python+selenium+requests爬取我的博客粉丝的名称
爬取目标
1.本次代码是在python2上运行通过的,python3的最需改2行代码,用到其它python模块
- selenium 2.53.6 +firefox 44
- BeautifulSoup
- requests
2.爬取目标网站,我的博客:https://home.cnblogs.com/u/yoyoketang
爬取内容:爬我的博客的所有粉丝的名称,并保存到txt
3.由于博客园的登录是需要人机验证的,所以是无法直接用账号密码登录,需借助selenium登录
selenium获取cookies
1.大前提:先手工操作浏览器,登录我的博客,并记住密码
(保证关掉浏览器后,下次打开浏览器访问我的博客时候是登录状态)
2.selenium默认启动浏览器是一个空的配置,默认不加载配置缓存文件,这里先得找到对应浏览器的配置文件地址,以火狐浏览器为例
3.使用driver.get_cookies()方法获取浏览器的cookies
# coding:utf-8
import requests
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import time
# firefox浏览器配置文件地址
profile_directory = r'C:\Users\admin\AppData\Roaming\Mozilla\Firefox\Profiles\yn80ouvt.default'
# 加载配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
driver = webdriver.Firefox(profile)
driver.get("https://home.cnblogs.com/u/yoyoketang/followers/")
time.sleep(3)
cookies = driver.get_cookies() # 获取浏览器cookies
print(cookies)
driver.quit()
(注:要是这里脚本启动浏览器后,打开的博客页面是未登录的,后面内容都不用看了,先检查配置文件是不是写错了)
requests添加登录的cookies
1.浏览器的cookies获取到后,接下来用requests去建一个session,在session里添加登录成功后的cookies
s = requests.session() # 新建session
# 添加cookies到CookieJar
c = requests.cookies.RequestsCookieJar()
for i in cookies:
c.set(i["name"], i['value'])
s.cookies.update(c) # 更新session里cookies
计算粉丝数和分页总数
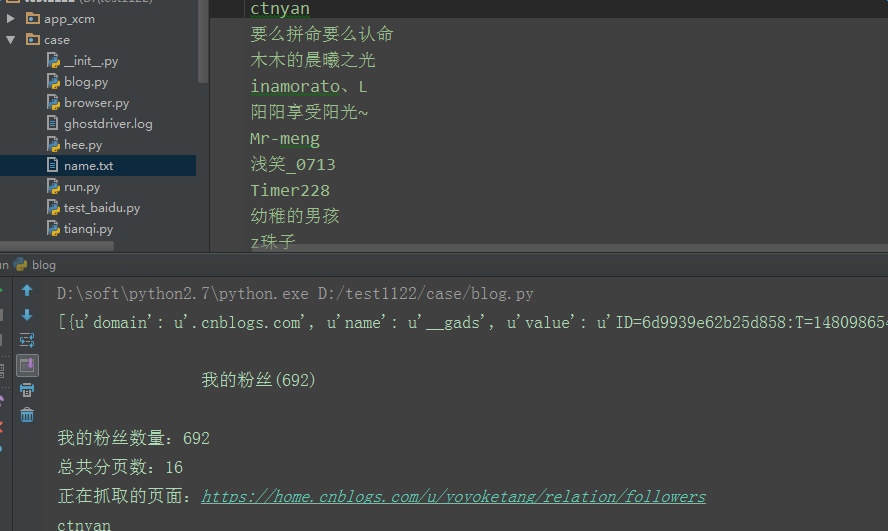
1.由于我的粉丝的数据是分页展示的,这里一次只能请求到45个,所以先获取粉丝总数,然后计算出总的页数
# 发请求
r1 = s.get("https://home.cnblogs.com/u/yoyoketang/relation/followers")
soup = BeautifulSoup(r1.content, "html.parser")
# 抓取我的粉丝数
fensinub = soup.find_all(class_="current_nav")
print fensinub[0].string
num = re.findall(u"我的粉丝\((.+?)\)", fensinub[0].string)
print u"我的粉丝数量:%s"%str(num[0])
# 计算有多少页,每页45条
ye = int(int(num[0])/45)+1
print u"总共分页数:%s"%str(ye)
保存粉丝名到txt
# 抓取第一页的数据
fensi = soup.find_all(class_="avatar_name")
for i in fensi:
name = i.string.replace("\n", "").replace(" ","")
print name
with open("name.txt", "a") as f: # 追加写入
f.write(name.encode("utf-8")+"\n")
# 抓第二页后的数据
for i in range(2, ye+1):
r2 = s.get("https://home.cnblogs.com/u/yoyoketang/relation/followers?page=%s"%str(i))
soup = BeautifulSoup(r1.content, "html.parser")
# 抓取我的粉丝数
fensi = soup.find_all(class_="avatar_name")
for i in fensi:
name = i.string.replace("\n", "").replace(" ","")
print name
with open("name.txt", "a") as f: # 追加写入
f.write(name.encode("utf-8")+"\n")
参考代码:
# coding:utf-8
import requests
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import time
# firefox浏览器配置文件地址
profile_directory = r'C:\Users\admin\AppData\Roaming\Mozilla\Firefox\Profiles\yn80ouvt.default'
s = requests.session() # 新建session
url = "https://home.cnblogs.com/u/yoyoketang"
def get_cookies(url):
'''启动selenium获取登录的cookies'''
try:
# 加载配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
driver = webdriver.Firefox(profile)
driver.get(url+"/followers")
time.sleep(3)
cookies = driver.get_cookies() # 获取浏览器cookies
print(cookies)
driver.quit()
return cookies
except Exception as msg:
print(u"启动浏览器报错了:%s" %str(msg))
def add_cookies(cookies):
'''往session添加cookies'''
try:
# 添加cookies到CookieJar
c = requests.cookies.RequestsCookieJar()
for i in cookies:
c.set(i["name"], i['value'])
s.cookies.update(c) # 更新session里cookies
except Exception as msg:
print(u"添加cookies的时候报错了:%s" % str(msg))
def get_ye_nub(url):
'''获取粉丝的页面数量'''
try:
# 发请求
r1 = s.get(url+"/relation/followers")
soup = BeautifulSoup(r1.content, "html.parser")
# 抓取我的粉丝数
fensinub = soup.find_all(class_="current_nav")
print(fensinub[0].string)
num = re.findall(u"我的粉丝\((.+?)\)", fensinub[0].string)
print(u"我的粉丝数量:%s"%str(num[0]))
# 计算有多少页,每页45条
ye = int(int(num[0])/45)+1
print(u"总共分页数:%s"%str(ye))
return ye
except Exception as msg:
print(u"获取粉丝页数报错了,默认返回数量1 :%s"%str(msg))
return 1
def save_name(nub):
'''抓取页面的粉丝名称'''
try:
# 抓取第一页的数据
if nub <= 1:
url_page = url+"/relation/followers"
else:
url_page = url+"/relation/followers?page=%s" % str(nub)
print(u"正在抓取的页面:%s" %url_page)
r2 = s.get(url_page, verify=False)
soup = BeautifulSoup(r2.content, "html.parser")
fensi = soup.find_all(class_="avatar_name")
for i in fensi:
name = i.string.replace("\n", "").replace(" ","")
print(name)
with open("name.txt", "a") as f: # 追加写入
f.write(name.encode("utf-8")+"\n")
# python3的改成下面这两行
# with open("name.txt", "a", encoding="utf-8") as f: # 追加写入
# f.write(name+"\n")
except Exception as msg:
print(u"抓取粉丝名称过程中报错了 :%s"%str(msg))
if __name__ == "__main__":
cookies = get_cookies(url)
add_cookies(cookies)
n = get_ye_nub(url)
for i in list(range(1, n+1)):
save_name(i)
---------------------------------python接口自动化完整版-------------------------
全书购买地址 https://yuedu.baidu.com/ebook/585ab168302b3169a45177232f60ddccda38e695
作者:上海-悠悠 QQ交流群:588402570
也可以关注下我的个人公众号:

python+selenium+requests爬取我的博客粉丝的名称的更多相关文章
- python3+selenium3+requests爬取我的博客粉丝的名称
爬取目标 1.本次代码是在python3上运行通过的 selenium3 +firefox59.0.1(最新) BeautifulSoup requests 2.爬取目标网站,我的博客:https:/ ...
- python+selenium+requests爬取qq空间相册时遇到的问题及解决思路
最近研究了下用python爬取qq空间相册的问题,遇到的问题及解决思路如下: 1.qq空间相册的访问需要qq登录并且需是好友,requests模块模拟qq登录略显麻烦,所以采用selenium的dri ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- Scrapy爬取自己的博客内容
python中常用的写爬虫的库有urllib2.requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现.这里有一篇我之前写过的用urllib2+BeautifulSoup做的一 ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- python+selenium+PhantomJS爬取网页动态加载内容
一般我们使用python的第三方库requests及框架scrapy来爬取网上的资源,但是设计javascript渲染的页面却不能抓取,此时,我们使用web自动化测试化工具Selenium+无界面浏览 ...
- python+selenium+xpath 爬取天眼查工商基本信息
# -*- coding:utf-8 -*-# author: kevin# CreateTime: 2018/8/16# software-version: python 3.7 import ti ...
- 看我怎么扒掉CSDN首页的底裤(python selenium+phantomjs爬取CSDN首页内容)
这里只是学习一下动态加载页面内容的抓取,并不适用于所有的页面. 使用到的工具就是python selenium和phantomjs,另外调试的时候还用了firefox的geckodriver.exe. ...
随机推荐
- nginx keepalive 高可用
https://blog.csdn.net/u012410733/article/details/57078407 在网络中机器不可避免的出现单点故障,当我们使用nginx进行反向代理的时候如果出现了 ...
- 网络编程初探--使用UDP协议的简易聊天室
UDP是一种无连接的传输层协议,提供快速不可靠的服务. 一.发送端 * 创建UDP发送端 * 步骤: * 1.建立UDP的Socket服务 * 2.将要发送的数据封装到数据包中 * 3.通过UDP的s ...
- Stones 优先队列
Because of the wrong status of the bicycle, Sempr begin to walk east to west every morning and walk ...
- windows dos命令
dos命令配置环境变量: path=%path%;D:\Installed software\Professional software\Python27 (https://www.cnblogs ...
- .gitignore忽略git版本库中的文件(夹)
# 忽略*.o和*.a文件 *.[oa] # 忽略*.b和*.B文件,my.b除外 *.[bB] !my.b # 忽略dbg文件和dbg目录 dbg # 只忽略dbg目录,不忽略dbg文件 dbg/ ...
- NoSQLUnit
NoSQLUnit Core Overview Unit testing is a method by which the smallest testable part of an applicati ...
- 高大上的JS工具
EtherPad (协同文件编辑): EtherCalc (协同电子表格编辑)
- 设置zedgraph鼠标拖拽和局部放大属性(转帖)
说一下几个属性的意义和具体应用: (1)鼠标拖拽显示区域 PanModifierKeys ->> Gets or sets a value that determines which mo ...
- 【jmeter】jmeter环境搭建
一. 工具描述 apache jmeter是100%的java桌面应用程序,它被设计用来加载被测试软件功能特性.度量被测试软件的性能.设计jmeter的初衷是测试web应用,后来又扩充了其它的功能.j ...
- linux 信号处理 五 (示例)
[摘要]本文分析了Linux内核对于信号的实现机制和应用层的相关处理.首先介绍了软中断信号的本质及信号的两种不同分类方法尤其是不可靠信号的原理.接着分析了内核对于信号的处理流程包括信号的触发/注册/执 ...