Mapreduce实验一:WordCountTest
1.确定Hadoop处于启动状态
[root@neusoft-master ~]# jps
23763 Jps
3220 SecondaryNameNode
3374 ResourceManager
2935 NameNode
3471 NodeManager
3030 DataNode
2. 在/usr/local/filecotent下新建hellodemo文件,并写入以下内容,以\t(tab键隔开)
[root@neusoft-master filecontent]# vi hellodemo
hello you
hello me
3.在linux中执行以下步骤:
3.1hdfs中创建data目录
[root@neusoft-master filecontent]# hadoop dfs -mkdir /data
3.2 将/usr/local/filecontent/hellodemo 上传到hdfs的data目录中
[root@neusoft-master filecontent]# hadoop dfs -put hellodemo /data
3.3查看data目录下的内容
[root@neusoft-master filecontent]# hadoop dfs -ls /data
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
17/02/01 00:39:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 3 root supergroup 19 2017-02-01 00:39 /data/hellodemo
3.4查看hellodemo的文件内容
[root@neusoft-master filecontent]# hadoop dfs -text /data/hellodemo
4. 编写WordCountTest.java并打包成jar文件
package Mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; /**
* 假设有个目录结构
* /目录1
* /目录1/hello.txt
* /目录1/目录2/hello.txt
*
* 问:统计/目录1下面所有的文件中的单词技术
*
*/
public class WordCountTest {
public static void main(String[] args) throws Exception {
//2将自定义的MyMapper和MyReducer组装在一起
Configuration conf=new Configuration();
String jobName=WordCountTest.class.getSimpleName();
//1首先寫job,知道需要conf和jobname在去創建即可
Job job = Job.getInstance(conf, jobName); //*13最后,如果要打包运行改程序,则需要调用如下行
job.setJarByClass(WordCountTest.class); //3读取HDFS內容:FileInputFormat在mapreduce.lib包下
FileInputFormat.setInputPaths(job, new Path("hdfs://neusoft-master:9000/data/hellodemo"));
//4指定解析<k1,v1>的类(谁来解析键值对)
job.setInputFormatClass(TextInputFormat.class);
//5指定自定义mapper类
job.setMapperClass(MyMapper.class);
//6指定map输出的key2的类型和value2的类型 <k2,v2>
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//7分区(默认1个),排序,分组,规约 采用 默认 //接下来采用reduce步骤
//8指定自定义的reduce类
job.setReducerClass(MyReducer.class);
//9指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//10指定输出<K3,V3>的类
job.setOutputFormatClass(TextOutputFormat.class);
//11指定输出路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://neusoft-master:9000/out1")); //12写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
}
private static class MyMapper extends Mapper<LongWritable, Text, Text,LongWritable>{
Text k2 = new Text();
LongWritable v2 = new LongWritable();
@Override
protected void map(LongWritable key, Text value,//三个参数
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] splited = line.split("\t");//因为split方法属于string字符的方法,首先应该转化为string类型在使用
for (String word : splited) {
//word表示每一行中每个单词
//对K2和V2赋值
k2.set(word);
v2.set(1L);
context.write(k2, v2);
}
}
}
private static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
LongWritable v3 = new LongWritable();
@Override //k2表示单词,v2s表示不同单词出现的次数,需要对v2s进行迭代
protected void reduce(Text k2, Iterable<LongWritable> v2s, //三个参数
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
long sum =0;
for (LongWritable v2 : v2s) {
//LongWritable本身是hadoop类型,sum是java类型
//首先将LongWritable转化为字符串,利用get方法
sum+=v2.get();
}
v3.set(sum);
//将k2,v3写出去
context.write(k2, v3);
}
}
}
WordCountTest.java
//1首先寫job,知道需要conf和jobname在去創建即可
Job job = Job.getInstance(conf, jobName);
//2将自定义的MyMapper和MyReducer组装在一起
Configuration conf=new Configuration();
String jobName=WordCountTest.class.getSimpleName();
FileInputFormat.setInputPaths(job, new Path("hdfs://neusoft-master:9000/data/hellodemo"));
//4指定解析<k1,v1>的类(谁来解析键值对)
job.setInputFormatClass(TextInputFormat.class);
//5指定自定义mapper类
job.setMapperClass(MyMapper.class);
//6指定map输出的key2的类型和value2的类型 <k2,v2>
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//7分区(默认1个),排序,分组,规约 采用 默认
//接下来采用reduce步骤
//8指定自定义的reduce类
job.setReducerClass(MyReducer.class);
//9指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//10指定输出<K3,V3>的类
job.setOutputFormatClass(TextOutputFormat.class);
//11指定输出路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://neusoft-master:9000/out1"));
//12写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
//*13最后,如果要打包运行改程序,则需要调用如下行
job.setJarByClass(WordCountTest.class);
mapper任务
private static class MyMapper extends Mapper<LongWritable, Text, Text,LongWritable>{
Text k2 = new Text();
LongWritable v2 = new LongWritable();
@Override
protected void map(LongWritable key, Text value,//三个参数
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] splited = line.split("\t");//因为split方法属于string字符的方法,首先应该转化为string类型在使用
for (String word : splited) {
//word表示每一行中每个单词
//对K2和V2赋值
k2.set(word);
v2.set(1L);
context.write(k2, v2);
}
}
}
Reducer任务
private static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
LongWritable v3 = new LongWritable();
@Override //k2表示单词,v2s表示不同单词出现的次数,需要对v2s进行迭代
protected void reduce(Text k2, Iterable<LongWritable> v2s, //三个参数
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
long sum =0;
for (LongWritable v2 : v2s) {
//LongWritable本身是hadoop类型,sum是java类型
//首先将LongWritable转化为字符串,利用get方法
sum+=v2.get();
}
v3.set(sum);
//将k2,v3写出去
context.write(k2, v3);
}
}
}
5.打成jar包并指定主类,在linux中运行
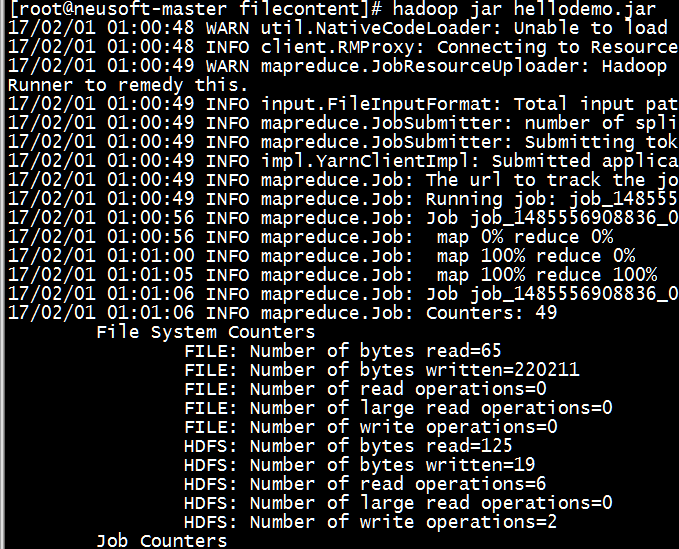
[root@neusoft-master filecontent]# hadoop jar hellodemo.jar
17/02/01 01:00:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/02/01 01:00:48 INFO client.RMProxy: Connecting to ResourceManager at neusoft-master/192.168.191.130:8080
17/02/01 01:00:49 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/02/01 01:00:49 INFO input.FileInputFormat: Total input paths to process : 1
17/02/01 01:00:49 INFO mapreduce.JobSubmitter: number of splits:1
17/02/01 01:00:49 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1485556908836_0003
17/02/01 01:00:49 INFO impl.YarnClientImpl: Submitted application application_1485556908836_0003
17/02/01 01:00:49 INFO mapreduce.Job: The url to track the job: http://neusoft-master:8088/proxy/application_1485556908836_0003/
17/02/01 01:00:49 INFO mapreduce.Job: Running job: job_1485556908836_0003
17/02/01 01:00:56 INFO mapreduce.Job: Job job_1485556908836_0003 running in uber mode : false
17/02/01 01:00:56 INFO mapreduce.Job: map 0% reduce 0%
17/02/01 01:01:00 INFO mapreduce.Job: map 100% reduce 0%
17/02/01 01:01:05 INFO mapreduce.Job: map 100% reduce 100%
17/02/01 01:01:06 INFO mapreduce.Job: Job job_1485556908836_0003 completed successfully
17/02/01 01:01:06 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=65
FILE: Number of bytes written=220211
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=125
HDFS: Number of bytes written=19
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2753
Total time spent by all reduces in occupied slots (ms)=3020
Total time spent by all map tasks (ms)=2753
Total time spent by all reduce tasks (ms)=3020
Total vcore-seconds taken by all map tasks=2753
Total vcore-seconds taken by all reduce tasks=3020
Total megabyte-seconds taken by all map tasks=2819072
Total megabyte-seconds taken by all reduce tasks=3092480
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=51
Map output materialized bytes=65
Input split bytes=106
Combine input records=0
Combine output records=0
Reduce input groups=3
Reduce shuffle bytes=65
Reduce input records=4
Reduce output records=3
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=40
CPU time spent (ms)=1550
Physical memory (bytes) snapshot=448503808
Virtual memory (bytes) snapshot=3118854144
Total committed heap usage (bytes)=319291392
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=19
File Output Format Counters
Bytes Written=19
*********************
6.查看输出文件内容
[root@neusoft-master filecontent]# hadoop dfs -ls /out1
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
17/02/01 01:01:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 3 root supergroup 0 2017-02-01 01:01 /out1/_SUCCESS
-rw-r--r-- 3 root supergroup 19 2017-02-01 01:01 /out1/part-r-00000

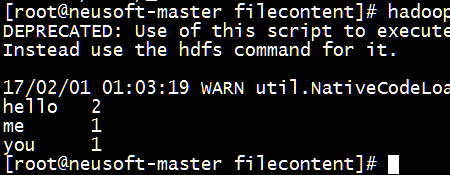
[root@neusoft-master filecontent]# hadoop dfs -text /out1/part-r-00000
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
17/02/01 01:03:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
hello 2
me 1
you 1
7.结果分析
根据上传到Hdfs中得文件和所得结果分析,所得结果是正确无误的。
注意:主函数中得方法有一些步骤是可省的,需要着重注意
其中第6、8、10步均可省略
public static void main(String[] args) throws Exception {
//必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定
//2将自定义的MyMapper和MyReducer组装在一起
Configuration conf=new Configuration();
String jobName=WordCountTest.class.getSimpleName();
//1首先寫job,知道需要conf和jobname在去創建即可
Job job = Job.getInstance(conf, jobName);
//*13最后,如果要打包运行改程序,则需要调用如下行
job.setJarByClass(WordCountTest.class);
//3读取HDFS內容:FileInputFormat在mapreduce.lib包下
FileInputFormat.setInputPaths(job, new Path("hdfs://neusoft-master:9000/data/hellodemo"));
//4指定解析<k1,v1>的类(谁来解析键值对)
//*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class
job.setInputFormatClass(TextInputFormat.class);
//5指定自定义mapper类
job.setMapperClass(MyMapper.class);
//6指定map输出的key2的类型和value2的类型 <k2,v2>
//*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//7分区(默认1个),排序,分组,规约 采用 默认
//接下来采用reduce步骤
//8指定自定义的reduce类
job.setReducerClass(MyReducer.class);
//9指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//10指定输出<K3,V3>的类
//*下面这一步可以省
job.setOutputFormatClass(TextOutputFormat.class);
//11指定输出路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://neusoft-master:9000/out1"));
//12写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
}
END
Mapreduce实验一:WordCountTest的更多相关文章
- 实验六 MapReduce实验:二次排序
实验指导: 6.1 实验目的基于MapReduce思想,编写SecondarySort程序. 6.2 实验要求要能理解MapReduce编程思想,会编写MapReduce版本二次排序程序,然后将其执行 ...
- mapreduce实验
代码: public class WordCount { public static void main(String[] args) throws IOException, ClassNotFoun ...
- Mit6.824 Lab1-MapReduce
前言 Mit6.824 是我在学习一些分布式系统方面的知识的时候偶然看到的,然后就开始尝试跟课.不得不说,国外的课程难度是真的大,一周的时间居然要学一门 Go 语言,然后还要读论文,进而做MapRed ...
- 实验6:Mapreduce实例——WordCount
实验目的1.准确理解Mapreduce的设计原理2.熟练掌握WordCount程序代码编写3.学会自己编写WordCount程序进行词频统计实验原理MapReduce采用的是“分而治之”的 ...
- 大型数据库技术实验六 实验6:Mapreduce实例——WordCount
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1. buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\t ...
- Hadoop大实验——MapReduce的操作
日期:2019.10.30 博客期:114 星期三 实验6:Mapreduce实例——WordCount 实验说明: 1. 本次实验是第六次上机,属于验证性实验.实验报告上交截止 ...
- 云计算——实验一 HDFS与MAPREDUCE操作
1.虚拟机集群搭建部署hadoop 利用VMware.centOS-7.Xshell(secureCrt)等软件搭建集群部署hadoop 远程连接工具使用Xshell: HDFS文件操作 2.1 HD ...
- mapreduce课上实验
今天我们课上做了一个关于数据清洗的实验,具体实验内容如下: 1.数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中: 2.数据处理: ·统计最受欢迎的视频/文章的Top10访问次数 (v ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
随机推荐
- 《倾国倾城》全套源代码:client+服务端+资源,歧视复制帖子
郝萌主倾心贡献,尊重作者的劳动成果,请勿转载. 假设文章对您有所帮助,欢迎给作者捐赠,支持郝萌主,捐赠数额任意.重在心意^_^ 我要捐赠: 点击捐赠 Cocos2d-X源代码下载:点我传送 游戏官方下 ...
- Dubbo -- 系统学习 笔记 -- 示例 -- 直连提供者
Dubbo -- 系统学习 笔记 -- 目录 示例 想完整的运行起来,请参见:快速启动,这里只列出各种场景的配置方式 直连提供者 在开发及测试环境下,经常需要绕过注册中心,只测试指定服务提供者,这时候 ...
- pgpool-II 的使用
1.pgpool-II的概念 pgpool-II 是一个位于 PostgreSQL 服务器和 PostgreSQL 数据库客户端之间的中间件,它提供以下功能: 连接池 pgpool-II 保持已经连接 ...
- osgEarth设置模型旋转角度
#include<windows.h> #include <osgViewer/Viewer> #include <osgEarthDrivers/gdal/GDALOp ...
- delphi xe 怎么生成apk
f9 运行: 让它执行install[如果没有连接到android环境,会提示安装失败]或, 就在bin下面产生一个apk文件了:好像单单build是没法产生的.
- android第三方---->android智能机器人的使用
在网上找了个第三方智能机器人,可以实现聊天语音等功能,比较不错的.今天我们就开始智能机器人聊天的学习,例子中涉及的handler的有关知识和json数据的解析,请参见我的博客:android基础--- ...
- 删除RHSA文件方法
DEL /F /A /Q \\?\%1RD /S /Q \\?\%1新建一个批处理文件,包含上面两行代码,然后将要删除的文件拖放进里面就OK!
- Word 2010 制作文档结构之图标自动编号设置
注意: 使用图片自动编号时,如果文档标题使用的样式是通过“将所选内容保存为新快速样式”所生成的样式,则图片自动编号不会生效 因此设置标题样式时,不要 新建样式,直接使用word预设的“标题 1”样式和 ...
- [Error: Failed to find 'ANDROID_HOME' environment variable. Try setting setting it manually
7down voteaccepted I don't think its necessary to add everything into path.Just add the JAVA_HOME , ...
- java(4) 异常
1.Throwable 继承体系 * Eorro * Exception --RuntimeException 该类及其子类用于表示运行时异常,Exception类下所有其他子类都用于表示编译时异常. ...