sklearn学习笔记之岭回归
岭回归
岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
使用sklearn.linear_model.Ridge进行岭回归
一个简单的例子
from sklearn.linear_model import Ridge
clf = Ridge(alpha=.5)
X = [[0,0],[0,0],[1,1]]
y = [0,.1,1]
clf.fit(X,y)
print(clf.coef_)
print(clf.intercept_)
运行结果如下:

使用方法
实例化
Ridge类已经设置了一系列默认的参数,因此clf = Ridge()即可以完成实例化。
但是,了解一下它的参数还是有必要的:
alpha:正则化项的系数copy_X:是否对X数组进行复制,默认为True,如果选False的话会覆盖原有X数组fit_intercept:是否需要计算截距max_iter:最大的迭代次数,对于sparse_cg和lsqr而言,默认次数取决于scipy.sparse.linalg,对于sag而言,则默认为1000次。normalize:标准化X的开关,默认为Falsesolver:在计算过程中选择的解决器auto:自动选择svd:奇异值分解法,比cholesky更适合计算奇异矩阵cholesky:使用标准的scipy.linalg.solve方法sparse_cg:共轭梯度法,scipy.sparse.linalg.cg,适合大数据的计算lsqr:最小二乘法,scipy.sparse.linalg.lsqrsag:随机平均梯度下降法,在大数据下表现良好。
注:后四个方法都支持稀疏和密集数据,而
sag仅在fit_intercept为True时支持密集数据。tol:精度random_state:sag的伪随机种子
以上就是所有的初始化参数,当然,初始化后还可以通过set_params方法重新进行设定。
回归分析
在实例化Ridge类以后,就可以直接使用Ridge中集成的方法来进行回归了,与绝大多数的sklearn类一样,Ridge使用fit方法执行计算
fit(X,y,sample\_weight=None):X是一个array类型,这是特征矩阵,包含着数据集每一条记录的特征值(N*M),y是结果矩阵,同样是array类型,可以是N*1的形状,也可以是N*K的形状,sample_weight代表着权重,可以是一个实数,也可以给每一条记录分配一个值(array类型)。
得到回归函数后,我们可以通过predict来使用回归函数。
predict(X):X测试数据集,此方法将返回回归后的结果
对于模型的好坏,Ridge当然提供了评价的方法——score
score(X,y,sample_weight=None):X为测试数据,y是测试数据的实际值,类型与fit中的相同,sample是权重
在sklearn中并没有提供直接的查看回归方程的函数,因此查看的时候需要自己转化一下。其实,sklearn就是把相关系数和残差分开保存了,因此,查看的时候要调用coef_和intercept_两个属性。
coef_:相关系数(array类型)intercept_:截距,在fit_intercept=False的时候,将会返回0
可能有用的方法
这些方法在sklearn的基类中就已经集成,但在一般情况下,通常不会用到。
get_params(deep=True):这是获取Ridge实例属性取值的方法,可以忽略set_params(**params):与get_params方法相对,是设置属性值,在岭回归中还是比较重要的,毕竟岭回归的alpha值在一开始可能并不知道,需要在一个范围内进行尝试,因此,利用这个方法来设置alpha值还是比较有用的。
以上就是Ridge的总体介绍,在现实生活中,一般不会想上面的实例中的直接使用定值来计算,下面是一个更实际一点的例子:
# Author: Fabian Pedregosa -- <fabian.pedregosa@inria.fr>
# License: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
# X is the 10x10 Hilbert matrix
X = 1. / (np.arange(1, 11) + np.arange(0, 10)[:, np.newaxis])
y = np.ones(10)
###############################################################################
# Compute paths
n_alphas = 200
alphas = np.logspace(-10, -2, n_alphas)
clf = linear_model.Ridge(fit_intercept=False)
coefs = []
for a in alphas:
clf.set_params(alpha=a)
clf.fit(X, y)
coefs.append(clf.coef_)
###############################################################################
# Display results
ax = plt.gca()
ax.set_color_cycle(['b', 'r', 'g', 'c', 'k', 'y', 'm'])
ax.plot(alphas, coefs)
ax.set_xscale('log')
ax.set_xlim(ax.get_xlim()[::-1]) # reverse axis
plt.xlabel('alpha')
plt.ylabel('weights')
plt.title('Ridge coefficients as a function of the regularization')
plt.axis('tight')
plt.show()
这个例子中,alpha为1e-10~1e-2,以对数值等分,对每一个aplha进行一次计算,最后画出岭迹图。岭迹图的样子如下:
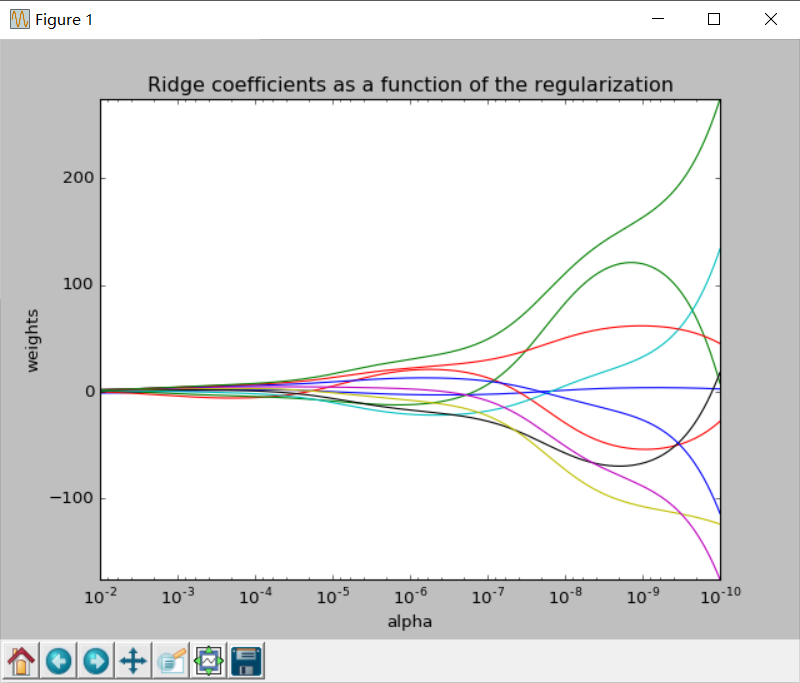
到此,岭回归的内容就结束了,我是sklearn的小小搬运工^_^/
sklearn学习笔记之岭回归的更多相关文章
- 机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归
机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归 关键字:Logistic回归.python.源码解析.测试作者:米仓山下时间:2018- ...
- sklearn学习笔记
用Bagging优化模型的过程:1.对于要使用的弱模型(比如线性分类器.岭回归),通过交叉验证的方式找到弱模型本身的最好超参数:2.然后用这个带着最好超参数的弱模型去构建强模型:3.对强模型也是通过交 ...
- sklearn学习笔记之简单线性回归
简单线性回归 线性回归是数据挖掘中的基础算法之一,从某种意义上来说,在学习函数的时候已经开始接触线性回归了,只不过那时候并没有涉及到误差项.线性回归的思想其实就是解一组方程,得到回归函数,不过在出现误 ...
- sklearn学习笔记(一)——数据预处理 sklearn.preprocessing
https://blog.csdn.net/zhangyang10d/article/details/53418227 数据预处理 sklearn.preprocessing 标准化 (Standar ...
- sklearn学习笔记之开始
简介 自2007年发布以来,scikit-learn已经成为Python重要的机器学习库了.scikit-learn简称sklearn,支持包括分类.回归.降维和聚类四大机器学习算法.还包含了特征 ...
- sklearn学习笔记3
Explaining Titanic hypothesis with decision trees decision trees are very simple yet powerful superv ...
- sklearn学习笔记2
Text classifcation with Naïve Bayes In this section we will try to classify newsgroup messages using ...
- sklearn学习笔记1
Image recognition with Support Vector Machines #our dataset is provided within scikit-learn #let's s ...
- Machine Learning 学习笔记 (3) —— 泊松回归与Softmax回归
本系列文章允许转载,转载请保留全文! [请先阅读][说明&总目录]http://www.cnblogs.com/tbcaaa8/p/4415055.html 1. 泊松回归 (Poisson ...
随机推荐
- 160720、SSM-Shiro使用详解
前言 相比有做过企业级开发的童鞋应该都有做过权限安全之类的功能吧,最先开始我采用的是建用户表,角色表,权限表,之后在拦截器中对每一个请求进行拦截,再到数据库中进行查询看当前用户是否有该权限,这样的设计 ...
- net.mvc中并发限制
浏览器限制 会话限制 线程限制 这篇文章讲的很详细: https://weblogs.asp.net/imranbaloch/concurrent-requests-in-asp-net-mvc 明白 ...
- Oracle 的安全保障 commit &checkpoint
Oracle 的安全 commit &checkpoint commit ---lgwr 事务相关的操作,保证事务的安全. commit标志着事务的结束.意味着别人对你事务操作的结果可见. c ...
- JS给html控件赋值
<html> <head> <title> JS给html控件赋值 </title> <script language="javascr ...
- MFC DLL获取当前路径
.首先定义此获取模块的静态方法 #if _MSC_VER >= 1300 // for VC 7.0 // from ATL 7.0 sources #ifndef _delayimp_h ex ...
- java基础10 吃货联盟点餐系统
public class OrderMsg { public static void main(String[] args) throws Exception { /** * 订餐人姓名.选择菜品.送 ...
- jenkins 升级
升级Jenkins Jenkins的开发迭代非常快,每周发布一个开发版本,长期支持版每半年更新一次(ps:大版本更新).如此频繁的更新,怎么升级呢? war:下载新版的war文件,替换旧版本war文件 ...
- Matlab/Simulink仿真中如何将Scope转化为Figure?
1.只需要在运行仿真后,在命令窗口内输入: ,'ShowHiddenHandle','on'); set(gcf,'menubar','figure'); scope最上方会出现一个菜单栏,选择Too ...
- Open Source VOIP applications, both clients and servers (开源sip server & sip client 和开发库)
SIP Proxies SBO SIP Proxy Bypass All types of Internet Firewall JAIN-SIP Proxy Mini-SIP-Proxy A very ...
- 数据库、Java与Hibernate数据类型对照
数据类型对照表: 标准SQL数据类型 Java数据类型 Hibernate数据类型 TINYINT byte.java.lang.Byte byte SMALLINT short.java.lang. ...