HashMap底层数据结构和算法解析
1.Hash Map的数据结构?
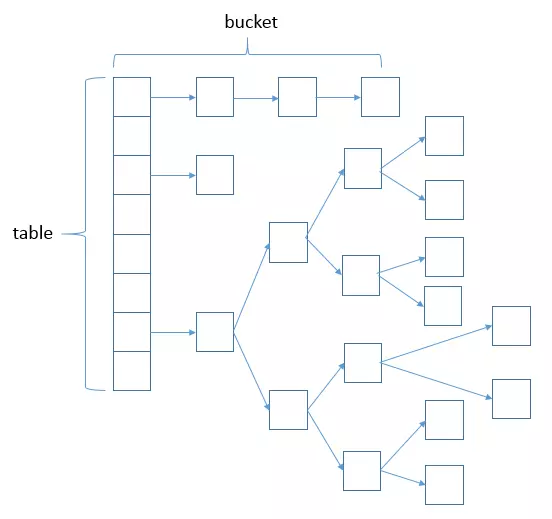
A:哈希表结构(链表散列:数组+链表)实现,结合数组和链表的优点。当链表长度超过8时,链表转换为红黑树。
transient Node<K,V>[] table;
2.HashMap的工作原理
A:HashMap底层是hash数组和单向链表实现,数组中的每个元素都是链表,由Node内部类(实现Map.Entry<k,V>接口)实现,HashMap通过put&get方法存储和获取。
存储对象时,将K/V键值对传给put()方法;
①、调用hash(K)方法计算K的hash值,然后结合数组长度,计算得数组下标;
②、调整数组大小(当容器中得元素个数大于capacity*loadFactor时,容器会进行resize为2n)
③、
i、如果K的hash值在HashMap不存在,则执行插入;若存在,则发生碰撞;
ii、如果K的hash值在HashMap存在,且它们两者equals返回true,则更新键值对;
iii、如果K的hash值在HashMap存在,且它们两者equals返回false,则插入链表的尾部(尾插法)或者红黑树(树的添加方式)
(JDK1.7 之前使用头插法、JDK 1.8 使用尾插法)
(注意:当碰撞导致链表大于TREEIFY_THRESHOLD = 8时,就把链表转换为红黑树)
获取对象时,将K传给get()方法:
①、调用hash(K)方法(计算K的hash值)从而获取该键值对所在链表的数组下标;
②、顺序遍历链表,equals()方法查找相同Node链表K值对应的V值
hashCode是定位的,存储位置;
equals是定性的,比较两者是否相等。
3.当两个对象的hashCode相同会发生什么?
A:因为hashCode相同,不一定就是相等的(equals方法比较),所以两个对象所在数组下标相同,“碰撞”就此发生。又因为HashMap使用链表存储对象,这个Node会存储到链表下。
4.:你知道hash的实现吗?为什么要这样实现?
A:JDK1.8中,是通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()^(h>>>16))
主要是从速度、功效和质量来考虑的,减少系统的开销,也不会造成因为高位没有参与下标的计算,从而引起的碰撞。
5:为什么要用异或运算符?
A:保持了对象的hashCode的32位值只要有一位发生改变,整个hash()返回值就会改变。尽可能的减少碰撞。
6.HashMap的table的容量如何确定?loadFactor是什么?该容量如何变化?这种变化会带来什么问题?
A:
①、table数组大小是由capacity这个参数确定的,默认是16,也可以构造时传入,最大限制为1<<30;
②、loadFactor是负载因子,主要目的是用来确认table数组是否需要动态扩展,默认值是0.75,比如table数组大小为16,装载因子为0.75时,threshold就是12,当table的实际大小超过12时,table就需要动态扩容;
③、扩容时,调用resize()方法,将table长度变为原来的两倍(注意是table长度,而不是threshold)
④、如果数据很大的情况下,扩展时将会带来性能的损失,在性能要求很高的地方,这种损失很可能很致命。
7.HashMap的遍历方式及其性能对比
A:主要四种方式
no1、for-each map.keySet()——只需要K值得时候推荐使用
for(String key : map.keySet()) {
map.get(key);
}
no2、for-each map.entrySet()——当需要V值得时候推荐使用
for(Map.Entry<String, String> entry : map.entrySet()) {
entry.getKey();
entry.getValue();
}
no3、for-each map.entrySet() + 临时变量
Set<Map.Entry<String, String>> entrySet = map.entrySet();
for (Map.Entry<String, String> entry : entrySet) {
entry.getKey();
entry.getValue();
}
no4、for-each map.entrySet().iterator()
Iterator<Map.Entry<String,String>> iterator =
map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
entry.getKey();
entry.getValue();
}
8.HashMap、LinkedHashMap、TreeMap有什么区别?
A:HashMap参考其他问题;
LinkedHashMap保存了记录得插入顺序,用iterator遍历时,先取到得记录肯定是先插入得;遍历比HashMap慢;
TreeMap实现SortMap接口,能够把它保存的记录根据键排序(默认按键值升序排序,也可以知道排序得比较器)
9.HashMap & TreeMap & LinkedHashMap 使用场景?
A:一般情况下,使用最多得是HashMao;
HashMap:在Map中插入、删除和定位元素时;
TreeMap:在需要按自然顺序或自定义顺序遍历键得情况下;
LinkedHashMap:在需要输出的顺序和输入的顺序相同的情况下。
10.HashMap和HashTable有什么区别?
A:
①、HashMap是线程不安全,HashTable是线程安全的;
②、由于线程安全,所以HashTable的效率比不上HashMap;
③、HashMap最多只允许一条记录的键为null,允许多条激励的值为null,而HashTable不允许;
④、HashMao默认初始化数组的大小为16,HashTable为11,前者扩容时,扩大两倍,后者扩大两倍+1;
⑤、HashMap需要重新计算hash值,而HashTable直接使用对象的hashCode。
11.同样是线程类,ConcurrentHashMap 和 HashTable 在线程同步上有什么不同
A:ConcurrentHashMap类(是Java并发包java.util.concurrent中提供的一个线程安全且高效的Hash Map实现)
HashTable是使用synchronize关键字加锁的原理(就是对对象加锁)
而针对ConcurrentHashMap,在JDK1.7 中采用分段锁的方式,JDK1.8 中直接采用了CAS(无锁算法)+ synchronized。
12.HashMap & ConcurrentHashMap 的区别?
A:除了加锁,原理上无太大区别。
另外,HashMap的键值对允许有null,但是ConcurrentHashMap 都不允许。
13.为什么 ConcurrentHashMap 比 HashTable 效率要高?
A:HashTable使用一把锁(锁住整个链表结构)处理并发问题,多个线程竞争一把锁,容易阻塞;
ConcurrentHashMap :
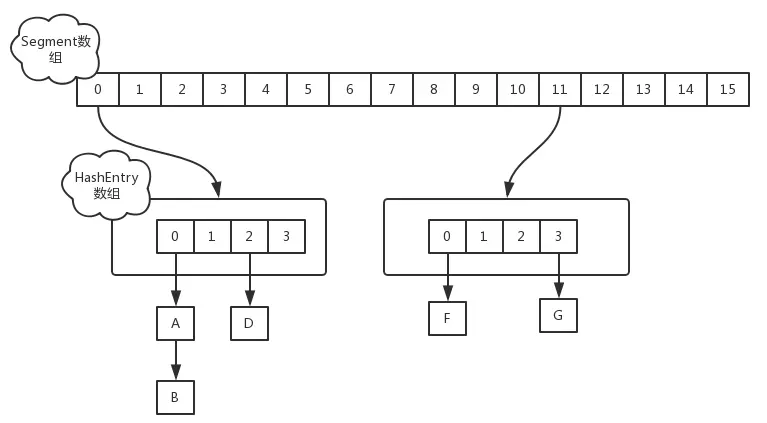
JDK1.7使用分段锁(ReentrantLock + Segment + HashEntry)相当于把一个HashMap分成多个段,每段分配一把锁,这样支持多线程访问。锁粒度:基于Segment,包含多个HashEntry。
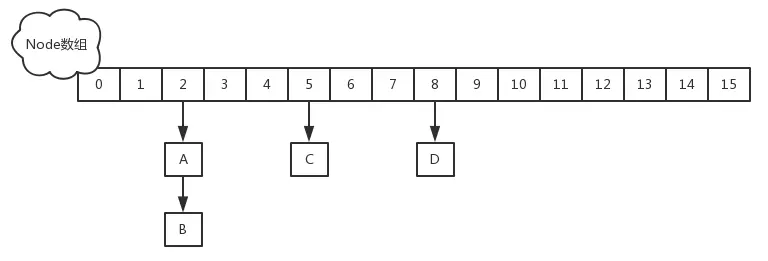
JDK1.8使用CAS + synchronized + Node + 红黑树。 锁粒度:Node(首结点)(实现Map.Entry<K,V>)。锁粒度降低了。
14:针对 ConcurrentHashMap 锁机制具体分析(JDK 1.7 VS JDK 1.8)?
A:JDK1.7中,采用分段锁的机制,实现并发的更新操作,底层采用数组+链表的存储结构,包括两个核心静态内部类Segment 和 HashEntry。
①、 Segment 继承 ReentrantLock(重入锁) 用来充当锁的角色,每个 Segment 对象守护每个散列映射表的若干个桶;
②、HashEntry用来封装映射表的键值对
③、每个桶是由若干个 HashEntry 对象链接起来的链表。
15:ConcurrentHashMap 在 JDK 1.8 中,为什么要使用内置锁 synchronized 来代替重入锁 ReentrantLock?
A:
i、粒度降低了
ii、JVM开发团队没有放弃synchronized,而且基于JVM的synchronized优化空间更大、更加自然
iii、在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存。
①、重要的常量:
private transient volatile int sizeCtl;
当为负数时,-1 表示正在初始化,-N 表示 N - 1 个线程正在进行扩容;
当为 0 时,表示 table 还没有初始化;
当为其他正数时,表示初始化或者下一次进行扩容的大小。
②、数据结构:
Node 是存储结构的基本单元,继承 HashMap 中的 Entry,用于存储数据;
TreeNode 继承 Node,但是数据结构换成了二叉树结构,是红黑树的存储结构,用于红黑树中存储数据;
TreeBin 是封装 TreeNode 的容器,提供转换红黑树的一些条件和锁的控制。
③、存储对象时(put() 方法):
1.如果没有初始化,就调用 initTable() 方法来进行初始化;
2.如果没有 hash 冲突就直接 CAS 无锁插入;
3.如果需要扩容,就先进行扩容;
4.如果存在 hash 冲突,就加锁来保证线程安全,两种情况:一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入;
5.如果该链表的数量大于阀值 8,就要先转换成红黑树的结构,break 再一次进入循环
6.如果添加成功就调用 addCount() 方法统计 size,并且检查是否需要扩容。
④、扩容方法 transfer():默认容量为 16,扩容时,容量变为原来的两倍。
helpTransfer():调用多个工作线程一起帮助进行扩容,这样的效率就会更高。
⑤、获取对象时(get()方法):
1.计算 hash 值,定位到该 table 索引位置,如果是首结点符合就返回;
2.如果遇到扩容时,会调用标记正在扩容结点 ForwardingNode.find()方法,查找该结点,匹配就返回;
3.以上都不符合的话,就往下遍历结点,匹配就返回,否则最后就返回 null。
A:程序运行时能够同时更新 ConccurentHashMap 且不产生锁竞争的最大线程数。默认为 16,且可以在构造函数中设置。当用户设置并发度时,ConcurrentHashMap 会使用大于等于该值的最小2幂指数作为实际并发度(假如用户设置并发度为17,实际并发度则为32)
作者:TinyDolphin
链接:https://www.jianshu.com/p/75adf47958a7
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
HashMap底层数据结构和算法解析的更多相关文章
- jdk1.8 HashMap底层数据结构:深入解析为什么jdk1.8 HashMap的容量一定要是2的n次幂
前言 1.本文根据jdk1.8源码来分析HashMap的容量取值问题: 2.本文有做 jdk1.8 HashMap.resize()扩容方法的源码解析:见下文“一.3.扩容:同样需要保证扩容后的容量是 ...
- jdk1.8源码解析:HashMap底层数据结构之链表转红黑树的具体时机
本文从三个部分去探究HashMap的链表转红黑树的具体时机: 一.从HashMap中有关“链表转红黑树”阈值的声明: 二.[重点]解析HashMap.put(K key, V value)的源码: 三 ...
- HashMap底层数据结构详解
一.HashMap底层数据结构 JDK1.7及之前:数组+链表 JDK1.8:数组+链表+红黑树 关于HashMap基本的大家都知道,但是为什么数组的长度必须是2的指数次幂,为什么HashMap的加载 ...
- [转]java 的HashMap底层数据结构
java 的HashMap底层数据结构 HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在.在HashMap中,key-v ...
- java 的HashMap底层数据结构
HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在.在HashMap中,key-value总是会当做一个整体来处理,系统会根据 ...
- Java数据结构与算法解析(十二)——散列表
散列表概述 散列表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即key,即可查找到其对应的值. 散列表的思路很简单,如果所有的键都是整数,那么就可以使用一个简单 ...
- 深入理解Mysql索引底层数据结构与算法
索引是帮助MySQL高效获取数据的排好序的数据结构 索引数据结构对比 二叉树 左边子节点的数据小于父节点数据,右边子节点的数据大于父节点数据. 如果col2是索引,查找索引为89的行元素,那么只需要查 ...
- java 中的JDK封装的数据结构和算法解析(集合类)----链表 List 之 Vector (向量)
Vector 看JDK解释(中文翻译)吧: Vector 类可以实现可增长的对象数组.与数组一样,它包含可以使用整数索引进行访问的组件.但是,Vector 的大小可以根据需要增大或缩小,以适应创建 ...
- java 中的JDK封装的数据结构和算法解析(集合类)----顺序表 List 之 ArrayList
1. 数据结构之List (java:接口)[由于是分析原理,这里多用截图说明] List是集合类中的容器之一,其定义如下:(无序可重复) An ordered collection (also kn ...
随机推荐
- 【网络】RFC1245-OSPF Protocol Analysis
OSPF协议分析 摘要 这是OSPF协议的两份报告中的第一份,这些报告是因特网工程指导组要求的,是用来将一个因特网协议写成标准草案的.OSPF是一个TCP/IP协议族中的一个的路由协议,被设计用于一个 ...
- redis linux下的环境搭建
系统 CentOS7 Redis 官网下载 https://redis.io/download 1.下载解压 [root@TestServer-DFJR programs]# /usr/loca ...
- Redis .net 客户端 分布式锁
关于Redis分布式锁的参考链接:http://redis.io/topics/distlock. 在我们项目中,之前琢磨用:ServiceStack.Redis,发现ServiceStack.Red ...
- 【51NOD-0】1012 最小公倍数LCM
[算法]欧几里德算法 #include<cstdio> int gcd(int a,int b) {?a:gcd(b,a%b);} int main() { int a,b; scanf( ...
- google protobuf序列化原理解析 (PHP示例)
一.简介 Protocol Buffers是谷歌定义的一种跨语言.跨平台.可扩展的数据传输及存储的协议,因为将字段协议分别放在传输两端,传输数据中只包含数据本身,不需要包含字段说明,所以传输数据量小, ...
- Vuejs - 花式渲染目标元素
Vue.js是什么 摘自官方文档: Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用.Vue 的核心库 ...
- It is possible that this issue is resolved by uninstalling an existi
使用真机连接Android Studio测试时出现这样的错误: 解决方法: 设置Android Studio 中Instant Run中的选项为不选中 根据以下路径,找到Instant Run中的选项 ...
- Java案例之随机验证码功能实现
实现的功能比较简单,就是随机产生了四个字符然后输出.效果图如下,下面我会详细说一下实现这个功能用到了那些知识点,并且会把 这些知识点详细的介绍出来.哈哈 ,大神勿喷,对于初学Java的人帮助应该蛮大的 ...
- copy_from_user分析
前言 copy_from_user函数的目的是从用户空间拷贝数据到内核空间,失败返回没有被拷贝的字节数,成功返回0.它内部的实现当然不仅仅拷贝数据,还需要考虑到传入的用户空间地址是否有效,比如地址是不 ...
- devm_xxx机制
前言 devm是内核提供的基础机制,用于方便驱动开发者所分配资源的自动回收.参考内核文档devres.txt.总的来说,就是驱动开发者只需要调用这类接口分配期望的资源,不用关心释放问题.这些资源的释放 ...