OkHttp3源码详解(五) okhttp连接池复用机制
1、概述
提高网络性能优化,很重要的一点就是降低延迟和提升响应速度。
通常我们在浏览器中发起请求的时候header部分往往是这样的
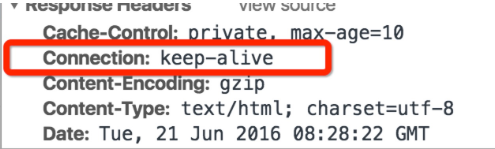
keep-alive 就是浏览器和服务端之间保持长连接,这个连接是可以复用的。在HTTP1.1中是默认开启的。
连接的复用为什么会提高性能呢?
通常我们在发起http请求的时候首先要完成tcp的三次握手,然后传输数据,最后再释放连接。三次握手的过程可以参考这里 TCP三次握手详解及释放连接过程
一次响应的过程

在高并发的请求连接情况下或者同个客户端多次频繁的请求操作,无限制的创建会导致性能低下。
如果使用keep-alive
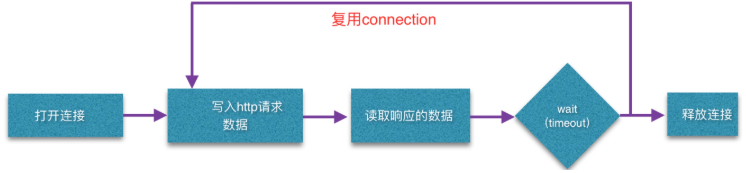
在timeout空闲时间内,连接不会关闭,相同重复的request将复用原先的connection,减少握手的次数,大幅提高效率。
并非keep-alive的timeout设置时间越长,就越能提升性能。长久不关闭会造成过多的僵尸连接和泄露连接出现。
那么okttp在客户端是如果类似于客户端做到的keep-alive的机制。
2、连接池的使用
连接池的类位于okhttp3.ConnectionPool。我们的主旨是了解到如何在timeout时间内复用connection,并且有效的对其进行回收清理操作。
其成员变量代码片
/**
* Background threads are used to cleanup expired connections. There will be at most a single
* thread running per connection pool. The thread pool executor permits the pool itself to be
* garbage collected.
*/
private static final Executor executor = new ThreadPoolExecutor( /* corePoolSize */,
Integer.MAX_VALUE /* maximumPoolSize */, 60L /* keepAliveTime */, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp ConnectionPool", true)); /** The maximum number of idle connections for each address. */
private final int maxIdleConnections; private final Deque<RealConnection> connections = new ArrayDeque<>();
final RouteDatabase routeDatabase = new RouteDatabase();
boolean cleanupRunning;
- excutor : 线程池,用来检测闲置socket并对其进行清理。
- connections : connection缓存池。Deque是一个双端列表,支持在头尾插入元素,这里用作LIFO(后进先出)堆栈,多用于缓存数据。
- routeDatabase :用来记录连接失败router
2.1 缓存操作
ConnectionPool提供对Deque<RealConnection>进行操作的方法分别为put、get、connectionBecameIdle、evictAll几个操作。分别对应放入连接、获取连接、移除连接、移除所有连接操作。
put操作
void put(RealConnection connection) {
assert (Thread.holdsLock(this));
if (!cleanupRunning) {
cleanupRunning = true;
executor.execute(cleanupRunnable);
}
connections.add(connection);
}
可以看到在新的connection 放进列表之前执行清理闲置连接的线程。
既然是复用,那么看下他获取连接的方式。
/** Returns a recycled connection to {@code address}, or null if no such connection exists. */
RealConnection get(Address address, StreamAllocation streamAllocation) {
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.allocations.size() < connection.allocationLimit
&& address.equals(connection.route().address)
&& !connection.noNewStreams) {
streamAllocation.acquire(connection);
return connection;
}
}
return null;
}
遍历connections缓存列表,当某个连接计数的次数小于限制的大小以及request的地址和缓存列表中此连接的地址完全匹配。则直接复用缓存列表中的connection作为request的连接。
streamAllocation.allocations是个对象计数器,其本质是一个
List<Reference<StreamAllocation>>存放在RealConnection连接对象中用于记录Connection的活跃情况。
连接池中Connection的缓存比较简单,就是利用一个双端列表,配合CRD等操作。那么connection在timeout时间类是如果失效的呢,并且如果做到有效的对连接进行清除操作以确保性能和内存空间的充足。
2.2 连接池的清理和回收
在看ConnectionPool的成员变量的时候我们了解到一个Executor的线程池是用来清理闲置的连接的。注释中是这么解释的:
Background threads are used to cleanup expired connections
我们在put新连接到队列的时候会先执行清理闲置连接的线程。调用的正是 executor.execute(cleanupRunnable); 方法。观察cleanupRunnable
private final Runnable cleanupRunnable = new Runnable() {
@Override public void run() {
while (true) {
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -) return;
if (waitNanos > ) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this) {
try {
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
线程中不停调用Cleanup 清理的动作并立即返回下次清理的间隔时间。继而进入wait 等待之后释放锁,继续执行下一次的清理。所以可能理解成他是个监测时间并释放连接的后台线程。
了解cleanup动作的过程。这里就是如何清理所谓闲置连接的和行了。怎么找到闲置的连接是主要解决的问题。
long cleanup(long now) {
int inUseConnectionCount = ;
int idleConnectionCount = ;
RealConnection longestIdleConnection = null;
long longestIdleDurationNs = Long.MIN_VALUE;
// Find either a connection to evict, or the time that the next eviction is due.
synchronized (this) {
for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
// If the connection is in use, keep searching.
if (pruneAndGetAllocationCount(connection, now) > ) {
inUseConnectionCount++;
continue;
}
idleConnectionCount++;
// If the connection is ready to be evicted, we're done.
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
// We've found a connection to evict. Remove it from the list, then close it below (outside
// of the synchronized block).
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > ) {
// A connection will be ready to evict soon.
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > ) {
// All connections are in use. It'll be at least the keep alive duration 'til we run again.
return keepAliveDurationNs;
} else {
// No connections, idle or in use.
cleanupRunning = false;
return -;
}
}
closeQuietly(longestIdleConnection.socket());
// Cleanup again immediately.
return ;
}
在遍历缓存列表的过程中,使用连接数目inUseConnectionCount 和闲置连接数目idleConnectionCount 的计数累加值都是通过pruneAndGetAllocationCount() 是否大于0来控制的。那么很显然pruneAndGetAllocationCount() 方法就是用来识别对应连接是否闲置的。>0则不闲置。否则就是闲置的连接。
进去观察
private int pruneAndGetAllocationCount(RealConnection connection, long now) {
List<Reference<StreamAllocation>> references = connection.allocations;
for (int i = ; i < references.size(); ) {
Reference<StreamAllocation> reference = references.get(i);
if (reference.get() != null) {
i++;
continue;
}
// We've discovered a leaked allocation. This is an application bug.
Platform.get().log(WARN, "A connection to " + connection.route().address().url()
+ " was leaked. Did you forget to close a response body?", null);
references.remove(i);
connection.noNewStreams = true;
// If this was the last allocation, the connection is eligible for immediate eviction.
if (references.isEmpty()) {
connection.idleAtNanos = now - keepAliveDurationNs;
return ;
}
}
return references.size();
}
}
好了,原先存放在RealConnection 中的allocations 派上用场了。遍历StreamAllocation 弱引用链表,移除为空的引用,遍历结束后返回链表中弱引用的数量。所以可以看出List<Reference<StreamAllocation>> 就是一个记录connection活跃情况的 >0表示活跃 =0 表示空闲。StreamAllocation 在列表中的数量就是就是物理socket被引用的次数
解释:StreamAllocation被高层反复执行aquire与release。这两个函数在执行过程中其实是在一直在改变Connection中的 List<WeakReference<StreamAllocation>>大小。
搞定了查找闲置的connection操作,我们回到cleanup 的操作。计算了inUseConnectionCount和idleConnectionCount 之后程序又根据闲置时间对connection进行了一个选择排序,选择排序的核心是:
// If the connection is ready to be evicted, we're done.
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
....
通过对比最大闲置时间选择排序可以方便的查找出闲置时间最长的一个connection。如此一来我们就可以移除这个没用的connection了!
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
// We've found a connection to evict. Remove it from the list, then close it below (outside
// of the synchronized block).
connections.remove(longestIdleConnection);
}
总结:清理闲置连接的核心主要是引用计数器
List<Reference<StreamAllocation>>和选择排序的算法以及excutor的清理线程池。
部分参考:http://www.jianshu.com/p/92a61357164b
OkHttp3源码详解(五) okhttp连接池复用机制的更多相关文章
- OkHttp3源码详解(六) Okhttp任务队列工作原理
1 概述 1.1 引言 android完成非阻塞式的异步请求的时候都是通过启动子线程的方式来解决,子线程执行完任务的之后通过handler的方式来和主线程来完成通信.无限制的创建线程,会给系统带来大量 ...
- OkHttp3源码详解(一) Request类
每一次网络请求都是一个Request,Request是对url,method,header,body的封装,也是对Http协议中请求行,请求头,实体内容的封装 public final class R ...
- OkHttp3源码详解(三) 拦截器
1.构造Demo 首先构造一个简单的异步网络访问Demo: OkHttpClient client = new OkHttpClient(); Request request = new Reques ...
- OkHttp3源码详解(三) 拦截器-RetryAndFollowUpInterceptor
最大恢复追逐次数: ; 处理的业务: 实例化StreamAllocation,初始化一个Socket连接对象,获取到输入/输出流()基于Okio 开启循环,执行下一个调用链(拦截器),等待返回结果(R ...
- OkHttp3源码详解(二) 整体流程
1.简单使用 同步: @Override public Response execute() throws IOException { synchronized (this) { if (execut ...
- udhcp源码详解(五) 之DHCP包--options字段
中间有很长一段时间没有更新udhcp源码详解的博客,主要是源码里的函数太多,不知道要不要一个一个讲下去,要知道讲DHCP的实现理论的话一篇博文也就可以大致的讲完,但实现的源码却要关心很多的问题,比如说 ...
- spring事务详解(三)源码详解
系列目录 spring事务详解(一)初探事务 spring事务详解(二)简单样例 spring事务详解(三)源码详解 spring事务详解(四)测试验证 spring事务详解(五)总结提高 一.引子 ...
- 源码详解系列(六) ------ 全面讲解druid的使用和源码
简介 druid是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能,另外,druid还扩展 ...
- 源码详解系列(七) ------ 全面讲解logback的使用和源码
什么是logback logback 用于日志记录,可以将日志输出到控制台.文件.数据库和邮件等,相比其它所有的日志系统,logback 更快并且更小,包含了许多独特并且有用的特性. logback ...
随机推荐
- 【PHP篇】输出方法
php开始处加:error_reporting(E_ALL & ~E_NOTICE); //不打印注意 echo: echo “字符串”; //也可为单引号 echo $变量名; ech ...
- WebService学习-第一弹
一:WebService简介(1)简介----百度百科(注意标识的重点) Web service是一个平台独立的,低耦合的,自包含的.基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言 ...
- 《CLR Via C#》读书笔记:27.计算限制的异步操作
一.CLR 线程池基础 一般来说如果计算机的 CPU 利用率没有 100% ,那么说明很多进程的部分线程没有运行.可能在等待 文件/网络/数据库等设备读取或者写入数据,又可能是等待按键.鼠标移动等事件 ...
- mybatis框架(3)---SqlMapConfig.xml解析
SqlMapConfig.xml SqlMapConfig.xml是Mybatis的全局配置参数,关于他的具体用的有专门的MyBatis - API文档,这里面讲的非常清楚,所以我这里就挑几个讲下: ...
- Linux编程 13 (系统环境变量位置, 环境变量持久化)
一.系统环境变量位置 在上章中,知道了如何修改系统环境变量,如PATH变量,以及创建自己的全局环境变量和局部环境变量.这篇学习怎么让环境变量的作用持久化.在此之前,先了解下系统环境变量文件会在哪些位置 ...
- es6入门3--箭头函数与形参等属性的拓展
对函数拓展兴趣更大一点,优先看,前面字符串后面再说,那些API居多,会使用能记住部分就好. 一.函数参数可以使用默认值 1.默认值生效条件 在变量的解构赋值就提到了,函数参数可以使用默认值了.正常我们 ...
- Java反射,注解,以及动态代理
Java反射,注解,以及动态代理 基础 最近在准备实习面试,被学长问到了Java反射,注解和动态代理的内容,发现有点自己有点懵,这几天查了很多资料,就来说下自己的理解吧[如有错误,望指正] Java ...
- PyInstaller 打包 python程序成exe
pychaim下PyInstaller 打包 python程序 主题是使用PyInstaller 打包python时遇到一些问题以及解决方案,其中将要打包的程序是用tensorflow做的LSTM算法 ...
- Java 趣史-差点把 Java 命名成了 Silk(丝绸)
差点把 Java 命名成了 Silk(丝绸) Java 命名的由来 Java是印度尼西亚爪哇岛的英文名称,因盛产咖啡而闻名.Java语言中的许多库类名称,多与咖啡有关:如JavaBeans(咖啡豆). ...
- Redis 缓存应用实战
为了提高系统吞吐量,我们经常在业务架构中引入缓存层. 缓存通常使用 Redis / Memcached 等高性能内存缓存来实现, 本文以 Redis 为例讨论缓存应用中面临的一些问题. 缓存更新一致性 ...