彻底搞懂Scrapy的中间件(二)
在上一篇文章中介绍了下载器中间件的一些简单应用,现在再来通过案例说说如何使用下载器中间件集成Selenium、重试和处理请求异常。
在中间件中集成Selenium
对于一些很麻烦的异步加载页面,手动寻找它的后台API代价可能太大。这种情况下可以使用Selenium和ChromeDriver或者Selenium和PhantomJS来实现渲染网页。
这是前面的章节已经讲到的内容。那么,如何把Scrapy与Selenium结合起来呢?这个时候又要用到中间件了。
创建一个SeleniumMiddleware,其代码如下:
from scrapy.http import HtmlResponse
class SeleniumMiddleware(object):
def __init__(self):
self.driver = webdriver.Chrome('./chromedriver')
def process_request(self, request, spider):
if spider.name == 'seleniumSpider':
self.driver.get(request.url)
time.sleep(2)
body = self.driver.page_source
return HtmlResponse(self.driver.current_url,
body=body,
encoding='utf-8',
request=request)
这个中间件的作用,就是对名为“seleniumSpider”的爬虫请求的网址,使用ChromeDriver先进行渲染,然后用返回的渲染后的HTML代码构造一个Response对象。如果是其他的爬虫,就什么都不做。在上面的代码中,等待页面渲染完成是通过time.sleep(2)来实现的,当然读者也可以使用前面章节讲到的等待某个元素出现的方法来实现。
有了这个中间件以后,就可以像访问普通网页那样直接处理需要异步加载的页面,如下图所示。
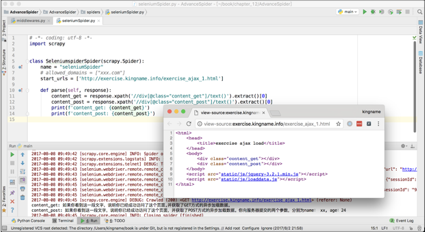
在中间件里重试
在爬虫的运行过程中,可能会因为网络问题或者是网站反爬虫机制生效等原因,导致一些请求失败。在某些情况下,少量的数据丢失是无关紧要的,例如在几亿次请求里面失败了十几次,损失微乎其微,没有必要重试。但还有一些情况,每一条请求都至关重要,容不得有一次失败。此时就需要使用中间件来进行重试。
有的网站的反爬虫机制被触发了,它会自动将请求重定向到一个xxx/404.html页面。那么如果发现了这种自动的重定向,就没有必要让这一次的请求返回的内容进入数据提取的逻辑,而应该直接丢掉或者重试。
还有一种情况,某网站的请求参数里面有一项,Key为date,Value为发起请求的这一天的日期或者发起请求的这一天的前一天的日期。例如今天是“2017-08-10”,但是这个参数的值是今天早上10点之前,都必须使用“2017-08-09”,在10点之后才能使用“2017-08-10”,否则,网站就不会返回正确的结果,而是返回“参数错误”这4个字。然而,这个日期切换的时间点受到其他参数的影响,有可能第1个请求使用“2017-08-10”可以成功访问,而第2个请求却只有使用“2017-08-09”才能访问。遇到这种情况,与其花费大量的时间和精力去追踪时间切换点的变化规律,不如简单粗暴,直接先用今天去试,再用昨天的日期去试,反正最多两次,总有一个是正确的。
以上的两种场景,使用重试中间件都能轻松搞定。
打开练习页面
http://exercise.kingname.info/exercise_middleware_retry.html。
这个页面实现了翻页逻辑,可以上一页、下一页地翻页,也可以直接跳到任意页数,如下图所示。
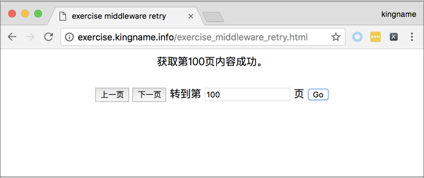
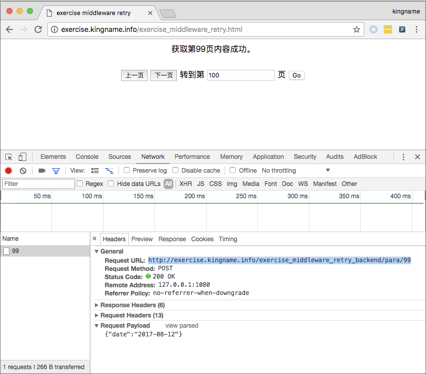
现在需要获取1~9页的内容,那么使用前面章节学到的内容,通过Chrome浏览器的开发者工具很容易就能发现翻页实际上是一个POST请求,提交的参数为“date”,它的值是日期“2017-08-12”,如下图所示。
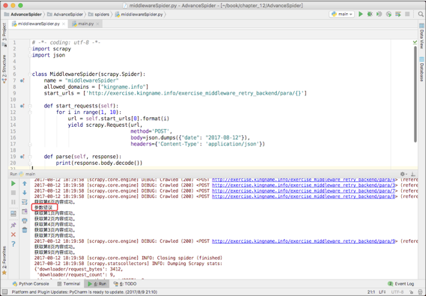
使用Scrapy写一个爬虫来获取1~9页的内容,运行结果如下图所示。
从上图可以看到,第5页没有正常获取到,返回的结果是参数错误。于是在网页上看一下,发现第5页的请求中body里面的date对应的日期是“2017-08-11”,如下图所示。
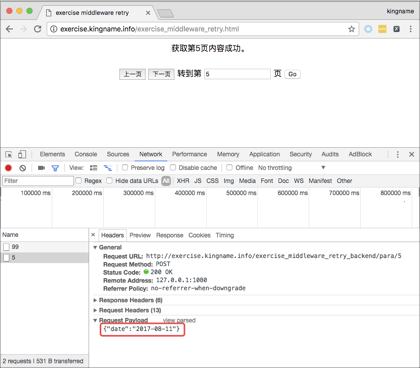
如果测试的次数足够多,时间足够长,就会发现以下内容。
- 同一个时间点,不同页数提交的参数中,date对应的日期可能是今天的也可能是昨天的。
- 同一个页数,不同时间提交的参数中,date对应的日期可能是今天的也可能是昨天的。
由于日期不是今天,就是昨天,所以针对这种情况,写一个重试中间件是最简单粗暴且有效的解决办法。中间件的代码如下图所示。
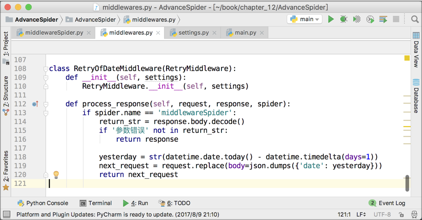
这个中间件只对名为“middlewareSpider”的爬虫有用。由于middlewareSpider爬虫默认使用的是“今天”的日期,所以如果被网站返回了“参数错误”,那么正确的日期就必然是昨天的了。所以在这个中间件里面,第119行,直接把原来请求的body换成了昨天的日期,这个请求的其他参数不变。让这个中间件生效以后,爬虫就能成功爬取第5页了,如下图所示。
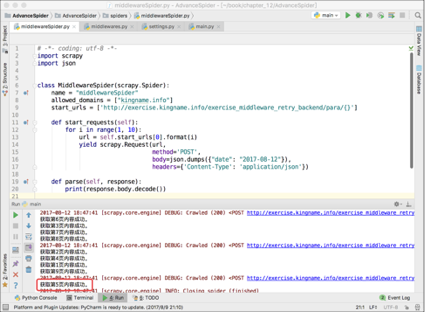
爬虫本身的代码,数据提取部分完全没有做任何修改,如果不看中间件代码,完全感觉不出爬虫在第5页重试过。
除了检查网站返回的内容外,还可以检查返回内容对应的网址。将上面练习页后台网址的第1个参数“para”改为404,暂时禁用重试中间件,再跑一次爬虫。其运行结果如下图所示。
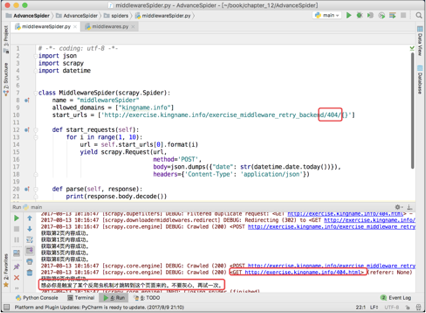
此时,对于参数不正确的请求,网站会自动重定向到以下网址对应的页面:
http://exercise.kingname.info/404.html
由于Scrapy自带网址自动去重机制,因此虽然第3页、第6页和第7页都被自动转到了404页面,但是爬虫只会爬一次404页面,剩下两个404页面会被自动过滤。
对于这种情况,在重试中间件里面判断返回的网址即可解决,如下图12-21所示。
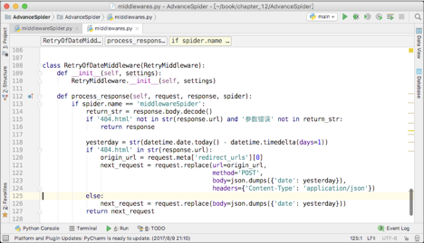
在代码的第115行,判断是否被自动跳转到了404页面,或者是否被返回了“参数错误”。如果都不是,说明这一次请求目前看起来正常,直接把response返回,交给后面的中间件来处理。如果被重定向到了404页面,或者被返回“参数错误”,那么进入重试的逻辑。如果返回了“参数错误”,那么进入第126行,直接替换原来请求的body即可重新发起请求。
如果自动跳转到了404页面,那么这里有一点需要特别注意:此时的请求,request这个对象对应的是向404页面发起的GET请求,而不是原来的向练习页后台发起的请求。所以,重新构造新的请求时必须把URL、body、请求方式、Headers全部都换一遍才可以。
由于request对应的是向404页面发起的请求,所以resquest.url对应的网址是404页面的网址。因此,如果想知道调整之前的URL,可以使用如下的代码:
request.meta['redirect_urls']
这个值对应的是一个列表。请求自动跳转了几次,这个列表里面就有几个URL。这些URL是按照跳转的先后次序依次append进列表的。由于本例中只跳转了一次,所以直接读取下标为0的元素即可,也就是原始网址。
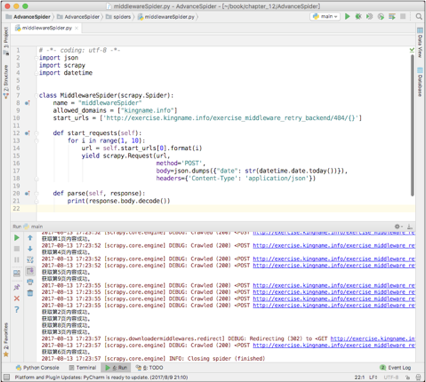
重新激活这个重试中间件,不改变爬虫数据抓取部分的代码,直接运行以后可以正确得到1~9页的全部内容,如下图所示。
在中间件里处理异常
在默认情况下,一次请求失败了,Scrapy会立刻原地重试,再失败再重试,如此3次。如果3次都失败了,就放弃这个请求。这种重试逻辑存在一些缺陷。以代理IP为例,代理存在不稳定性,特别是免费的代理,差不多10个里面只有3个能用。而现在市面上有一些收费代理IP提供商,购买他们的服务以后,会直接提供一个固定的网址。把这个网址设为Scrapy的代理,就能实现每分钟自动以不同的IP访问网站。如果其中一个IP出现了故障,那么需要等一分钟以后才会更换新的IP。在这种场景下,Scrapy自带的重试逻辑就会导致3次重试都失败。
这种场景下,如果能立刻更换代理就立刻更换;如果不能立刻更换代理,比较好的处理方法是延迟重试。而使用Scrapy_redis就能实现这一点。爬虫的请求来自于Redis,请求失败以后的URL又放回Redis的末尾。一旦一个请求原地重试3次还是失败,那么就把它放到Redis的末尾,这样Scrapy需要把Redis列表前面的请求都消费以后才会重试之前的失败请求。这就为更换IP带来了足够的时间。
重新打开代理中间件,这一次故意设置一个有问题的代理,于是可以看到Scrapy控制台打印出了报错信息,如下图所示。
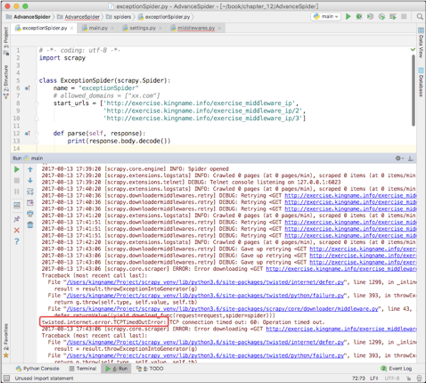
从上图可以看到Scrapy自动重试的过程。由于代理有问题,最后会抛出方框框住的异常,表示TCP超时。在中间件里面如果捕获到了这个异常,就可以提前更换代理,或者进行重试。这里以更换代理为例。首先根据上图中方框框住的内容导入TCPTimeOutError这个异常:
from twisted.internet.error import TCPTimedOutError
修改前面开发的重试中间件,添加一个process_exception()方法。这个方法接收3个参数,分别为request、exception和spider,如下图所示。
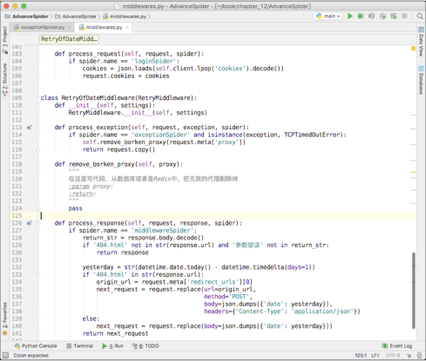
process_exception()方法只对名为“exceptionSpider”的爬虫生效,如果请求遇到了TCPTimeOutError,那么就首先调用remove_broken_proxy()方法把失效的这个代理IP移除,然后返回这个请求对象request。返回以后,Scrapy会重新调度这个请求,就像它第一次调度一样。由于原来的ProxyMiddleware依然在工作,于是它就会再一次给这个请求更换代理IP。又由于刚才已经移除了失效的代理IP,所以ProxyMiddleware会从剩下的代理IP里面随机找一个来给这个请求换上。
特别提醒:图片中的remove_broken_proxy()函数体里面写的是pass,但是在实际开发过程中,读者可根据实际情况实现这个方法,写出移除失效代理的具体逻辑。
下载器中间件功能总结
能在中间件中实现的功能,都能通过直接把代码写到爬虫中实现。使用中间件的好处在于,它可以把数据爬取和其他操作分开。在爬虫的代码里面专心写数据爬取的代码;在中间件里面专心写突破反爬虫、登录、重试和渲染AJAX等操作。
对团队来说,这种写法能实现多人同时开发,提高开发效率;对个人来说,写爬虫的时候不用考虑反爬虫、登录、验证码和异步加载等操作。另外,写中间件的时候不用考虑数据怎样提取。一段时间只做一件事,思路更清晰。
本文节选自我的新书《Python爬虫开发 从入门到实战》完整目录可以在京东查询到 https://item.jd.com/12436581.html
彻底搞懂Scrapy的中间件(二)的更多相关文章
- 彻底搞懂Scrapy的中间件(一)
中间件是Scrapy里面的一个核心概念.使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫. "中间件"这个中文名字和前面章节讲到 ...
- 彻底搞懂Scrapy的中间件(三)
在前面两篇文章介绍了下载器中间件的使用,这篇文章将会介绍爬虫中间件(Spider Middleware)的使用. 爬虫中间件 爬虫中间件的用法与下载器中间件非常相似,只是它们的作用对象不同.下载器中间 ...
- 彻底搞懂 etcd 系列文章(二):etcd 的多种安装姿势
0 专辑概述 etcd 是云原生架构中重要的基础组件,由 CNCF 孵化托管.etcd 在微服务和 Kubernates 集群中不仅可以作为服务注册与发现,还可以作为 key-value 存储的中间件 ...
- 链表算法题二,还原题目,用debug调试搞懂每一道题
文章简述 大家好,本篇是个人的第4篇文章. 承接第3篇文章<开启算法之路,还原题目,用debug调试搞懂每一道题>,本篇文章继续分享关于链表的算法题目. 本篇文章共有5道题目 一,反转链表 ...
- Java进阶专题(二十六) 将近2万字的Dubbo原理解析,彻底搞懂dubbo
前言 前面我们研究了RPC的原理,市面上有很多基于RPC思想实现的框架,比如有Dubbo.今天就从Dubbo的SPI机制.服务注册与发现源码及网络通信过程去深入剖析下Dubbo. Dubbo架构 ...
- c#代码 天气接口 一分钟搞懂你的博客为什么没人看 看完python这段爬虫代码,java流泪了c#沉默了 图片二进制转换与存入数据库相关 C#7.0--引用返回值和引用局部变量 JS直接调用C#后台方法(ajax调用) Linq To Json SqlServer 递归查询
天气预报的程序.程序并不难. 看到这个需求第一个想法就是只要找到合适天气预报接口一切都是小意思,说干就干,立马跟学生沟通价格. 不过谈报价的过程中,差点没让我一口老血喷键盘上,话说我们程序猿的人 ...
- 搞懂分布式技术2:分布式一致性协议与Paxos,Raft算法
搞懂分布式技术2:分布式一致性协议与Paxos,Raft算法 2PC 由于BASE理论需要在一致性和可用性方面做出权衡,因此涌现了很多关于一致性的算法和协议.其中比较著名的有二阶提交协议(2 Phas ...
- 彻底搞懂 etcd 系列文章(三):etcd 集群运维部署
0 专辑概述 etcd 是云原生架构中重要的基础组件,由 CNCF 孵化托管.etcd 在微服务和 Kubernates 集群中不仅可以作为服务注册与发现,还可以作为 key-value 存储的中间件 ...
- 彻底搞懂 etcd 系列文章(一):初识 etcd
0 专辑概述 etcd 是云原生架构中重要的基础组件,由 CNCF 孵化托管.etcd 在微服务和 Kubernates 集群中不仅可以作为服务注册与发现,还可以作为 key-value 存储的中间件 ...
随机推荐
- SOCKET.IO 的用法 系统API,
原文:http://www.cnblogs.com/xiezhengcai/p/3956401.html 1. 服务端 io.on('connection',function(socket)); 监听 ...
- OO第二次博客作业(第二单元总结)
在我开始写这次博客作业的时候,窗外响起了希望之花,由此联想到乘坐自己写的电梯FROM-3-TO--1下楼洗澡,然后······ 开个玩笑,这么辣鸡的电梯肯定不会投入实际使用的,何况只是一次作业.还是从 ...
- 面试题-linux基础
Linux基础和git linux的基础命令(怎么区分一个文件还是文件夹) ls -F 在显示名称的时候会在文件夹后面添加“/”, 在文件后面加“*” 日志以什么格式,存放在哪里?日志可以存储在“/ ...
- 谷歌浏览器添加JSON-handle插件
访问谷歌应用商店必须FQ,具体可安装谷歌访问助手:http://www.cnblogs.com/yangcx666/p/8783642.html 不想FQ的可以百度 "谷歌插件网" ...
- Redis 单机部署
参考文章: https://www.cnblogs.com/zy-303/p/10273167.html#_label0 https://blog.csdn.net/linyifan_/article ...
- Spring Boot - AMQP 消息中间件
Message Broker是一种消息验证.传输.路由的架构模式,其设计目标主要应用于下面这些场景: 消息路由到一个或多个目的地 消息转化为其他的表现方式 执行消息的聚集.消息的分解,并将结果发送到他 ...
- osx免驱网卡推荐
1. 单频2.4G芯片为Realtek RTL8188cu, RTL8192cu,都可以用,如TP-Link TL-WN821N.TP-Link TL-WN823N等等:2. 单频2.4G芯片为Med ...
- vue中的组件化
组件化 1.定义全局组件 1.要在父实例中使用某个组件,组件必须在实例值之前定义2.组件其实也是一个Vue实例,因此它在定义时也会接收:data.methond.生命周期函数等3.不同的组件不会与页面 ...
- locate中使用variant
利用locate构造多字段查询,采用variant很方便,简介如下, //构造查询多字段,例如'编号;姓名'形式 aLookField := FieldByName ('关键字1').AsStrin ...
- js通过replace()方法配合正则去除空格
<script> //去掉全部空格 var str = " 546546 4564 46 46 88 88 "; var str = str.replace(/\s+/ ...