Elasticsearch —— bulk批量导入数据
在使用Elasticsearch的时候,一定会遇到这种场景——希望批量的导入数据,而不是一条一条的手动导入。那么此时,就一定会需要bulk命令!
更多内容参考我整理的Elk教程
bulk批量导入
批量导入可以合并多个操作,比如index,delete,update,create等等。也可以帮助从一个索引导入到另一个索引。
语法大致如下;
action_and_meta_data\n
optional_source\n
action_and_meta_data\n
optional_source\n
....
action_and_meta_data\n
optional_source\n
需要注意的是,每一条数据都由两行构成(delete除外),其他的命令比如index和create都是由元信息行和数据行组成,update比较特殊它的数据行可能是doc也可能是upsert或者script,如果不了解的朋友可以参考前面的update的翻译。
注意,每一行都是通过\n回车符来判断结束,因此如果你自己定义了json,千万不要使用回车符。不然_bulk命令会报错的!
一个小例子
比如我们现在有这样一个文件,data.json:
{ "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }
它的第一行定义了_index,_type,_id等信息;第二行定义了字段的信息。
然后执行命令:
curl -XPOST localhost:9200/_bulk --data-binary @data.json
就可以看到已经导入进去数据了。
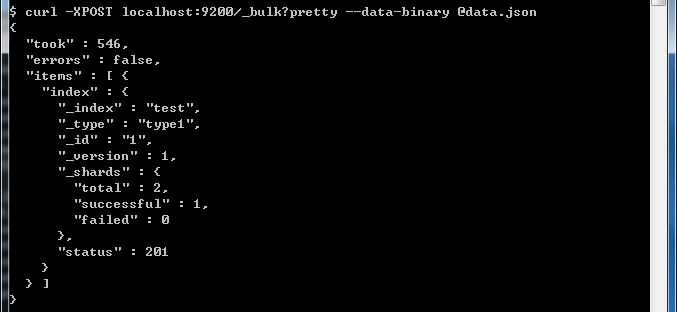
对于其他的index,delete,create,update等操作也可以参考下面的格式:
{ "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_type" : "type1", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "type1", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_type" : "type1", "_index" : "index1"} }
{ "doc" : {"field2" : "value2"} }
在Url中设置默认的index和type
如果在路径中设置了index或者type,那么在JSON中就不需要设置了。如果在JSON中设置,会覆盖掉路径中的配置。
比如上面的例子中,文件中定义了索引为test,类型为type1;而我们在路径中定义了默认的选项,索引为test333,类型为type333。执行命令后,发现文件中的配置会覆盖掉路径中的配置。这样也提供了统一的默认配置以及个性化的特殊配置的需求。

其他
由于bulk是一次性提交很多的命令,它会把这些数据都发送到一个节点,然后这个节点解析元数据(index或者type或者id之类的),然后分发给其他的节点的分片,进行操作。
由于很多命令执行后,统一的返回结果,因此数据量可能会比较大。这个时候如果使用的是chunk编码的方式,分段进行传输,可能会造成一定的延迟。因此还是对条件在客户端进行一定的缓冲,虽然bulk提供了批处理的方法,但是也不能给太大的压力!
最后要说一点的是,Bulk中的操作执行成功与否是不影响其他的操作的。而且也没有具体的参数统计,一次bulk操作,有多少成功多少失败。
扩展:在Logstash中,传输的机制其实就是bulk,只是他使用了Buffer,如果是服务器造成的访问延迟可能会采取重传,其他的失败就只丢弃了....
Elasticsearch —— bulk批量导入数据的更多相关文章
- elasticsearch bulk批量导入 大文件拆分
命令如下: curl -s -XPOST http://localhost:9200/_bulk --data-binary @data.json 如果上传的data.json文件较大,可以将其切分为 ...
- csv文件批量导入数据到sqlite。
csv文件批量导入数据到sqlite. 代码: f = web.input(bs_switch = {}) # bs_switch 为from表单file字段的namedata =[i.split( ...
- 使用python向Redis批量导入数据
1.使用pipeline进行批量导入数据.包含先使用rpush插入数据,然后使用expire改动过期时间 class Redis_Handler(Handler): def connect(self) ...
- Cassandra使用pycassa批量导入数据
本周接手了一个Cassandra系统的维护工作,有一项是需要将应用方的数据导入我们维护的Cassandra集群,并且为应用方提供HTTP的方式访问服务.这是我第一次接触KV系统,原来只是走马观花似的看 ...
- Redis批量导入数据的方法
有时候,我们需要给redis库中插入大量的数据,如做性能测试前的准备数据.遇到这种情况时,偶尔可能也会懵逼一下,这里就给大家介绍一个批量导入数据的方法. 先准备一个redis protocol的文件( ...
- 项目总结04:SQL批量导入数据:将具有多表关联的Excel数据,通过sql语句脚本的形式,导入到数据库
将具有多表关联的Excel数据,通过sql语句脚本的形式,导入到数据库 写在前面:本文用的语言是java:数据库是MySql: 需求:在实际项目中,经常会被客户要求,做批量导入数据:一般的简单的单表数 ...
- 批量导入数据到mssql数据库的
概述 批量导入数据到数据库中,我们有好几种方式. 从一个数据表里生成数据脚本,到另一个数据库里执行脚本 从EXCEL里导入数据 上面两种方式,导入的数据都会生成大量的日志.如果批量导入5W条数据到数据 ...
- asp.net线程批量导入数据时通过ajax获取执行状态
最近因为工作中遇到一个需求,需要做了一个批量导入功能,但长时间运行没个反馈状态,很容易让人看了心急,产生各种臆想!为了解决心里障碍,写了这么个功能. 通过线程执行导入,并把正在执行的状态存入sessi ...
- ADO.NET 对数据操作 以及如何通过C# 事务批量导入数据
ADO.NET 对数据操作 以及如何通过C# 事务批量导入数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ...
随机推荐
- 23种设计模式--工厂模式-Factory Pattern
一.工厂模式的介绍 工厂模式让我们相到的就是工厂,那么生活中的工厂是生产产品的,在代码中的工厂是生产实例的,在直白一点就是生产实例的类,代码中我们常用new关键字,那么这个new出来的实例 ...
- 【Web动画】SVG 实现复杂线条动画
在上一篇文章中,我们初步实现了一些利用基本图形就能完成的线条动画: [Web动画]SVG 线条动画入门 当然,事物都是朝着熵增焓减的方向发展的,复杂线条也肯定比有序线条要多. 很多时候,我们无法人工去 ...
- OpenCV模板匹配算法详解
1 理论介绍 模板匹配是在一幅图像中寻找一个特定目标的方法之一,这种方法的原理非常简单,遍历图像中的每一个可能的位置,比较各处与模板是否“相似”,当相似度足够高时,就认为找到了我们的目标.OpenCV ...
- 深入浅出JavaScript之原型链&继承
Javascript语言的继承机制,它没有"子类"和"父类"的概念,也没有"类"(class)和"实例"(instanc ...
- 水平可见直线 bzoj 1007
水平可见直线 (1s 128M) lines [问题描述] 在xoy直角坐标平面上有n条直线L1,L2,...Ln,若在y值为正无穷大处往下看,能见到Li的某个子线段,则称Li为可见的,否则Li为被覆 ...
- 【Java学习系列】第3课--Java 高级教程
本文地址 可以拜读: 从零开始学 Java 分享提纲: 1. Java数据结构 2. Java 集合框架 3. Java泛型 4. Java序列化 5. Java网络编程 6. Java发送Email ...
- 一些关于Linux入侵应急响应的碎碎念
近半年做了很多应急响应项目,针对黑客入侵.但疲于没有时间来总结一些常用的东西,寄希望用这篇博文分享一些安全工程师在处理应急响应时常见的套路,因为方面众多可能有些杂碎. 个人认为入侵响应的核心无外乎四个 ...
- 【开源】专业K线绘制[K线主副图、趋势图、成交量、滚动、放大缩小、MACD、KDJ等)
这是一个iOS项目雅黑深邃的K线的绘制. 实现功能包括K线主副图.趋势图.成交量.滚动.放大缩小.MACD.KDJ,长按显示辅助线等功能 预览图 最后的最后,这是项目的开源地址:https://git ...
- HA 高可用软件系统保养指南
又过了一年 618,六月是公司一年一度的大促月,一般提前一个月各系统就会减少需求和功能的开发,转而更多去关注系统可用性.稳定性和管控性等方面的非功能需求.大促前的准备工作一般叫作「备战」,可以把线上运 ...
- 浅析SQL查询语句未显式指定排序方式,无法保证同样的查询每次排序结果都一致的原因
本文出处:http://www.cnblogs.com/wy123/p/6189100.html 标题有点拗口,来源于一个开发人员遇到的实际问题 先抛出问题:一个查询没有明确指定排序方式,那么,第二次 ...