深度强化学习——连续动作控制DDPG、NAF
一、存在的问题
DQN是一个面向离散控制的算法,即输出的动作是离散的。对应到Atari 游戏中,只需要几个离散的键盘或手柄按键进行控制。
然而在实际中,控制问题则是连续的,高维的,比如一个具有6个关节的机械臂,每个关节的角度输出是连续值,假设范围是0°~360°,归一化后为(-1,1)。若把每个关节角取值范围离散化,比如精度到0.01,则一个关节有200个取值,那么6个关节共有20062006个取值,若进一步提升这个精度,取值的数量将成倍增加,而且动作的数量将随着自由度的增加呈指数型增长。所以根本无法用传统的DQN方法解决。
解决方法
使用Policy-Based方法,通过各种策略梯度方法直接优化用深度神经网络参数化表示的策略,即网络的输出就是动作。
二、DDPG
深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)算法是Lillicrap 等人利用 DQN 扩展 Q 学习算法的思路对确定性策略梯度(Deterministic Policy Gradient, DPG)方法进行改造,提出的一种基于行动者-评论家(Actor-Critic,AC)框架的算法,该算法可用于解决连续动作空间上的 DRL 问题。
随机性策略和确定性策略:
- 随机性策略,策略输出的是动作的概率,比如上一篇A3C博客提到的连续动作控制,使用的是一个正态分布对动作进行采样选择,即每个动作都有概率被选到;优点,将探索和改进集成到一个策略中;缺点,需要大量训练数据。
- 确定性策略,策略输出即是动作;优点,需要采样的数据少,算法效率高;缺点,无法探索环境。
在真实场景下机器人的操控任务中,在线收集并利用大量训练数据会产生十分昂贵的代价, 并且动作连续的特性使得在线抽取批量轨迹的方式无法达到令人满意的覆盖面, 这些问题会导致局部最优解的出现。
然而使用确定性策略无法探索环境,如何解决?
利用off-policy学习方法。off-policy是指采样的策略和改进的策略不是同一个策略。类似于DQN,使用随机策略产生样本存放到经验回放机制中,训练时随机抽取样本,改进的是当前的确定性策略。整个确定性策略的学习框架采用AC的方法。
DDPG公式
在DDPG中,分别使用参数为 θμθμ 和 θQθQ 的深度神经网络来表示确定性策略 a=π(s|θμ)a=π(s|θμ) 和动作值函数 Q(s,a|θQ)Q(s,a|θQ)。其中,策略网络用来更新策略,对应 AC 框架中的行动者;值网络用来逼近状态动作对的值函数, 并提供梯度信息, 对应 AC 框架中的评论家。目标函数被定义为带折扣的总回报:
通过随机梯度法对目标函数进行端对端的优化(注意,目标是提高总回报 JJ)。Silver等人证明了目标函数关于 θμθμ 的梯度等价于Q值函数关于 θμθμ 的期望梯度:
根据确定性策略 a=π(s|θμ)a=π(s|θμ) 可得:
沿着提升 Q 值的方向更新策略网络的参数。
通过 DQN中更新值网络的方法来更新评论家网络,梯度信息为:
其中 θμ′θμ′ 和 θQ′θQ′ 分别表示目标策略网络和目标值网络的参数,用梯度下降方式更新值网络。
算法伪代码

区别于DQN,DQN每隔一定的迭代次数后,将MainNet参数复制给TargetNet;而DDPG中TargetNet的参数每次迭代都以微小量逼近MainNet的参数。
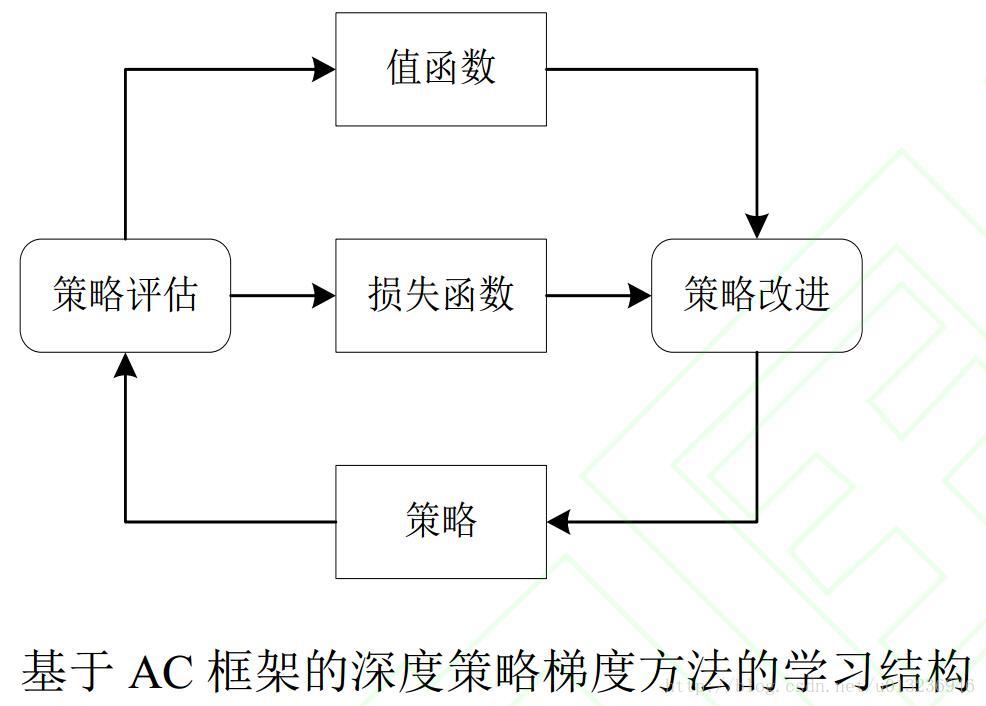
网络训练流程图
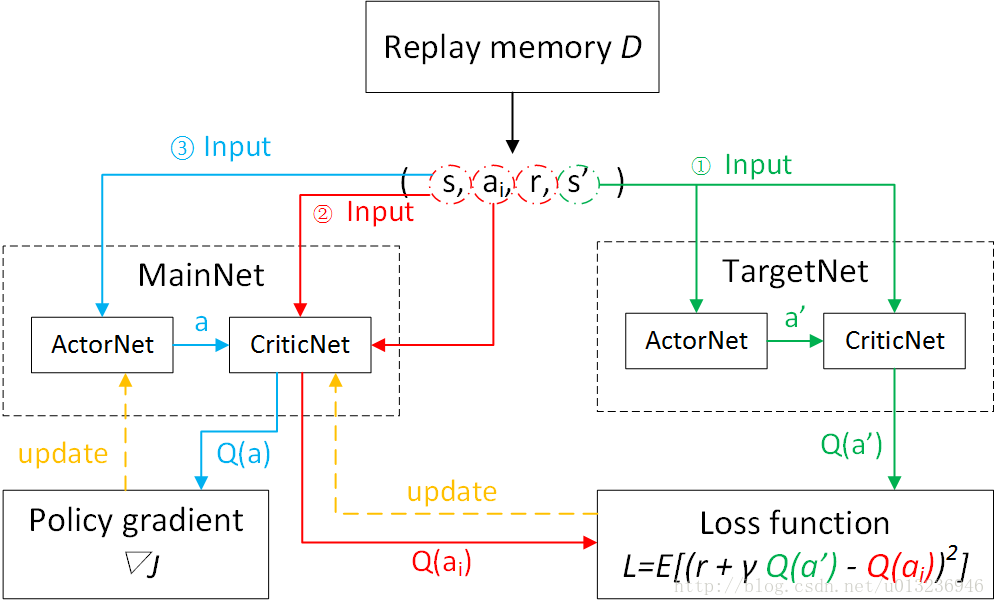
实验表明, DDPG 不仅在一系列连续动作空间的任务中表现稳定,而且求得最优解所需要的时间步也远远少于 DQN。与基于值函数的 DRL 方法相比, 基于 AC 框架的深度策略梯度方法优化策略效率更高、 求解速度更快。
DDPG缺点:
不适用于随机环境的场景
三、NAF
Shixiang等人的论文中共有两个算法,第一个是NAF,第二个是基于模型(Model-based)加速的NAF。这里只介绍简单的NAF。
DDPG的问题:
需要训练两个网络即策略网络和值网络
解决方法
归一化优势函数(normalized advantage functions ,NAF)只需要训练一个网络。
NAF公式:
NAF的目的之一是要将深度神经网络Q-Learning应用于连续动作空间,而要用Q-Learing进行训练必须要知道目标Q值(TargetQ)。
和前面博客Dueling-DDQN介绍的dueling net思想类似,动作值函数可以表示为状态值函数 VV 与动作价值函数 AA 的和,即
其中 xx 表示状态State,uu 表示动作Action,θθ 是对应的网络参数,A(x,u|θA)A(x,u|θA) 可以看成动作 uu 在状态 xx 下的优势。我们的目的就是要使策略网络输出的动作 uu 所对应的Q值最大。
如果能使 ∀x,uA(x,u|θA)⩽0∀x,uA(x,u|θA)⩽0,则 ∀x,uQ(x,u|θQ)⩽V(x|θV)∀x,uQ(x,u|θQ)⩽V(x|θV)。在状态 xx 下最优的动作 uu 的动作优势函数 A(x,u|θA)=0A(x,u|θA)=0,所以对应最优动作的值函数Q(x,u|θQ)=V(x|θV)Q(x,u|θQ)=V(x|θV),这样就很容易构造出TargetQ值了。具体的做法是令
P(x|θP)P(x|θP)是一个关于状态的正定矩阵,因为正定矩阵可以进行楚列斯基(Cholesky)分解,即
L(x|θP)L(x|θP)是对角线都是正数的下三角矩阵,且是唯一的。
最终算法的Loss Function为
使用DQN的训练方式训练。
算法伪代码

网络训练流程图
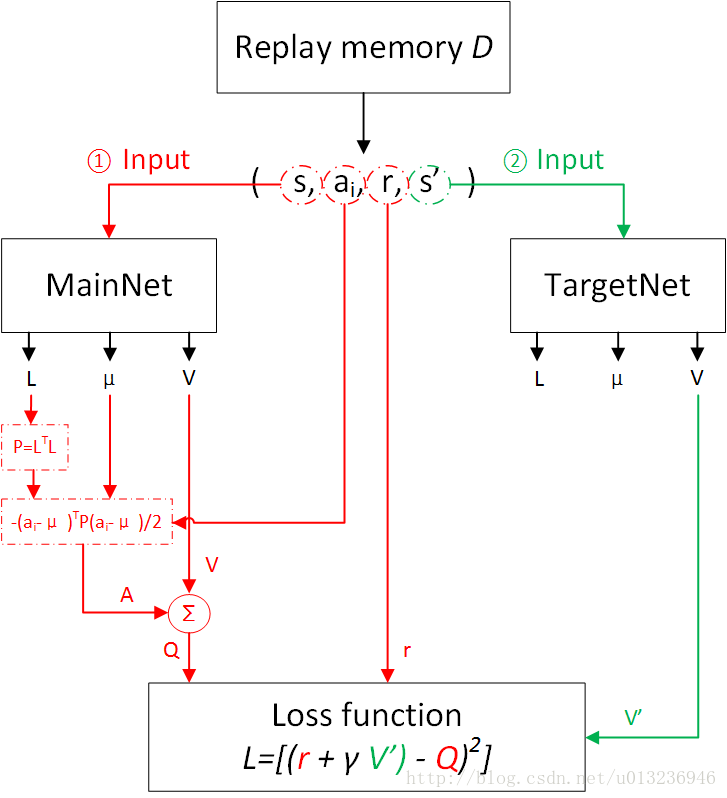
网络输出的是下三角矩阵LL,动作 uu,状态值函数 VV
异步NAF训练机械臂
Shixiang等人还使用了异步NAF训练机械臂开门。

该算法具有一个训练线程(trainer thread)和多个收集样本线程(collector thread),collector thread将收集到的样本存于经验回放机制中,供trainer thread训练。
这个异步NAF算法和A3C算法的不同之处在于:
异步NAF是off-policy,collector thread不提供梯度信息;
A3C是on-policy,每个线程agent都提供梯度信息。
参考文献
[1]Continuous control with deep reinforcement learning
[2]Continuous Deep Q-Learning with Model-based Acceleration
[3]Deterministic Policy Gradient Algorithm
[4]Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates
[5]深度强化学习综述_刘全等
深度强化学习——连续动作控制DDPG、NAF的更多相关文章
- 5G网络的深度强化学习:联合波束成形,功率控制和干扰协调
摘要:第五代无线通信(5G)支持大幅增加流量和数据速率,并提高语音呼叫的可靠性.在5G无线网络中共同优化波束成形,功率控制和干扰协调以增强最终用户的通信性能是一项重大挑战.在本文中,我们制定波束形成, ...
- 基于TORCS和Torch7实现端到端连续动作自动驾驶深度强化学习模型(A3C)的训练
基于TORCS(C++)和Torch7(lua)实现自动驾驶端到端深度强化学习模型(A3C-连续动作)的训练 先占坑,后续内容有空慢慢往里填 训练系统框架 先占坑,后续内容有空慢慢往里填 训练系统核心 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 用深度强化学习玩FlappyBird
摘要:学习玩游戏一直是当今AI研究的热门话题之一.使用博弈论/搜索算法来解决这些问题需要特别地进行周密的特性定义,使得其扩展性不强.使用深度学习算法训练的卷积神经网络模型(CNN)自提出以来在图像处理 ...
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
随机推荐
- 基于TextRank提取关键词、关键短语、摘要
一.TextRank原理 TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要.因为TextRank是基于PageRank的,所以首先简要介绍下PageRank算法. 1. Pa ...
- spark 与 Hadoop 融合后启动 slf4j提示Class path contains multiple SLF4J bindings
相关参考文献: https://www.oschina.net/question/93435_174549 警告信息如下: 看起来明明就是一个文件,怎么还提示multiple bindings呢,sl ...
- Visual Studio 2017 以前的旧格式的 csproj Import 进来的 targets 文件有时不能正确计算属性(PropertyGroup)和集合(ItemGroup)
我在之前的博客中有教大家如何编写 NuGet 工具包,其中就有编写 .targets 文件. 我在实际的使用中,发现 Visual Studio 2017 带来的含 Sdk 的新 csproj 格式基 ...
- utf-8编码的csv文件,用excel打开乱码,解决办法,在输出前加 0xEF,0xBB,0xBF三个char
转自 http://blog.csdn.net/zcmssd/article/details/6086649 是由于输出的CSV文件中没有BOM. 什么是BOM? 在UCS 编码中有一个叫做”ZERO ...
- 【java编程】正确重写hashCode和equesl方案
一. 正确书写hashCode的办法: [原则]按照equals( )中比较两个对象是否一致的条件用到的属性来重写hashCode(). {1}. 常用的办法就是利用涉及到的的属性进行线性组合. {2 ...
- C语言运算符优先级和ASCII表
1. C语言运算符优先级及结合性 优先级 运算符 名称或含义 使用形式 结合方向 说明 1 [] 数组下标 数组名[常量表达式] 左到右 -- () 圆括号 (表达式)/函数名(形参表) -- . 成 ...
- FastAdmin 教程草稿大纲
FastAdmin 教程草稿大纲 计划 FastAdmin 教程大纲 FastAdmin 环境搭建 phpStudy 2018 安装 一键 CRUD 教程 环境变量配置 环境安装 命令行安装 列出所需 ...
- Maven的dependency type属性
官方地址: http://maven.apache.org/ref/3.5.2/maven-model/maven.html (搜索:Some examples are jar, war, ejb-c ...
- sqlserver 同义名的使用
USE [ccflow5]GOdrop synonym ccusergo/****** Object: Synonym [dbo].[ccuser] Script Date: 11/12/20 ...
- 【shell】awk命令
简介 awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再 ...