支持向量机(理论+opencv实现)


 、
、 、
、 求出x,y,λ的值,代入即可得到目标函数的极值。
求出x,y,λ的值,代入即可得到目标函数的极值。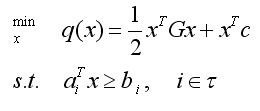
3.线性中的对偶
线性规划有一个有趣的特性,就是任何一个求极大的问题都有一个与其匹配的求极小的线性规划问题。
例;原问题为
MAX X=8*Z1+10*Z2+2*Z3
s.t. 2*Z1+1*Z2+3*Z3 <=70
4*Z1+2*Z2+2*Z3 <=80
3*Z1+ 1*Z3 <=15
2*Z1+2*Z2 <=50
Z1,Z2,Z3 〉=0
Z则其对偶问题为
MIN =70*Y1+80*Y2+15*Y3+50*Y4
s.t 2*y1+4*y2+3*y3+2*y4>=8
1*y1+2*y2+ 1*y4>=10
3*y1+2*y2+1*y3 >=2
y1,y2,y3,y3>=0 可以看出:
1、若一个模型为目标求 极大 约束为 小于等于的不等式,则它的对偶模型为目标求极小 约束为极大的不等式
即 “MAX,〈=” “与MIN,〉=”相对应
2、从约束条件系数矩阵来看,一个模型中为A 另一个为A的转质,一个模型是 m个约束n个变量 则他的对偶模型为n个约束 m个变量
3、从数据b c 的位置看 两个规划模型中b和 c的位置对换
即8、10、2 与 70、80、15、50 对换
4、两个规划模型中变量非负。
4. 内积空间





5.欧式空间


6.线性空间、希尔伯特空间、巴拿赫空间




在数学中有许多空间表示,比如欧几里德空间、赋范空间、希尔伯特空间等。这些空间之间有什么关系呢?
首先要从距离的定义说起。
什么是距离呢?实际上距离除了我们经常用到的直线距离外,还有向量距离如Σni=1xi⋅yi−−−−−−−−√, 函数距离如∫ba(f(x)−g(x))2dx、 曲面距离、折线距离等等,这些具体的距离与距离之间的关系类似于苹果、香蕉等与水果的关系,前面是具体的事物,后面是抽象的概念。距离就是一个抽象的概念,其定义为:
设X是任一非空集,对X中任意两点x,y,有一实数d(x,y)与之对应且满足:
1. d(x,y) ≥0,且d(x,y)=0当且仅当x=y;
2. d(x,y)=d(y,x);
3. d(x,y) ≤d(x,z)+d(z,y)。
称d(x,y)为X中的一个距离。
定义了距离后,我们再加上线性结构,如向量的加法、数乘,使其满足加法的交换律、结合律、零元、负元;数乘的交换律、单位一;数乘与加法的结合律(两个)共八点要求,从而形成一个线性空间,这个线性空间就是向量空间。
在向量空间中,我们定义了范数的概念,表示某点到空间零点的距离:
1. ||x|| ≥0;
2. ||ax||=|a|||x||;
3. ||x+y||≤||x||+||y||。
将范数与距离比较,可知,范数比距离多了一个条件2,数乘的运算,表明其是一个强化了的距离概念。范数与距离的关系可以类似理解为与红富士苹果与苹果的关系。
接下来对范数和距离进行扩展,形成如下:
范数的集合⟶ 赋范空间+线性结构⟶线性赋范空间
距离的集合⟶ 度量空间+线性结构⟶线性度量空间
下面在已经构成的线性赋范空间上继续扩展,添加内积运算,使空间中有角的概念,形成如下:
线性赋范空间+内积运算⟶ 内积空间;
这时的内积空间已经有了距离、长度、角度等,有限维的内积空间也就是我们熟悉的欧氏空间。
继续在内积空间上扩展,使得内积空间满足完备性,形成希尔伯特空间如下:
内积空间+完备性⟶ 希尔伯特空间
其中完备性的意思就是空间中的极限运算不能跑出该空间,如有理数空间中的2√ 的小数表示,其极限随着小数位数的增加收敛到2√,但2√ 属于无理数,并不在有理数空间,故不满足完备性。一个通俗的理解是把学校理解为一个空间,你从学校内的宿舍中开始一直往外走,当走不动停下来时(极限收敛),发现已经走出学校了(超出空间),不在学校范围内了(不完备了)。希尔伯特就相当于地球,无论你怎么走,都还在地球内(飞出太空除外)。
此外,前面提到的赋范空间,使其满足完备性,扩展形成巴拿赫空间如下:
赋范空间+完备性⟶ 巴拿赫空间
以上均是在距离的概念上进行添加约束形成的,递增关系如下:
距离⟶范数⟶内积
向量空间+范数⟶ 赋范空间+线性结构⟶线性赋范空间+内积运算⟶内积空间+完备性⟶希尔伯特空间
内积空间+有限维⟶欧几里德空间
赋范空间+完备性⟶巴拿赫空间
顺便提以下,对距离进行弱化,保留距离的极限和连续概念,就形成拓扑的概念。
有了上面的基础知识,下面开始支持向量机的理论学习
注:已经有很多关于SVM的优秀文章,自认为我距离大牛很远而且表达的没他们好,所以接下来的分析是我觉得难懂的地方,或者自认为老师和前辈们感觉太简单没说到的地方。
1.开篇距离公式推导
推导如下的公式:


2.SMO算法(主体来自博客,下面会给出链接,自己更改的部分已经标注)
假设我们选取了初始值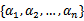 满足了问题中的约束条件。接下来,我们固定
满足了问题中的约束条件。接下来,我们固定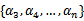 ,这样W就是
,这样W就是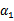 和
和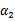 的函数。并且
的函数。并且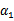 和
和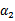 满足条件:
满足条件:
由于  ,所以推到出:
,所以推到出: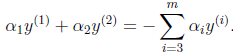
由于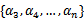 都是已知固定值,因此为了方面,可将等式右边标记成实数值
都是已知固定值,因此为了方面,可将等式右边标记成实数值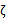 。
。
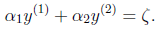
当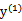 和
和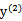 异号时,也就是一个为1,一个为-1时,他们可以表示成一条直线:a1-a2=ζ,相当于x-y=c作图,斜率为1。如下图:
异号时,也就是一个为1,一个为-1时,他们可以表示成一条直线:a1-a2=ζ,相当于x-y=c作图,斜率为1。如下图:
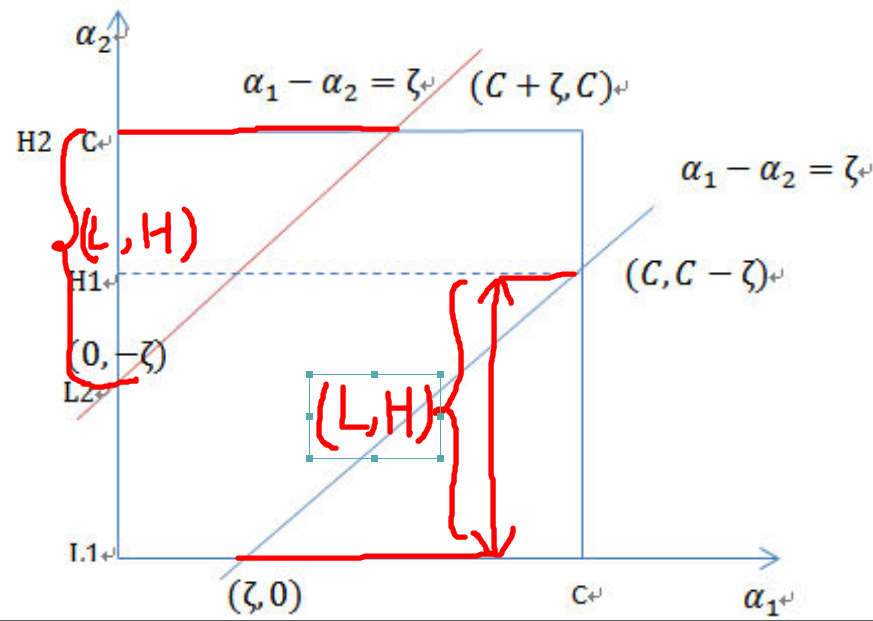
横轴是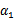 ,纵轴是
,纵轴是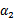 ,
,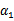 和
和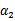 既要在矩形方框内,也要在直线上,因此
既要在矩形方框内,也要在直线上,因此
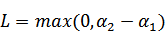 ,
,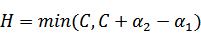
注:这里L、H表示a1给定之后a2的取值范围,从图中可以看到a2取值两种情况,其中{0,C-ζ}属于一条直线、{-ζ,C}属于一条直线,且后者在前者之上,那么:
a2的最小值从{0,-ζ}取最大的值,a2的最大值从{C-ζ,C}取最小的值,因为 ζ = a1 - a2,所以:
同理,当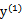 和
和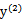 同号时,
同号时,
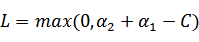 ,
,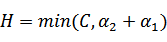
opencv实现SVM
按照以前的性格肯定是用C++把SVM写出来,现在感觉没多大意思,因为很多算法都要自己去实现太难了而且没那么多时间,毕竟现在还用不到SVM,先用opencv自带的例子测试再说。
本文用的opencv3.1实现的非线性分类,看了网上的基本都是2.4或者2.9,要么就是用的线性实现的,弄了很长世间才实现!
其实主要是讲解一些参数的意义和怎么调用:
SVM的类型:
enum Types {
/** C-Support Vector Classification. n-class classification (n \f$\geq\f$ 2), allows
imperfect separation of classes with penalty multiplier C for outliers. */
C_SVC=, //C类支持向量分类机。 n类分组 (n≥2),允许用异常值惩罚因子C进行不完全分类。
/** \f$\nu\f$-Support Vector Classification. n-class classification with possible
imperfect separation. Parameter \f$\nu\f$ (in the range 0..1, the larger the value, the smoother
the decision boundary) is used instead of C. */
NU_SVC=,//  类支持向量分类机。n类似然不完全分类的分类器。参数为取代C(其值在区间【0,1】中,nu越大,决策边界越平滑)。
类支持向量分类机。n类似然不完全分类的分类器。参数为取代C(其值在区间【0,1】中,nu越大,决策边界越平滑)。
/** Distribution Estimation (One-class %SVM). All the training data are from
the same class, %SVM builds a boundary that separates the class from the rest of the feature
space. */
ONE_CLASS=,//单分类器,所有的训练数据提取自同一个类里,然后SVM建立了一个分界线以分割该类在特征空间中所占区域和其它类在特征空间中所占区域。
/** \f$\epsilon\f$-Support Vector Regression. The distance between feature vectors
from the training set and the fitting hyper-plane must be less than p. For outliers the
penalty multiplier C is used. */
EPS_SVR=,//类支持向量回归机。 代替了 p。
/** \f$\nu\f$-Support Vector Regression. \f$\nu\f$ is used instead of p.
See @cite LibSVM for details. */
NU_SVR=
};
核函数:
enum KernelTypes {
/** Returned by SVM::getKernelType in case when custom kernel has been set */
CUSTOM=-,
/** Linear kernel. No mapping is done, linear discrimination (or regression) is
done in the original feature space. It is the fastest option. \f$K(x_i, x_j) = x_i^T x_j\f$. */
LINEAR=,//线性核函数
/** Polynomial kernel:
\f$K(x_i, x_j) = (\gamma x_i^T x_j + coef0)^{degree}, \gamma > 0\f$. */
POLY=,//多项式函数(r*u'v + coef0)^degree
/** Radial basis function (RBF), a good choice in most cases.
\f$K(x_i, x_j) = e^{-\gamma ||x_i - x_j||^2}, \gamma > 0\f$. */
RBF=,//exp(-gamma|u-v|^2)基于径向的函数,对于大多数情况都是一个较好的选择:
/** Sigmoid kernel: \f$K(x_i, x_j) = \tanh(\gamma x_i^T x_j + coef0)\f$. */
SIGMOID=,//tanh(r*u'v + coef0)
/** Exponential Chi2 kernel, similar to the RBF kernel:
\f$K(x_i, x_j) = e^{-\gamma \chi^2(x_i,x_j)}, \chi^2(x_i,x_j) = (x_i-x_j)^2/(x_i+x_j), \gamma > 0\f$. */
CHI2=,
/** Histogram intersection kernel. A fast kernel. \f$K(x_i, x_j) = min(x_i,x_j)\f$. */
INTER=
};
核函数的参数:
成员变量degree针对多项式核函数degree的设置,
gamma针对多项式/rbf/sigmoid核函数的设置,
coef0针对多项式/sigmoid核函数的设置,
Cvalue为损失函数,在C-SVC、e-SVR、v-SVR中有效,
nu设置v-SVC、一类SVM和v-SVR参数,
p为设置e-SVR中损失函数的值,
class_weightsC_SVC的权重,
一些函数的参数:
TermCriteria::TermCriteria(int _type, int _maxCount, double _epsilon)
: type(_type), maxCount(_maxCount), epsilon(_epsilon) {}
//_type:迭代结束的类型,如果为CV_TERMCRIT_ITER,则用最大迭代次数作为终止条件,如果为CV_TERMCRIT_EPS 则用精度作为迭代条件,如果为CV_TERMCRIT_ITER+CV_TERMCRIT_EPS则用最大迭代次数或者精度作为迭代条件,看哪个条件先满足。
//_maxCount:终止程序的最大迭代次数
//_epsilon:终止程序的精度
train( InputArray samples, int layout, InputArray responses );
//samples:输入数据
//layout: 读取数据方式
//----ROW_SAMPLE = 0, //!< 一行为一个样本
//----COL_SAMPLE = 1 //!< 一列为一个样本
//responses:返回的数据(默认为不返回)
上代码:
#include <opencv2/opencv.hpp>
#include <iostream>
#include "math.h" using namespace cv;
using namespace std;
int test = ;
RNG rng();
void drawCross(Mat &img, Point center, Scalar color)
{
int col = center.x > ? center.x : ;
int row = center.y> ? center.y : ;
line(img, Point(col - , row - ), Point(col + , row + ), color);
line(img, Point(col + , row - ), Point(col - , row + ), color);
} void newSvmTest(int rows, int cols, int testCount)
{
assert(testCount >= rows * cols); Mat img = Mat::zeros(rows, cols, CV_8UC3);
Mat testPoint = Mat::zeros(rows, cols, CV_8UC1);
Mat data = Mat::zeros(testCount, , CV_32FC1);
Mat res = Mat::zeros(testCount, , CV_32SC1); //Create random test points
for (int i = ; i < testCount; i++)
{
int row = rng.uniform(,) % rows;
int col = rng.uniform(,) % cols;
//-----存储数据
if (testPoint.at<unsigned char>(row, col) == )
{
testPoint.at<unsigned char>(row, col) = ;
data.at<float>(i, ) = float(col) / cols;
data.at<float>(i, ) = float(row) / rows;
}
else//防止重复
{
i--;
continue;
}
//分成三类
if (row > ( * cos(col * CV_PI / ) + ))
{
drawCross(img, Point(col, row), CV_RGB(, , ));
res.at<unsigned int>(i, ) = ;
}
else
{
if (col > )
{
drawCross(img, Point(col, row), CV_RGB(, , ));
res.at<unsigned int>(i, ) = ;
}
else
{
drawCross(img, Point(col, row), CV_RGB(, , ));
res.at<unsigned int>(i, ) = ;
}
} }
Mat show = img.clone();
//----SVM训练
cv::Ptr<cv::ml::SVM> svm = cv::ml::SVM::create();
svm->setType(cv::ml::SVM::Types::C_SVC);
svm->setKernel(cv::ml::SVM::KernelTypes::RBF);
svm->setDegree();
svm->setGamma();
svm->setCoef0(1.0);
svm->setC();
svm->setNu();
svm->setP(0.1);
svm->setTermCriteria(cv::TermCriteria(cv::TermCriteria::EPS, , FLT_EPSILON));
// train operation
svm->train(data, cv::ml::SampleTypes::ROW_SAMPLE, res);
//----预测数据
for (int i = ; i< rows; i++)
{
for (int j = ; j< cols; j++)
{
Mat m = Mat::zeros(, , CV_32FC1);
m.at<float>(, ) = float(j) / cols;
m.at<float>(, ) = float(i) / rows; float ret = 0.0;
ret = svm->predict(m);
Scalar rcolor; switch ((int)ret)
{
case : rcolor = Scalar(, , ); break;
case : rcolor = Scalar(, , ); break;
case : rcolor = Scalar(, , ); break;
} line(img, Point(j, i), Point(j, i), rcolor);
}
}
//-------获得支持向量
int thickness = ;
int lineType = ;
//Mat sv = svm->getUncompressedSupportVectors();//不能使用,不知道什么原因,网上有的人可以使用
Mat sv = svm->getSupportVectors();
for (int i = ; i < sv.rows; ++i)
{
const float* v = sv.ptr<float>(i);
circle(img, Point((int)(v[]*), (int)(v[]*)), , Scalar(, , ), thickness, lineType);
} imshow("dst", img);
waitKey();
} int main(int argc,char** argv[])
{
newSvmTest(, , );
return ;
}

原图

SVM预测
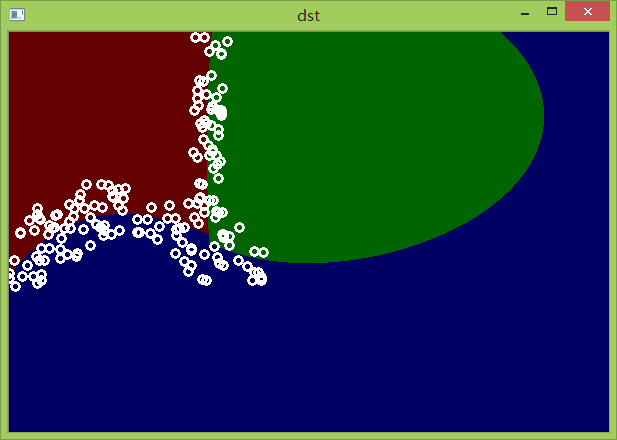
支持向量数据
参考: 百度文库(具体不标注了,都是公式和概念)
《机器学习》周志华老师
https://wenku.baidu.com/view/8f48d70e581b6bd97f19eaaf.html(内积空间)
https://wenku.baidu.com/view/8bee6e76b0717fd5360cdced.html(欧式空间)
http://open.163.com/movie/2013/3/T/0/M8PTB0GHI_M8PTBUHT0.html(网易公开课讲函数空间,讲的非常好!)
http://blog.csdn.net/shijing_0214/article/details/51052208(这篇博客是对上面视频的总结,本来想自己总结的,感觉这篇博文总结的很好,所以自己偷懒不写了)
http://blog.csdn.net/v_july_v/article/details/7624837(看了SMO感觉不错)
http://blog.csdn.net/v_july_v/article/details/7624837(July不用说的大牛,写的非常详细,配合上面的资料就更容易理解)
http://www.pami.sjtu.edu.cn/people/gpliu/document/libsvm_src.pdf(代码解释,还没看)
http://blog.csdn.net/zhazhiqiang/article/details/20146243(很全的opencv实现SVM)
http://blog.csdn.net/firefight/article/details/6400060(程序核心是参考这篇文章,此博客opencv版本太低,很多不适合)
http://blog.csdn.net/changyuanchn/article/details/7540014(opencv SVM参数在这篇文章)
支持向量机(理论+opencv实现)的更多相关文章
- 分水岭算法(理论+opencv实现)
分水岭算法理论 从意思上就知道通过用水来进行分类,学术上说什么基于拓扑结构的形态学...其实就是根据把图像比作一副地貌,然后通过最低点和最高点去分类! 原始的分水岭: 就是上面说的方式,接下来用一幅图 ...
- K-means算法(理论+opencv实现)
写在前面:之前想分类图像的时候有看过k-means算法,当时一知半解的去使用,不懂原理不懂使用规则...显然最后失败了,然后看了<机器学习>这本书对k-means算法有了理论的认识,现在通 ...
- 高斯混合模型(理论+opencv实现)
查资料的时候看了一个不文明的事情,转载别人的东西而不标注出处,结果原创无人知晓,转载很多人评论~~标注了转载而不说出处这样的人有点可耻! 写在前面: Gaussian Mixture Model (G ...
- opencv 支持向量机SVM分类器
支持向量机SVM是从线性可分情况下的最优分类面提出的.所谓最优分类,就是要求分类线不但能够将两类无错误的分开,而且两类之间的分类间隔最大,前者是保证经验风险最小(为0),而通过后面的讨论我们看到,使分 ...
- 支持向量机通俗导论(理解SVM的三层境界)
原文链接:http://blog.csdn.net/v_july_v/article/details/7624837 作者:July.pluskid :致谢:白石.JerryLead 出处:结构之法算 ...
- SVM(支持向量机)与统计机器学习 & 也说一下KNN算法
因为SVM和统计机器学习内容很多,所以从 http://www.cnblogs.com/charlesblc/p/6188562.html 这篇文章里面分出来,单独写. 为什么说SVM和统计学关系很大 ...
- 支持向量机SVM 参数选择
http://ju.outofmemory.cn/entry/119152 http://www.cnblogs.com/zhizhan/p/4412343.html 支持向量机SVM是从线性可分情况 ...
- 支持向量机通俗导论(理解SVM的三层境界)(ZT)
支持向量机通俗导论(理解SVM的三层境界) 原文:http://blog.csdn.net/v_JULY_v/article/details/7624837 作者:July .致谢:pluskid.白 ...
- 支持向量机通俗导论(理解SVM的三层境界)【非原创】
支持向量机通俗导论(理解SVM的三层境界) 作者:July :致谢:pluskid.白石.JerryLead. 出处:结构之法算法之道blog. 前言 动笔写这个支持向量机(support vecto ...
随机推荐
- Unity3D-实现连续点击两次返回键退出游戏(安卓/IOS)
Unity3D-连续点击两次返回键退出游戏 本文提供全流程,中文翻译.Chinar坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) 1 Count ...
- Unity3D游戏-愤怒的小鸟游戏源码和教程(一)
Unity愤怒的小鸟游戏教程 本文提供全流程,中文翻译.Chinar坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) AngryEva游戏效果: 1 ...
- HDU 1232:畅通工程(并查集模板)
畅通工程 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- 大家一起做训练 第一场 G CD
题目来源:UVA 624 题目的意思就是:我现在需要从 t 张CD中拿出一部分来,尽可能的凑出接近 N 这么久的音乐,但是不能超过 N. CD不超过20张,每张长度不超过 N ,不能重复选. 一个很简 ...
- Springboot集成mybatis(mysql),mail,mongodb,cassandra,scheduler,redis,kafka,shiro,websocket
https://blog.csdn.net/a123demi/article/details/78234023 : Springboot集成mybatis(mysql),mail,mongodb,c ...
- HashMap Hashtable LinkedHashMap TreeMap
// Map<String, String> map = new HashMap<String, String>(); // bb aa cc Map<String, S ...
- elasticsearch问题解决之分片副本UNASSIGNED
在上一篇文章中,我记录了在windows下同一台机器上搭建es集群的步骤,第二天在向集群中创建索引的时候,出现了分片副本未分配的情况(UNASSIGNED). 虽然并不影响数据的插入和查询,但是有问题 ...
- python 获取excel文件的所有sheet名字
当一个excel文件的sheet比较多时候, 这时候需要获取所有的sheet的名字. xl = pd.ExcelFile('foo.xls') xl.sheet_names # see all she ...
- ZZ ? ?: 回?做??的十年技?生涯(?文,非??慎入)
元音字母 身份 用户 文章 1409 星座 双子座 积分 14420 等级 灵樨(8) 发信人: fafe (元音字母), 信区: WorkLife 标 题: 回顾做码农的十年技术生涯(长文,非码农 ...
- 【转】解决Win7字体模糊不清晰的最佳办法
原文网址:http://blog.sina.com.cn/s/blog_3d5f68cd0100ldtp.html 相信初次用win7的朋友,都会遇到字体不清晰的问题,有很多人因为这个问题而放弃使用w ...