Kafka 及 PyKafka 的使用
1. Kafka
1. 简介
Kafka 是一种分布式的、分区的、多副本的基于发布/订阅的消息系统。它是通过 zookeeper 进行协调,常见可以用于 web/nginx 日志、访问日志、消息服务等。主要应用场景为:日志收集系统和消息系统。
Kafka 的主要设计目标如下:
1. 以时间复杂度为 O(1) 的方式提供持久化能力,即使对 TB 级别以上的数据也能保证常数时间的访问性能。
2. 高吞吐率,即使在十分廉价的机器上也能实现单机支持每秒 100K 条消息的传输。
3. 支持 Kafka Server (即 Kafka 集群的服务器)间的消息分区,及分布式消费,同时保证每个 partition 内的消息顺序传输。
4. 同时支持离线数据处理和实时数据处理
2. Kafka 架构

如上图所示,一个 Kafka 集群由若干producer、若干consumer、若干broker,以及一个zookeeper集群所组成。Kafka通过zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。producer使用push模式将消息发布到broker,consumer使用pull模式从broker订阅并消费消息。
Kafka名词解释:
broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群,相当于物理层面上的一台服务器。
topic:存放同一类消息的位置,是一个概念层面上的名词,Kafka集群可以负责多个topic的分发。(物理上不同topic的消息分开存储,逻辑上一个topic的消息虽然保存于一个或多个broker上但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处)
partition:topic在物理层面上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列,创建topic时可以指定partition数量,每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件。一般来说partition的数量大于等于broker的数量。
producer:负责发布消息到Kafka broker
consumer:消费消息,每个consumer属于一个特定的consumer group(可为每个consumer指定group name,若不指定group name则为默认的group)。使用consumer high level API时,同一topic的一条消息只能被一个consumer group的一个consumer消费,但多个consumer group可同时消费这条消息。
consumer group:每个consumer属于一个特定的consumer group,consumer group是实际记录的概念。
3. Kafka数据传输的事务特点
1. at most once
这种模式下consumer fetch消息,先进行commit,再进行处理。如果再处理消息的过程中出现异常,下次重新开始工作就无法读到之前已经确认而未处理的消息。
2. at least once
消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。消费者fetch消息,然后处理消息,然后保存offset。如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是”at least once”,原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态。
3. exactly once
消息只会发送一次,Kafka中并没有严格的去实现,我们认为这种策略在Kafka中是没有必要的。
通常情况下,Kafka默认保证at least once。
5. Push & Pull
作为一个消息系统,Kafka遵循了传统的方式,选择由producer向broker push消息,并由consumer从broker中pull消息。
push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标就是以尽可能快的速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现是拒绝服务以及网络拥塞。而pull模式可以根据consumer的消费能力以适当的速率消费消息。
6. Topic & Partition
Topic在逻辑上可以认为是一个存在的queue,每条消息都必须指定它的topic,可以简单的理解为必须指明把这条消息放进哪个queue里。为了使Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件。

每个日志文件都是"log entries"序列,每一个log entry包含一个4字节整型值(值为N),其后跟N个字节的消息体。每条消息都有一个当前partition下唯一的64字节的offset,它指明了这条消息的起始位置,也是对数据的唯一标识,Kafka中并没有提供额外的索引机制来存储offset,因为在Kafka中几乎不允许对消息进行"随机读写"。磁盘上log entry的存储格式如下:
message length:4 bytes(它的具体值为1+4+n,如下所示)
"magic" value:1 byte
crc:4 bytes
payload:n bytes
这个log entries并非由一个文件构成,而是分为多个segment,每个segment名为该segment第一条消息的offset和".kafka"组成。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围。
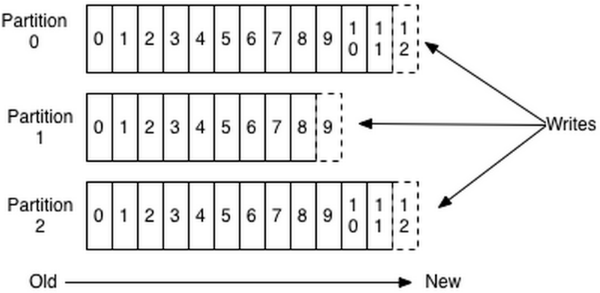
因为每条消息都被append到该partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘比随机写内存还要高,这是Kafka高吞吐率的一个保证)。
每条消息被发送到topic时,会根据指定的partition规则选择被存储到哪一个partition。如果partition规则设计的合理,所有的消息会均匀分配到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而partition解决了这个问题)。在创建topic时,可以在$KAFKA_HOME/config/server.properties中指定这个partition的数量(如下所示),当然也可以在topic创建之后去修改parition数量。
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=3
在发送一条消息时,可以指定这条消息的key,producer根据这个key和partition机制来判断这个将这条消息发送到哪个partition。paritition机制可以通过指定producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。(比如如果一个key能够被解析为整数,那么将对应的整数与partition总数取余,可以作为该消息被发送到的partition id)
7. 历史数据删除机制
对于传统的message queue而言,一般会删除已经消费过的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,由于磁盘限制,不可能永久保留,因此Kafka提供两种机制去删除旧数据。一是基于时间,一是基于partition文件大小。(例如可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可通过配置让Kafka在partition文件超过1GB时删除旧数据)
这里要注意,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除文件与Kafka性能无关,选择怎样的删除策略只与磁盘以及具体的需求有关。另外,Kafka会为每一个consumer group保留一些metadata信息—当前消费的消息的position,也即offset。这个offset由consumer控制。正常情况下consumer会在消费完一条消息后线性增加这个offset。当然,consumer也可将offset设成一个较小的值,重新消费一些消息。因为offet由consumer控制,所以Kafka broker是无状态的,它不需要标记哪些消息被哪些consumer过,不需要通过broker去保证同一个consumer group只有一个consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。
8. Consumer Group
对于程序员来说,consumer group 是消费 Kafka 消息队列中消息的接口,每个 consumer group 可以消费多个 topic,对于每一个 topic 可以有多个消费者实体 consumer(对应多个程序或者进程)。在消费过程中,同一个 topic 中的消息只会被同一个 consumer group 中的一个 consumer 消费,而不会出现重复订阅的情况。对于每一个 consumer group 消费 topic,可以手动commit,也可以设置参数集群自动commit(确认)消费进行的位置,保证下一次能接着从上次的位置继续消费。
consumer group 和 topic 一样,也是直接使用就能新建的。如果直接新建一个 consumer,而不指定具体的 consumer group,系统会自动的指定默认的 consumer group,并且从最老的数据(EARLIEST)位置开始消费。
详情参考:
http://developer.51cto.com/art/201501/464491.htm
http://geek.csdn.net/news/detail/229569
http://www.cnblogs.com/likehua/p/3999538.html
2. PyKafka 的使用
1. 导入 pykafka 模块
import pykafka
from pykafka import KafkaClient
2. 初始化 KafkaClient
client = KafkaClient(hosts="127.0.0.1:9092,127.0.0.1:9093,...") 可以通过 hosts 地址初始化,也可以使用 zookeeper_hosts 进行初始化:
client = KafkaClient(zookeeper_hosts = 'yq01-ps-4-m42-pc177.yq01:2181,yq01-ps-4-m42-pc186.yq01:2181,yq01-ps-4-m42-pc187.yq01:2181,yq01-ps-4-m42-pc191.yq01:2181,yq01-ps-4-m42-pc192.yq01:2181')
3. Topic 对象
client.topics 可以查看当前所有的 topic。
topic = client.topics['bjhapp_history'] #如果该 topic 存在,那么会选中对应的 topic;如果不存在,会自动新建该 topic。
Topic 对象包含的方法:
1. get_balanced_consumer(consumer_group, managed=False, **kwargs) :生成对应 consumer_group 对 topic 下消息消费的一个 balanced_consumer,与 simple_consumer 的差别在于如果有多个 consumer 进来对同一个 topic 的消息进行订阅,balanced_consumer 会自动平衡和分配 partitions 给每个 consumer;而先进来的 simple_consumer 会对当前 topic 的partition 有100%的占有权。
参数:consumer_group:消费的 consumer_group 名
managed:是否对 consumer_group 进行管理
**kwargs:对应于 consumer 对象的众多参数
2. get_producer(use_rdkafka=False, **kwargs):生成对应 topic 的一个异步消息 producer
3. get_simple_consumer(consumer_group=None, use_rdkafka=False, **kwargs):生成对应 consumer_group 对 topic 的一个 simple_consumer
4. get_sync_producer(**kwargs):生成对 topic 的一个同步 producer
成员变量:
name:topic 的名字
partitions:包含当前 topic 对应 partitions 的字典
4. Producer 对象
1. 同步的 producer 对象
producer = topic.get_sync_producer()
producer.produce("test")
同步的 producer 对象发布消息时,只有在确认消息成功发送到集群时才返回,因此网络 IO 的速度会影响程序的整体速度。
2. 异步的 producer 对象
为了实现更高的吞吐量,我们推荐使用异步模式的 producer,这样 produce() 函数能够立即返回,并且可以批量处理更多的消息,而不用等待当前消息发布成功的确认。我们通过队列的接口同样可以在之后收到消息发布成功的确认,需要设置参数 delivery_reports = True。
producer = topic.get_producer(delivery_reports=True) #初始化异步的 producer
count = 0 #定义 count 变量用来存储消息发送的条数,以便于定期检查之前的消息是否发送成功
def produce(msg, partition_key):
global count
producer.produce(msg, partition_key = partition_key)
count += 1
if count % 10 == 0:
while True:
try:
old_msg, exc = producer.get_delivery_report(block = False)
if exc is not None:
log.warn("fail to delivery msg: %s, exc: %s, try again", \
old_msg.partition_key, exc)
if type(exc) is not MessageSizeTooLarge:
producer.produce(old_msg.value, partition_key = old_msg.partition_key)
else:
log.info("succ delivery msg: %s", old_msg.partition_key)
except Queue.Empty:
break;
上述代码每尝试发布十条消息,就对之前发送的消息的 delivery_report 进行检查,查看其发布是否成功的状态,通过 producer.get_delivery_report() 函数返回之前发送失败的消息和结果,如果没有发布成功,会尝试重新进行发送。直到 delivery_report 的队列为空。
要注意 producer 发布消息时是先将消息存储在缓存区,再将缓存区的消息发布到 Kafka 集群。所以异步的 produce() 函数执行完后,依然需要一定的时间来实现消息从缓存区的发布。所以如果文件执行结束,producer 对象会自动释放,导致消息发布不成功,返回错误:ReferenceError: weakly-referenced object no longer exists。解决方法,在程序的尾部让程序等待一段时间使消息发布完成,例如:sleep(6)
5. Consumer 对象
当一个 PyKafka consumer 开始从一个 topic 中订阅消息时,它在记录器中的起始位置是由 auto_offset_reset 和 reset_offset_on_start 两个参数确定的。
consumer = topic.get_simple_consumer(
consumer_group = 'my_group',
auto_offset_reset = OffsetType.EARLIEST,
reset_offset_on_start=False
)
同样,是否 Kafka 集群保有任何之前的 consumer group/topic/partition set 的消费偏移量也会影响数据的初始订阅点。一个 new group/topic/partition set 就是之前没有任何 commited offsets,一个存在的就是有 commited offsets 的。这两者的订阅点由下面的规则决定:
1. 对于一个新的 consumer group/topic/partitions,不管参数 reset_offset_on_start 的参数是什么,都会从 auto_offset_reset 指定的位置开始消息订阅。
2. 对于一个已经存在的 consumer group/topic/partitions,假设参数 reset_offset_on_start 为false,那么消费会从上一次消费的偏移量之后开始进行(比如上一次的消费偏移量为4,那么消费会从5开始)。假设参数为 true,会自动从 auto_offset_reset 指定的位置开始消费。
Tips:
1. No handlers could be found for logger "pykafka.simpleconsumer"
错误的原因是 consumer 在订阅消息时需要有一个 logger 来记录日志,如果有一个全局 logger 对象,会自动的写入该全局对象中,否则会报这条信息,但是不影响消息订阅。
2. 有的时候会出现 consumer 在订阅消息时迟迟不能读出现的情况,这是由于 KafkaClient 的未知原因导致的,可以尝试在初始化 consumer 的参数中加上 consumer_timeout_ms 参数来解决问题。该参数表示 consumer 在返回 None 前尝试等待可以消费的消息的时间。
Kafka 及 PyKafka 的使用的更多相关文章
- Python 基于pykafka简单实现KAFKA消费者
基于pykafka简单实现KAFKA消费者 By: 授客 QQ:1033553122 1.测试环境 python 3.4 zookeeper-3.4.13.tar.gz 下载地址1 ...
- Python 基于Python结合pykafka实现kafka生产及消费速率&主题分区偏移实时监控
基于Python结合pykafka实现kafka生产及消费速率&主题分区偏移实时监控 By: 授客 QQ:1033553122 1.测试环境 python 3.4 zookeeper- ...
- Python测试Kafka集群(pykafka)
生产者代码: # -* coding:utf8 *- from pykafka import KafkaClient host = 'IP:9092, IP:9092, IP:9092' client ...
- 使用spark-streaming实时读取Kafka数据统计结果存入MySQL
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- 使用生成器把Kafka写入速度提高1000倍
title: 使用生成器把Kafka写入速度提高1000倍 toc: true comment: true date: 2018-04-13 21:35:09 tags: ['Python', '经验 ...
- python kafka权限校验client.id
kafka集群有权限校验,在连接时需要加入client.id.但pykafka不能配置该选项.搜索了一下,需要使用confluent-kafka 链接: https://blog.csdn.net/l ...
- spark-streaming集成Kafka处理实时数据
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- 【kafka】生产者速度测试
非常有用的参考博客:http://blog.csdn.net/qq_33160722/article/details/52903380 pykafka文档:http://pykafka.readthe ...
- 【kafka】celery与kafka的联用问题
背景:一个小应用,用celery下发任务,任务内容为kafka生产一些数据. 问题:使用confluent_kafka模块时,单独启用kafka可以正常生产消息,但是套上celery后,kafka就无 ...
随机推荐
- 008-插件方式启动web服务tomcat,jetty
一.pom引入 1.tomcat7 <!-- tomcat7 --> <plugin> <groupId>org.apache.tomcat.maven</g ...
- 十天精通CSS3(3)
颜色之RGBA RGB是一种色彩标准,是由红(R).绿(G).蓝(B)的变化以及相互叠加来得到各式各样的颜色.RGBA是在RGB的基础上增加了控制alpha透明度的参数. 语法: color:rgba ...
- 使用Python2.7 POST 数据到 onenet 平台
功能 发送数据名称为SENSORID(这里用TEST测试),数值为VALUE(这里用49值做测试)的数据,发送到自己的onenet对应设备 效果发送成功 代码 # -*- coding: utf-8 ...
- [lr] 常用快捷键
界面基本操作 F5 : 隐藏/显示上部面板 F6 : 隐藏/显示下部面板 F7 : 隐藏/显示左部面板 F8 ...
- 关于DOM2级事件的事件捕获和事件冒泡
DOM2级事件中addEventListener的执行机制,多个addEventListener同时添加时的执行先后规律: W3C的DOM事件触发分为三个阶段:①.事件捕获阶段,即由最顶层元素(一般是 ...
- Codeforces 1146E Hot is Cold
题意: 给出一个序列,有两种操作: \(>\;x\) 将大于\(x\)的数全都取负 \(<\;x\) 将小于\(x\)的数全都取负 最后输出序列中的所有数最后的状态 思路: 我们先考虑对于 ...
- BP神经网络原理详解
转自博客园@编程De: http://www.cnblogs.com/jzhlin/archive/2012/07/28/bp.html http://blog.sina.com.cn/s/blog ...
- Linux服务器---配置apache支持用户认证
Apache支持用户认证 为了服务器的安全,通常用户在请求访问某个文件夹的时候,Apache可以要求用户输入有效的用户名和登录密码 1.创建一个测试目录 [root@localhost cgi-bin ...
- C/C++之static函数与普通函数
全局变量(外部变量)的说明之前再冠以static 就构成了静态的全局变量.全局变量本身就是静态存储方式, 静态全局变量当然也是静态存储方式.这两者在存储方式上并无不同.这两者的区别虽在于非静态全局变量 ...
- corejDay1
1.内部类: 有什么用? 1.可以访问该类定义所在作用域中的数据,包括私有数据. 2.当想定义一个回调函数而不想编写大量代码时,使用匿名内部类比较便捷. 3.内部类可以对同一个包中的其他类隐藏起来. ...