scrapy-splash抓取动态数据例子六
一、介绍
本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息。
给定关键字:打通;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
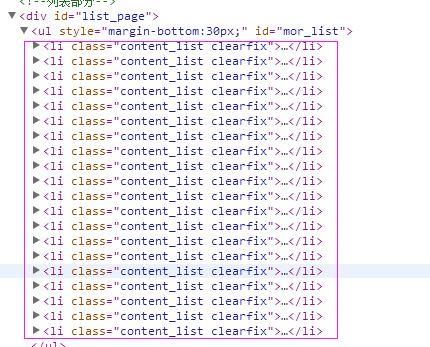

三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:sels = site.xpath('//li[@class="content_list clearfix"]')
2、抓取标题
首先列表页面,根据标题和日期来判断是否自己需要的资讯,如果是,就今日到资讯对应的链接,来抓取来源,如果不是,就不用抓取了
抓取代码:titles = sel.xpath('.//div[@class="content_listtext"]/a/h3/text()')
3、抓取链接
抓取代码:url = 'http://www.tvoao.com' + str(sel.xpath('.//a/@href')[0].extract())
4、抓取日期
抓取代码:strdates = sel.xpath('.//div[@class="listtext_label"]/span/text()')
5、抓取来源
抓取代码:sources = site.xpath('//div[@class="headlines_source"]/span[2]/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from splash_test.items import SplashTestItem
import IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') sys.stdout = open('output.txt', 'w') class tvoaoSpider(Spider):
name = 'tvoao' configfile = os.path.join(os.getcwd(), 'splash_test\spiders\setting.conf') cf = IniFile.ConfigFile(configfile)
information_wordlist = cf.GetValue("section", "information_keywords").split(';')
websearch_urls = cf.GetValue("tvoao", "websearchurl").split(';')
start_urls = []
for url in websearch_urls:
start_urls.append(url) # request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url
, self.parse
, args={'wait': ''}
)
def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 四种格式 '2小时前'; '2天前' ; '昨天' ;'2017.2.12 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{2}-\d{2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate, strDate[0]) == 0:
return True, currentDate
return False, '' def parse(self, response):
site = Selector(response)
sels = site.xpath('//li[@class="content_list clearfix"]')
for sel in sels:
strdates = sel.xpath('.//div[@class="listtext_label"]/span/text()') if len(strdates)>0:
flag, date = self.date_isValid(str(strdates[0].extract()))
if flag:
titles = sel.xpath('.//div[@class="content_listtext"]/a/h3/text()')
if len(titles) > 0:
title = str(titles[0].extract()) url = 'http://www.tvoao.com' + str(sel.xpath('.//a/@href')[0].extract())
for keyword in self.information_wordlist:
if title.find(keyword) > -1:
yield SplashRequest(url
, self.parse_item
, args={'wait': ''},
meta={'date': date, 'url': url,
'keyword': keyword, 'title': title}
) def parse_item(self, response):
site = Selector(response)
it = SplashTestItem()
it['title'] = response.meta['title']
it['url'] = response.meta['url']
it['date'] = response.meta['date']
it['keyword'] = response.meta['keyword']
sources = site.xpath('//div[@class="headlines_source"]/span[2]/text()')
if len(sources)>0:
it['source'] = str(sources[0].extract()).replace(u'来源: ', '')
return it
scrapy-splash抓取动态数据例子六的更多相关文章
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子四
一.介绍 本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十五
一.介绍 本例子用scrapy-splash爬取电视之家(http://www.tvhome.com/news/)网站的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电视 抓取信 ...
随机推荐
- Edit Distance——经典的动态规划问题
题目描述Edit DistanceGiven two words word1 and word2, find the minimum number of steps required to conve ...
- Graph Cut
转自:http://blog.csdn.net/zouxy09/article/details/8532111 Graph Cut,下一个博文我们再学习下Grab Cut,两者都是基于图论的分割方法. ...
- BootStrap 实现导航栏nav透明,nav子元素文字不透明
在给nav 的属性赋值 opacity:0.0透明度时会导致nav内子元素会继承opacity属性.此时再对子元素赋值opacity:1.0 时会导致 子元素实际opacity值为0.0*1.0=0. ...
- PHP数组转对象,对象转数组
废话不多,直接上代码: <?php class object_array{ //数组转对象 public static function array_to_object($e){ if(gett ...
- 前端组件化-Web Components【转】
以下全部转自:http://www.cnblogs.com/pqjwyn/p/7401918.html 前端组件化的痛点在前端组件化横行的今天,确实极大的提升了开发效率.不过有一个问题不得不被重视,拟 ...
- 解决Django在mariadb创建的表插入中文乱码的问题
1.确保你的mariadb数据库的character_set_connection.character_set_database.character_set_server的编码均为utf8 Maria ...
- 搭建openstack系统初始化(2)
操作系统环境 :Centos 7.3 x64 1).安装需要的包 yum install wget vim chrony net-tools bash-completion -y 2)配置阿里elpl ...
- SpringMVC完成文件上传的基本步骤
1.修改form表单的提交方式 2.将文件存入磁盘 3.配置视图解析器 1).前端文件 --需要在form表单中添加 enctype="multipart/form-data"属性 ...
- 洛谷——P1208 [USACO1.3]混合牛奶 Mixing Milk
P1208 [USACO1.3]混合牛奶 Mixing Milk 题目描述 由于乳制品产业利润很低,所以降低原材料(牛奶)价格就变得十分重要.帮助Marry乳业找到最优的牛奶采购方案. Marry乳业 ...
- 使用html+css实现三角标示符号
我们平常打开某个网站的时候,常常会发现网页上很多导航或者指示条会使用一个三角符号去指向内容,效果简洁美观,甚至很多前端面试中也会提及如何在网页上实现一个三角符号,这里给出一个很简单使用的实现方式. 首 ...