主存和cache的地址映射
cache是一种高速缓冲寄存器,是为解决CPU和主存之间速度不匹配而采用的一项重要技术。
主存与cache的地址映射方式有全相联方式、直接方式和组相联方式三种。
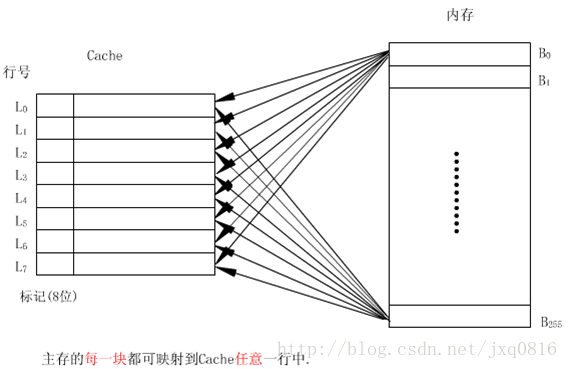
直接映射(directmapping):将一个主存块存储到唯一的一个Cache行。
全相联映射(fullyassociative mapping):可以将一个主存块存储到任意一个Cache行。
组相联映射(setassociative mapping):可以将一个主存块存储到唯一的一个Cache组中任意一个行。
1.直接映射
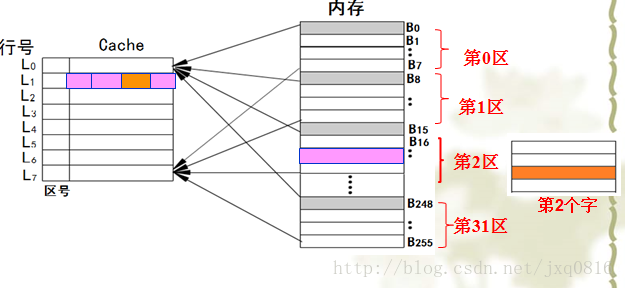
直接映射的cache检索过程
在直接映射方式中,首先用r位行号找到cache中的对应行,然后用地址中的s-r位标记部分与此行的标记在比较器中做比较。若符合命中,在cache中找到了对应的块,然后用地址中最低位w读取所需的字。若未命中,按内存地址从主存中读取这个字。
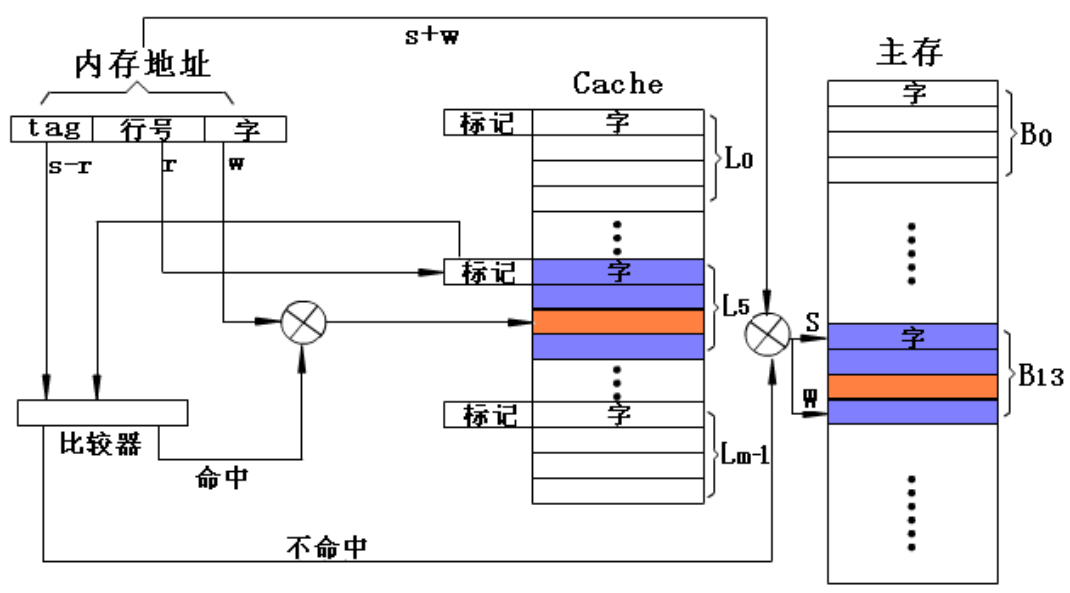
2.全相联映射
全相联映射方式检索过程
在全相联映射方式中,将内存地址的s位块号与cache中所有行的标记同时在比较器中做比较。若块号命中,按w位字地址从cache中读取一个字;若未命中,则按内存地址从主存中读取这个字。
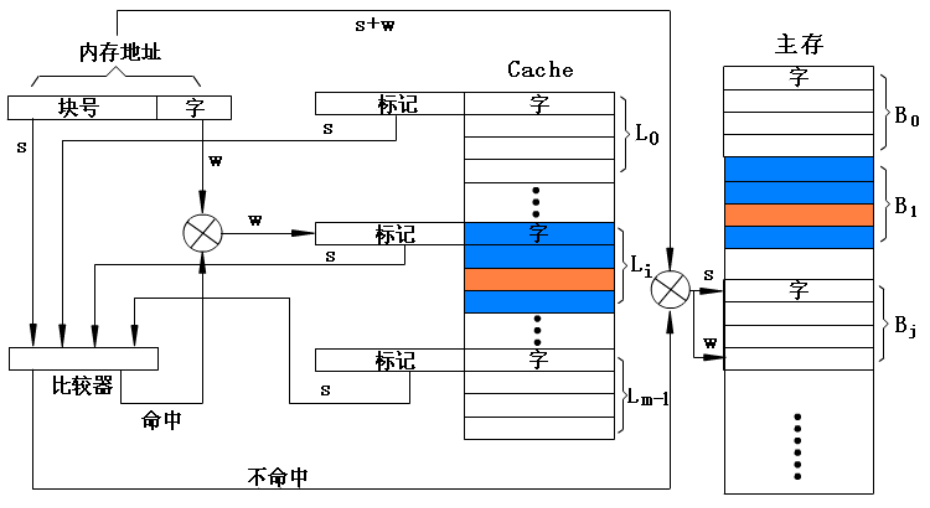
3.组相联映射
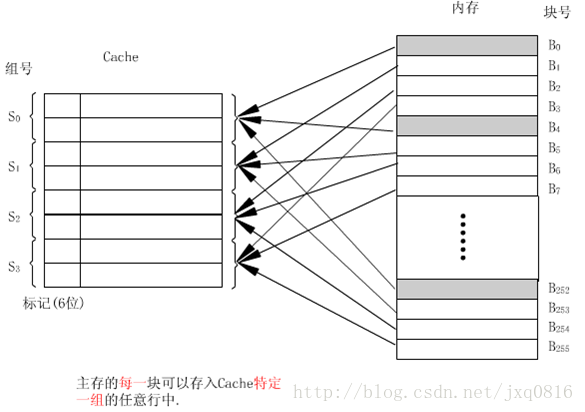
组相联cache的检索过程
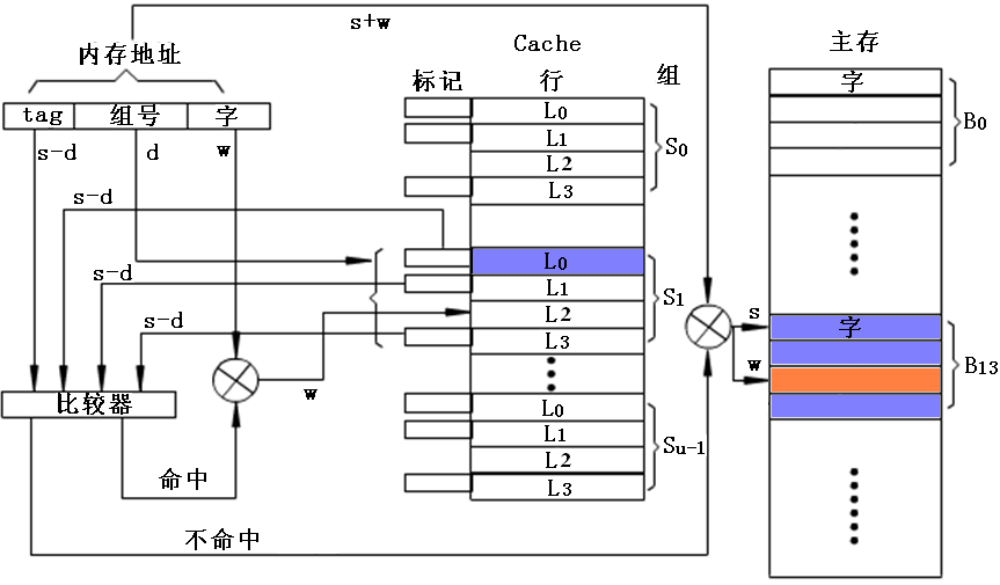
在组相联映射方式中,首先用给定s位块号的低d位找到cache的相应组,然后将块号的高s-d位与该组v(=2d)行中的所有标记同时比较,哪一行的标记相符即该行命中。再以内存地址的低w位检索此行对应的字。
主存和cache的地址映射的更多相关文章
- 主存与Cache的地址映射
最近在复习计算机体系结构,选用的教材是名闻遐迩的<计算机体系结构 量化研究方法 第五版>(Computer Architecture A Quantitative Approach), 关 ...
- 计算机组成原理——主存与cache的映射关系
全相联映像: 特点:指主存的一个字块能够映像到整个Cache的不论什么一个字块中.这样的映射方法比較灵活,cache的利用率高.但地址转换速度慢,且须要採用某种置换算法将cache中的内容调入调出,实 ...
- 主存到Cache直接映射、全相联映射和组相联映射
转自:https://blog.csdn.net/dongyanxia1000/article/details/53392315 ---- Cache的容量很小,它保存的内容只是主存内容的一个子集,且 ...
- Cache与主存地址映像计算例题
一.全相连映像 主存中任何一个块均可以映像装入到Cache中的任何一个块的位置上.主存地址分为块号和块内地址两部分,Cache地址也分为块号和块内地址.Cache的块内地址部分直接取自主存地址的块内地 ...
- Cache与主存之间的全相联映射,直接映射和组相联映射的区别
2017-02-22 注:本文并非原创,来自百度文库,只是觉得写得较好,故分享之.若是某人的知识产权,望告知!谢谢 1.高速缓冲存储器的功能.结构与工作原理 高速缓冲存储器是存在于主存与CPU之间的一 ...
- cache与MMU与总线仲裁
为了以合理的价格,设计容量和速度满足计算机系统的需求,计算机体系结构设计者设计出了存储器的层次结构. "Cache-主存"和"主存-辅存"是最常见的两种层次结构 ...
- TMS320C64x DSP L1 L2 Cache架构(1)——C64x Cache Architecture
[前沿]研究生阶段从事于DSP和FPGA技术的相关研究工作,学习并整理了大量的技术资料,包括TI公司的官方文档和网络上的详细笔记,花费了大量的时间和精力总结了前人的工作成果.无奈工作却从事于嵌入式技术 ...
- Something about cache
http://www.tyut.edu.cn/kecheng1/2008/site04/courseware/chapter5/5.5.htm 5.5 高速缓冲存储器cache 随着CPU时钟速率的不 ...
- 7.2 高速缓冲存储器-Cache
高速缓冲存储器:Cache.Cache的功能是提高CPU数据的输入和输出的速率.CPU的速度与主存的速度之间有巨大的差异.主存的存取时间.存取速度要比CPU的速度要慢了很多倍.为了调和它们之间的巨大速 ...
随机推荐
- CentOS 7 Nginx+PHP环境搭建!
1.Nginx 安装 rpm -Uvh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx. ...
- 026json和pickle,xml模块
###json和pickle ##json#dumps()data = #源数据data = json.dumps(data)这时候的data可以写入到文件了#loads()data = f.read ...
- Java连接MQ的实例, 测试类
package cjf.mq.mqclient; import com.ibm.mq.MQC; import com.ibm.mq.MQEnvironment; import com.ibm.mq.M ...
- 人类主动探索地外文明(METI)活动正在进行中
请看下图: 这是位于俄罗斯克里米亚境内的行星际深空通讯雷达(口径70米,2-300GHz,建造于1978年)的外观.借助该雷达的强大发射功率,有关国际 ...
- 【[SHOI2009]会场预约】
同样是从试炼场点进来的,这是一道非常需要耐心的题 不过明明就是我太菜了,真正的大佬都是一眼秒吧 首先我们有一种比较常规的暴力思路,就是用线段树来维护区间连续子段数,而拒绝掉所有与当前区间相冲突的预约我 ...
- 【[HNOI2005]狡猾的商人】
加权并查集 由于给出信息的是一些一个区间的和为多少,我们显然并不好处理出每一个点应该为多少,这我们根本做不到 但是我们想一下,如果要求一个区间\([l,r]\)的和,那么我们是不是可以利用前缀和\(p ...
- Redis通过IO进行序列化+反序列化
必须引用序列化Serializable接口 创建类:Role package com.wbg.springRedis.entity; import java.io.Serializable; publ ...
- 【nlogn LIS】 模板
总结:stl真好用 #include <cstdio> #include <cstring> #include <iostream> #include <al ...
- 【题解】UVA10298 Power String(KMP)
UVA10298:https://www.luogu.org/problemnew/show/UVA10298 思路 设P[x]数组为 前x个字符的最大前缀长度等于后缀字串 由P数组的定义我们可以知道 ...
- hdu 1026 Ignatius and the Princess I(BFS+优先队列)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=1026 Ignatius and the Princess I Time Limit: 2000/100 ...