Redis 如何保持和MySQL数据一致【二】
需求起因
在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库。
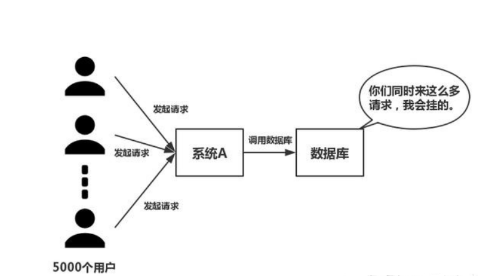
这个业务场景,主要是解决读数据从Redis缓存,一般都是按照下图的流程来进行业务
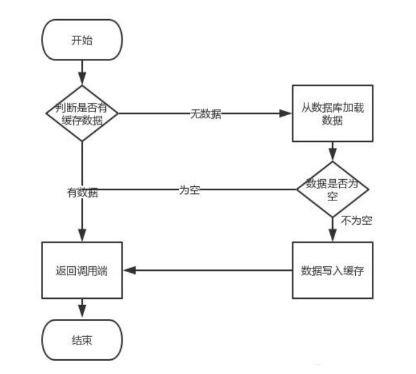
读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存(Redis)和数据库(MySQL)间的数据一致性问题。
不管是先写MySQL数据库,再删除Redis缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。举一个例子:
1.如果删除了缓存Redis,还没有来得及写库MySQL,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。
2.如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。
如来解决?这里给出两个解决方案,先易后难,结合业务和技术代价选择使用。
缓存和数据库一致性解决方案
1.第一种方案:采用延时双删策略
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。
伪代码如下
public void write( String key, Object data )
{
redis.delKey( key );
db.updateData( data );
Thread.sleep( );
redis.delKey( key );
}
2.具体的步骤就是:
- 先删除缓存
- 再写数据库
- 休眠500毫秒
- 再次删除缓存
那么,这个500毫秒怎么确定的,具体该休眠多久呢?
需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
当然这种策略还要考虑redis和数据库主从同步的耗时。最后的的写数据的休眠时间:则在读数据业务逻辑的耗时基础上,加几百ms即可。比如:休眠1秒。
3.设置缓存过期时间
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
4.该方案的弊端
结合双删策略+缓存超时设置,这样最差的情况就是在超时时间内数据存在不一致,而且又增加了写请求的耗时。
2、第二种方案:异步更新缓存(基于订阅binlog的同步机制)
1.技术整体思路:
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis
- 读Redis:热数据基本都在Redis
- 写MySQL:增删改都是操作MySQL
- 更新Redis数据:MySQ的数据操作binlog,来更新到Redis
2.Redis更新
(1)数据操作主要分为两大块:
- 一个是全量(将全部数据一次写入到redis)
- 一个是增量(实时更新)
这里说的是增量,指的是mysql的update、insert、delate变更数据。
(2)读取binlog后分析 ,利用消息队列,推送更新各台的redis缓存数据。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
这里可以结合使用canal(阿里的一款开源框架),通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。
当然,这里的消息推送工具你也可以采用别的第三方:kafka、rabbitMQ等来实现推送更新Redis!
Redis 如何保持和MySQL数据一致【二】的更多相关文章
- Redis 如何保持和MySQL数据一致
1. MySQL持久化数据,Redis只读数据 redis在启动之后,从数据库加载数据. 读请求: 不要求强一致性的读请求,走redis,要求强一致性的直接从mysql读取 写请求: 数据首先都写到数 ...
- Redis 如何保持和MySQL数据一致【一】
1. MySQL持久化数据,Redis只读数据redis在启动之后,从数据库加载数据.读请求:不要求强一致性的读请求,走redis,要求强一致性的直接从mysql读取写请求:数据首先都写到数据库,之后 ...
- MySQL数据备份与恢复(二) -- xtrabackup工具
上一篇介绍了逻辑备份工具mysqldump,本文将通过应用更为普遍的物理备份工具xtrabackup来演示数据备份及恢复的第二篇内容. 1. xtrabackup 工具的安装 1.1 安装依赖包 ...
- redis的key对应mysql数据表设计
根据用户名来查询用户信息 在关系型数据中,除主键外,还有可能其他列也步骤查询, 如上表中, username 也是极频繁查询的,往往这种列也是加了索引的. 转换到k-v数据中,则也要相应的生成一条按照 ...
- 转载:mysql数据同步redis
from: http://www.cnblogs.com/zhxilin/archive/2016/09/30/5923671.html 在服务端开发过程中,一般会使用MySQL等关系型数据库作为最终 ...
- mysql数据向Redis快速导入
Redis协议 *<args><cr><lf> 参数个数 $<len><cr><lf> 第一个参数长度 <arg0> ...
- 快速同步mysql数据到redis中
MYSQL快速同步数据到Redis 举例场景:存储游戏玩家的任务数据,游戏服务器启动时将mysql中玩家的数据同步到redis中. 从MySQL中将数据导入到Redis的Hash结构中.当然,最直接的 ...
- [python]mysql数据缓存到redis中 取出时候编码问题
描述: 一个web服务,原先的业务逻辑是把mysql查询的结果缓存在redis中一个小时,加快请求的响应. 现在有个问题就是根据请求的指定的编码返回对应编码的response. 首先是要修改响应的bo ...
- Redis和mysql数据怎么保持数据一致的?
需求起因 在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节.所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库. 这个业务场景, ...
随机推荐
- Centos7搭建vsftp服务器
环境查看 安装vsftp软件 yum -y install vsftpd 修改配置文件/etc/vsftpd/vsftpd.conf (其余配置保持默认即可) anonymous_enable=NO ...
- 洛谷P2463 Sandy的卡片【后缀数组】【二分】
题目描述 Sandy和Sue的热衷于收集干脆面中的卡片. 然而,Sue收集卡片是因为卡片上漂亮的人物形象,而Sandy则是为了积攒卡片兑换超炫的人物模型. 每一张卡片都由一些数字进行标记,第i张卡片的 ...
- ECNU 3260 - 袋鼠妈妈找孩子
题目链接:http://acm.ecnu.edu.cn/problem/3260/ Time limit per test: 1.5 seconds Time limit all tests: 10. ...
- POJ - 1191 棋盘分割 记忆递归 搜索dp+数学
http://poj.org/problem?id=1191 题意:中文题. 题解: 1.关于切割的模拟,用递归 有这样的递归方程(dp方程):f(n,棋盘)=f(n-1,待割的棋盘)+f(1,割下的 ...
- Reading table information for completion of table and column names
mysql> use ad_detail_page;Reading table information for completion of table and column namesYou c ...
- window10 telnet的启用
(1) window+R打开运行窗口,输入control,如图: (2) 点击类别改成大图标: 如图所示: 然后点击程序和功能. (3) 然后依次点击:启用或者关闭windows功能->teln ...
- 从0开始做一个的Vue图片/ 文件选择(上传)组件[基础向]
原文:http://blog.csdn.net/sinat_17775997/article/details/58585142 之前用Vue做了一个基础的组件 vue-img-inputer ,下面就 ...
- 【python-opencv】20-图像金字塔
知识点介绍 图像金字塔原理: 高斯金字塔 拉普拉斯金字塔: 代码层面知识点: cv2.PyrDown:降采样 cv2.PyrUp:升采样 高斯金字塔与拉普拉斯金字塔 图像金字塔是图像中多尺度表达的 ...
- 【Pyton】【小甲鱼】爬虫
一.什么是爬虫? 可以理解为一只蜘蛛,在不同的网页上爬来爬去,获取我们需要的资源 二.Python如何访问互联网 urllib(一个包)=url(网页地址)+lib() 第一部分:protocol:/ ...
- spfa 判断负环 (转载)
当然,对于Spfa判负环,实际上还有优化:就是把判断单个点的入队次数大于n改为:如果总的点入队次数大于所有点两倍 时有负环,或者单个点的入队次数大于sqrt(点数)有负环.这样时间复杂度就降了很多了. ...