poj 1330 Nearest Common Ancestors lca 在线rmq
Description
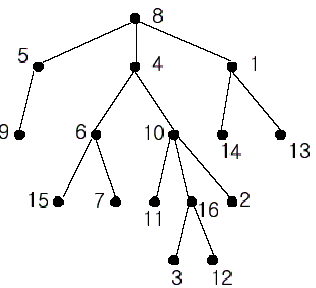
In the figure, each node is labeled with an integer from {1, 2,...,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
Output
Sample Input
2
16
1 14
8 5
10 16
5 9
4 6
8 4
4 10
1 13
6 15
10 11
6 7
10 2
16 3
8 1
16 12
16 7
5
2 3
3 4
3 1
1 5
3 5
Sample Output
4
3
题意:n组数据,y-1条边,最后一个求lca;
博客:http://blog.csdn.net/barry283049/article/details/45842247;我的代码思路根据最后的在线算法得出;
#include<iostream>
#include<cstdio>
#include<cmath>
#include<string>
#include<queue>
#include<algorithm>
#include<stack>
#include<cstring>
#include<vector>
#include<list>
#include<set>
#include<map>
using namespace std;
#define ll long long
#define mod 1000000007
#define inf 999999999
//#pragma comment(linker, "/STACK:102400000,102400000")
int scan()
{
int res = , ch ;
while( !( ( ch = getchar() ) >= '' && ch <= '' ) )
{
if( ch == EOF ) return << ;
}
res = ch - '' ;
while( ( ch = getchar() ) >= '' && ch <= '' )
res = res * + ( ch - '' ) ;
return res ;
}
struct is
{
int u,v;
int next;
}edge[];
int head[];
int deep[];
int rudu[];
int first[];
int dfn[];//存深搜的数组
int dp[][];
int point,jiedge;
int minn(int x,int y)
{
return deep[x]<=deep[y]?x:y;
}
void update(int u,int v)
{
jiedge++;
edge[jiedge].u=u;
edge[jiedge].v=v;
edge[jiedge].next=head[u];
head[u]=jiedge;
}
void dfs(int u,int step)
{
dfn[++point]=u;
deep[point]=step;
if(!first[u])
first[u]=point;
for(int i=head[u];i;i=edge[i].next)
{
int v=edge[i].v;
dfs(v,step+);
dfn[++point]=u;
deep[point]=step;
}
}
void st(int len)
{
for(int i=;i<=len;i++)
dp[i][]=i;
for(int j=;(<<j)<=len;j++)
for(int i=;i+(<<j)-<=len;i++)
{
dp[i][j]=minn(dp[i][j-],dp[i+(<<(j-))][j-]);
}
}
int query(int l,int r)
{
int lll=first[l];
int rr=first[r];
if(lll>rr) swap(lll,rr);
int x=(int)(log((double)(rr-lll+))/log(2.0));
return dfn[minn(dp[lll][x],dp[rr-(<<x)+][x])];
}
int main()
{
int x,y,z,i,t;
scanf("%d",&x);
while(x--)
{
memset(head,,sizeof(head));
memset(rudu,,sizeof(rudu));
memset(first,,sizeof(first));
point=;
jiedge=;
scanf("%d",&y);
for(i=;i<y;i++)
{
int u,v;
scanf("%d%d",&u,&v);
update(u,v);
rudu[v]++;
}
for(i=;i<=y;i++)
if(!rudu[i])
{
dfs(i,);
break;
}
st(point);
int u,v;
scanf("%d%d",&u,&v);
printf("%d\n",query(u,v));
}
return ;
}
poj 1330 Nearest Common Ancestors lca 在线rmq的更多相关文章
- POJ.1330 Nearest Common Ancestors (LCA 倍增)
POJ.1330 Nearest Common Ancestors (LCA 倍增) 题意分析 给出一棵树,树上有n个点(n-1)条边,n-1个父子的边的关系a-b.接下来给出xy,求出xy的lca节 ...
- POJ 1330 Nearest Common Ancestors LCA题解
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 19728 Accept ...
- POJ 1330 Nearest Common Ancestors (LCA,倍增算法,在线算法)
/* *********************************************** Author :kuangbin Created Time :2013-9-5 9:45:17 F ...
- poj 1330 Nearest Common Ancestors LCA
题目链接:http://poj.org/problem?id=1330 A rooted tree is a well-known data structure in computer science ...
- POJ 1330 Nearest Common Ancestors(LCA模板)
给定一棵树求任意两个节点的公共祖先 tarjan离线求LCA思想是,先把所有的查询保存起来,然后dfs一遍树的时候在判断.如果当前节点是要求的两个节点当中的一个,那么再判断另外一个是否已经访问过,如果 ...
- POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA)
POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA) Description A ...
- POJ 1330 Nearest Common Ancestors 倍增算法的LCA
POJ 1330 Nearest Common Ancestors 题意:最近公共祖先的裸题 思路:LCA和ST我们已经很熟悉了,但是这里的f[i][j]却有相似却又不同的含义.f[i][j]表示i节 ...
- POJ - 1330 Nearest Common Ancestors(基础LCA)
POJ - 1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000KB 64bit IO Format: %l ...
- POJ 1330 Nearest Common Ancestors(lca)
POJ 1330 Nearest Common Ancestors A rooted tree is a well-known data structure in computer science a ...
随机推荐
- django的serializers
views.py # get所需的 from snippets.serializers import SnippetSerializer from rest_framework.views impor ...
- [py][mx]django添加后台课程机构页数据-图片上传设置
分析下课程页前台部分 机构类别-目前机构库中没有这个字段,需要追加下 所在地区 xadmin可以手动添加 课程机构 涉及到机构封面图, 即图片上传media设置, 也需要在xadmin里手动添加几条 ...
- python排序函数sort()与sorted()区别
sort是容器的函数:sort(cmp=None, key=None, reverse=False) sorted是python的内建函数:sorted(iterable, cmp=None, key ...
- Centos7 Zabbix3.2集群安装
安装环境:服务器10.80.0.191作为zabbix-server,10.80.0.191-195作为zabbix-agent. [zabbix@miyan ~]$ cat /etc/redhat- ...
- Legal or Not(模板题)
本来以为这题能用并查集做的,但一想不对 例如A-> B,A->C如果用并查集的话B与C就不能连了,但实际B可以是C的徒弟,所以这题是考拓扑排序. #include<stdio.h&g ...
- DW课堂练习 用所学的知识去制作一个 (邮箱的注册页面)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 转载如何实现portlet之间的传递参数
Liferay 6开发学习(三十):跨页面Portlet之间的调用与数据传递 2014年10月09日 Liferay 评论 2 条 阅读 4,209 views 次 Portlet之间的通信方法有多种 ...
- cocos代码研究(2)Label学习笔记
理论部分 Label类继承自Node类,中文翻译文字与字体,通常在应用开发中为模块作为提示和描述的作用,主要有3中不同的创建方式. 1.通过ttf字体包创建,通过指定本地已有的ttf格式的字体文件,创 ...
- zw版【转发·台湾nvp系列Delphi例程】HALCON HistoToThresh2
zw版[转发·台湾nvp系列Delphi例程]HALCON HistoToThresh2 procedure TForm1.Button1Click(Sender: TObject);var imag ...
- 关键词提取自动摘要相关开源项目,自动化seo
关键词提取自动摘要相关开源项目 GitHub - hankcs/HanLP: 自然语言处理 中文分词 词性标注 命名实体识别 依存句法分析 关键词提取 自动摘要 短语提取 拼音 简繁转换https:/ ...