数据
- GET请求参数显示,都显示在浏览器网址上,HTTP服务器根据该请求所包含URL中的参数来产生响应内容,即“Get”请求的参数是URL的一部分。 例如:
http://www.baidu.com/s?wd=Chinese - POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等),请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码.
HTTP响应状态码
浏览器内核
浏览器 内核
IE Trident
Chrome Webkit
Firefox Gecho
Opera Pesto
Safari(Apple) Webkit
HTTP代理工具Fiddler
Fiddler是一款强大Web调试工具,它能记录所有客户端和服务器的HTTP请求.
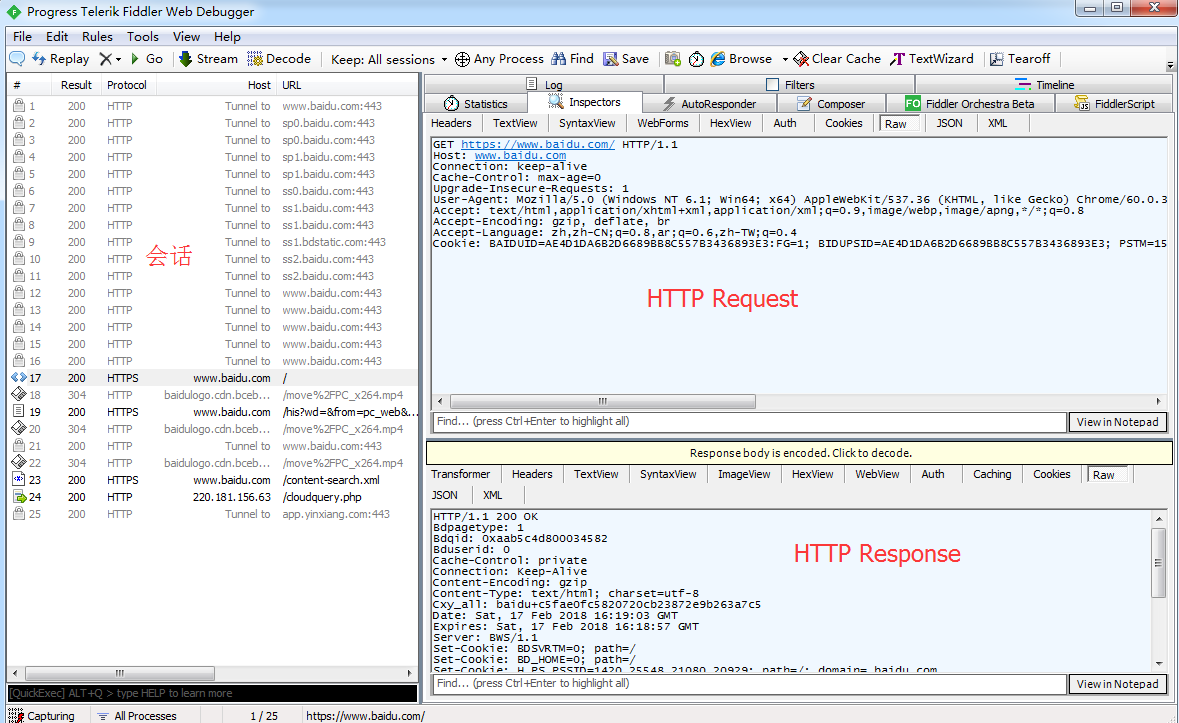
Request部分详解
- Headers —— 显示客户端发送到服务器的
HTTP 请求的 header,显示为一个分级视图,包含了 Web 客户端信息、Cookie、传输状态等。 - Textview —— 显示
POST 请求的 body 部分为文本。 - WebForms —— 显示请求的
GET 参数 和 POST body 内容。 - HexView —— 用十六进制数据显示请求。
- Auth —— 显示响应
header 中的
Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息. - Raw —— 将整个请求显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果请求的
body 是 XML 格式,就是用分级的 XML 树来显示它。
Responser部分详解
- Transformer —— 显示响应的编码信息。
- Headers —— 用分级视图显示响应的
header。 - TextView —— 使用文本显示相应的
body。 - ImageVies —— 如果请求是图片资源,显示响应的图片。
- HexView —— 用十六进制数据显示响应。
- WebView —— 响应在 Web 浏览器中的预览效果。
- Auth —— 显示响应
header 中的
Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息。 - Caching —— 显示此请求的缓存信息。
- Privacy —— 显示此请求的私密
(P3P) 信息。 - Raw —— 将整个响应显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果响应的 body 是 XML 格式,就是用分级的 XML 树来显示它 。
了解了这些知识后,接下来真正迈向爬虫之路.......
urllib2
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。 在Python中有很多库可以用来抓取网页,先学习urllib2。
urllib2模块直接导入就可以用,在python3中urllib2被改为urllib.request
开始爬虫需要准备的一些工具
(1)下载Fiddeler抓包工具,百度直接下载安装就可以(抓包)
(2)下载chrome浏览器代理插件 Proxy-SwitchyOmega(代理)
(3)下载chrome浏览器插件XPath(解析HTML)
(4)工具网站:http://www.json.cn/ (json解析网站)
http://tool.chinaz.com/tools/urlencode.aspx (url编码解码网站)
先写个简单的爬虫百度页面
urlopen
# _*_ coding:utf-8 _*_
import urllib2 #向指定的url地址发送请求,并返回服务器响应的类文件对象
response = urllib2.urlopen('http://www.baidu.com/')
#服务器返回的类文件对象支持python文件对象的操作方法
#read()方法就是读取文件里的全部内容,返回字符串
html = response.read()
print html
urllib2默认的User-Agent是Python-urllib/2.7,容易被检查到是爬虫,所以我们要构造一个请求对象,要用到request方法。
模拟浏览器访问
浏览器访问时通过抓包工具获得的headers信息如下:
GET https://www.baidu.com/ HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh,zh-CN;q=0.8,ar;q=0.6,zh-TW;q=0.4
Cookie: BAIDUID=AE4D1DA6B2D6689BB8C557B3436893E3:FG=1; BIDUPSID=AE4D1DA6B2D6689BB8C557B3436893E3; PSTM=1501466227; BD_CK_SAM=1; PSINO=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BD_HOME=0; H_PS_PSSID=1420_25548_21080_20929; BD_UPN=12314353
我们要设置User-Agent模仿浏览器去访问数据
# _*_ coding:utf-8 _*_
import urllib2 # User-Agent是爬虫与反爬虫的第一步
ua_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
# 通过urllib2.Request()方法构造一个请求对象
request = urllib2.Request('http://www.baidu.com/',headers=ua_headers) #向指定的url地址发送请求,并返回服务器响应的类文件对象
response = urllib2.urlopen(request) # 服务器返回的类文件对象支持python文件对象的操作方法
# read()方法就是读取文件里的全部内容,返回字符串
html = response.read() print html
Request总共三个参数,除了必须要有url参数,还有下面两个:
1. data(默认空):是伴随 url 提交的数据(比如要post的数据),同时 HTTP 请求将从 "GET"方式 改为 "POST"方式。
2. headers(默认空):是一个字典,包含了需要发送的HTTP报头的键值对。
response的常用方法
# _*_ coding:utf-8 _*_
import urllib2 # User-Agent是爬虫与反爬虫的第一步
ua_headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
# 通过urllib2.Request()方法构造一个请求对象
request = urllib2.Request('http://www.baidu.com/',headers=ua_headers) #向指定的url地址发送请求,并返回服务器响应的类文件对象
response = urllib2.urlopen(request) # 服务器返回的类文件对象支持python文件对象的操作方法
# read()方法就是读取文件里的全部内容,返回字符串
html = response.read() # 返回HTTP的响应吗,成功返回200,4服务器页面出错,5服务器问题
print response.getcode() # # 返回数据的实际url,防止重定向
print response.geturl() #https://www.baidu.com/ # 返回服务器响应的HTTP报头
print response.info() # print html
随机选择一个Use-Agent
为了防止封IP,先生成一个user-agent列表,然后从中随机选择一个
# _*_ coding:utf-8 _*_
import urllib2
import random url = 'http:/www.baidu.com/' # 可以试User-Agent列表,也可以是代理列表
ua_list = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
] # 在User-Agent列表中随机选择一个User-Agent
user_agent = random.choice(ua_list) # 构造一个请求
request = urllib2.Request(url) # add_header()方法添加/修改一个HTTP报头
request.add_header('User-Agent',user_agent) #get_header()获取一个已有的HTTP报头的值,注意只能第一个字母大写,后面的要小写
print request.get_header('User-agent')
urllib和urllib2的主要区别
urllib和urllib2都是接受URL请求的相关模块,但是提供了不同的功能,最显著的区别如下:
(1)urllib仅可以接受URL,不能创建,设置headers的request类实例;
(2)但是urllib提供urlencode()方法用来GET查询字符串的产生,而urllib2则没有(这是urllib和urllib2经常一起使用的主要原因)
(3)编码工作使用urllib的urlencode()函数,帮我们讲key:value这样的键值对转换成‘key=value’这样的字符串,解码工作可以使用urllib的unquote()
函数
urllib.encode()的使用
urlencode()里面必须是字典类型
# _*_ coding:utf-8 _*_
import urllib dic = {'derek':'编码'}
print urllib.urlencode(dic) #derek=%E7%BC%96%E7%A0%81 m = urllib.urlencode(dic) print urllib.unquote(m) #derek=编码
一般HTTP请求提交数据,需要编码成 URL编码格式,然后做为url的一部分,或者作为参数传到Request对象中。
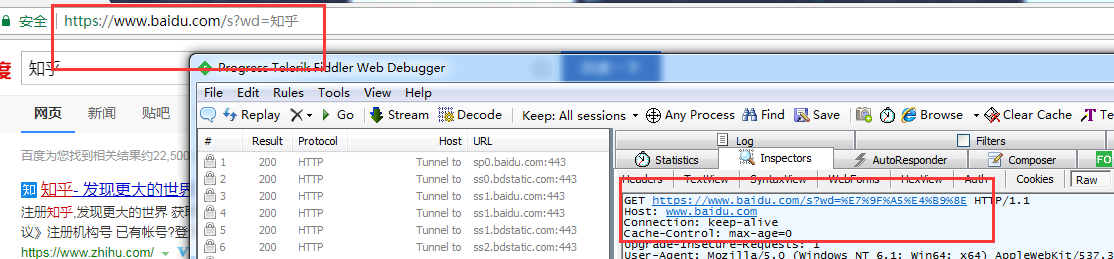
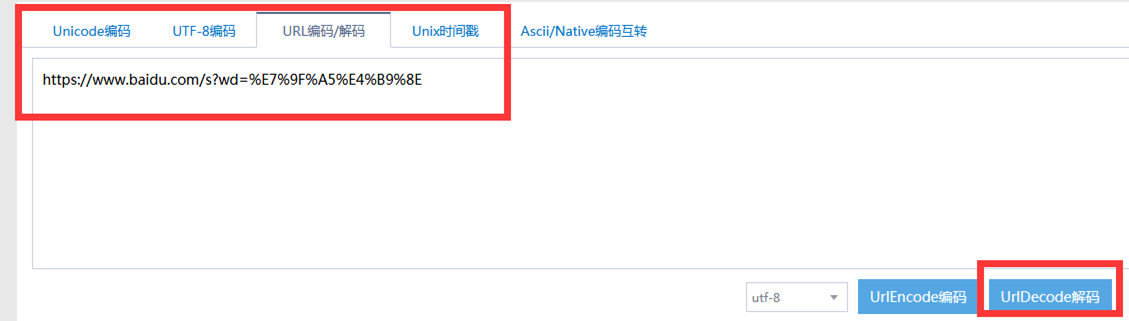
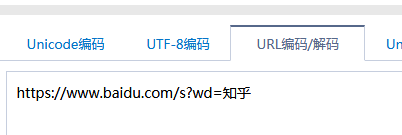
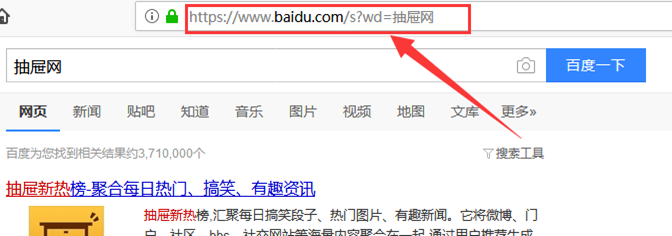
GET请求一般用于我们向服务器获取数据,比如说,我们用百度搜索知乎:https://www.baidu.com/s?wd=知乎
发现GEThttps://www.baidu.com/s?wd=%E7%9F%A5%E4%B9%8E,后面是一个长长的字符串,urldecode后发现就是知乎
用urllib.urlencode()进行转码,然后组合url
# _*_ coding:utf-8 _*_
import urllib,urllib2 url = 'http://www.baidu.com/s'
headers = {'UserAgent':'Mozilla'}
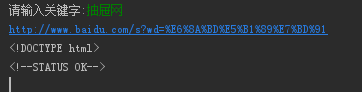
keyword = raw_input('请输入关键字:')
wd = urllib.urlencode({'wd':keyword})
fullurl = url + '?' + wd
print fullurl
request = urllib2.Request(fullurl,headers=headers)
response = urllib2.urlopen(request)
print response.read()
然后输入关键字,爬取下对应的内容
爬取贴吧内容
先了解贴吧url组成:

每个贴吧url都是以'https://tieba.baidu.com/f?'开头,然后是关键字 kw=‘’贴吧名字‘’,再后面是 &pn=页数 (pn=0第一页,pn=50第二页,依次类推)
1.先写一个main,提示用户输入要爬取的贴吧名,并用urllib.urlencode()进行转码,然后组合url
2.接下来,写一个百度贴吧爬虫接口tiebaSpider(),需要传递3个参数给这个接口, 一个是main里组合的url地址,以及起始页码和终止页码,表示要爬取页码的范围。
3.前面写出一个爬取一个网页的代码。然后,将它封装成一个小函数loadPage(),供我们使用。
4.将爬取到的每页的信息存储在本地磁盘上,我们可以简单写一个存储文件的接口writePage()
# _*_ coding:utf-8 _*_
import urllib,urllib2 def loadPage(url,filename):
#根据url发送请求,获取服务器响应文件
print '正在下载' + filename
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
request = urllib2.Request(url,headers = headers)
content = urllib2.urlopen(request).read()
return content
def writePage(html,filename):
#将html内容写入到本地
print '正在保存' + filename
with open(unicode(filename,'utf-8'),'w') as f:
f.write(html)
print '_' * 30 def tiebaSpider(url,beginPage,endPage):
#贴吧爬虫调度器,负责组合处理每个页面的url
for page in range(beginPage,endPage + 1):
pn = (page - 1) * 50
filename = '第' + str(page) + '页.html'
fullurl = url + '&pn=' + str(pn)
# print fullurl
html = loadPage(fullurl,filename)
writePage(html,filename) if __name__ == '__main__':
kw = raw_input('请输入贴吧名:')
beginPage = int(raw_input('请输入起始页:'))
endPage = int(raw_input('请输入结束页:')) url = 'https://tieba.baidu.com/f?'
key = urllib.urlencode({'kw':kw})
fullurl = url + key
tiebaSpider(fullurl,beginPage,endPage)
通过输入想要搜索的贴吧名字,爬取内容并保存到本地

获取Ajax方式加载的数据
爬虫最需要关注的不是页面信息,而是页面信息的数据来源
Ajax方式加载的页面,数据来源一定是JSON,直接对AJAX地址进行post或get,拿到JSON,就是拿到了网页数据,
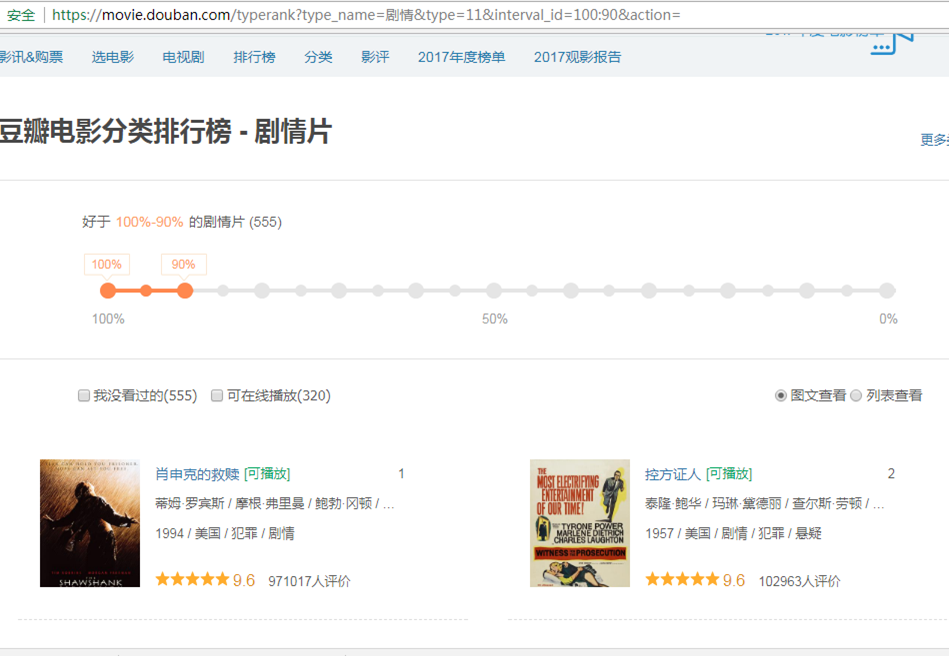
(1)先通过浏览器访问豆瓣电影排行榜
https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
(2)浏览器访问后,通过抓包工具就可以获取我们想要的一些信息
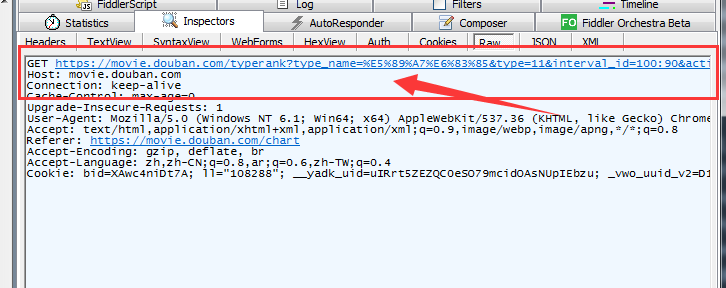
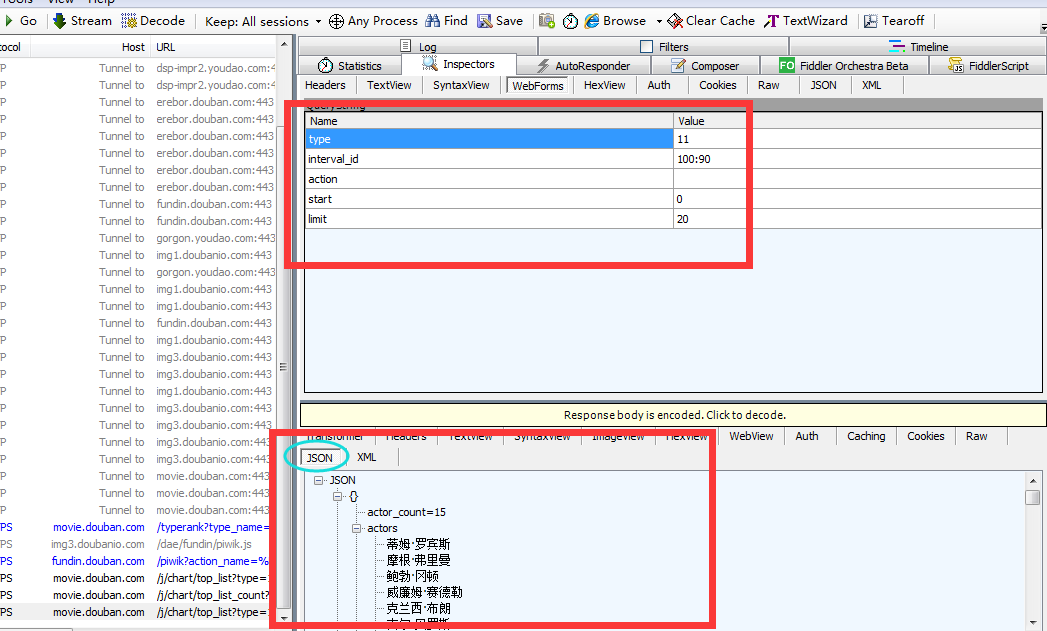
只要response里面有 JSON数据,我们就可以找到服务器的数据来源
分析发现变动的是start value和limit value, type,interval_id,action,固定不变,这三个url中已经包含了,所以formdata只用传start和limit
import urllib
import urllib2 url = 'https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action='
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'} # start和limit可以自己随便设置
formdata = {'start':'','limit':''} data = urllib.urlencode(formdata)
request = urllib2.Request(url,data = data,headers=headers) response = urllib2.urlopen(request)
print response.read()
经历了爬取豆瓣电影TOP250数据我们会发现使用正则表达式其实并没有多么方便,有没有更加好的工具呢?答案当然是有的。接下来将使用三个篇幅分别介绍XPath,Beautiful Soup和pyquery这三个解析库。
XPath介绍
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。 起初 XPath 的提出的初衷是将其作为一个通用的、介于XPointer与XSLT间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。*[来自360百科]*现在我们使用它对HTML文档进行搜索。
lxml的安装
lxml库是Python的一个解析库,支持HTML和XML的解析,支持XPath。下面介绍在Windows,Linux和Mac上的安装。
Windows下的安装
首先使用命令`pip3 install lxml`进行安装。如果没有错误信息说明安装成功了;如果出现错误,比如缺少libxml2库,使用wheel文件离线安装。提供Win64位,Python3.6的lxml安装包:https://pan.baidu.com/s/1wM1xKxCxOH8QOWclp6iasw。使用命令`pip3 install lxml-4.2.4-cp36-cp36m-win_amd64.whl`进行安装。
Linux下的安装
首先也是使用命令`pip3 install lxml`进行安装。如果没有错误信息说明安装成功了。如果报错一般都是缺少必要的库,可以参考以下解决方案。
Centos、Red Hat:
yum groupinstall -y development tools
yum install -y epel-release libxslt-devel libxml2-devel openssl-devel
Ubuntu、Debian和Deepin:
sudo apt-get install -y python3-dev build-essential libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
1
安装好这些必要的类库后重试命令pip3 install lxml进行安装。
## XPath常用规则 ##
表达式 描述
nodename 选择这个节点名的所有子节点
/ 从当前节点选择直接子节点
// 从当前节点选取子孙节点
. 选择当前节点
… 选取当前节点的父节点
@ 选取属性
标签补全
以下是一段HTML:
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
显然,这段HTML中的节点没有闭合,我们可以使用lxml中的etree模块进行补全。
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result.decode('UTF-8'))
可以看见etree不仅将节点闭合了还添加了其他需要的标签。
除了直接读取文本进行解析,etree也可以读取文件进行解析。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('UTF-8'))
获取所有节点
根据XPath常用规则可以知道通过//可以查找当前节点下的子孙节点,以上面的html为例获取所有节点。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//*')#'//'表示获取当前节点子孙节点,'*'表示所有节点,'//*'表示获取当前节点下所有节点
for item in result:
print(item)
如果我们不要获取所有节点而是指定获取某个名称的节点,只需要将*改为指定节点名称即可。如获取所有的li节点
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li')#将*改为li,表示只获取名称为li的子孙节点
#返回一个列表
for item in result:
print(item)
获取子节点
根据XPath常用规则我们可以使用/或//获取子孙节点或子节点。现在我要获取li节点下的a节点。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li/a')#//li选择所有的li节点,/a选择li节点下的直接子节点a
for item in result:
print(item)
我们也可以使用//ul//a首先选择所有的ul节点,再获取ul节点下的的所有a节点,最后结果也是一样的。但是使用//ul/a就不行了,首先选择所有的ul节点,再获取ul节点下的直接子节点a,然而ul节点下没有直接子节点a,当然获取不到。需要深刻理解//和/的不同之处。/用于获取直接子节点,//用于获取子孙节点。
根据属性获取
根据XPath常用规则可以通过@匹配指定的属性。我们通过class属性找最后一个li节点。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li[@class="item-3"]')#最后一个li的class属性值为item-3,返回列表形式
print(result)
获取父节点
根据XPath常用规则可以通过..获取当前节点的父节点。现在我要获取最后一个a节点的父节点下的class属性。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//a[@href="https://hao.360.cn/?a1004"]/../@class')
#a[@href="https://hao.360.cn/?a1004"]:选择href属性为https://hao.360.cn/?a1004的a节点
#..:选取父节点
#@class:选取class属性,获取属性值
print(result)
获取文本信息
很多时候我们找到指定的节点都是要获取节点内的文本信息。我们使用text()方法获取节点中的文本。现在获取所有a标签的文本信息。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//ul//a/text()')
print(result)
属性多值匹配
在上面的例子中所有的属性值都只有一个,如果属性值有多个还能匹配的上吗?
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="spitem-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[@class="sp"]')
print(result)
第二个li节点的class属性有两个值:sp和item-1。如果我们的xpath匹配规则为//li[@class="sp"]匹配的仅仅是class属性值只为sp的li节点,这显然是不存在的。
遇到属性值有多个的情况我们需要使用contains()函数了,contains()匹配一个属性值中包含的字符串 。包含的字符串,而不是某个值。
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="sp item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,"sp")]/a/text()')
print(result)
多属性匹配
属性多值匹配是节点属性有许多个值,我们根据一个值获取符合添加的节点。由于我们很多情况下无法仅仅根据一个属性值就获取到目标节点,往往要根据多个属性来获取目标节点。
from lxml import etree
text = '''
<div>
<ul>
<li class="sp item-0" name="one"><a href="www.baidu.com">baidu</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,"item-0") and @name="one"]/a/text()')#使用and操作符将两个条件相连。
print(result)
也许你会说这个直接使用name的属性值就可以得到了,然而,这里只是作为演示。
from lxml import etree
text = '''
<div>
<ul>
<li class="sp item-0" name="one"><a href="www.baidu.com">baidu</a>
<li class="sp item-1" name="two"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="sp item-2" name="two"><a href="https://www.csdn.net/">csdn</a>
<li class="sp item-3" name="four"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[2]/a/text()')#选择第二个li节点,获取a节点的文本
print(result)
result = html.xpath('//li[last()]/a/text()')#选择最后一个li节点,获取a节点的文本
print(result)
result = html.xpath('//li[last()-1]/a/text()')#选择倒数第2个li节点,获取a节点的文本
print(result)
result = html.xpath('//li[position()<=3]/a/text()')#选择前三个li节点,获取a节点的文本
print(result)
我们使用了last()和postion()函数,在XPath中还有很多函数,详情见:w3school 函数。
XPath 轴
我们可以通过XPath获取祖先节点,属性值,兄弟节点等等,这就是XPath的节点轴。轴可定义相对于当前节点的节点集。
轴名称 结果
ancestor 选取当前节点的所有先辈(父、祖父等)。
ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。
attribute 选取当前节点的所有属性。
child 选取当前节点的所有直接子元素。
descendant 选取当前节点的所有后代元素(子、孙等)。
descendant-or-self 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。
following 选取文档中当前节点的结束标签之后的所有节点。
following-sibling 选取当前节点之后的所有同级节点。
namespace 选取当前节点的所有命名空间节点。
parent 选取当前节点的父节点。
preceding 选取文档中当前节点的开始标签之前的所有同级节点及同级节点下的节点。
preceding-sibling 选取当前节点之前的所有同级节点。
self 选取当前节点。
【上表来源:[w3school XPath轴](https://www.w3cschool.cn/xpath/xpath-axes.html)】
使用示例:
from lxml import etree
text = '''
<div>
<ul>
<li class="sp item-0" name="one"><a href="www.baidu.com">baidu</a>
<li class="sp item-1" name="two"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="sp item-2" name="two"><a href="https://www.csdn.net/">csdn</a>
<li class="sp item-3" name="four"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/ancestor::*')#ancestor表示选取当前节点祖先节点,*表示所有节点。合:选择当前节点的所有祖先节点。
print(result)
result = html.xpath('//li[1]/ancestor::div')#ancestor表示选取当前节点祖先节点,div表示div节点。合:选择当前节点的div祖先节点。
print(result)
result = html.xpath('//li[1]/ancestor-or-self::*')#ancestor-or-self表示选取当前节点及祖先节点,*表示所有节点。合:选择当前节点的所有祖先节点及本及本身。
print(result)
result = html.xpath('//li[1]/attribute::*')#attribute表示选取当前节点的所有属性,*表示所有节点。合:选择当前节点的所有属性。
print(result)
result = html.xpath('//li[1]/attribute::name')#attribute表示选取当前节点的所有属性,name表示name属性。合:选择当前节点的name属性值。
print(result)
result = html.xpath('//ul/child::*')#child表示选取当前节点的所有直接子元素,*表示所有节点。合:选择ul节点的所有直接子节点。
print(result)
result = html.xpath('//ul/child::li[@name="two"]')#child表示选取当前节点的所有直接子元素,li[@name="two"]表示name属性值为two的li节点。合:选择ul节点的所有name属性值为two的li节点。
print(result)
result = html.xpath('//ul/descendant::*')#descendant表示选取当前节点的所有后代元素(子、孙等),*表示所有节点。合:选择ul节点的所有子节点。
print(result)
result = html.xpath('//ul/descendant::a/text()')#descendant表示选取当前节点的所有后代元素(子、孙等),a/test()表示a节点的文本内容。合:选择ul节点的所有a节点的文本内容。
print(result)
result = html.xpath('//li[1]/following::*')#following表示选取文档中当前节点的结束标签之后的所有节点。,*表示所有节点。合:选择第一个li节点后的所有节点。
print(result)
result = html.xpath('//li[1]/following-sibling::*')#following-sibling表示选取当前节点之后的所有同级节点。,*表示所有节点。合:选择第一个li节点后的所有同级节点。
print(result)
result = html.xpath('//li[1]/parent::*')#选取当前节点的父节点。父节点只有一个,祖先节点可能多个。
print(result)
result = html.xpath('//li[3]/preceding::*')#preceding表示选取文档中当前节点的开始标签之前的所有同级节点及同级节点下的节点。,*表示所有节点。合:选择第三个li节点前的所有同级节点及同级节点下的子节点。
print(result)
result = html.xpath('//li[3]/preceding-sibling::*')#preceding-sibling表示选取当前节点之前的所有同级节点。,*表示所有节点。合:选择第三个li节点前的所有同级节点。
print(result)
result = html.xpath('//li[3]/self::*')#选取当前节点。
print(result)
XPath Helper插件
实话说我不想写XPath的匹配规则,在真正的网页解析中怎么可能那么短的规则。这时候我们就可以使用Chrome的插件XPath Helper了【下载地址】,使用它我们可以很快速的得到匹配规则。直接将下载下来的crx文件拖进Chrome扩展程序界面安装即可。
出现红框内图标说明安装成功了。
运行XPath Helper插件,安装shift选择我们需要的内容,自动生成匹配规则。
正则表达式
一、简介
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
二、使用方法
1、简单看一下写法
函数语法:
re.match(pattern, string, flags=0)
|
1 2 3 4 5 6 7 8 9 10 |
|
import re
p = re.compile('abcd')
print(type(p))
#<class '_sre.SRE_Pattern'>
print(dir(p))
#['__class__', '__copy__', '__deepcopy__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'findall', 'finditer', 'flags', 'fullmatch', 'groupindex', 'groups', 'match', 'pattern', 'scanner', 'search', 'split', 'sub', 'subn']
m = p.match('abcdef')
print(type(m))
#<class '_sre.SRE_Match'>
print(dir(m))
#['__class__', '__copy__', '__deepcopy__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'end', 'endpos', 'expand', 'group', 'groupdict', 'groups', 'lastgroup', 'lastindex', 'pos', 're', 'regs', 'span', 'start', 'string']
print(m.group())
#abcd
print(m.group(0))
#abcd
re.match()方法值匹配字符串的开头如果不满足,就返回一个None
|
1 2 3 4 5 6 |
|
神奇的.
|
1 2 3 4 5 6 |
|
特殊字符(元字符)
注意:\在里面是转义词的意思,例如,你想匹配一个re.compile('.'),这个.是匹配任意字符。但是我就想让它匹配一个.怎么办,re.compile('\.'),这样的话它就真的只匹配一个点。

re.findall()
|
1 2 3 4 5 6 7 8 9 10 |
|
数量词:

贪婪模式和非贪婪模式
1、一个小例子
我们知道*表示匹配一个字符串0次或者多次,而+是匹配字符串1次或多次,所以*的时候匹配了0次也打印出来了,而+只找匹配1次的字符。
|
1 2 3 4 5 6 7 8 9 |
|
贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配.
而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。
2、{}
根据下面的例子不难看出,数量词{m}表示的是匹配前面字符串的几个字符串
|
1 2 3 4 5 6 7 8 9 10 11 |
|
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配,否则返回的是None(注意findall返回的是list,而search返回的直接就是字符串)
|
1 2 3 4 5 |
|
检索和替换
Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
语法:
|
1 |
|
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
示例一:
替换一#开头的所有字符(匹配任意字符0次或者多次),替换成无。
|
1 2 3 4 5 |
|
示例一:扩展
找到所有非数字的字符,‘’代表着删除。
|
1 2 3 4 5 |
|
正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:

现在拥有了正则表达式这把神兵利器,我们就可以进行对爬取到的全部网页源代码进行筛选了。
下面我们一起尝试一下爬取内涵段子网站:
http://www.neihan8.com/article/list_5_1.html
打开之后,不难看出里面一个一个非常有内涵的段子,当你进行翻页的时候,注意url地址的变化:
- 第一页url:
http: //www.neihan8.com/article/list_5_1 .html - 第二页url:
http: //www.neihan8.com/article/list_5_2 .html - 第三页url:
http: //www.neihan8.com/article/list_5_3 .html - 第四页url:
http: //www.neihan8.com/article/list_5_4 .html
这样我们的url规律找到了,要想爬取所有的段子,只需要修改一个参数即可。
我们就开始一步一步将所有的段子爬取下来吧。
第一步:获取数据
1. 按照我们之前的用法,我们需要一个加载页面的方法。
这里我们统一定义一个类,将url请求作为一个成员方法处理。
我们创建了一个文件,叫duanzi_spider.py
然后定义一个Spider类,并且添加一个加载页面的成员方法。
import urllib2 class Spider:
"""
内涵段子爬虫类
"""
def loadPage(self, page):
"""
@brief 定义一个url请求网页的方法
@param page需要请求的第几页
@returns 返回的页面url
"""
url = "http://www.neihan8.com/article/list_5_" + str(page)+ ".html"
#user-Agent头
user_agent = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT6.1; Trident/5.0"
headers = {"User-Agent":user_agent}
req = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(req)
print html
以上的loadPage的实现思想想必大家都应该熟悉了,需要注意定义python类的成员方法需要额外添加一个参数self.
2.写main函数测试一个loadPage方法
if __name__ == "__main__":
"""
=====================
内涵段子小爬虫
=====================
"""
print("请按下回车开始")
raw_input() #定义一个Spider对象
mySpider = Spider()
mySpider.loadPage(1)
- 程序正常执行的话,我们会在皮姆上打印了内涵段子第一页的全部html代码。但是我们发现,html中的中文部分显示的可能是乱码。
那么我们需要简单的将得到的网页源代码处理一下:
def loadPage(self, page):
"""
@bridf 定义一个url请求网页的方法
@param page 需要请求的第几页
@returns 返回的页面html
""" url = "http://www.neihan8.com/article/list_5_"+str(page)+".html"
#user-agent头
user-agent = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT6.1; Trident/5.0"
headers = {"User-Agent":user-agent}
req = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(req)
html = response.read()
gbk_html = html.decode("gbk").encode("utf-8") return gbk_html
注意:对于每个网站对中文的编码各自不同,所以html.decode("gbk")的写法并不是通用的,根据网站的编码而异。
第二步:筛选数据
接下来我们已经得到了整个页面的数据。但是,很多内容我们并不关心,所以下一步我们需要筛选数据。如何筛选,就用到了上一节讲述的正则表达式
- 首先
- 然后,我们得到的gbk_html中进行筛选匹配。
import re
我们需要一个匹配规则
我们可以打开内涵段子的网页,鼠标点击右键"查看源代码"你会惊奇的发现,我们需要的每个段子的内容都是在一个<div>标签中,而且每个div标签都有一个属性class="f18 mb20"
根据正则表达式,我们可以推算出一个公式是:
<div.*?class="f18 mb20">(.*?)</div>
- 这个表达式实际上就是匹配到所有
div中class="f18 mb20"里面的内容(具体可以看前面介绍) - 然后这个正则应用到代码中,我们会得到以下代码:
- 这里需要注意一个是
re.S是正则表达式中匹配的一个参数。 - 如果没有re.S则是只匹配一行有没有符合规则的字符串,如果没有则下一行重新匹配。
- 如果加上re.S则是将所有的字符串按一个整体进行匹配,findall将匹配到的所有结果封装到一个list中。
- 如果我们写了一个遍历
item_list的一个方法printOnePage()。ok程序写到这,我们再一次执行一下。
- 如果我们写了一个遍历
def loadPage(self, page):
"""
@brief 定义一个url请求网页的办法
@param page 需要请求的第几页
@returns 返回的页面html
"""
url = "http://www.neihan8.com/article/list_5_" +str(page) + ".html"
#User-Agent头
user-agent = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT6.1; Trident/5.0" headers = {"User-Agent":user-agent}
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req) html = response.read() gbk_html = html.decode("gbk").encode("utf-8") #找到所有的段子内容<div class="f18 mb20"></div>
#re.S 如果没有re.S,则是只匹配一行有没有符合规则的字符串,如果没有则匹配下一行重新匹配
#如果加上re.S,则是将所有的字符串按一个整体进行匹配
pattern = re.compile(r'<div.*?class="f18 mb20">(.*?)</div>', re.S)
item_list = pattern.findall(gbk_html) return item_list def printOnePage(self, item_list, page):
"""
@brief 处理得到的段子列表
@param item_list 得到的段子列表
@param page处理第几页
""" print("*********第%d页,爬取完毕...******"%page) for item in item_list:
print("===============")
print ite
python duanzi_spider.py
我们第一页的全部段子,不包含其他信息全部的打印了出来.
- 你会发现段子中有很多
<p>,</p>很是不舒服,实际上这个是html的一种段落的标签。 - 在浏览器上看不出来,但是如果按照文本打印会有
<p>出现,那么我们只需要把我们的内容去掉即可。 - 我们可以如下简单修改一下printOnePage()
- 我们可以将所有的段子存放在文件中。比如,我们可以将得到的每个item不是打印出来,而是放在一个叫duanzi.txt的文件中也可以。
- 然后我们将所有的print的语句改写成writeToFile(), 当前页面的所有段子就存在了本地的duanzi.txt文件中。
- 接下来我们就通过参数的传递对page进行叠加来遍历内涵段子吧的全部段子内容。
- 只需要在外层加上一些逻辑处理即可。
- 最后,我们执行我们的代码,完成后查看当前路径下的duanzi.txt文件,里面已经有了我们要的内涵段子。
def printOnePage(self, item_list, page):
"""
@brief 处理得到的段子列表
@param item_list 得到的段子列表
@param page 处理第几页
"""
print("******第%d页,爬取完毕*****"%page)
for item in item_list:
print("============")
item = item.replace("<p>", "").replace("</p>", "").replace("<br />", "")
print item
第三步:保存数据
def writeToFile(self, text):
"""
@brief 将数据追加写进文件中
@param text 文件内容
""" myFile = open("./duanzi.txt", "a") #a追加形式打开文件
myFile.write(text)
myFile.write("-------------------------")
myFile.close()
def printOnePage(self, item_list, page):
"""
@brief 处理得到的段子列表
@param item_list 得到的段子列表
@param page 处理第几页
""" print("***第%d页,爬取完毕****"%page)
for item in item_list:
item = item.replace("<p>", "").replace("</p>", "").replace("<br />". "") self.writeToFile(item)
第四步:显示数据
def doWork(self):
"""
让爬虫开始工作
"""
while self.enable:
try:
item_list = self.loadPage(self.page)
except urllib2.URLError, e:
print e.reason
continue #将得到的段子item_list处理
self.printOnePage(item_list, self.page)
self.page += 1
print "按回车继续...."
print "输入quit退出" command = raw_input()
if(command == "quit"):
self.enable = False
break
公告
更多python源码,视频教程,欢迎关注公众号:南城故梦
>零起点大数据与量化分析PDF及教程源码
>利用python进行数据分析PDF及配套源码
>大数据项目实战之Python金融应用编程(数据分析、定价与量化投资)讲义及源码
>董付国老师Python教学视频
1. 课堂教学管理系统开发:在线考试功能设计与实现
2. Python+pillow图像编程;
3. Python+Socket编程
4. Python+tkinter开发;
5. Python数据分析与科学计算可视化
6. Python文件操作
7. Python多线程与多进程编程
8. Python字符串与正则表达式
.....
>数据分析教学视频
1. 轻松驾驭统计学——数据分析必备技能(12集);
2. 轻松上手Tableau 软件——让数据可视化(9集);
3. 竞品分析实战攻略(6集);
4. 电商数据化运营——三大数据化工具应用(20集);
>大数据(视频与教案)
1. hadoop
2. Scala
3. spark
>Python网络爬虫分享系列教程PDF
>【千锋】Python爬虫从入门到精通(精华版)(92集)
欢迎关注公众号获取学习资源:南城故梦
Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式的更多相关文章
- Python爬虫:数据分析小能手:JSON库的用法
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写. 给大家推荐一个Python交流的q裙,大家在学习遇到了什么问题都可以进群一起交流,大家 ...
- Python爬虫与数据分析之模块:内置模块、开源模块、自定义模块
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- Python爬虫与数据分析之进阶教程:文件操作、lambda表达式、递归、yield生成器
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python网络爬虫之初始网络爬虫
第一次接触到python是一个很偶然的因素,由于经常在网上看连载小说,很多小说都是上几百的连载.因此想到能不能自己做一个工具自动下载这些小说,然后copy到电脑或者手机上,这样在没有网络或者网络信号不 ...
- python网络爬虫之初识网络爬虫
第一次接触到python是一个很偶然的因素,由于经常在网上看连载小说,很多小说都是上几百的连载.因此想到能不能自己做一个工具自动下载这些小说,然后copy到电脑或者手机上,这样在没有网络或者网络信号不 ...
- Python爬虫合集:花6k学习爬虫,终于知道爬虫能干嘛了
爬虫Ⅰ:爬虫的基础知识 爬虫的基础知识使用实例.应用技巧.基本知识点总结和需要注意事项 爬虫初始: 爬虫: + Request + Scrapy 数据分析+机器学习 + numpy,pandas,ma ...
- python 基于aiohttp的异步爬虫实战
钢铁知识库,一个学习python爬虫.数据分析的知识库.人生苦短,快用python. 之前我们使用requests库爬取某个站点的时候,每发出一个请求,程序必须等待网站返回响应才能接着运行,而在整个爬 ...
- Python 爬虫3——第一个爬虫脚本的创建
在进行真正的爬虫工程创建之前,我们先要明确我们所要操作的对象是什么?完成所有操作之后要获取到的数据或信息是什么? 首先是第一个问题:操作对象,爬虫全称是网络爬虫,顾名思义,它所操作的对象当然就是网页, ...
- python Cmd实例之网络爬虫应用
python Cmd实例之网络爬虫应用 标签(空格分隔): python Cmd 爬虫 废话少说,直接上代码 # encoding=utf-8 import os import multiproces ...
随机推荐
- C语言中sizeof、strlen函数的部分理解
一.测试环境 Win10 + Visual Studio 2017 二.测试代码 #include "pch.h" #include <iostream> #inclu ...
- robot framework关键词记录单(更新中)
1.select Radio Button groupname value 选择单选按钮 A)适用于input的html单选框,属性中包含name以及value如:Select Radio Butt ...
- robotframework之上传功能
上传功能,分为上传图片以及上传文件 1.上传文件 A)上传文件的html标签为input类型,可以直接输入文本中input文件路径,可以省略点击[上传文件]这一步骤 B)直接输入使用的关键词为:cho ...
- Angular2+AngularJS
AngularJS 系列: 1.angular.module 的定义 var mapApp = angular.module("positionSalaryEditApp",[&q ...
- Spring Boot的日志配置
一.配置logback日志 Spring Boot默认使用logback打印日志 需要增加依赖 <groupId>org.springframework.boot</groupId& ...
- IntellijIDEA常用快捷键总结
转载自:http://blog.csdn.net/qq_17586821/article/details/52554731 下面的这些常用快捷键需要在实际操作中不断地体会才能真正感受到它们的方便之处. ...
- 双网卡单IP实现网卡冗余与负载均衡
WINDOWS下: 所谓双网卡,就是通过软件将双网卡绑定为一个IP地址,这个技术对于许多朋友来说并不陌生,许多高档服务器网卡(例如intel8255x系列.3COM服务器网卡等)都具有多网卡绑定功能, ...
- PyCharm激活(License server)
打开激活窗口 选择 Activate new license with: License server (用license server 激活) 在 License sever address 处填入 ...
- Python——PyQt GUI编程(python programming)
import sys from math import * from PyQt5.QtCore import * from PyQt5.QtGui import * from PyQt5.QtWidg ...
- note 9 列表、时间复杂度、排序
列表 List +内建(built-in)数据结构(data structure),用来存储一系列元素(items) 如:lst = [5.4,'hello',2] 前向索引.后向索引.切片.拼接.成 ...